
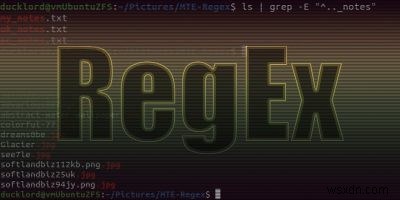
คุณเคยพยายามค้นหารูปแบบที่เกิดซ้ำในข้อความหรือไม่? คุณอาจเคยใช้บางอย่าง เช่น ฟังก์ชันการค้นหาในเบราว์เซอร์หรือโปรแกรมประมวลผลคำ แต่เมื่อคุณต้องการค้นหาบางอย่างที่ซับซ้อนกว่านี้ ก็อาจเหมือนกับการค้นหาเข็มในกองหญ้าที่เป็นที่เลื่องลือ
โชคดีที่มีวิธีเลือกรูปแบบที่แม่นยำในข้อความลงไปถึงตัวละคร ซึ่งเรียกว่านิพจน์ทั่วไป (RegEx) และช่วยให้คุณเป็นผู้เชี่ยวชาญในการค้นหาข้อความได้
ฉันจะใช้ RegEx ได้ที่ไหน
แม้ว่า Unix และ Linux จะได้รับความนิยม แต่นิพจน์ทั่วไปก็มีให้ใช้งานในแพ็คเกจที่หลากหลาย รวมถึง Microsoft Word
นิพจน์ทั่วไปมีการใช้งานที่โดดเด่นที่สุดในโปรแกรม Linux ที่มีชื่อเสียงหลายโปรแกรม รวมถึง grep , Awk และ Sed .
ตัวอย่างเช่น คุณอาจต้องการตรวจสอบอุปกรณ์ USB บนพีซีของคุณ การใช้ lspci คุณจะเห็นรายการอุปกรณ์ทั้งหมด และคุณจะต้องค้นหารายการ USB ด้วยตัวเอง คุณสามารถใช้สิ่งต่อไปนี้เพื่อแสดงเฉพาะอุปกรณ์ USB:
lspci | grep "USB"
นี่เป็นตัวอย่างที่ง่ายที่สุดของการดำเนินการ RegEx เป็นวิธีที่ได้รับความนิยมมากที่สุดในการใช้นิพจน์ทั่วไปในเทอร์มินัล แต่ไม่ใช่วิธีเดียว วันนี้ คุณสามารถหาการสนับสนุน RegEx ในซอฟต์แวร์ประเภทต่างๆ ได้มากมาย ตั้งแต่โปรแกรมแก้ไขข้อความไปจนถึงโปรแกรมจัดการไฟล์
การหารูปแบบ
คุณอาจเคยใช้ * อักขระซึ่งทำหน้าที่เป็นตัวแทนเมื่อเลือกไฟล์หรือโฟลเดอร์ในเทอร์มินัล ตัวอย่างเช่น ในการแสดงรายการไฟล์ JPG ทั้งหมดในโฟลเดอร์ คุณสามารถใช้:
ls *.jpg
RegEx ที่เทียบเท่ากับข้างต้นจะเป็น:
ls | grep -E "\.jpg"
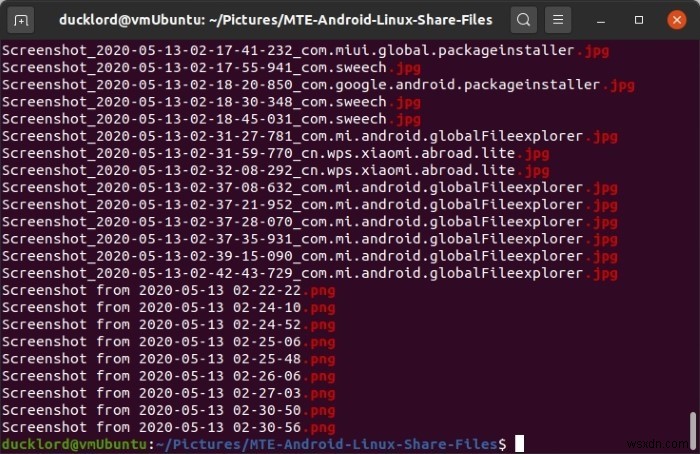
หากต้องการค้นหาทั้งไฟล์ jpg และ png ให้ใช้:
ls | grep -E "(\.jpg|\.png)"
ช่วง
หากคุณต้องการค้นหาช่วงอักขระเฉพาะแทนที่จะเป็นรูปแบบ คุณสามารถทำได้โดยกำหนดในวงเล็บ ตัวอย่างเช่น หากคุณใช้ [a-z] เป็นรูปแบบของคุณ ซึ่งจะจับคู่สตริงใดๆ ที่ประกอบด้วยตัวพิมพ์เล็กของตัวอักษร
อย่างที่คุณอาจเดาได้ [A-Z] จะเลือกเฉพาะอักษรตัวพิมพ์ใหญ่เท่านั้น ในการเลือกช่วงของตัวอักษรทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก นิพจน์จะเปลี่ยนเป็น [a-zA-Z] .
หากต้องการระบุจำนวนอินสแตนซ์เฉพาะของรูปแบบ คุณสามารถระบุในวงเล็บปีกกา {5} จะส่งคืนรูปแบบของคุณห้าครั้ง คุณยังสามารถใช้ช่วงของตัวเลขได้ ดังนั้น {5,10} จะนำเสนอคุณด้วยห้าถึงสิบอินสแตนซ์
เมตาคาแรคเตอร์
ในนิพจน์ทั่วไป คุณยังสามารถค้นหาส่วนของสตริงที่มีอักขระสองตัวที่เรียกว่า metacharacters คล้ายกับการจับคู่ไวด์การ์ดที่คุณอาจเคยใช้ในเชลล์
ตัวหลักคือจุดธรรมดา ซึ่งย่อมาจากอักขระตัวเดียวอื่นๆ หากคุณใช้รูปแบบ c.ll จะจับคู่กับ "เซลล์" แต่ยัง "คัดแยก" และ "โทร" ด้วย
เมื่อป้อนเครื่องหมายดอกจันหลังจุด คุณสามารถใช้เพื่อจับคู่อักขระได้ไม่จำกัดจำนวน ตัวอย่างเช่น .*board จะเป็นการจับคู่สำหรับทั้ง "คีย์บอร์ด" และ "สเกตบอร์ด" แม้ว่า “คีย์” และ “สเก็ต” จะมีจำนวนตัวอักษรต่างกัน
หลบหนี
คุณอาจสังเกตเห็นว่าในตัวอย่างของเรา ที่เราเลือกไฟล์รูปภาพประเภทต่างๆ เราใช้แบ็กสแลชก่อนจุด (“\.jpg”) นั่นคือวิธีที่คุณจะหลีกเลี่ยงอักขระพิเศษใน RegEx
หากเราไม่ใช้มัน รูปแบบของเราจะไม่จับคู่เฉพาะนามสกุลของไฟล์ สตริง เช่น ".jpg" และ ".png" แต่จะจับคู่ "ajpg" และ "opng" ด้วย จำไว้นะ . เป็นไวด์การ์ดที่ตรงกับอักขระใดก็ได้
จุดยึดและขอบเขต
จุดยึดและขอบเขตช่วยให้คุณกำหนดสิ่งที่คุณต้องการได้อย่างแม่นยำยิ่งขึ้น
หากต้องการค้นหาเฉพาะคำว่า "คอมพิวเตอร์" แต่ละรายการโดยไม่มีอักขระอื่นอยู่ก่อนหรือหลัง คุณควรกำหนดรูปแบบเป็น \<computer\> .
คุณยังสามารถค้นหาเฉพาะสำหรับรูปแบบที่ปรากฏที่จุดเริ่มต้นหรือจุดสิ้นสุดของบรรทัด สิ่งนี้ทำได้ด้วย ^ และ $ ตามลำดับ
ดังนั้น หากคุณต้องการค้นหาเฉพาะรายการที่คำว่า "คอมพิวเตอร์" ปรากฏที่ต้นบรรทัด รูปแบบของคุณจะมีลักษณะเหมือน ^computer . ในทางกลับกัน เมื่ออยู่ท้ายบรรทัด รูปแบบจะเปลี่ยนเป็น computer$ .
นี่เป็นกฎง่ายๆ ของ RegEx ซึ่งคุณสามารถผสมเพื่อค้นหารูปแบบที่คุณต้องการได้อย่างแม่นยำ คุณสามารถค้นหาช่วงอักขระที่จุดเริ่มต้นของบรรทัดหรือคำที่สลับกันที่ส่วนท้าย วันที่ที่ระบุ หรือช่วงปี โดยใช้สตริงข้อความเดียว
อย่าลืมตรวจสอบชีทนิพจน์ทั่วไปของเราเพื่อควบคุมนิพจน์ทั่วไป
