
เรื่องราวของการสื่อสาร
คุณเคยสงสัยหรือไม่ว่าอินเทอร์เน็ตพูดอย่างไร? คอมพิวเตอร์เครื่องหนึ่ง “พูดคุย” กับคอมพิวเตอร์อีกเครื่องหนึ่งผ่านทางอินเทอร์เน็ตได้อย่างไร
เมื่อผู้คนสื่อสารกัน เราใช้คำที่ร้อยเรียงเป็นประโยคที่ดูเหมือนมีความหมาย ประโยคนี้สมเหตุสมผลเพราะเราเห็นด้วยกับความหมายของประโยคเหล่านี้ เราได้กำหนดโปรโตคอลการสื่อสารไว้แล้ว
ปรากฏว่าคอมพิวเตอร์คุยกันในลักษณะเดียวกันทางอินเทอร์เน็ต แต่เรากำลังก้าวไปข้างหน้า ผู้คนใช้ปากสื่อสารกัน มาดูกันว่าปากของคอมพิวเตอร์คืออะไรก่อน
ป้อนซ็อกเก็ต
ซ็อกเก็ตเป็นหนึ่งในแนวคิดพื้นฐานที่สุดในวิทยาการคอมพิวเตอร์ คุณสามารถสร้างเครือข่ายทั้งหมดของอุปกรณ์ที่เชื่อมต่อถึงกันได้โดยใช้ซ็อกเก็ต
เช่นเดียวกับสิ่งอื่น ๆ ในวิทยาการคอมพิวเตอร์ซ็อกเก็ตเป็นแนวคิดที่เป็นนามธรรมมาก ดังนั้น แทนที่จะกำหนดว่าซ็อกเก็ตคืออะไร การกำหนดสิ่งที่ซ็อกเก็ตทำนั้นง่ายกว่ามาก
ดังนั้นซ็อกเก็ตทำอะไร? ช่วยให้คอมพิวเตอร์สองเครื่องสื่อสารกัน มันทำอย่างนี้ได้อย่างไร? มีการกำหนดสองวิธี เรียกว่า send() และ recv() สำหรับส่งและรับตามลำดับ
โอเค เยี่ยมเลย แต่ send() . ทำอะไร และ recv() ส่งและรับจริง? เมื่อผู้คนขยับปาก พวกเขาแลกเปลี่ยนคำพูด เมื่อซ็อกเก็ตใช้วิธีของพวกเขา ซ็อกเก็ตจะแลกเปลี่ยนบิตและไบต์
มาอธิบายวิธีการด้วยตัวอย่างกัน สมมติว่าเรามีคอมพิวเตอร์ 2 เครื่อง คือ A และ B คอมพิวเตอร์ A กำลังพยายามพูดอะไรบางอย่างกับคอมพิวเตอร์ B ดังนั้น คอมพิวเตอร์ B จึงพยายามฟังสิ่งที่คอมพิวเตอร์ A กำลังพูด หน้าตาก็จะประมาณนี้
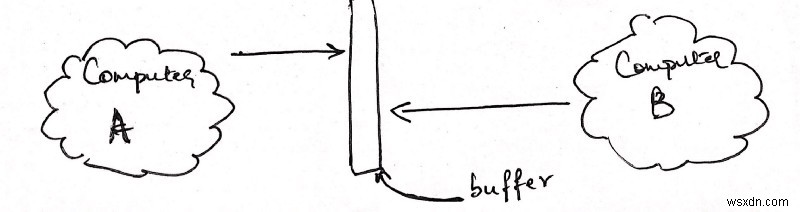
การอ่านบัฟเฟอร์
ดูแปลกไปหน่อยใช่มั้ย? ประการหนึ่ง คอมพิวเตอร์ทั้งสองเครื่องชี้ไปที่แถบตรงกลางที่ชื่อว่า "บัฟเฟอร์"
บัฟเฟอร์คืออะไร? บัฟเฟอร์เป็นสแต็กหน่วยความจำ เป็นที่เก็บข้อมูลสำหรับคอมพิวเตอร์แต่ละเครื่องและจัดสรรโดยเคอร์เนล
ต่อไป เหตุใดทั้งสองจึงชี้ไปที่บัฟเฟอร์เดียวกัน นั่นไม่ถูกต้องนักจริงๆ คอมพิวเตอร์แต่ละเครื่องมีบัฟเฟอร์ของตัวเองที่จัดสรรโดยเคอร์เนลของตัวเอง และเครือข่ายจะส่งข้อมูลระหว่างบัฟเฟอร์ทั้งสองแยกกัน แต่ฉันไม่ต้องการดูรายละเอียดเครือข่ายที่นี่ ดังนั้นเราจะถือว่าคอมพิวเตอร์ทั้งสองเครื่องสามารถเข้าถึงบัฟเฟอร์เดียวกันซึ่งวางไว้ "ที่ใดที่หนึ่งในช่องว่างระหว่าง"
โอเค ตอนนี้เรารู้แล้วว่าหน้าตาเป็นอย่างไร มาสรุปเป็นโค้ดกัน
#Computer A sends data computerA.send(data) #Computer B receives data computerB.recv(1024)
ข้อมูลโค้ดนี้ทำในสิ่งเดียวกับที่รูปภาพด้านบนแสดง ยกเว้นความอยากรู้อย่างเดียว เราไม่พูดว่า computerB.recv(data) . แต่เราระบุตัวเลขที่ดูเหมือนสุ่มแทนข้อมูล
เหตุผลง่ายๆ ข้อมูลบนเครือข่ายถูกส่งเป็นบิต ดังนั้น เมื่อเราเรียกคืนใน computerB เราจึงระบุจำนวน บิต เรายินดีรับ ณ จุดใดจุดหนึ่งในเวลาที่กำหนด
เหตุใดฉันจึงเลือก 1024 ไบต์เพื่อรับในครั้งเดียว ไม่มีเหตุผลเฉพาะ เป็นการดีที่สุดที่จะระบุจำนวนไบต์ที่คุณจะได้รับเป็นยกกำลัง 2 ฉันเลือก 1024 ซึ่งก็คือ 2¹⁰
ดังนั้นบัฟเฟอร์หาสิ่งนี้ได้อย่างไร? คอมพิวเตอร์ A เขียนหรือส่งข้อมูลใด ๆ ที่เก็บไว้ในบัฟเฟอร์ คอมพิวเตอร์ B ตัดสินใจอ่านหรือรับ 1024 ไบต์แรกของสิ่งที่เก็บไว้ในบัฟเฟอร์นั้น
โอเค เจ๋ง! แต่คอมพิวเตอร์สองเครื่องนี้รู้ได้อย่างไรว่าต้องคุยกัน? ตัวอย่างเช่น เมื่อคอมพิวเตอร์ A เขียนไปยังบัฟเฟอร์นี้ จะรู้ได้อย่างไรว่าคอมพิวเตอร์ B จะรับมัน หากต้องการใช้ถ้อยคำใหม่ จะแน่ใจได้อย่างไรว่าการเชื่อมต่อระหว่างคอมพิวเตอร์สองเครื่องมีบัฟเฟอร์ที่ไม่ซ้ำกัน
กำลังพอร์ตไปยัง IP
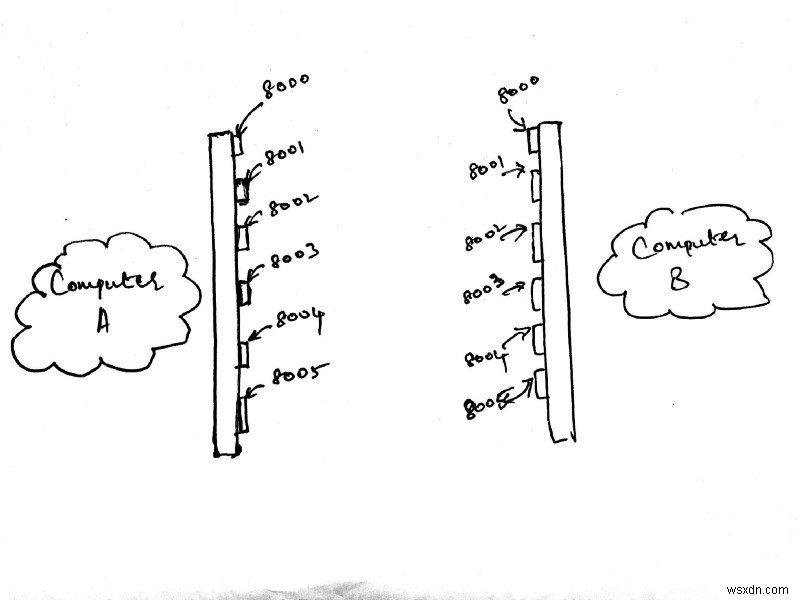
ภาพด้านบนแสดงคอมพิวเตอร์สองเครื่องเดียวกันกับที่เราใช้งานอยู่ พร้อมด้วยรายละเอียดเพิ่มเติมอีกหนึ่งรายการ มีตัวเลขจำนวนมากแสดงอยู่ด้านหน้าคอมพิวเตอร์แต่ละเครื่องตลอดความยาวของแถบ
พิจารณาแถบยาวที่ด้านหน้าของคอมพิวเตอร์แต่ละเครื่องเป็นเราเตอร์ที่เชื่อมต่อคอมพิวเตอร์เครื่องใดเครื่องหนึ่งเข้ากับอินเทอร์เน็ต หมายเลขที่ระบุไว้ในแต่ละแถบเรียกว่า พอร์ต . คอมพิวเตอร์ของคุณมีพอร์ตหลายพันพอร์ตอยู่ในขณะนี้ แต่ละพอร์ตอนุญาตให้เชื่อมต่อซ็อกเก็ต ฉันแสดงเพียง 6 พอร์ตในภาพด้านบน แต่คุณคงเข้าใจแล้ว
พอร์ตที่ต่ำกว่า 255 โดยทั่วไปสงวนไว้สำหรับการเรียกระบบและการเชื่อมต่อระดับต่ำ โดยทั่วไปแนะนำให้เปิดการเชื่อมต่อบนพอร์ตที่มีตัวเลข 4 หลักสูง เช่น 8000 ฉันไม่ได้วาดบัฟเฟอร์ในภาพด้านบน แต่คุณสามารถสรุปได้ว่าแต่ละพอร์ตมีบัฟเฟอร์ของตัวเอง
แถบนั้นยังมีตัวเลขที่เกี่ยวข้องอีกด้วย หมายเลขนี้เรียกว่าที่อยู่ IP ที่อยู่ IP มีพอร์ตมากมายที่เกี่ยวข้อง ลองคิดดูดังนี้:
127.0.0.1 / | \ / | \ / | \ 8000 8001 8002เยี่ยมมาก มาตั้งค่าการเชื่อมต่อบนพอร์ตเฉพาะระหว่างคอมพิวเตอร์ A และคอมพิวเตอร์ B
# computerA.pyimport socket computerA = socket.socket() # Connecting to localhost:8000 computerA.connect(('127.0.0.1', 8000)) string = 'abcd' encoded_string = string.encode('utf-8') computerA.send(encoded_string)
นี่คือรหัสสำหรับ computerB.py
# computerB.py import socket computerB = socket.socket() # Listening on localhost:8000 computerB.bind(('127.0.0.1', 8000)) computerB.listen(1) client_socket, address = computerB.accept() data = client_socket.recv(2048) print(data.decode('utf-8'))ดูเหมือนว่าเราจะก้าวไปข้างหน้าเล็กน้อยในแง่ของโค้ด แต่ฉันจะก้าวผ่านมันไปให้ได้ เรารู้ว่าเรามีคอมพิวเตอร์ 2 เครื่อง คือ A และ B ดังนั้น เราต้องการเครื่องหนึ่งเพื่อส่งข้อมูลและอีกเครื่องหนึ่งเพื่อรับข้อมูล
ฉันได้เลือก A เพื่อส่งข้อมูลและ B เพื่อรับข้อมูลโดยพลการ ในบรรทัดนี้ computerA.connect((‘127.0.0.1’, 8000) ฉันกำลังทำให้ computerA เชื่อมต่อกับพอร์ต 8000 บนที่อยู่ IP 127.0.0.1
หมายเหตุ:โดยทั่วไปแล้ว 127.0.0.1 หมายถึง localhost ซึ่งอ้างอิงถึงเครื่องของคุณ
จากนั้นสำหรับ computerB ฉันกำลังทำให้มันผูกกับพอร์ต 8000 บนที่อยู่ IP 127.0.0.1 ตอนนี้ คุณอาจสงสัยว่าเหตุใดฉันจึงมีที่อยู่ IP เดียวกันสำหรับคอมพิวเตอร์สองเครื่อง
นั่นเป็นเพราะฉันโกง ฉันใช้คอมพิวเตอร์เครื่องหนึ่งเพื่อสาธิตวิธีการใช้ซ็อกเก็ต (โดยพื้นฐานแล้วฉันกำลังเชื่อมต่อจากและไปยังคอมพิวเตอร์เครื่องเดียวกันเพื่อความง่าย) โดยทั่วไปแล้ว คอมพิวเตอร์สองเครื่องจะมีที่อยู่ IP ต่างกันสองเครื่อง
เราทราบแล้วว่าสามารถส่งได้เพียงบิตเป็นส่วนหนึ่งของแพ็กเก็ตข้อมูล นั่นคือเหตุผลที่เราเข้ารหัสสตริงก่อนที่จะส่ง ในทำนองเดียวกัน เราถอดรหัสสตริงบนคอมพิวเตอร์ B หากคุณตัดสินใจที่จะเรียกใช้สองไฟล์ข้างต้นในเครื่อง ตรวจสอบให้แน่ใจว่าได้เรียกใช้ computerB.py ไฟล์ก่อน หากคุณเรียกใช้ computerA.py ไฟล์ก่อน คุณจะได้รับการเชื่อมต่อถูกปฏิเสธข้อผิดพลาด
การให้บริการลูกค้า
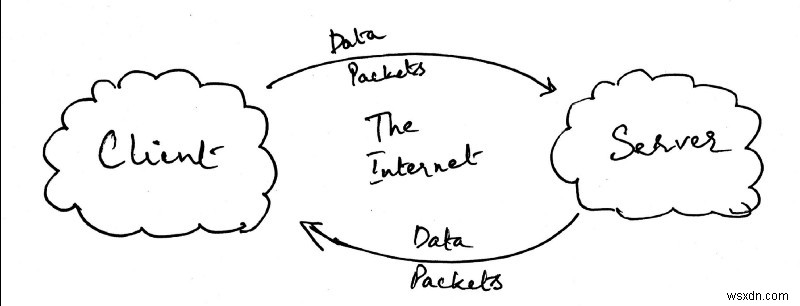
ฉันแน่ใจว่าพวกคุณหลายคนค่อนข้างชัดเจนแล้วว่าสิ่งที่ฉันอธิบายมาจนถึงตอนนี้คือโมเดลไคลเอนต์-เซิร์ฟเวอร์ที่เรียบง่ายมาก อันที่จริง คุณจะเห็นได้ว่าจากภาพด้านบน ทั้งหมดที่ฉันทำคือแทนที่คอมพิวเตอร์ A เป็นไคลเอนต์ และคอมพิวเตอร์ B เป็นเซิร์ฟเวอร์
มีการสื่อสารอย่างต่อเนื่องระหว่างไคลเอนต์และเซิร์ฟเวอร์ ในตัวอย่างโค้ดก่อนหน้านี้ เราได้อธิบายการถ่ายโอนข้อมูลเพียงครั้งเดียว สิ่งที่เราต้องการคือกระแสข้อมูลที่ส่งจากลูกค้าไปยังเซิร์ฟเวอร์อย่างต่อเนื่อง อย่างไรก็ตาม เราต้องการทราบด้วยว่าการถ่ายโอนข้อมูลเสร็จสิ้นเมื่อใด เราจึงหยุดฟังได้
ลองใช้การเปรียบเทียบเพื่อตรวจสอบเพิ่มเติม ลองนึกภาพการสนทนาต่อไปนี้ระหว่างคนสองคน
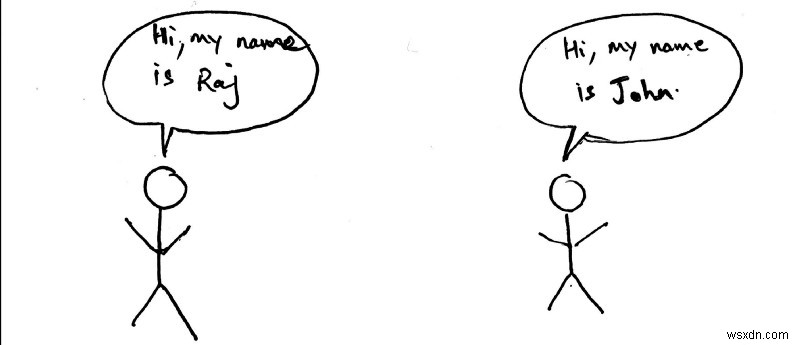
คนสองคนกำลังพยายามแนะนำตัวเอง อย่างไรก็ตาม พวกเขาจะไม่พยายามพูดคุยพร้อมกัน สมมติว่าราชไปก่อน จอห์นจะรอจนกว่าราชจะแนะนำตัวเองเสร็จก่อนที่เขาจะเริ่มแนะนำตัวเอง ข้อมูลนี้อิงจากการวิเคราะห์พฤติกรรมที่เรียนรู้แล้ว แต่โดยทั่วไปเราสามารถอธิบายข้างต้นเป็นโปรโตคอลได้
ลูกค้าและเซิร์ฟเวอร์ของเราต้องการโปรโตคอลที่คล้ายคลึงกัน มิฉะนั้นพวกเขาจะรู้ได้อย่างไรว่าถึงคราวที่ต้องส่งแพ็กเก็ตข้อมูล
เราจะทำบางสิ่งง่ายๆ เพื่อแสดงสิ่งนี้ สมมติว่าเราต้องการส่งข้อมูลที่เกิดขึ้นเป็นอาร์เรย์ของสตริง สมมติว่าอาร์เรย์เป็นดังนี้:
arr = ['random', 'strings', 'that', 'need', 'to', 'be', 'transferred', 'across', 'the', 'network', 'using', 'sockets']
ด้านบนเป็นข้อมูลที่จะเขียนจากไคลเอนต์ไปยังเซิร์ฟเวอร์ มาสร้างข้อจำกัดอื่นกันเถอะ เซิร์ฟเวอร์ต้องยอมรับข้อมูลที่เทียบเท่ากับข้อมูลที่ถูกครอบครองโดยสตริงที่จะถูกส่งผ่านในทันทีนั้น
ตัวอย่างเช่น หากไคลเอ็นต์จะส่ง "สุ่ม" ข้ามสตริง และสมมติว่าอักขระแต่ละตัวมีพื้นที่ 1 ไบต์ สตริงนั้นจะมีขนาด 6 ไบต์ 6 ไบต์จึงเท่ากับ 6*8 =48 บิต ดังนั้น สำหรับสตริง 'สุ่ม' ที่จะถ่ายโอนข้ามซ็อกเก็ตจากไคลเอนต์ไปยังเซิร์ฟเวอร์ เซิร์ฟเวอร์จำเป็นต้องรู้ว่าต้องเข้าถึง 48 บิตสำหรับแพ็กเก็ตข้อมูลเฉพาะนั้น
นี่เป็นโอกาสที่ดีในการทำลายปัญหา มีสองสิ่งที่เราต้องหาก่อน
เราจะหาจำนวนไบต์ที่สตริงอยู่ใน หลาม?
เราอาจเริ่มด้วยการหาความยาวของสตริงก่อน ง่ายๆ แค่โทรไปที่ len() . แต่เรายังต้องทราบจำนวนไบต์ที่ครอบครองโดยสตริง ไม่ใช่แค่ความยาว
เราจะแปลงสตริงเป็นไบนารีก่อน แล้วจึงหาความยาวของการแทนค่าไบนารีที่ได้ นั่นควรให้จำนวนไบต์ที่ใช้กับเรา
len(‘random’.encode(‘utf-8’)) จะให้สิ่งที่เราต้องการ
เราจะส่งจำนวนไบต์ที่แต่ละไบต์ครอบครองได้อย่างไร สตริงไปยังเซิร์ฟเวอร์หรือไม่
ง่ายๆ เราจะแปลงจำนวนไบต์ (ซึ่งเป็นจำนวนเต็ม) เป็นเลขฐานสองของตัวเลขนั้น และส่งไปยังเซิร์ฟเวอร์ ขณะนี้ เซิร์ฟเวอร์สามารถคาดหวังว่าจะได้รับความยาวของสตริงก่อนที่จะรับสตริงนั้นเอง
เซิร์ฟเวอร์จะทราบได้อย่างไรว่าเมื่อไคลเอ็นต์ส่งไฟล์ทั้งหมดเสร็จสิ้น สตริง?
จำจากการเปรียบเทียบของการสนทนา จะต้องมีวิธีการทราบว่าการถ่ายโอนข้อมูลเสร็จสมบูรณ์หรือไม่ คอมพิวเตอร์ไม่มีฮิวริสติกของตัวเองที่สามารถพึ่งพาได้ ดังนั้น เราจะให้กฎแบบสุ่ม เราจะบอกว่าเมื่อเราส่งผ่านสตริง 'end' นั่นหมายความว่าเซิร์ฟเวอร์ได้รับสตริงทั้งหมดและสามารถปิดการเชื่อมต่อได้ แน่นอนว่านี่หมายความว่าเราไม่สามารถใช้สตริง 'end' ในส่วนอื่น ๆ ของอาร์เรย์ของเราได้ยกเว้นส่วนท้ายสุด
นี่คือโปรโตคอลที่เราออกแบบจนถึงตอนนี้:
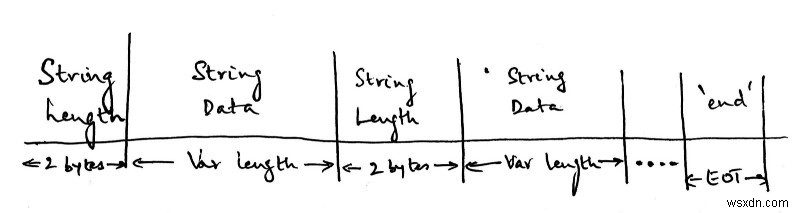
ความยาวของสตริงจะเป็น 2 ไบต์ ตามด้วยสตริงจริงซึ่งจะมีความยาวแปรผัน จะขึ้นอยู่กับความยาวของสตริงที่ส่งในแพ็กเก็ตก่อนหน้า และเราจะสลับกันระหว่างการส่งความยาวของสตริงและสตริงเอง EOT ย่อมาจาก End Of Transmission และการส่งสตริง 'end' หมายความว่าไม่มีข้อมูลที่จะส่งอีกต่อไป
หมายเหตุ:ก่อนที่เราจะดำเนินการต่อ ฉันต้องการชี้ให้เห็นบางอย่าง นี่เป็นโปรโตคอลที่ง่ายและโง่มาก หากคุณต้องการดูว่าโปรโตคอลที่ออกแบบมาอย่างดีเป็นอย่างไร ไม่ต้องมองหาที่อื่นนอกจากโปรโตคอล HTTP
มาเขียนโค้ดกัน ฉันได้ใส่ความคิดเห็นไว้ในโค้ดด้านล่างเพื่อให้เข้าใจในตัวเอง
เยี่ยมมาก เรามีลูกค้าที่ทำงานอยู่ ต่อไปเราต้องการเซิร์ฟเวอร์
ฉันต้องการอธิบายโค้ดบางบรรทัดในส่วนสำคัญข้างต้น อันแรกจาก clientSocket.py ไฟล์.
len_in_bytes = (len_of_string).to_bytes(2, byteorder='little')
สิ่งที่ด้านบนทำคือแปลงตัวเลขเป็นไบต์ พารามิเตอร์แรกที่ส่งไปยังฟังก์ชัน to_bytes คือจำนวนไบต์ที่จัดสรรให้กับผลลัพธ์ของการแปลง len_of_string เพื่อแทนค่าไบนารี
พารามิเตอร์ที่สองใช้เพื่อตัดสินใจว่าจะใช้รูปแบบ Little Endian หรือรูปแบบ Big Endian คุณสามารถอ่านเพิ่มเติมเกี่ยวกับเรื่องนี้ได้ที่นี่ สำหรับตอนนี้ แค่รู้ว่าเราจะยึดติดกับพารามิเตอร์นั้นเพียงเล็กน้อยเสมอ
รหัสบรรทัดถัดไปที่ฉันต้องการดูคือ:
client_socket.send(string.encode(‘utf-8’))
เรากำลังแปลงสตริงให้อยู่ในรูปแบบไบนารีโดยใช้‘utf-8’ กำลังเข้ารหัส
ต่อไปใน serverSocket.py ไฟล์:
data = client_socket.recv(2) str_length = int.from_bytes(data, byteorder='little')
โค้ดบรรทัดแรกด้านบนได้รับข้อมูล 2 ไบต์จากลูกค้า จำไว้ว่าเมื่อเราแปลงความยาวของสตริงให้อยู่ในรูปแบบไบนารีใน clientSocket.py เราตัดสินใจเก็บผลลัพธ์เป็น 2 ไบต์ นี่คือเหตุผลที่เราอ่านข้อมูลขนาด 2 ไบต์ที่นี่สำหรับข้อมูลเดียวกัน
บรรทัดถัดไปเกี่ยวข้องกับการแปลงรูปแบบไบนารีเป็นจำนวนเต็ม byteorder นี่คือ "น้อย" เพื่อให้ตรงกับ byteorder เราใช้กับไคลเอนต์
หากคุณดำเนินการต่อและเรียกใช้ซ็อกเก็ตทั้งสอง คุณจะเห็นว่าเซิร์ฟเวอร์จะพิมพ์สตริงที่ไคลเอ็นต์ส่งผ่าน เราสร้างการสื่อสาร!
บทสรุป
ตกลงเราครอบคลุมค่อนข้างน้อย กล่าวคือ ซ็อกเก็ตคืออะไร เราใช้งานอย่างไร และวิธีออกแบบโปรโตคอลที่เรียบง่ายและโง่เขลา หากคุณต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการทำงานของซ็อกเก็ต เราขอแนะนำให้คุณอ่าน Beej's Guide To Network Programming e-book เล่มนั้นมีสิ่งที่ยอดเยี่ยมมากมาย
แน่นอน คุณสามารถใช้สิ่งที่คุณอ่านในบทความนี้ และนำไปใช้กับปัญหาที่ซับซ้อนมากขึ้น เช่น การสตรีมรูปภาพจากกล้อง RaspberryPi ไปยังคอมพิวเตอร์ของคุณ ขอให้สนุกกับมัน!
หากต้องการ คุณสามารถติดตามฉันได้ทาง Twitter หรือ GitHub คุณยังสามารถตรวจสอบบล็อกของฉันได้ที่นี่ ฉันพร้อมเสมอหากคุณต้องการติดต่อฉัน!
เผยแพร่ครั้งแรกที่ https://redixhumayun.github.io/networking/2019/02/14/how-the-internet-speaks.html เมื่อวันที่ 14 กุมภาพันธ์ 2019
