
คุณอาจเคยได้ยินเกี่ยวกับเรื่องนี้ Google กำลังพิจารณาแนวคิดที่จะเปลี่ยนวิธีที่ผู้คนโต้ตอบกับเว็บไซต์ โดยเฉพาะอย่างยิ่ง วิธีที่ผู้คนโต้ตอบกับ URL ซึ่งเป็นที่อยู่เว็บที่มนุษย์อ่านได้ ซึ่งเราใช้ในการระบุและจดจำเว็บไซต์ที่เราเข้าชมเป็นส่วนใหญ่ ผลกระทบกระเพื่อมรอบ ๆ ข้อเสนอนี้ค่อนข้างน่าสนใจที่จะพูดน้อยที่สุด และทำให้ฉันคิด
ประการแรก ฟันเฟืองที่ต่อต้านการเปลี่ยนแปลงนั้นเปิดเผยมากกว่าตัวการเปลี่ยนแปลงเอง สอง มีข้อดีจริง ๆ หรือไม่ในการพยายามสร้าง URL ที่มีความหมายและ/หรือมีประโยชน์มากกว่ารูปแบบปัจจุบัน ด้วยเหตุนี้ คุณกำลังอ่านบทความนี้
URL คร่าวๆ
มนุษย์เชื่อมโยงความทรงจำกับคำพูดมากกว่าตัวเลข การที่เราจะจำทั้งประโยคหรือย่อหน้าได้ง่ายกว่าชุดตัวเลข เนื่องจากภาษาของเราสร้างจากคำเป็นส่วนใหญ่ เราต่อสู้กับลำดับของตัวเลขที่ยาวกว่าแปดหรือเก้าหลัก เหตุผลง่ายๆ ก็คือ ด้วยตัวอักษร ความเป็นเอกลักษณ์ของข้อมูลมีขนาดค่อนข้างเล็ก - 1001 และ 1002 ห่างกันเพียงตัวอักษรเดียว แต่เป็นเพียงส่วนสุดท้ายที่ให้ความหมายกับความแตกต่าง สำหรับคำ มีชุดค่าผสมค่อนข้างน้อยที่จะคลุมเครือเกินลำดับอักขระและ/หรือเสียงสั้นๆ
ดังนั้น เมื่อเว็บเกิดขึ้น การใช้คำ - สตริง - เพื่อระบุเว็บไซต์จึงมีเหตุผลมากกว่าการตีความด้วยเครื่อง มันเป็นวงจรที่ตลก เราแปลงคำ (โค้ด) ให้เป็นภาษาเครื่อง จากนั้นจึงทำสิ่งที่ตรงกันข้าม เพื่อให้ผู้คนสามารถโต้ตอบกับคอมพิวเตอร์ได้อย่างมีความหมาย ท่องเว็บโดยใช้ตัวเลขเป็นหลัก สตริงเป็นวิถีของมนุษย์ปัญหาคือ - URL เป็นรูปแบบลูกผสมระหว่างภาษามนุษย์และภาษาเครื่อง ในแง่หนึ่ง คุณมีองค์ประกอบของมนุษย์ ที่อยู่เอง (เช่น dedoimedo.com) แต่ส่วนที่เหลือทั้งหมดเป็นเพียงคำแนะนำสำหรับเซิร์ฟเวอร์ระยะไกลในการค้นหา ค้นหา และนำเสนอข้อมูลกลับไปยังผู้ใช้ สิ่งนี้นำเสนอปัญหาที่ผู้คนโต้ตอบกับเว็บไซต์ในลักษณะที่ไม่สมเหตุสมผลสำหรับสมองของมนุษย์ทั่วไป
ปัญหาอีกประการหนึ่งคือ - URL ไม่มีความเที่ยงตรงของข้อมูลที่ฝังอยู่ เหมือนกับที่อยู่ทางกายภาพในโลกแห่งความเป็นจริง หากคุณไปที่ 17 Orchard Drive จะไม่บอกคุณว่าที่อยู่นั้นคืออะไร อาจเป็นสำนักงาน อาจเป็นที่พักส่วนตัว อาจเป็นห้องเต้นรำ ไม่มีข้อมูลเกี่ยวกับเนื้อหาเช่นเดียวกับสิ่งที่คุณจะพบในนั้น - ผู้คน เศษหินหรืออิฐ แท่นบูชาบูชายัญ ฯลฯ
ในทำนองเดียวกัน URL จะไม่แสดงถึงปลายทาง (ไซต์ที่คุณกำลังเชื่อมต่อ) แต่อย่างใด บางครั้งอาจมีความสัมพันธ์กัน แต่โดยรวมแล้วจะไม่มีความหมายเว้นแต่คุณจะรู้ว่าไซต์นี้เกี่ยวกับอะไรและมีวัตถุประสงค์เพื่อทำอะไร นี่เป็นเรื่องจริงสำหรับไซต์ขนาดเล็กเช่นเดียวกับบริษัทยักษ์ใหญ่
ตัวอย่างเช่น Google ไม่ได้บอกคุณจริงๆ ว่าเป็นเครื่องมือค้นหา Yahoo ไม่ได้บอกคุณว่าเป็นเครื่องมือค้นหา Bing หมายถึงอะไร Amazon เป็นแม่น้ำ ป่าไม้ หรือตลาดออนไลน์ขนาดใหญ่หรือไม่? คุณไว้วางใจไซต์เหล่านี้ได้จากการใช้งานและชื่อเสียงโดยทั่วไป ไม่ใช่เพราะมีค่าโปรโตในข้อมูล URL แต่จะดีขึ้นหรือแย่ลง:
- ไม่มีความสัมพันธ์ระหว่างสตริงของไซต์และวัตถุประสงค์ของไซต์
- ไม่มีความสัมพันธ์ระหว่างสตริงของไซต์และชื่อไซต์ (หรือธุรกิจที่อยู่เบื้องหลัง)
- ไม่มีความสัมพันธ์ระหว่างชื่อหน้าเว็บไซต์และชื่อเว็บไซต์
- ไม่มีข้อมูลเกี่ยวกับวัตถุประสงค์ของไซต์
นอกจากนี้ เมื่อคุณเข้าสู่หน้าใดหน้าหนึ่ง อาจไม่มีความสัมพันธ์กันระหว่างชื่อหน้า, URL และเนื้อหา คุณสามารถไปที่ไซต์บางแห่ง ไปที่หน้า kittys.html แต่อาจเกี่ยวกับสติกเกอร์รูปแมวสำหรับรถยนต์ หรือเกี่ยวกับสิ่งเล็กๆ ที่มีขนยาว หรืออย่างอื่นโดยสิ้นเชิง. และไซต์อาจถูกเรียกว่าร้านของ Dany และ URL อาจเป็นเช่น mysitenstuff.org
และมันยังคงแย่ลงไปอีก สำหรับตอนนี้ เราได้พูดถึงองค์ประกอบของมนุษย์ในสมการเท่านั้น จากนั้นมีส่วนของเครื่องจักร โดเมนย่อย เช่น m, www, www3 โปรโตคอลเช่น http, https, ftp ตัวคั่นไดเร็กทอรีย่อย วิธีที่ไม่สม่ำเสมอซึ่งไซต์นำเสนอหน้าของพวกเขา - วันที่ ตัวเลขสุ่ม สตริง ฯลฯ จากนั้นคุณยังมีคำแนะนำ หน้าอาจมีบางอย่างเช่น &uid=1234567&ref=true ต่อท้ายสตริง URL ซึ่งไม่มีความหมายอะไรสำหรับคุณในฐานะผู้ใช้ แต่จะบอกบางสิ่งกับเว็บเซิร์ฟเวอร์และ/หรือแอปพลิเคชันที่ให้บริการหรือแยกวิเคราะห์เนื้อหา .
ตัวเลือก URL ทั้งหมดนี้จะแปลงเป็นเนื้อหาเดียวกัน แต่ทั้งหมดจะดูและแสดงผลต่างกัน
สุดท้ายก็ไม่มีมาตรวัดความไว้เนื้อเชื่อใจ เว็บไซต์มีค่าเท่ากันจนกว่าจะได้รับการตรวจสอบในทางใดทางหนึ่ง ในช่วงแรก เมื่อการช้อปปิ้งออนไลน์ได้รับความนิยมมากขึ้น แนวคิดของใบรับรองดิจิทัลจึงเกิดขึ้น โดยมีหน่วยงานที่น่าเชื่อถือรับรองทั้งความน่าเชื่อถือและความปลอดภัยที่อยู่เบื้องหลังตราสัญลักษณ์ที่เข้ารหัสและป้องกันการงัดแงะ ความพยายามของชุมชนและการจัดอันดับหน้า (บางครั้งเป็นกรรมสิทธิ์) กลายเป็นการวัดมูลค่ารองที่เกี่ยวข้องกับโดเมน (ไซต์) และเนื้อหาของโดเมน แต่โดยพื้นฐานแล้ว สิ่งนี้ไม่ได้สะท้อนให้เห็นในตัว URL เลย
คำถามคือเราต้องการการเปลี่ยนแปลงหรือไม่? อาจจะ. อาจจะไม่. อินเทอร์เน็ตใช้งานได้และปรับขนาดได้ดี
คำตอบอยู่ในการแก้ปัญหา แต่ก่อนอื่นมีปรัชญาอีกเล็กน้อยคุณรู้สึกอย่างไรเมื่อได้ยินเกี่ยวกับข้อเสนอนี้
เท่าที่เห็นมามี 2 ค่ายใหญ่ครับ ผู้ที่ยินดีกับการเปลี่ยนแปลง รู้สึกว่าสิ่งนี้จะทำให้เว็บดีขึ้น (จำเป็นต้องกำหนดปริมาณของสิ่งที่ดีขึ้น และผู้ที่ต่อต้านการเปลี่ยนแปลง. กลุ่มที่สองสามารถแบ่งออกเป็นสามกลุ่ม:ผู้คนที่ต่อต้านการเปลี่ยนแปลงเพื่อเห็นแก่ประโยชน์ ผู้ที่ต่อต้านข้อดีทางเทคนิคและผลประโยชน์ที่ควรได้รับ และกลุ่มที่สามที่ไม่ไว้วางใจบริษัทที่แสวงหาผลกำไรที่เสนอหรือเป็นผู้นำการเปลี่ยนแปลงนี้
นี่เป็นคำถามเชิงปรัชญาที่ยิ่งใหญ่กว่ามาก Google ควรได้รับอนุญาตให้เป็นผู้นำในเรื่องนี้หรือไม่
ตลอดหลายปีที่ผ่านมา บริษัทที่แสวงหาผลกำไรจำนวนมากได้สร้างผลิตภัณฑ์ที่ดีที่เราใช้อยู่ทุกวันนี้โดยไม่ได้คิดถึงมันเลย ความเกรี้ยวกราดและการโต้เถียงในช่วงต้นถูกลืมไปนานแล้ว แต่มีเงินเข้ามาเกี่ยวข้อง เป็นปัจจัยกระตุ้นที่แข็งแกร่ง และมีการดำเนินการต่างๆ เพื่อเสริมความแข็งแกร่งให้กับผลกำไรของบริษัท สิ่งเดียวกันนี้ย่อมเกิดขึ้นกับบริษัทที่มีความรับผิดชอบต่อผู้ถือหุ้นไม่ว่าจะชื่ออะไรก็ตาม Google มีตำแหน่งผู้นำเนื่องจากมีอิทธิพลอย่างมากในโลกมือถือและเวทีการค้นหา แต่นี่อาจเป็นบริษัทใดก็ได้ และท้ายที่สุดแล้วปัจจัยพื้นฐานก็เหมือนกัน สำหรับบางคน นี่คือทั้งหมดที่สำคัญ หากเป็นการแสวงหาผลกำไร ก็จะไม่สามารถแก้ปัญหาที่เป็นกลางซึ่งเป็นประโยชน์ต่อมนุษยชาติได้ อาจเป็นผลข้างเคียง แต่ไม่ใช่เป็นเป้าหมายหลัก
และนี่คือสิ่งที่น่าสนใจจริงๆ การต่อต้านเป็นภาพสะท้อนของ Google ในช่วงหลายปีที่ผ่านมามากกว่าที่จะเกี่ยวข้องกับเทคโนโลยี ดูเหมือนว่าตั้งแต่การไม่ทำความชั่ว (หายไปจากรายการของบริษัท) ไปจนถึงบริษัทสูทหนุ่มใหญ่อีกแห่งหนึ่ง
อีกตัวอย่างหนึ่งที่ทำให้กรณีนี้แข็งแกร่งขึ้นคือการที่ Google ยืนหยัดใน AMP ซึ่งเป็นโครงการที่ปรับให้เหมาะกับมือถือของตัวเองที่รวม HTML ธรรมดาไว้ในคำสั่ง AMP พิเศษ แม้ว่าจะมีข้อดีอยู่บ้างเมื่อพูดถึงการโหลดหน้าเว็บ แต่โดยรวมแล้วถือว่าแย่มาก เป็นปัญหาซ้ำซากที่เราเห็นใน Internet Explorer 6 ซึ่ง Microsoft ออกคำสั่งใหม่มากมายที่ไม่เป็นไปตามมาตรฐานเว็บ สร้างความโกลาหล HTML/CSS เฉพาะเบราว์เซอร์ซึ่งเพิ่งได้รับการแก้ไขบางส่วน
เมื่อฉันเริ่ม Dedoimedo ในปี 2549 นี่เป็นปัญหาใหญ่ เกือบทุกไซต์ในตอนนั้นมีการแทนที่ IE6/7/8 ใน HTML ฉันตัดสินใจที่จะไม่ใช้สิ่งเหล่านั้นและยึดตามข้อกำหนดเฉพาะของ W3C โดยไม่คำนึงว่าผู้เข้าชมอาจโดนลงโทษหรือไม่ก็ตาม เพราะวิธีเดียวที่จะออกแบบให้เหมือนกันและเป็นมาตรฐานคือวิธีที่ Tim Berners-Lee ผู้เป็นตำนานได้จินตนาการไว้ ประวัติศาสตร์พิสูจน์ว่าฉันถูกต้อง แม้กระทั่งทุกวันนี้ ฉันแน่ใจว่าทุกหน้าของฉันมี HTML และ CSS ที่ถูกต้อง ซึ่งเป็นสิ่งที่คุณไม่ค่อยเห็นในตลาดทุกวันนี้ และถ้าคุณใช้การแทนที่พิเศษสำหรับเบราว์เซอร์นี้หรือเบราว์เซอร์นั้น แสดงว่าคุณกำลังช่วยทำให้อินเทอร์เน็ตดีน้อยลง
HTML ที่ถูกต้อง สัตว์ใกล้สูญพันธุ์
ขณะนี้ Google กำลังสร้างปัญหาความแตกต่างของการปฏิบัติตามข้อกำหนด HTML/CSS ขึ้นใหม่ด้วย AMP เว็บต้องเป็นกลางและเป็นไปตามมาตรฐานสากลที่เป็นกลาง ไม่ควรมีรูปร่างตามสิ่งที่บริษัทต้องการ
ดังนั้น URL จึงเป็นเพียงตัวเร่งให้เกิดความไม่ไว้วางใจต่อองค์กรขนาดใหญ่ โดยเฉพาะอย่างยิ่งในธุรกิจข้อมูลส่วนตัว นั่นคือปัญหาที่ต้องแก้ไขก่อนเพื่อที่เราจะสามารถแยกอารมณ์ความรู้สึกออกจากเทคโนโลยีได้ มิฉะนั้น ข้อเสนอในอนาคตทั้งหมดจะมีข้อบกพร่อง เนื่องจากข้อเสนอเหล่านี้จะพยายามตอบสนองความต้องการทางอารมณ์มากกว่าความต้องการทางเทคนิค
ฉันไม่มีวิธีแก้ปัญหานี้ มีเพียง Google เท่านั้นที่เปลี่ยนแปลง Google ได้ แน่นอนหากพวกเขาต้องการ
สิ่งต่าง ๆ เปลี่ยนไป
เราต้องไม่ลืมสิ่งนี้ ความคิดที่เป็นกุศลถูกพัดพาไปในโมเมนตัมของชีวิต กลายเป็นแนวคิดผิดๆ ในยุคแรกเริ่ม บางครั้งสิ่งนี้เกิดขึ้นจากการออกแบบโดยเจตนา และบางครั้งก็เกิดขึ้นโดยบังเอิญ จากการตัดสินใจและข้อจำกัดเล็กๆ น้อยๆ นับล้านที่ไม่สามารถมองเห็นหรือวางแผนล่วงหน้าได้ ลองนึกถึงผลิตภัณฑ์ใดๆ ก็ตามที่คุณใช้อยู่ ดูว่าเมื่อห้าหรือสิบปีก่อนเป็นอย่างไร หากย้อนกลับไปไกลขนาดนั้น คุณเห็นการเปลี่ยนแปลงหรือไม่? คุณชอบมันไหม? จากนั้นจำไว้ว่าคุณเองก็เปลี่ยนไปเช่นกัน และวิธีที่คุณรับรู้โลกทุกวันนี้ก็ไม่เหมือนกับที่คุณรู้สึกเมื่อสองสามปีก่อน
โซลูชันของ Google หรือของใครก็ตามอาจเป็นสิ่งที่ดีที่สุดในโลก สิบเจ็ดหรือยี่สิบปีนับจากนี้ มันอาจเปลี่ยนแปลงไปในทางที่คาดเดาไม่ได้ แม้จะมีความตั้งใจดีที่สุดและการเรียนรู้อย่างลึกซึ้งทั้งหมดในโลกก็ตาม ไม่จำเป็นต้องมีความชั่วร้ายใด ๆ ในนั้น เพียงแค่ค่อยๆ คืบคลานของวิธีการทำ ผู้คนเริ่มคุ้นเคยและยอมรับบรรทัดฐานใหม่ที่เป็นประเพณีเก่า และดำเนินต่อไป จนกระทั่งสิ่งดั้งเดิมถูกลืมเลือนไปนานแล้ว
ปัญหาใหญ่อยู่ในนั้น ไม่ว่าข้อเสนอที่ตกลงในวันนี้จะเป็นเช่นไร แม้ว่าโซลูชันของ Google จะสมบูรณ์แบบ แต่ก็ไม่มีสิ่งใดที่จะหยุดบริษัทใดๆ จากการดำเนินการที่เป็นส่วนตัวและเป็นกรรมสิทธิ์ รวมถึง Google เองสำหรับเรื่องนั้นด้วย หรือคู่แข่งรายใด
การแปรรูปอินเทอร์เน็ตเกิดขึ้นจริงแล้ว อินเทอร์เน็ตมีขนาดเล็กลง ประการแรก คุณใช้ข้อมูลส่วนใหญ่ของคุณผ่านนายหน้า - เสิร์ชเอ็นจิ้น พอร์ทัลข่าว คุณจะแทบไม่พบเนื้อหาใหม่ๆ นอกเสียจากว่าเนื้อหานั้นจะแสดงอยู่ในไซต์ค้นหายอดนิยม และถึงอย่างนั้น เนื้อหาก็อยู่ในอันดับต้นๆ ของรายการ บนมือถือมันแย่ยิ่งกว่า ผู้คนแทบจะไม่เรียกดูอีกต่อไป พวกเขาใช้แอพที่ให้บริการโดยร้านค้าส่วนกลางแห่งเดียว
เพียงแค่ดูว่าสมาร์ทโฟนทั่วไปหรือสมาร์ททีวีเป็นอย่างไร - แพลตฟอร์มที่มีการควบคุมอย่างเข้มงวดพร้อมเนื้อหาที่คัดสรรและกรอง เมื่อคุณเปิดแอปโทรศัพท์ คุณจะไม่รู้ว่าแอปกำลังทำอะไรอยู่เบื้องหลังหรือเชื่อมต่อกับ URL ใด ไม่ว่าคุณจะไว้วางใจแพลตฟอร์มให้ทำตามที่บอกว่าจะทำ หรือคุณไม่ได้ใช้ ซึ่งยากขึ้นเรื่อย ๆ เนื่องจากเทคโนโลยีที่จำเป็นและก้าวก่ายเข้ามาในชีวิตประจำวัน และสิ่งนี้เกิดขึ้นในช่วงสิบหรือสิบห้าปีหลังจากอินเทอร์เน็ตเฟื่องฟูจริงๆ? ลองจินตนาการว่าจะเกิดอะไรขึ้นในอีกยี่สิบหรือห้าสิบปี
อินเทอร์เน็ตเป็นสิทธิมนุษยชน
กล่าวคือ อินเทอร์เน็ตได้ถูกเพิ่มเข้าไปในปฏิญญาสากลว่าด้วยสิทธิมนุษยชนแล้ว แต่นั่นยังไม่เพียงพอ
เรามีคณะทำงานด้านอินเทอร์เน็ตแล้ว เรามีมาตรฐาน เรายังมีกฎหมายความเป็นส่วนตัว ซึ่งส่วนใหญ่เป็นกฎหมายระดับชาติ แต่ไม่มีหน่วยงานของรัฐที่รับรองเสรีภาพทางดิจิทัลและการไม่แทรกแซงโดยฝ่ายเอกชนในความเป็นกลางของเว็บจนถึงระดับบุคคล เป็นไปได้ทีเดียวที่สิ่งนี้จะไม่เกิดขึ้น เนื่องจากพายมีขนาดใหญ่เกินไปและฉ่ำเกินไปที่จะปล่อยมือ
ถ้าคุณถามฉัน วิธีเดียวที่จะทำให้แน่ใจได้ว่าบางส่วนของเว็บไม่สามารถถูกแตะต้องได้อย่างแท้จริงคือการประดิษฐานไว้ในรูปแบบดิจิทัลแบบเจนีวา ฟังดูไร้เดียงสาและเพ้อฝัน แต่วันนี้ คุณคือความเมตตาของใครก็ตามที่ควบคุมอินเทอร์เน็ตของคุณ และวิธีที่พวกเขาตัดสินใจมอบอินเทอร์เน็ตให้คุณ
ข้อเสนอของฉัน
เอาล่ะ สุดท้ายคือข้อมูลทางเทคนิค
อย่างไรก็ตาม โครงสร้าง URL ส่วนใหญ่จะเป็น:machine | มนุษย์ | เครื่อง
ปัจจัยขับเคลื่อนได้แก่ ความเป็นกลาง ความปลอดภัย ความสมบูรณ์ ความสะดวกในการใช้งาน ความปลอดภัยและความสมบูรณ์ได้รับการแก้ไขค่อนข้างดีด้วยใบรับรองดิจิทัล แต่สามารถปรับปรุงได้ ความเป็นกลางฝังอยู่ในส่วนของมนุษย์ของสตริง URL และความสะดวกในการใช้งานจะอยู่ในส่วนแรกและส่วนสุดท้าย
เครื่องจักร ตอนที่ 1
อย่างที่คุณทราบ เบราว์เซอร์สมัยใหม่พยายามแยกส่วนเครื่องออกจากส่วนของมนุษย์ของสตริงที่อยู่เว็บอยู่แล้ว โดยไม่แสดงส่วน https:// และ/หรือ www ของที่อยู่ เนื่องจากเบราว์เซอร์เหล่านี้ไม่ค่อยให้บริการโปรโตคอลอื่นนอกจาก http หรือ https นี้ไม่ได้เลวร้ายเกินไป อย่างไรก็ตาม แนวคิด Secure-Not Secure ยังไม่ชัดเจนเพียงพอ เป็นเรื่องที่น่าตกใจและสบายใจ แต่ไม่ใช่ด้วยเหตุผลที่ถูกต้อง เราจะพูดถึงเรื่องนี้ในส่วนของมนุษย์
HTTP:// หรือ HTTPS:// ไม่มีความหมายสำหรับผู้คน 99% ซึ่งจะมีประโยชน์หากคุณส่งต่อสตริง URL ให้กับแอปพลิเคชันอื่นๆ เพื่อให้สามารถใช้โปรโตคอลที่ถูกต้องในการเชื่อมต่อได้ ยิ่งไปกว่านั้น เรามีความซ้ำซ้อนที่นี่จริงๆ ใบรับรองกำลังทำหน้าที่ยืนยันความปลอดภัยในการเชื่อมต่ออยู่แล้ว
คำตอบคือให้ลบคำนำหน้า (เครื่องส่วนที่ 1) ออกทั้งหมดและใช้เพียงใบรับรอง หรือด้วยเหตุผลเชิงสัญลักษณ์ ให้แทนที่คำนำหน้าด้วยบางอย่าง เช่น เว็บ ซึ่งเป็นตัวคั่นจริงและสิ่งที่ไม่ได้รับการตรวจสอบแยกจากกัน สิ่งนี้อาจเปิดพื้นที่ให้ใช้งานโปรโตคอลอื่นๆ ที่ไม่ใช่เว็บในอนาคต เช่น ความจริงเสมือน การสตรีมสื่อล้วน แชท และอื่นๆ และสอดคล้องกับหน้าภายในเฉพาะของเบราว์เซอร์ เช่น config, chrome เป็นต้น
ส่วนของมนุษย์
ชิ้นส่วนของมนุษย์จะต้องไม่ละเมิด ไม่ว่าที่อยู่ของหน้าเว็บไซต์จะเป็นเช่นไร จะต้องคงอยู่และต้องแสดงให้ผู้ใช้เห็นเสมอโดยไม่มีการรบกวนใดๆ ควรมีแนวทางปฏิบัติสำหรับ URL ที่ดีที่แอปพลิเคชันสามารถปฏิบัติตามได้ รวมถึงการจับคู่ชื่อโดเมน วัตถุประสงค์ ตรรกะ วันที่และชื่อ ซึ่งเซิร์ฟเวอร์บางแห่งทำ แต่นี่ก็เหมือนกับที่อยู่ทางกายภาพ We don't get to choose how streets are named, or how the home address is formed, and there are so many options worldwide. Same here.
This is part of what we are - and changing this language also breaks communication. There is no universal piece of objective information in a domain name, page title or similar. It's all down to what we want to write, and so, trying to tame this into submission is the wrong way forward.
But what about trust, integrity, spoofing?
If you mistype a site name, you could land on a wrong page. Or people ignore security warnings and give their credentials out on fake domains. Are there ways to work around these without breaking the human communication?
Well, certificates help - but they won't stop you going to a digitally signed site that is serving bogus content. Nor can they stop you from giving out your personal data. But on its own, technology CANNOT stop human stupidity or ignorance. It can be mitigated, but the unholy obsession with security degrades the user experience and breaks the Internet. So what to do?
I believe it is better to compromise on security than on user experience. The benefits outweigh the costs. There is crime out there, but largely, there's no breakdown of society and no anarchy. Because if we compromise on freedom for the sake of security, well, you know where this leads.
All that said, if the question is how to guarantee human users can differentiate between legitimate and fake sources supposedly serving identical content, beyond what we already have, then the answer lies in another question. If you give out two seemingly identical pages to a user, what is the one piece that separates them? The immediate answer is:URL. But if the user is not paying attention to the URL, what then?
The answer to that question could be a whitelist mechanism. In other words, if a user tries to input information on a page that is not recognized (in some way) as a known (read good) source, the browser could prompt the user with something like:You're currently on a page XYZ and about to fill in personal information, is this what you expect?
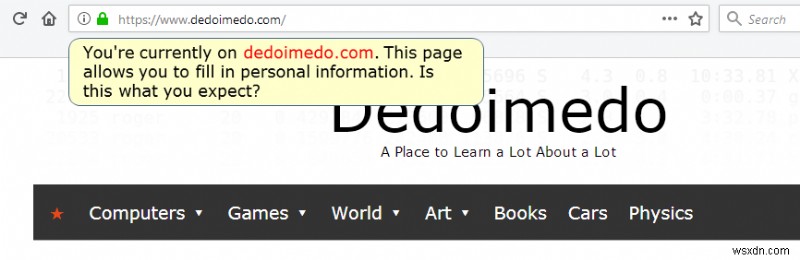
Crude illustration/mockup of what could be used to warn users when they are about to provide personal information on websites that are not "whitelisted" in some way.
People might still proceed and give away their data, but hey, nothing stops people from electrocuting themselves with toaster ovens in a bath tub, either. It is NOT about changing the URL - it's about helping people understand they are at the RIGHT address. In a way that does not break the user experience.
Now, let's talk about the machine string some more, shall we.
Machine part 2
The second part needs to be standardized. Today, servers and applications parse, mangle and structure URLs any which way they want. You can add all sorts of qualifies and key pair values, and end up with things like video autoplay, shopping cart contents, pre-filled forms, and more. In a way, this is lazy, convenient coding.
The standardization needs to be neutral - not dependent on how the browser or the site wants to present its information, because it's part of the problem today (including phishing and whatnot). I think that websites need to be forced to present a simple URL structure to the user that responds in a valid way.
The answer is:URL language. The same way browsers parse HTML and CSS, there could be a URL standard for the machine part. This could be a relatively small dictionary, and it would include somewhat STILL human-readable keys like (just a small subset of possible examples):
- unique-user-identifier - this would be a value that maps to an individual browser/user.
- javascript-status - if the client supports or runs Javascript.
- media-autoplay - whether media should play.
- media-timestamp - playback position for media.
- page - navigation element.
- Other similar keys.
And the rest would be ignored by the browser - provided all browsers adhere to the international standards and offer the same behavior and responses. Yes, the same way if you invent a new CSS class or HTML directive, and it does not exist and/or hasn't been properly declared, it gets ignored. The same way the remote application should ignore non-existent standard keys.
There must be special keys (flags), like dev=1 or debug=1 that would force the browser to interpret all provided machine parts and forward them to the server, which would also allow site devs/owners to troubleshoot their applications and offer full backward compatibility to everything we have on the market today. But then, the user could be prompted if such a combo is spotted in the URL address:
This site wants to run in dev mode. Do you want to allow it?
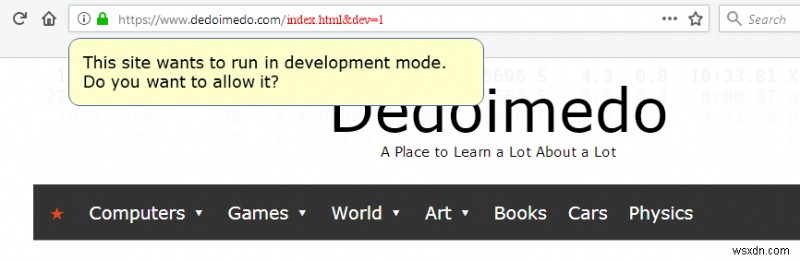
Crude illustration/mockup of what a standardized URL construct might be, with dev/debug flags.
This might enhance security too. Theoretically, the browsers could allow the user to block tracking via URL and not just on loaded pages. For instance, lots of email invitations and such come with a whole load of tracking, embedded in the URL. Privacy-conscious browsers could strip those away - or ask the user.
The URL is convenient for passing information to the application - but there's no real reason for this. When you click Buy on Amazon or PayPal, you don't see what happens. When you read Gmail, you don't see what happens. Buttons hide functionality, and it is not reflected in the URL.
To sum it up:the machine-part of the URL would contain a limited dictionary of standardized keys that would allow the information to be passed this way, but the rest would be ignored unless special flags like dev or debug are used, with the option to prompt the user. Enhanced security, enhanced privacy.
If ever defined, standardized and adopted, this will take time - an industry-wide effort. Now, is there a way to ignore forty years of legacy and existing implementations? The answer is, no bloody way. A change to the URL structure is something that will take decades. If you think IPv4 to IPv6 is complex, the URL journey will be even longer.
Finally, Quis custodiet ipsos custodes? Back to square one.
บทสรุป
The URL change is not important on its own - it is, but the technical part is relatively easy. The bigger issue is that, at the moment, people still have a fairly unrestricted access to the Web, largely due to the nerdy nature of the human-readable Web addresses. The URL is one of the old pieces of the Internet, and as such, it is mostly unfiltered and without abstractions. Once that goes away, we truly lose control of information. The world becomes a walled garden.
Google's general call to action makes sense, from the technical perspective, but the change could accidentally lead to something far bigger. Something sinister. Something sad. The death of the Internet as we know it. The ugly, cumbersome URL was invented in an age of innocence and exploration. As confusing as it is, it's the one piece that does not really belong to anyone. Any future change must preserve that neutrality.
If I were Google, I wouldn't worry about the URL. I would focus on why people don't want Google to be the arbiter of their Internet. Understand why people oppose you, regardless of the technical detail. Because, in the end, it's not about the URL. It's about freedom. Once that piece clicks into place, the technical solution will be trivial.
Food for thought.
ไชโย
