

โดย อเล็กซ์ นาดาลิน
ข้อมูลเบื้องต้นเกี่ยวกับความปลอดภัยของเว็บแอปพลิเคชัน
 _รูปภาพโดย [Unsplash](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel="noopener" target="_blank" title="">Liam Tucker บน
_รูปภาพโดย [Unsplash](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel="noopener" target="_blank" title="">Liam Tucker บน
คุณอาจคุ้นเคยกับการทำงานกับหนึ่งในเบราว์เซอร์ยอดนิยม เช่น Chrome, Firefox, Edge หรือ Safari แต่นั่นไม่ได้หมายความว่าไม่มีเบราว์เซอร์ที่แตกต่างกันออกไป
ตัวอย่างเช่น lynx เป็นเบราว์เซอร์แบบข้อความน้ำหนักเบาที่ทำงานจากบรรทัดคำสั่งของคุณ หัวใจสำคัญของ lynx คือหลักการเดียวกันกับที่คุณจะพบในเบราว์เซอร์ "กระแสหลัก" อื่นๆ ผู้ใช้ป้อนที่อยู่เว็บ (URL) เบราว์เซอร์จะดึงเอกสารและแสดงผล — ข้อแตกต่างเพียงอย่างเดียวคือความจริงที่ว่า lynx ไม่ได้ใช้เครื่องมือเรนเดอร์ภาพ แต่เป็นอินเทอร์เฟซแบบข้อความ ซึ่งทำให้เว็บไซต์เช่น Google มีลักษณะดังนี้:
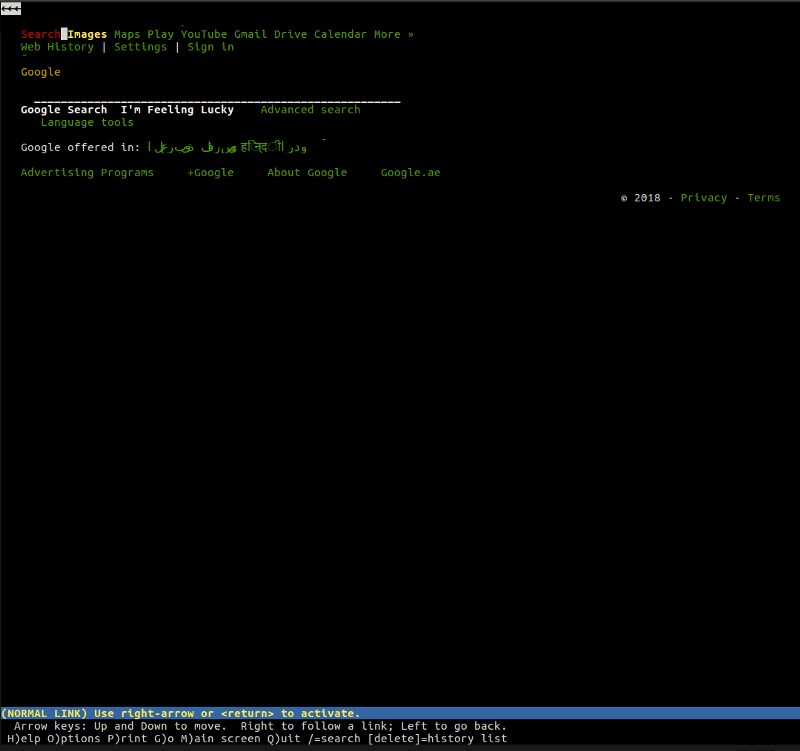
เราเข้าใจอย่างกว้างๆ ว่าเบราว์เซอร์ทำอะไรได้บ้าง แต่มาดูขั้นตอนที่แอปพลิเคชันอันชาญฉลาดเหล่านี้ทำเพื่อเรากันดีกว่า
เบราว์เซอร์ทำหน้าที่อะไร?
สรุปสั้นๆ ก็คือ งานของเบราว์เซอร์ส่วนใหญ่ประกอบด้วย:
- ความละเอียด DNS
- การแลกเปลี่ยน HTTP
- การแสดงผล
- ล้างและทำซ้ำ
ความละเอียด DNS
กระบวนการนี้ทำให้แน่ใจว่าเมื่อผู้ใช้ป้อน URL แล้ว เบราว์เซอร์จะรู้ว่าต้องเชื่อมต่อกับเซิร์ฟเวอร์ใด เบราว์เซอร์ติดต่อกับเซิร์ฟเวอร์ DNS เพื่อค้นหา 00 แปลเป็น 18 ที่อยู่ IP ที่เบราว์เซอร์สามารถเชื่อมต่อได้
แลกเปลี่ยน HTTP
เมื่อเบราว์เซอร์ได้ระบุเซิร์ฟเวอร์ที่จะตอบสนองคำขอของเราแล้ว เบราว์เซอร์จะเริ่มการเชื่อมต่อ TCP และเริ่ม การแลกเปลี่ยน HTTP . นี่ไม่ใช่อะไรเลยนอกจากเป็นวิธีสำหรับเบราว์เซอร์ในการสื่อสารกับเซิร์ฟเวอร์ถึงสิ่งที่ต้องการ และเพื่อให้เซิร์ฟเวอร์ตอบกลับ
HTTP เป็นเพียงชื่อของโปรโตคอลยอดนิยมสำหรับการสื่อสารบนเว็บ และเบราว์เซอร์ส่วนใหญ่จะพูดคุยผ่าน HTTP เมื่อสื่อสารกับเซิร์ฟเวอร์ การแลกเปลี่ยน HTTP เกี่ยวข้องกับไคลเอนต์ (เบราว์เซอร์ของเรา) ที่ส่งคำขอ และเซิร์ฟเวอร์ตอบกลับด้วยตอบกลับ .
ตัวอย่างเช่น หลังจากที่เบราว์เซอร์เชื่อมต่อกับเซิร์ฟเวอร์หลัง 25 สำเร็จแล้ว มันจะส่งคำขอที่มีลักษณะดังต่อไปนี้:
GET / HTTP/1.1Host: google.comAccept: */*
มาแยกย่อยคำขอทีละบรรทัด:
31 :ด้วยบรรทัดแรกนี้ เบราว์เซอร์จะขอให้เซิร์ฟเวอร์ดึงเอกสารที่ตำแหน่ง45โดยเสริมว่าคำขอที่เหลือจะเป็นไปตามโปรโตคอล HTTP/1.1 (อาจใช้57ก็ได้ หรือ60 )76 :นี่คือ ส่วนหัว HTTP เดียวที่บังคับใน HTTP/1.1 . เนื่องจากเซิร์ฟเวอร์อาจให้บริการหลายโดเมน (80,97 ฯลฯ) ลูกค้าที่นี่ระบุว่าคำขอนั้นมีไว้สำหรับโฮสต์เฉพาะนั้น108 :ส่วนหัวเพิ่มเติม โดยที่เบราว์เซอร์บอกเซิร์ฟเวอร์ว่าจะยอมรับการตอบกลับทุกประเภท เซิร์ฟเวอร์อาจมีทรัพยากรที่มีอยู่ในรูปแบบ JSON, XML หรือ HTML ดังนั้นจึงสามารถเลือกรูปแบบใดก็ได้ที่ต้องการ
รองจากเบราว์เซอร์ซึ่งทำหน้าที่เป็น ลูกค้า เสร็จสิ้นตามคำขอแล้ว ถึงเวลาที่เซิร์ฟเวอร์จะตอบกลับ นี่คือลักษณะการตอบกลับ:
HTTP/1.1 200 OKCache-Control: private, max-age=0Content-Type: text/html; charset=ISO-8859-1Server: gwsX-XSS-Protection: 1; mode=blockX-Frame-Options: SAMEORIGINSet-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly
<!doctype html><html">......</html>
โอ้โห นั่นเป็นข้อมูลที่ต้องแยกแยะมากมาย เซิร์ฟเวอร์แจ้งให้เราทราบว่าคำขอสำเร็จแล้ว (113 ) และเพิ่มส่วนหัวบางส่วนใน การตอบกลับ ตัวอย่างเช่น โฆษณาว่าเซิร์ฟเวอร์ใดที่ประมวลผลคำขอของเรา (121 ) 130 คืออะไร นโยบายการตอบสนองนี้และอื่นๆ
ตอนนี้คุณไม่จำเป็นต้องเข้าใจแต่ละบรรทัดในการตอบกลับ เราจะกล่าวถึงโปรโตคอล HTTP, ส่วนหัวของโปรโตคอล และอื่นๆ ต่อไปในชุดนี้
สำหรับตอนนี้ สิ่งที่คุณต้องเข้าใจก็คือไคลเอนต์และเซิร์ฟเวอร์กำลังแลกเปลี่ยนข้อมูลและพวกเขาแลกเปลี่ยนกันผ่าน HTTP
กำลังแสดงผล
สุดท้ายแต่ไม่ท้ายสุด การแสดงผล กระบวนการ เบราว์เซอร์จะดีแค่ไหนหากสิ่งเดียวที่จะแสดงให้ผู้ใช้เห็นคือรายชื่อตัวละครตลกๆ
<!doctype html><html">......</html>
ในร่างกาย ของการตอบกลับ เซิร์ฟเวอร์จะรวมการแสดงการตอบกลับตาม 149 ส่วนหัว ในกรณีของเรา ประเภทเนื้อหาถูกตั้งค่าเป็น 152 ดังนั้นเราจึงคาดหวังมาร์กอัป HTML ในการตอบกลับ ซึ่งเป็นสิ่งที่เราพบในส่วนเนื้อหา
นี่คือจุดที่เบราว์เซอร์โดดเด่นอย่างแท้จริง โดยแยกวิเคราะห์ HTML โหลดทรัพยากรเพิ่มเติมที่รวมอยู่ในมาร์กอัป (เช่น อาจมีไฟล์ JavaScript หรือเอกสาร CSS ที่จะดึงข้อมูล) และนำเสนอต่อผู้ใช้โดยเร็วที่สุด
อีกครั้งหนึ่ง ผลลัพธ์ที่ได้คือสิ่งที่โจทั่วๆ ไปสามารถเข้าใจได้
สำหรับรายละเอียดเพิ่มเติมของสิ่งที่เกิดขึ้นจริงเมื่อเรากด Enter ในแถบที่อยู่ของเบราว์เซอร์ ฉันขอแนะนำให้อ่าน "จะเกิดอะไรขึ้นเมื่อ..." ซึ่งเป็นความพยายามที่ซับซ้อนมากในการอธิบายกลไกเบื้องหลังกระบวนการ
เนื่องจากนี่เป็นซีรีส์ที่เน้นเรื่องความปลอดภัย ฉันจะบอกใบ้ถึงสิ่งที่เราเพิ่งเรียนรู้:ผู้โจมตีหาเลี้ยงชีพได้อย่างง่ายดายจากช่องโหว่ในการแลกเปลี่ยน HTTP และส่วนการเรนเดอร์ . ช่องโหว่และผู้ใช้ที่เป็นอันตรายแฝงตัวอยู่ที่อื่นเช่นกัน แต่วิธีการรักษาความปลอดภัยที่ดีกว่าในระดับเหล่านั้นช่วยให้คุณมีความก้าวหน้าในการปรับปรุงมาตรการรักษาความปลอดภัยของคุณ
ผู้ขาย
เบราว์เซอร์ที่ได้รับความนิยมสูงสุด 4 อันดับเป็นของผู้จำหน่ายที่แตกต่างกัน:
- Chrome โดย Google
- Firefox โดย Mozilla
- ซาฟารีโดย Apple
- Edge โดย Microsoft
นอกจากการต่อสู้กันเองเพื่อเพิ่มการเจาะตลาดแล้ว ผู้ขายยังมีส่วนร่วมซึ่งกันและกันเพื่อปรับปรุง มาตรฐานเว็บ ซึ่งเป็น "ข้อกำหนดขั้นต่ำ" ประเภทหนึ่งสำหรับเบราว์เซอร์
W3C เป็นหน่วยงานที่อยู่เบื้องหลังการพัฒนามาตรฐาน แต่ก็ไม่ใช่เรื่องแปลกที่เบราว์เซอร์จะพัฒนาคุณสมบัติของตัวเองจนกลายเป็นมาตรฐานเว็บในที่สุด และการรักษาความปลอดภัยก็ไม่มีข้อยกเว้น
ตัวอย่างเช่น Chrome 51 เปิดตัวคุกกี้ SameSite ซึ่งเป็นฟีเจอร์ที่อนุญาตให้เว็บแอปพลิเคชันกำจัดช่องโหว่บางประเภทที่เรียกว่า CSRF (จะมีรายละเอียดเพิ่มเติมในภายหลัง) ผู้จำหน่ายรายอื่นๆ ตัดสินใจว่านี่เป็นความคิดที่ดีและปฏิบัติตาม ส่งผลให้ SameSite เป็นมาตรฐานเว็บ:ณ ตอนนี้ Safari เป็นเบราว์เซอร์หลักเพียงตัวเดียวที่ไม่รองรับคุกกี้ SameSite

สิ่งนี้บอกเรา 2 สิ่ง:
- Safari ดูเหมือนจะไม่สนใจความปลอดภัยของผู้ใช้มากพอ (ล้อเล่น:คุกกี้ SameSite จะพร้อมใช้งานใน Safari 12 ซึ่งอาจเปิดตัวแล้วเมื่อคุณอ่านบทความนี้)
- การแก้ไขช่องโหว่ในเบราว์เซอร์เดียวไม่ได้หมายความว่าผู้ใช้ทั้งหมดของคุณจะปลอดภัย
จุดแรกคือช็อตที่ Safari (อย่างที่บอก ล้อเล่น!) ในขณะที่จุดที่สองนั้นสำคัญมาก เมื่อพัฒนาเว็บแอปพลิเคชัน เราไม่เพียงแต่ต้องแน่ใจว่าพวกมันดูเหมือนกันในเบราว์เซอร์ต่างๆ แต่ยังต้องแน่ใจว่าผู้ใช้ของเราได้รับการปกป้องในลักษณะเดียวกันบนแพลตฟอร์มต่างๆ
กลยุทธ์ของคุณในการรักษาความปลอดภัยของเว็บควรแตกต่างกันไปตามสิ่งที่ผู้จำหน่ายเบราว์เซอร์อนุญาตให้เราทำได้ . ปัจจุบันนี้ เบราว์เซอร์ส่วนใหญ่สนับสนุนชุดคุณลักษณะเดียวกันและแทบจะไม่เบี่ยงเบนไปจากแผนงานทั่วไป แต่กรณีเช่นที่กล่าวมาข้างต้นยังคงเกิดขึ้น และเป็นสิ่งที่เราต้องคำนึงถึงเมื่อกำหนดกลยุทธ์ด้านความปลอดภัยของเรา
ในกรณีของเรา หากเราตัดสินใจว่าจะบรรเทาการโจมตี CSRF ผ่านคุกกี้ SameSite เท่านั้น เราควรตระหนักว่าเรากำลังทำให้ผู้ใช้ Safari ของเราตกอยู่ในความเสี่ยง และผู้ใช้ของเราก็ควรทราบเช่นกัน
สุดท้ายแต่ไม่ท้ายสุด คุณควรจำไว้ว่าคุณสามารถตัดสินใจได้ว่าจะรองรับเวอร์ชันของเบราว์เซอร์หรือไม่ การรองรับเบราว์เซอร์แต่ละเวอร์ชันนั้นคงเป็นไปไม่ได้ (ลองนึกถึง Internet Explorer 6 สิ) โดยทั่วไปแล้ว การตรวจสอบให้แน่ใจว่าเบราว์เซอร์หลักไม่กี่เวอร์ชันล่าสุดได้รับการสนับสนุนถือเป็นการตัดสินใจที่ดี หากคุณไม่ได้วางแผนที่จะเสนอการป้องกันบนแพลตฟอร์มใดแพลตฟอร์มหนึ่ง โดยทั่วไปขอแนะนำให้แจ้งให้ผู้ใช้ของคุณทราบ
เคล็ดลับมือโปร :คุณไม่ควรสนับสนุนให้ผู้ใช้ใช้เบราว์เซอร์ที่ล้าสมัยหรือสนับสนุนพวกเขาอย่างจริงจัง แม้ว่าคุณอาจได้ใช้มาตรการป้องกันที่จำเป็นทั้งหมดแล้ว แต่นักพัฒนาเว็บรายอื่นก็อาจไม่ได้ทำ สนับสนุนให้ผู้ใช้ใช้เบราว์เซอร์หลักเวอร์ชันล่าสุดที่รองรับ
ผู้ขายหรือข้อผิดพลาดมาตรฐาน?
ความจริงที่ว่าผู้ใช้โดยเฉลี่ยเข้าถึงแอปพลิเคชันของเราผ่านไคลเอนต์บุคคลที่สาม (เบราว์เซอร์) เพิ่มระดับทางอ้อมอีกระดับหนึ่งสู่ประสบการณ์การท่องเว็บที่ชัดเจนและปลอดภัย:ตัวเบราว์เซอร์เองอาจมีช่องโหว่ด้านความปลอดภัย
โดยทั่วไปแล้วผู้ขายจะให้รางวัล (หรือที่เรียกว่า ค่าหัวข้อบกพร่อง ) สำหรับนักวิจัยด้านความปลอดภัยที่สามารถค้นหาช่องโหว่บนเบราว์เซอร์ได้ จุดบกพร่องเหล่านี้ไม่ได้เชื่อมโยงกับการใช้งานของคุณ แต่ขึ้นอยู่กับวิธีที่เบราว์เซอร์จัดการกับความปลอดภัยด้วยตัวมันเอง
ตัวอย่างเช่น โปรแกรมรางวัล Chrome ช่วยให้วิศวกรความปลอดภัยติดต่อทีมรักษาความปลอดภัยของ Chrome เพื่อรายงานช่องโหว่ที่พวกเขาพบ หากช่องโหว่เหล่านี้ได้รับการยืนยัน จะมีการออกแพตช์ โดยทั่วไปประกาศคำแนะนำด้านความปลอดภัยจะเผยแพร่สู่สาธารณะ และผู้วิจัยจะได้รับรางวัล (โดยปกติจะเป็นทางการเงิน) จากโปรแกรม
บริษัทต่างๆ เช่น Google ลงทุนเงินทุนจำนวนค่อนข้างดีในโปรแกรม Bug Bounty ของตน เนื่องจากช่วยให้พวกเขาดึงดูดนักวิจัยโดยสัญญาว่าจะได้รับผลประโยชน์ทางการเงินหากพวกเขาพบปัญหาใดๆ กับแอปพลิเคชัน
ในโปรแกรม Bug Bounty ทุกคนชนะ:ผู้ขายจัดการเพื่อปรับปรุงความปลอดภัยของซอฟต์แวร์ และนักวิจัยจะได้รับค่าตอบแทนสำหรับการค้นพบของพวกเขา เราจะหารือเกี่ยวกับโปรแกรมเหล่านี้ในภายหลัง เนื่องจากฉันเชื่อว่าโครงการริเริ่ม Bug Bounty สมควรได้รับส่วนของตนเองในแนวความปลอดภัย
Jake Archibald เป็นผู้สนับสนุนนักพัฒนาซอฟต์แวร์ของ Google ซึ่งเพิ่งค้นพบช่องโหว่ที่ส่งผลกระทบต่อเบราว์เซอร์มากกว่าหนึ่งตัว เขาบันทึกความพยายามของเขา วิธีที่เขาติดต่อกับผู้ขายต่างๆ และปฏิกิริยาของพวกเขาในบล็อกโพสต์ที่น่าสนใจที่ฉันขอแนะนำให้คุณอ่าน
เบราว์เซอร์สำหรับนักพัฒนา
ถึงตอนนี้ เราควรเข้าใจแนวคิดที่เรียบง่ายแต่ค่อนข้างสำคัญ:เบราว์เซอร์เป็นเพียงไคลเอ็นต์ HTTP ที่สร้างขึ้นสำหรับนักท่องอินเทอร์เน็ตทั่วไป .
พวกมันมีประสิทธิภาพมากกว่าไคลเอนต์ HTTP เปล่าของแพลตฟอร์มอย่างแน่นอน (ลองนึกถึง 162 ของ NodeJS เป็นตัวอย่าง) แต่ท้ายที่สุดแล้ว สิ่งเหล่านี้เป็น "เพียง" วิวัฒนาการตามธรรมชาติของไคลเอนต์ HTTP ที่เรียบง่ายกว่า
ในฐานะนักพัฒนา ไคลเอ็นต์ HTTP ที่เราเลือกน่าจะเป็น cURL โดย Daniel Stenberg หนึ่งในโปรแกรมซอฟต์แวร์ยอดนิยมที่นักพัฒนาเว็บใช้เป็นประจำทุกวัน ช่วยให้เราสามารถแลกเปลี่ยน HTTP ได้ทันทีโดยการส่งคำขอ HTTP จากบรรทัดคำสั่งของเรา:
$ curl -I localhost:8080
HTTP/1.1 200 OKserver: ecstatic-2.2.1Content-Type: text/htmletag: "23724049-4096-"2018-07-20T11:20:35.526Z""last-modified: Fri, 20 Jul 2018 11:20:35 GMTcache-control: max-age=3600Date: Fri, 20 Jul 2018 11:21:02 GMTConnection: keep-alive
ในตัวอย่างข้างต้น เราได้ขอเอกสารที่ 176 และเซิร์ฟเวอร์ภายในเครื่องตอบกลับสำเร็จ
แทนที่จะทิ้งเนื้อหาของการตอบกลับไปที่บรรทัดคำสั่ง เราใช้ 180 ตั้งค่าสถานะซึ่งบอก cURL ว่าเราสนใจเฉพาะส่วนหัวการตอบกลับเท่านั้น ก้าวไปข้างหน้าหนึ่งก้าว เราสามารถสั่งให้ cURL ดัมพ์ข้อมูลเพิ่มเติมเล็กน้อย รวมถึงคำขอจริงที่ดำเนินการ เพื่อให้เราสามารถดูการแลกเปลี่ยน HTTP ทั้งหมดนี้ได้ดียิ่งขึ้น ตัวเลือกที่เราต้องใช้คือ 195 (คำกริยา):
$ curl -I -v localhost:8080* Rebuilt URL to: localhost:8080/* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 8080 (#0)> HEAD / HTTP/1.1> Host: localhost:8080> User-Agent: curl/7.47.0> Accept: */*>< HTTP/1.1 200 OKHTTP/1.1 200 OK< server: ecstatic-2.2.1server: ecstatic-2.2.1< Content-Type: text/htmlContent-Type: text/html< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""etag: "23724049-4096-"2018-07-20T11:20:35.526Z""< last-modified: Fri, 20 Jul 2018 11:20:35 GMTlast-modified: Fri, 20 Jul 2018 11:20:35 GMT< cache-control: max-age=3600cache-control: max-age=3600< Date: Fri, 20 Jul 2018 11:25:55 GMTDate: Fri, 20 Jul 2018 11:25:55 GMT< Connection: keep-aliveConnection: keep-alive
<* Connection #0 to host localhost left intact
ข้อมูลเดียวกันเกือบทั้งหมดมีอยู่ในเบราว์เซอร์กระแสหลักผ่านทาง DevTools
ดังที่เราได้เห็นแล้วว่าเบราว์เซอร์เป็นเพียงไคลเอนต์ HTTP ที่ซับซ้อนเท่านั้น แน่นอนว่าพวกเขาเพิ่มฟีเจอร์จำนวนมหาศาล (ลองนึกถึงการจัดการข้อมูลรับรอง บุ๊กมาร์ก ประวัติ ฯลฯ) แต่ความจริงก็คือพวกมันเกิดมาเป็นไคลเอนต์ HTTP ของมนุษย์ นี่เป็นสิ่งสำคัญ เนื่องจากในกรณีส่วนใหญ่ คุณไม่จำเป็นต้องมีเบราว์เซอร์เพื่อทดสอบความปลอดภัยของแอปพลิเคชันเว็บของคุณ เนื่องจากคุณเพียงแค่ "ม้วนงอ" และดูการตอบสนอง
สิ่งสุดท้ายที่ฉันอยากจะชี้ให้เห็นก็คือ อะไรก็ได้ที่เป็นเบราว์เซอร์ได้ . หากคุณมีแอปพลิเคชันมือถือที่ใช้ API ผ่านโปรโตคอล HTTP แอปนั้นก็คือเบราว์เซอร์ของคุณ ซึ่งบังเอิญเป็นแอปที่ปรับแต่งได้สูงที่คุณสร้างขึ้นเอง ซึ่งเป็นแอปที่เข้าใจเฉพาะการตอบสนอง HTTP ประเภทใดประเภทหนึ่งเท่านั้น (จาก API ของคุณเอง)
เข้าสู่โปรโตคอล HTTP
ดังที่เราได้กล่าวไปแล้ว การแลกเปลี่ยน HTTP และการแสดงผล ระยะต่างๆ นั้นเป็นช่วงที่เราจะพูดถึงเป็นส่วนใหญ่ เนื่องจากพวกมันให้พาหะการโจมตีจำนวนมากที่สุด สำหรับผู้ใช้ที่เป็นอันตราย
ในบทความถัดไป เราจะเจาะลึกเกี่ยวกับโปรโตคอล HTTP และพยายามทำความเข้าใจว่าเราควรใช้มาตรการใดเพื่อรักษาความปลอดภัยของการแลกเปลี่ยน HTTP
เผยแพร่ครั้งแรกที่ odino.org (29 กรกฎาคม 2018)
_คุณสามารถติดตามฉันได้ทาง Twitter - ยินดีรับฟัง!_ ?
เรียนรู้การเขียนโค้ดฟรี หลักสูตรโอเพ่นซอร์สของ freeCodeCamp ช่วยให้ผู้คนมากกว่า 40,000 คนได้งานในตำแหน่งนักพัฒนา เริ่มต้น
