
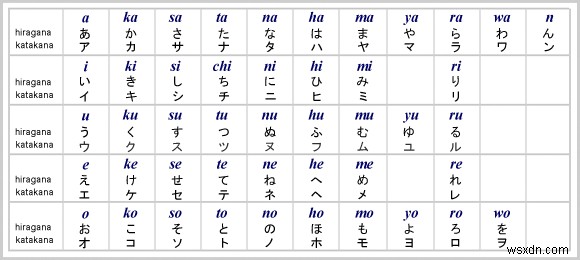
ตั้งแต่การสร้าง Convolutional Neural Network ไปจนถึงการปรับใช้ OCR กับ iOS
แรงจูงใจสำหรับโครงการ ✍️ ??
ในขณะที่ฉันกำลังเรียนรู้วิธีสร้างโมเดลการเรียนรู้เชิงลึกสำหรับชุดข้อมูล MNIST เมื่อไม่กี่เดือนที่ผ่านมา ฉันก็ได้สร้างแอป iOS ที่จดจำอักขระที่เขียนด้วยลายมือได้
เพื่อนของฉัน Kaichi Momose กำลังพัฒนาแอพการเรียนรู้ภาษาญี่ปุ่น Nukon เขาบังเอิญต้องการมีลักษณะที่คล้ายคลึงกันในนั้น จากนั้นเราจึงร่วมมือกันสร้างสิ่งที่ซับซ้อนกว่าการจดจำตัวเลข:OCR (Optical Character Recognition/Reader) สำหรับอักขระภาษาญี่ปุ่น (ฮิระงะนะและคะตะคะนะ)
ในระหว่างการพัฒนา Nukon ไม่มี API สำหรับการรู้จำลายมือในภาษาญี่ปุ่น เราไม่มีทางเลือกอื่นนอกจากต้องสร้าง OCR ของเราเอง ประโยชน์ที่ใหญ่ที่สุดที่เราได้รับจากการสร้างตั้งแต่เริ่มต้นคือการทำงานของเราแบบออฟไลน์ ผู้ใช้สามารถอยู่ลึกเข้าไปในภูเขาได้โดยไม่ต้องใช้อินเทอร์เน็ต และยังคงเปิด Nukon เพื่อรักษากิจวัตรประจำวันในการเรียนภาษาญี่ปุ่น เราได้เรียนรู้มากมายตลอดกระบวนการ แต่ที่สำคัญกว่านั้น เราตื่นเต้นที่จะจัดส่งผลิตภัณฑ์ที่ดีขึ้นสำหรับผู้ใช้ของเรา
บทความนี้จะอธิบายขั้นตอนการสร้าง OCR ภาษาญี่ปุ่นสำหรับแอป iOS สำหรับผู้ที่ต้องการสร้างภาษา/สัญลักษณ์อื่น สามารถปรับแต่งได้โดยเปลี่ยนชุดข้อมูล
โดยไม่ต้องกังวลใจอีกต่อไป มาดูกันว่าจะครอบคลุมอะไรบ้าง:
ส่วนที่ 1️⃣:รับชุดข้อมูลและประมวลผลภาพล่วงหน้า
ตอนที่ 2️⃣:สร้างและฝึกอบรม CNN (Convolutional Neural Network)
ส่วนที่ 3️⃣:ผสานรวมโมเดลที่ผ่านการฝึกอบรมเข้ากับ iOS
รับชุดข้อมูลและอิมเมจพรีโพรเซส ?
ชุดข้อมูลมาจากฐานข้อมูลอักขระ ETL ซึ่งมีรูปภาพอักขระและสัญลักษณ์ที่เขียนด้วยลายมือจำนวนเก้าชุด เนื่องจากเรากำลังจะสร้าง OCR สำหรับฮิระงะนะ ETL8 จึงเป็นชุดข้อมูลที่เราจะใช้
ในการรับรูปภาพจากฐานข้อมูล เราจำเป็นต้องมีฟังก์ชันตัวช่วยที่อ่านและจัดเก็บรูปภาพใน .npz รูปแบบ
import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
เมื่อเราได้ hiragana.npz บันทึกแล้ว มาเริ่มประมวลผลภาพด้วยการโหลดไฟล์และ ปรับขนาดภาพใหม่เป็น 32x32 พิกเซล . นอกจากนี้เรายังจะเพิ่มการเสริมข้อมูลเพื่อสร้างภาพพิเศษที่หมุนและซูม เมื่อโมเดลของเราได้รับการฝึกฝนเกี่ยวกับภาพตัวละครจากหลากหลายมุม โมเดลของเราจะปรับให้เข้ากับลายมือของผู้คนได้ดีขึ้น
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)สร้างและฝึกอบรมซีเอ็นเอ็น ?️
มาถึงส่วนที่สนุกแล้ว! เราจะใช้ Keras เพื่อสร้าง CNN (Convolutional Neural Network) สำหรับโมเดลของเรา เมื่อฉันสร้างโมเดลครั้งแรก ฉันได้ทดลองกับไฮเปอร์พารามิเตอร์และปรับมันหลายครั้ง ชุดค่าผสมด้านล่างให้ความแม่นยำสูงสุดแก่ฉัน — 98.77% อย่าลังเลที่จะเล่นกับพารามิเตอร์ต่างๆ ด้วยตัวคุณเอง
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))ต่อไปนี้คือเคล็ดลับบางประการหากคุณพบว่า ประสิทธิภาพของโมเดลไม่เป็นที่น่าพอใจ ในขั้นตอนการฝึก:
แบบจำลอง กำลังพอดี
ซึ่งหมายความว่าโมเดลไม่ได้มีลักษณะทั่วไปที่ดี อ่านบทความนี้สำหรับคำอธิบายที่เข้าใจง่าย
วิธีตรวจจับการใส่มากเกินไป :acc (ความแม่นยำ) ขึ้นต่อ แต่ val_acc (ความถูกต้องในการตรวจสอบ) ตรงกันข้ามในกระบวนการฝึกอบรม
วิธีแก้ไขบางอย่างสำหรับการใส่มากเกินไป :การทำให้เป็นมาตรฐาน (เช่น การออกกลางคัน) การเพิ่มข้อมูล การปรับปรุงคุณภาพของชุดข้อมูล
จะทราบได้อย่างไรว่าโมเดลนั้นเป็น "การเรียนรู้"
โมเดลไม่เรียนรู้ถ้า val_loss (การสูญเสียการตรวจสอบ) เพิ่มขึ้นหรือไม่ลดลงตามการฝึกอบรมที่ดำเนินต่อไป
ใช้ TensorBoard — ให้การแสดงภาพสำหรับประสิทธิภาพของแบบจำลองเมื่อเวลาผ่านไป ขจัดความยุ่งยากในการดูทุกยุคสมัยและเปรียบเทียบค่าต่างๆ อย่างต่อเนื่อง
เนื่องจากเราพอใจกับความถูกต้องแล้ว เราจึงนำเลเยอร์ที่หลุดออกมาก่อนที่จะบันทึกน้ำหนักและการกำหนดค่าโมเดลเป็นไฟล์
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
งานเดียวที่เหลือก่อนที่จะย้ายไปยังส่วน iOS คือการแปลง hiraganaModel.h5 เป็นโมเดล CoreML
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
The output_labels เป็นผลลัพธ์ที่เป็นไปได้ทั้งหมดที่เราจะได้เห็นใน iOS ในภายหลัง
เกร็ดน่ารู้:หากคุณเข้าใจภาษาญี่ปุ่น คุณอาจรู้ว่าลำดับของอักขระที่ส่งออกไม่ตรงกับ "ลำดับตัวอักษร" ของฮิระงะนะ เราต้องใช้เวลาพอสมควรกว่าจะรู้ว่ารูปภาพใน ETL8 นั้นไม่อยู่ใน "ลำดับตัวอักษร" (ขอบคุณ Kaichi ที่ทำให้เข้าใจในเรื่องนี้) ชุดข้อมูลนี้รวบรวมโดยมหาวิทยาลัยในญี่ปุ่น…?
ผสานรวม Trained Model เข้ากับ iOS หรือไม่
ในที่สุดเราก็รวบรวมทุกอย่างเข้าด้วยกัน! ลากและวาง hiraganaModel.mlmodel ในโครงการ Xcode จากนั้นคุณจะเห็นสิ่งนี้:
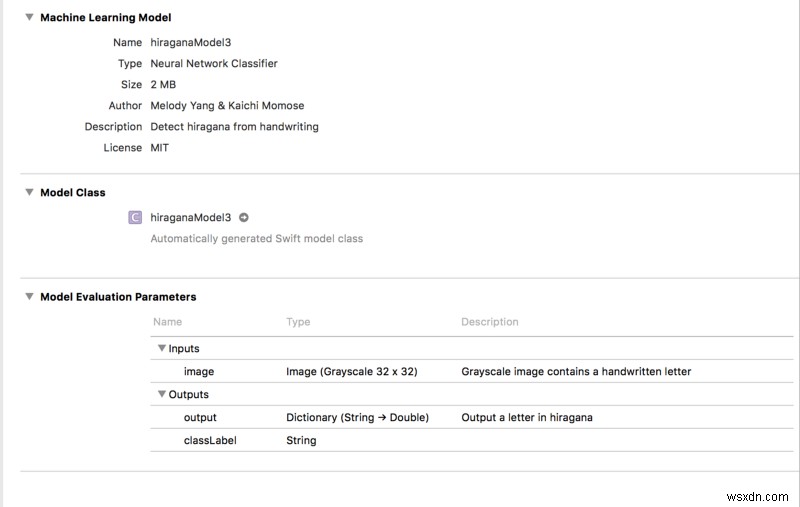
หมายเหตุ :Xcode จะสร้างพื้นที่ทำงานเมื่อคัดลอกโมเดล เราจำเป็นต้องเปลี่ยนสภาพแวดล้อมการเขียนโค้ดของเราเป็นพื้นที่ทำงาน มิฉะนั้น โมเดล ML จะไม่ทำงาน!
เป้าหมายสุดท้ายคือการให้โมเดลฮิรางานะของเราทำนายตัวละครโดยส่งผ่านรูปภาพ เพื่อให้บรรลุสิ่งนี้ เราจะสร้าง UI แบบง่าย เพื่อให้ผู้ใช้สามารถเขียนได้ และเราจะจัดเก็บการเขียนของผู้ใช้ในรูปแบบภาพ สุดท้ายนี้ เราดึงค่าพิกเซลของรูปภาพและป้อนให้กับโมเดลของเรา
มาทำทีละขั้นตอนกัน:
- “วาด” ตัวอักษรบน
UIViewด้วยUIBezierPath
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
strokeLayer.strokeColor สามารถเป็นสีใดก็ได้ อย่างไรก็ตาม สีพื้นหลังของ canvas ต้องเป็น ดำ . แม้ว่ารูปภาพการฝึกของเราจะมีพื้นหลังสีขาวและลายเส้นสีดำ แต่โมเดล ML นั้นไม่ตอบสนองได้ดีกับรูปภาพที่ป้อนด้วยสไตล์นี้
2. เปิด UIView เป็น UIImage และดึงค่าพิกเซลด้วย CVPixelBuffer
ในส่วนขยายมีฟังก์ชันตัวช่วยสองแบบ ร่วมกันจะแปลภาพเป็นบัฟเฟอร์พิกเซลซึ่งเทียบเท่ากับค่าพิกเซล อินพุต width และ height ทั้งสองควรเป็น 32 เนื่องจากขนาดอินพุตของโมเดลของเราคือ 32 x 32 พิกเซล
ทันทีที่เรามี pixelBuffer เราสามารถเรียก model.prediction() แล้วส่งผ่าน pixelBuffer . แล้วเราไปกันเลย! เราสามารถมีผลลัพธ์เป็น classLabel !
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
3. แสดงผลด้วย UIAlertController
ขั้นตอนนี้เป็นทางเลือกทั้งหมด ตามที่แสดงใน GIF ในตอนเริ่มต้น ฉันได้เพิ่มตัวควบคุมการแจ้งเตือนเพื่อแจ้งผลลัพธ์
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}โว้ว! เราเพิ่งสร้าง OCR ที่พร้อมสำหรับการสาธิต (และ App-Store-ready)! ??
สรุป ?
การสร้าง OCR ไม่ได้ยากขนาดนั้น อย่างที่คุณเห็น บทความนี้ประกอบด้วยขั้นตอนและปัญหา และฉันพบปัญหาขณะสร้างโครงการนี้ ฉันสนุกกับกระบวนการสร้างโค้ด Python จำนวนมากที่พิสูจน์ได้ด้วยการเชื่อมต่อกับ iOS และฉันตั้งใจจะทำเช่นนั้นต่อไป
ฉันหวังว่าบทความนี้จะให้ข้อมูลที่เป็นประโยชน์แก่ผู้ที่ต้องการสร้าง OCR แต่ไม่รู้ว่าจะเริ่มต้นจากที่ใด
คุณสามารถค้นหา ซอร์สโค้ด ที่นี่
โบนัส :หากคุณสนใจที่จะทดลองกับอัลกอริธึมแบบตื้น อ่านต่อไป!
[ไม่บังคับ] ฝึกด้วยอัลกอริทึมแบบตื้น ?
ก่อนที่จะใช้งาน CNN ไคจิกับฉันได้ทดสอบอัลกอริธึมแมชชีนเลิร์นนิงอื่น ๆ เพื่อดูว่าพวกเขาสามารถทำงานให้สำเร็จได้หรือไม่ (และช่วยเราประหยัดค่าใช้จ่ายในการคำนวณด้วย!) เราเลือก KNN และ Random Forest
ในการประเมินประสิทธิภาพ เราได้กำหนดความแม่นยำพื้นฐานไว้ที่ 1/71 =0.014
เราคิดว่าคนที่ไม่มีความรู้ภาษาญี่ปุ่นอาจมีโอกาส 1.4% ในการเดาตัวละครที่ถูกต้อง
ดังนั้น โมเดลนี้จะทำได้ดีหากความแม่นยำเกิน 1.4% ลองดูว่าเป็นกรณีหรือไม่ ?
เคเอ็นเอ็น
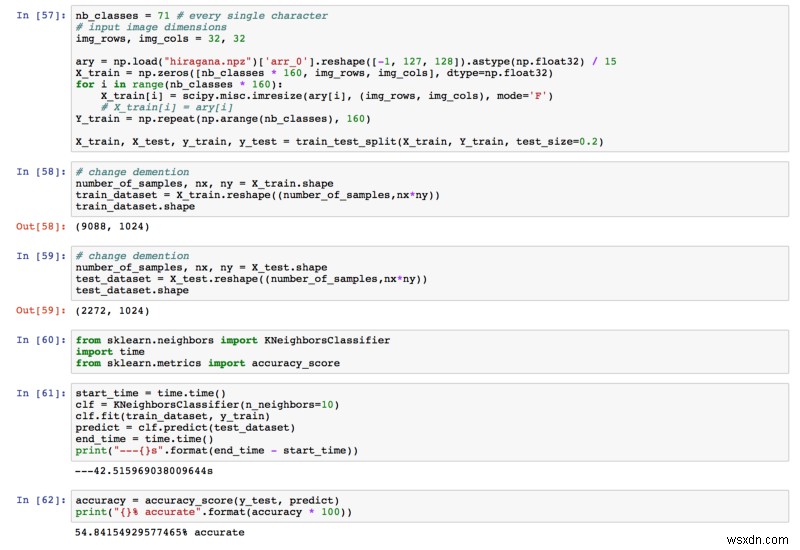
ความแม่นยำสุดท้ายที่เราได้รับคือ 54.84% สูงกว่า 1.4% มากแล้ว!
ป่าสุ่ม
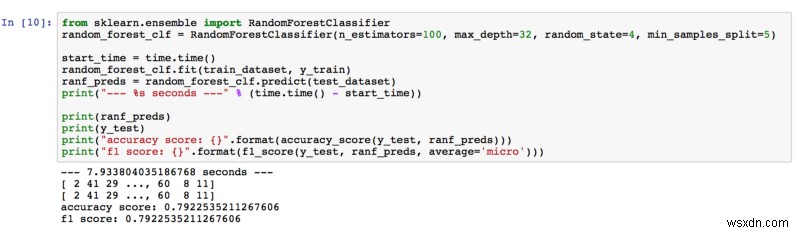
ความแม่นยำ 79.23% ดังนั้น Random Forest จึงเกินความคาดหมายของเรา ขณะปรับไฮเปอร์พารามิเตอร์ เราได้ผลลัพธ์ที่ดีขึ้นโดยการเพิ่มจำนวนตัวประมาณและความลึกของต้นไม้ เราคิดว่าการมีต้นไม้มากขึ้น (ตัวประมาณ) ในป่าหมายถึงการเรียนรู้คุณลักษณะต่างๆ ในภาพมากขึ้น ยิ่งต้นไม้ยิ่งลึก ยิ่งเรียนรู้จากคุณสมบัติต่างๆ มากเท่านั้น
หากคุณสนใจที่จะเรียนรู้เพิ่มเติม ฉันพบบทความนี้ที่กล่าวถึงการจัดประเภทรูปภาพด้วย Random Forest
ขอขอบคุณที่อ่าน ยินดีรับฟังความคิดเห็นและข้อเสนอแนะ!
