
ปัญญาประดิษฐ์เติบโตขึ้นในช่วงหลายปีที่ผ่านมา และ Facebook ได้รวมการพัฒนาและแนวคิดของ AI เข้ากับคุณสมบัติที่หลากหลาย รวมถึงกล้องและการวิเคราะห์ฟีดข่าว ปัญญาประดิษฐ์ควรจะทำให้ชีวิตของผู้คนง่ายขึ้นโดยการปรับการใช้ทรัพยากรให้เกิดประโยชน์สูงสุดและทำให้ประสบการณ์ของพวกเขาง่ายขึ้น ในโซเชียลมีเดีย AI ถูกนำมาใช้เพื่อแนะนำผู้ใช้ให้รู้จักกับสื่อการสื่อสารและการโต้ตอบยุคใหม่ ดังนั้นจึงช่วยให้พวกเขาเชื่อมต่อกับคนที่ตนรักได้อย่างชาญฉลาด แต่อีกครั้ง AI ของ Facebook ล้มเหลวอย่างน่าสังเวชในการกรองฟีดข่าว ปกป้องความเป็นส่วนตัวของผู้ใช้ และละเมิดจริยธรรมโดยปล่อยให้คำพูดแสดงความเกลียดชังแพร่กระจายอย่างเสรีบนแพลตฟอร์มโซเชียลมีเดียที่ใหญ่ที่สุดในโลก ในวันที่ 2 ของงาน F8 Keynote ของ Facebook AI และความปลอดภัยของ AI ครอบคลุมงานส่วนใหญ่ นำโดย Mike Schroepfer CTO ของ Facebook มาดูกันว่า Facebook มีแผนจะทำอะไรกับ AI ในอนาคต
ปัญญาประดิษฐ์บน Facebook

การใช้ปัญญาประดิษฐ์หลักของ Facebook คือการตรวจสอบฟีดข่าว เทคโนโลยี AI ถูกนำมาใช้เพื่อให้แน่ใจว่าเนื้อหาใด ๆ ที่แสดงถึงคำพูดแสดงความเกลียดชัง ความรุนแรง การเหยียดเชื้อชาติ ข้อมูลทางการเมือง และสิ่งอื่น ๆ ที่ละเมิดค่านิยมของ Facebook และรวมถึงกฎหมายทั่วโลก AI ยังใช้เพื่ออ่านการค้นหา การตั้งค่า และการอัปเดตของผู้ใช้ ซึ่งทำให้ Facebook สามารถดึงดูดผู้ใช้ด้วยประเภทโฆษณาที่เหมาะสม และกรองคำแนะนำของเพื่อนและโพสต์ของผู้สนับสนุนเพื่อเพิ่มในฟีดของพวกเขา นี่คือสิ่งที่สนับสนุนโมเดลธุรกิจของ Facebook
วิธีที่ Facebook ใช้ AI

Facebook ใช้การประมวลผลภาษาธรรมชาติขั้นสูง (NLP) เพื่อฝึก AI และช่วยให้เข้าใจความแตกต่างระหว่างเนื้อหาประเภทต่างๆ ในทุกรูปแบบ NLP ใช้การฝังหลายภาษาที่ช่วยให้ AI เข้าใจเนื้อหาในภาษาต่างๆ และลบเนื้อหาที่เป็นอันตรายออกจากฟีดข่าวทั่วโลก
ความยากลำบาก

แม้จะมีการฝังหลายภาษา แต่ก็เป็นเรื่องยากมากที่ Facebook AI จะจับภาพเนื้อหาทั้งหมด มีภาษามากกว่าหกพันภาษาในโลกที่เขียนและพูดโดยผู้คนที่มีภูมิหลังทางชาติพันธุ์เกือบเท่ากัน การฝึกอบรม AI ด้วยความรู้ความเข้าใจภาษาที่กว้างขวางเช่นนี้เป็นเรื่องยากมาก AI ที่ใช้โดย Facebook เรียนรู้จากข้อมูลที่ติดป้ายกำกับที่อัปโหลดในระบบและเรียนรู้จากมัน ข้อมูลมีจำนวนมหาศาลและการติดฉลากเพื่อการฝึกอบรม AI อย่างมีประสิทธิภาพนั้นเป็นงานหนักสำหรับนักพัฒนา และยิ่งได้รับข้อมูลจำนวนมากเท่าใด ช่องว่างสำหรับข้อผิดพลาดของมนุษย์ก็ยิ่งมีมากขึ้นเท่านั้น
การเรียนรู้รูปแบบข้อมูลรูปภาพและวิดีโอเป็นอีกหนึ่งปัญหาที่น่าปวดหัว

Facebook เติบโตขึ้นอย่างกว้างขวางเมื่อพูดถึงการทำความเข้าใจเกี่ยวกับภาพถ่าย โดยเฉพาะอย่างยิ่งหลังจากการเข้าซื้อกิจการของ Instagram Facebook ได้ฝังแนวคิดของ Computer Vision และ Panoptic Feature Pyramid Network (Panoptic FPN) เพื่อให้เข้าใจสถาปัตยกรรมของภาพทุกด้าน Panoptic FPN เติบโตขึ้นจนสามารถเข้าใจโครงสร้างภาพใดๆ ควบคู่ไปกับพื้นหลังของภาพ ซึ่งทำให้ AI ของ Facebook สามารถกรองเนื้อหาที่เป็นอันตรายบนเว็บในรูปแบบของภาพได้มากขึ้น
แต่การทำความเข้าใจเนื้อหาวิดีโอเป็นข้อเสียเปรียบที่สำคัญสำหรับ AI ของ Facebook และการเรียนรู้ของเครื่องล้มเหลวในหลายระดับเมื่อต้องหลีกเลี่ยงคำพูดแสดงความเกลียดชังและความรุนแรงผ่านวิดีโอที่อัปโหลดและแชร์บน Facebook แม้ว่า Facebook จะอ้างว่าได้พยายามใช้แฮชแท็กเป็นป้ายกำกับข้อมูลเพื่อช่วยให้ AI เรียนรู้จากเนื้อหาวิดีโอเช่นกัน หรืออย่างน้อยก็กำหนดความเกี่ยวข้องของข้อมูลจากข้อมูลที่ได้รับจากแฮชแท็ก อย่างไรก็ตาม มันไม่ได้ขึ้นอยู่กับเครื่องหมาย
AI ของ Facebook ล้มเหลวตรงไหน

Facebook AI ทำงานบน การเรียนรู้ภายใต้การดูแล กรอบการทำงาน โดย AI เรียนรู้จากชุดข้อมูลที่นักพัฒนามนุษย์ติดป้ายไว้ ในช่วงไม่กี่ปีที่ผ่านมา ประชากรบน Facebook มีจำนวนเกือบถึง 1 ใน 3 ของประชากรทั้งหมดบนโลก ซึ่งหมายความว่าข้อมูลส่วนเกินในรูปแบบลายลักษณ์อักษร เสียง และวิดีโอจะถูกอัปโหลดบน Facebook ภายในเสี้ยววินาที ในขณะเดียวกัน AI มีหน้าที่ประเมินเนื้อหานี้แบบเรียลไทม์ เนื่องจากมีมนุษย์เข้ามาเกี่ยวข้อง การวิจัยอย่างละเอียดจึงสามารถนำไปสู่การติดฉลากข้อมูลหรือข้อบกพร่องในชุดข้อมูลที่ AI อ่านได้ ซึ่งอาจนำไปสู่ข้อผิดพลาดในการตรวจจับเนื้อหา และ AI อาจไม่ทำงานในลักษณะเดียวกันสำหรับเนื้อหาของผู้ใช้ทั้งหมดที่อัปโหลดบนฟีดข่าว
AI ที่ดูแลตนเอง:แผนสำรองของ Facebook ในการลบเนื้อหาที่เป็นอันตราย
ในวันที่ 2 ของ F8 2019 CTO Mike Schroepfer ประกาศว่า Facebook เป็นผู้นำในการวิจัยและพัฒนาในการออกแบบระบบที่สนับสนุนการเรียนรู้ด้วยตนเอง ระบบ AI ดังกล่าวจะสามารถเข้าใจข้อมูลได้โดยไม่ต้องมีชุดข้อมูลและการติดฉลาก จึงทำให้ระบบพึ่งพาตนเองและตระหนักรู้ในตนเอง AI ที่ดูแลตนเองสามารถป้อนข้อมูลปริมาณมหาศาลได้ อย่างไรก็ตาม ไม่จำเป็นว่าข้อมูลทั้งหมดจะต้องเป็นข้อมูลดิบและจะถูกป้อนตามที่เป็นอยู่ ในการออกแบบโมดูลการฝึกอบรมสำหรับเครื่อง AI นั้น ผู้ใช้จำเป็นต้องลบข้อมูลบางส่วนออกจากเนื้อหาหรือข้อมูล จากนั้นให้เครื่องรับรู้ถึงบิตที่หายไปด้วยตัวเอง การฝึกอบรมประเภทนี้จะช่วยให้เครื่องเพิ่มความเกี่ยวข้องของเนื้อหาที่ดำเนินการบน Facebook และช่วยให้สามารถพิจารณาเนื้อหาดังกล่าวกับนโยบายและกฎหมายในลักษณะที่ดีขึ้น
การฝึกอบรมที่ครอบคลุมสำหรับ AI:การทำให้ธุรกิจ AR ของ Facebook มีจริยธรรมและปลอดภัยมากขึ้น
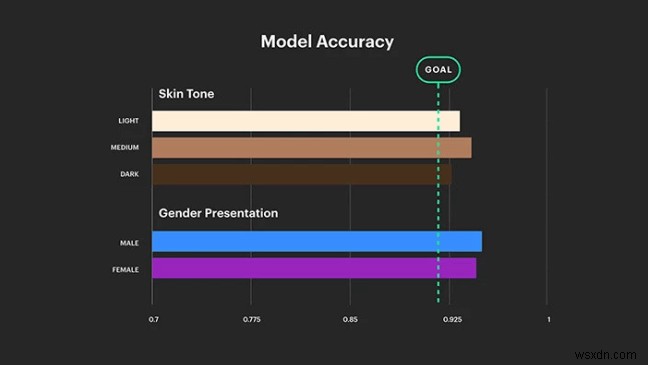
ด้วยพอร์ทัลและ Spark AR Facebook วางแผนการลงทุนครั้งใหญ่ในธุรกิจเทคโนโลยี AR และ VR อย่างไรก็ตาม เทคโนโลยีอัจฉริยะต้องการ AI อัจฉริยะเพื่อมอบประสบการณ์การใช้งานที่ดี Portal Cameras ได้รับการออกแบบตามแนวคิดความจริงเสริมและเป็นกุญแจสำคัญในการแนะนำการจดจำใบหน้ายุคถัดไปและแพลตฟอร์มวิดีโอแชทอัจฉริยะ แต่พบว่ากล้องและชุดหูฟัง AR/VR เหล่านี้มีอคติในการทำความเข้าใจคำสั่งจากผู้คน พบว่าเลนส์สามารถแยกความแตกต่างระหว่างโทนสีผิวและเพศได้ ในขณะที่ไม่สามารถให้ประสบการณ์การใช้งานที่คล้ายคลึงกันแก่ผู้ใช้ทุกคน นอกจากนี้ยังส่งเสริมการเลือกปฏิบัติทางเชื้อชาติและเพศ หลังจากกระแสวิพากษ์วิจารณ์ไปทั่วโลก นี่คือสิ่งสุดท้ายที่ Facebook ต้องการ

ดังนั้น Facebook จึงประกาศว่าจะสร้าง AI แบบรวมเพื่อกำจัดปัญหานี้ สำหรับสิ่งนี้ พวกเขามี Lade Obamehinti ชาวอเมริกันเชื้อสายไนจีเรีย ซึ่งเป็นผู้นำแผนกกลยุทธ์ของส่วน AR/VR ของ Facebook นักวิจัยจะทดสอบกล้อง AI ในการตั้งค่าแสงต่างๆ กับคนที่มีโทนสีผิวต่างกัน เพื่อให้แน่ใจว่า AI มีความครอบคลุมที่ฝังอยู่ในโมดูลการเรียนรู้โดยไม่มีข้อผิดพลาดหรือความผันผวนใดๆ
เหตุใด Facebook จึงจำเป็นต้องทำงานกับ AI

Facebook ปล่อยให้ข้อมูลของผู้คนถูกละเมิดและข้อมูลนั้นถูกขายให้กับนักการตลาดและผู้โฆษณาภายใต้จมูกของทางการ จากนั้น Facebook ก็ประสบปัญหาไฟกระชากและรหัสผ่านของผู้ใช้หลายล้านคนก็ถูกเปิดเผยในรูปแบบข้อความล้วน จากนั้น ระดับความสามารถของ AI และความไม่รู้ของนักพัฒนาก็เกินขึ้น เมื่อชายคนหนึ่งในไครสต์เชิร์ช นิวซีแลนด์ สตรีมวิดีโอสดบน Facebook ขณะที่เขายิงคนในมัสยิดจนเสียชีวิตหลายครั้ง วิดีโอถูกสตรีมและอยู่ในฟีดข่าว FB เป็นระยะเวลานานพอให้ผู้คนดาวน์โหลดได้
Facebook ประสบปัญหาฟันเฟืองจำนวนมากและสูญเสียเงินนับพันล้านในกระบวนการนี้ นี่คือเหตุผลที่ Mark Zuckerberg ใช้คำว่า "ความเป็นส่วนตัว" ล้านครั้งในวันที่ 1 ของงาน F8 ในปีนี้ Facebook สูญเสียอำนาจและก้าวข้ามขีดจำกัดความอดทนของทั้งผู้ใช้และผู้กำหนดนโยบายทั่วโลก หาก Facebook ไม่ได้รับ AI เพื่อทำความเข้าใจเนื้อหา อาจเผชิญกับการปิดตัวลงในอีกไม่กี่ปีข้างหน้า
นั่นอาจเป็นเหตุผลเดียวที่ทำให้ Facebook มี CTO บนเวทีตลอดทั้งวัน ทำให้ผู้ใช้มั่นใจด้วยการแจ้งให้พวกเขาทราบว่า Facebook พยายามทำอะไรเพื่อปกป้องพวกเขาในทุกวิถีทาง
การย้ายครั้งนี้จะสำเร็จหรือไม่

Zuckerberg ยอมรับตัวเองว่าการเปลี่ยนแปลงเหล่านี้จะไม่เกิดขึ้นในชั่วข้ามคืน Facebook อาจต้องเปลี่ยนรูปแบบธุรกิจเพื่อกำจัดข้อบกพร่องใน AI อย่างสมบูรณ์และลบเนื้อหาที่แสดงความเกลียดชังออกจาก Facebook อย่างถาวร การวิจัยยังดำเนินอยู่ และการพัฒนาโมดูลการฝึกอบรมดังกล่าวยังอยู่ในช่วงเริ่มต้น อย่างไรก็ตาม บอกได้คำเดียวว่า Facebook เริ่มเอาจริงเอาจังกับเรื่องดังกล่าวแล้ว และหากยังคงมีความสำคัญ บริษัทอาจสามารถส่งมอบสัญญาที่เจ้าหน้าที่ได้ให้ไว้ใน F8 ปีนี้
ถึงเวลาแล้วที่ Facebook จะมาพร้อมกับเทคโนโลยีใหม่และโมดูลการฝึกอบรม AI ที่ดีขึ้นเพื่อทำความเข้าใจเนื้อหาบน FB โดยเฉพาะอย่างยิ่งเนื่องจากผู้ใช้บน Facebook และแพลตฟอร์มและผลิตภัณฑ์อื่น ๆ ที่เป็นเจ้าของทั้งหมดมีแนวโน้มที่จะเพิ่มขึ้นในแต่ละวัน เนื่องจาก Facebook กลายเป็นโฆษณาและมีอิทธิพลต่อพอร์ทัลพร้อมกับบริการแชทและการสื่อสาร ข้อมูลบนเซิร์ฟเวอร์จึงเกินขีดจำกัดการจัดหมวดหมู่และการติดฉลากข้อมูล ความเคลื่อนไหวเหล่านี้ของ Facebook Inc. จะช่วยบริษัทได้หรือไม่? คำตอบนี้อาจไม่ง่ายเกินไป จนถึงตอนนี้ สิ่งที่เราทำได้คือรอดูว่านาย Zuckerberg จะปฏิบัติตามคำพูดของเขาอย่างไร
