
การสร้างแบบเสริมการดึงข้อมูลควรจะเพิ่มแบบจำลองภาษาขนาดใหญ่ด้วยความรู้ภายนอก สามารถทำงานอย่างสวยงามในการสาธิต:ชุดข้อมูลขนาดเล็กที่ดูแลจัดการ การสืบค้นที่ชัดเจน และงบประมาณเวลาในการตอบสนองที่ไม่จำกัด นำไปสู่คำตอบที่มีความรู้และมีเหตุผลซึ่งผู้ใช้เชื่อว่าถูกต้อง อย่างไรก็ตาม หลายทีมพบว่าเมื่อพวกเขาปรับใช้แอปพลิเคชัน RAG กับผู้ใช้ ประสิทธิภาพจะลดลง การสืบค้นมีความคลุมเครือ คลังข้อมูลขยายออก คุณภาพการเรียกข้อมูลลดลง บอลลูนเวลาแฝง และระบบเริ่มจางหายไปในความแม่นยำ ที่แย่กว่านั้นคือเทคนิคการประเมินที่ไม่ดีจะซ่อนจุดที่ระบบเริ่มล้มเหลวจนกว่าผู้ใช้จะบ่น บทความนี้สำรวจสาเหตุที่ระบบ RAG จำนวนมากล้มเหลวในการผลิต เราดึงมาจากการวิจัยล่าสุดและแนวทางอุตสาหกรรม เรากำหนดประเด็นปัญหาเกี่ยวกับคุณภาพการดึงข้อมูล การแลกเปลี่ยนเวลาแฝง การดริฟท์แบบฝัง และช่องว่างในการประเมินเป็นลิงก์ในห่วงโซ่ของโหมดความล้มเหลว แต่ละลิงก์ในห่วงโซ่นี้จะต้องได้รับการพิจารณาเพื่อสร้างระบบ RAG การผลิตที่มีประสิทธิภาพ
ประเด็นสำคัญ
- ความล้มเหลวของ RAG ส่วนใหญ่เริ่มต้นจากการดึงข้อมูล ไม่ใช่การสร้าง เมื่อระบบดึงข้อมูลหลักฐานที่ไม่สมบูรณ์ ไม่เกี่ยวข้อง หรือมีการจัดอันดับไม่ดี แม้แต่ LLM ที่แข็งแกร่งก็ยังให้คำตอบที่อ่อนแอ
- การดึงข้อมูลที่ดีขึ้นจำเป็นต้องมีทางเลือกทางวิศวกรรมที่ดีกว่า การแบ่งส่วนการรับรู้โดเมน การดึงข้อมูลแบบไฮบริด และการจัดอันดับใหม่จะถูกนำเสนอเป็นเทคนิคหลักในการปรับปรุงความเกี่ยวข้องและลดความล้มเหลวในการเรียกข้อมูลโดยไม่โต้ตอบ
- เวลาแฝงอย่างรวดเร็วกลายเป็นคอขวดในการผลิต การเพิ่ม top_k ที่ใหญ่ขึ้น การจัดอันดับใหม่ บริบทที่ยาว และขั้นตอนการเรียกข้อมูลเพิ่มเติมอาจปรับปรุงการเรียกคืน แต่ก็อาจทำให้ระบบช้าเกินไปสำหรับผู้ใช้จริง
- การฝังการเบี่ยงเบนจะลดประสิทธิภาพลงอย่างเงียบๆ เมื่อเวลาผ่านไป การเปลี่ยนแปลงในแบบจำลองการฝัง คอลเลกชันเอกสาร และคำศัพท์ของผู้ใช้สามารถเปลี่ยนพฤติกรรมการดึงข้อมูลได้ ดังนั้นการกำหนดเวอร์ชันและความสามารถในการสังเกตจึงมีความจำเป็น
- คุณภาพคำตอบสุดท้ายเพียงอย่างเดียวไม่เพียงพอสำหรับการประเมิน ทีมต้องการเมตริกการดึงข้อมูลและการสร้างแยกกัน ชุดการทดสอบที่สมจริง การตรวจสอบอย่างต่อเนื่อง และความสามารถของระบบในการละเว้นเมื่อหลักฐานอ่อนหรือขาดหายไป
ความล้มเหลวเนื่องจากคุณภาพการดึงข้อมูลต่ำ
คุณภาพการดึงข้อมูลต่ำเป็นสาเหตุหนึ่งที่พบบ่อยที่สุดของความล้มเหลวของระบบ RAG เมื่อนำไปใช้กับการใช้งานจริง นักพัฒนามักตำหนิ LLM สำหรับคำตอบที่ผิด/ไม่ดี อย่างไรก็ตาม ข้อผิดพลาดมักเกิดขึ้นเร็วกว่าในขั้นตอนการผลิต หากระบบไม่สามารถดึงหลักฐานที่สมบูรณ์หรือเกี่ยวข้องได้ หรือจัดอันดับหลักฐานได้ไม่ดี แม้แต่แบบจำลองที่ดีที่สุดก็ไม่น่าจะสร้างการตอบสนองที่น่าเชื่อถือได้ คุณภาพการดึงข้อมูลควรถือเป็นข้อกังวลด้านวิศวกรรมชั้นหนึ่งมากกว่าเป็นขั้นตอนเบื้องหลัง
ความล้มเหลวส่วนใหญ่เกิดขึ้นก่อนที่ LLM จะเห็นข้อความค้นหา
ไปป์ไลน์มาตรฐานฝังการสืบค้นของผู้ใช้ ดึงเอกสาร top-k จากร้านค้าเวกเตอร์ และส่งไปยัง LLM ลูกศรทุกลูกในไปป์ไลน์นั้นเป็นจุดที่อาจเกิดความล้มเหลว
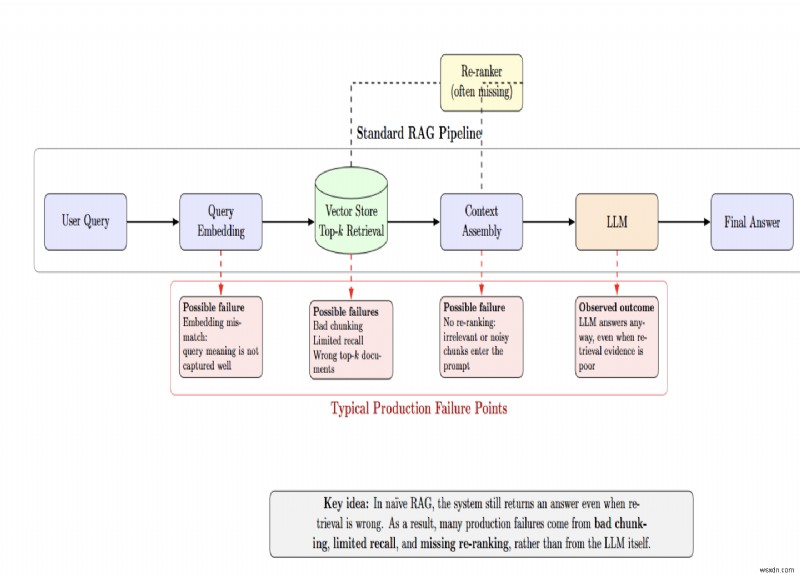
Naïve RAG ปิดบังความล้มเหลวเหล่านี้ เนื่องจากระบบจะให้คำตอบ ไม่ว่าการดึงข้อมูลจะผิดหรือไม่ก็ตาม ปัญหาด้านการผลิตจำนวนมากเกิดขึ้นจากกลยุทธ์การแยกชิ้นส่วนที่ไม่ดี การเรียกคืนอย่างจำกัด และการขาดการจัดอันดับใหม่ แทนที่จะเป็นข้อบกพร่องของ LLM
ความผิดพลาดแบบเป็นก้อนจะทำให้เกิดความล้มเหลวแบบเงียบๆ
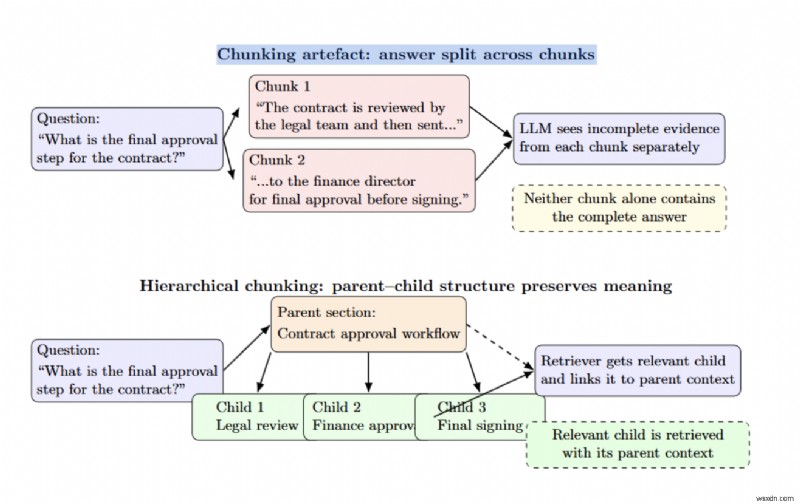
ขนาดก้อนส่งผลต่อความแม่นยำ/การเรียกคืน — ชิ้นที่ใหญ่กว่าจะให้บริบทมากกว่าโดยมีความเกี่ยวข้องน้อยกว่า ในขณะที่ชิ้นที่เล็กกว่าจะให้ความแม่นยำมากกว่า แต่สูญเสียข้อมูลโดยรอบ การแบ่งส่วนตามลำดับชั้น (หลัก-รอง) จะช่วยแก้ปัญหาการแลกเปลี่ยนนี้โดยการจัดเก็บทั้งส่วนเป็นส่วนหลักและดึงข้อมูลเฉพาะส่วนย่อยที่เกี่ยวข้องที่มีขนาดเล็กกว่าเท่านั้น
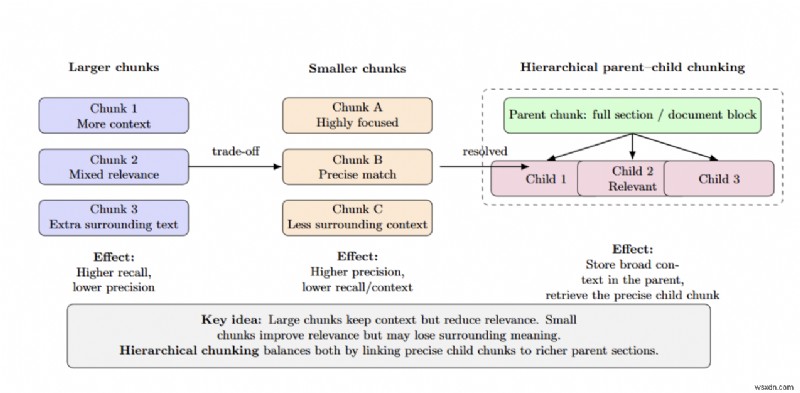
การทดสอบภายในของ NVIDIA บนชุดการนำเสนอของมหาวิทยาลัยพบว่าการแบ่งส่วนตามลำดับชั้นช่วยเพิ่มความแม่นยำของคำตอบจาก 61% ด้วยชิ้นส่วนที่มีขนาดคงที่เป็น 89% สิ่งสำคัญคือต้องเลือกขนาดก้อนข้อมูลที่เหมาะสมโดยยังคงคำนึงถึงขอบเขตของโครงสร้างและใช้การแยก DomainAware เมื่อเป็นไปได้
การดึงข้อมูลแบบไฮบริดและการจัดอันดับใหม่
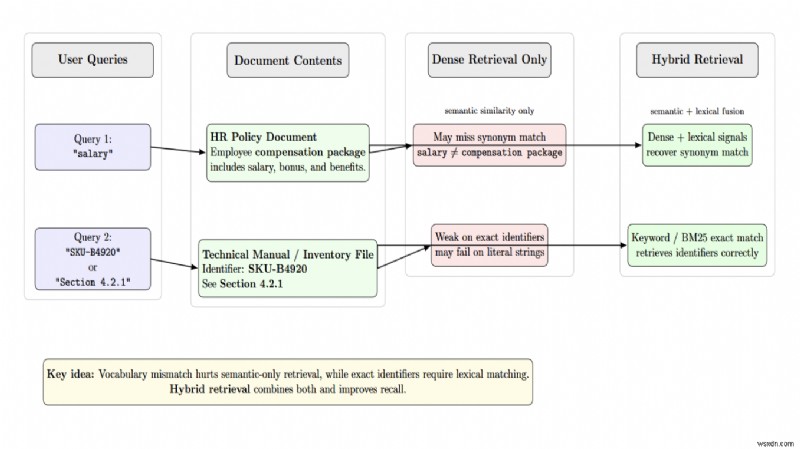
การดึงข้อมูลแบบหนาแน่นเพียงอย่างเดียวนั้นดีในเรื่องความคล้ายคลึงทางความหมาย แต่ขาดตัวระบุที่แน่ชัด การค้นหาคำหลักที่แท้จริงนั้นไวต่อคำที่ตรงทั้งหมด แต่ล้มเหลวในการถอดความความหมาย ระบบการดึงข้อมูลแบบไฮบริดจะทำการดึงข้อมูลแบบหนาแน่น (เวกเตอร์) และการดึงข้อมูลแบบกระจาย (BM25/คำหลัก) พร้อมกัน จากนั้นจึงหลอมรวมผลลัพธ์ด้วยการรวมอันดับซึ่งกันและกัน
ระบบการดึงข้อมูลแบบไฮบริดช่วยแก้ปัญหาคำศัพท์ที่ไม่ตรงกันโดยการรวมสัญญาณความคล้ายคลึงทางความหมายเข้ากับสัญญาณการจับคู่คำศัพท์ การให้คะแนนคู่ผู้สมัครอีกครั้งด้วยการจัดอันดับใหม่ (ตัวเข้ารหัสแบบไขว้) หลังจากการหลอมรวมจะปรับปรุงการเรียกคืน โดยพื้นฐานแล้ว ผู้จัดอันดับใหม่จะจัดลำดับเอกสารที่ดึงมาใหม่ เพื่อให้เฉพาะเอกสารที่เกี่ยวข้องมากที่สุดเท่านั้นที่จะทำให้เป็นบริบทที่ LLM ตรวจสอบ วิธีนี้จะช่วยประหยัดขีดจำกัดของโทเค็นและหลีกเลี่ยงการบรรจุบริบทในขณะที่ปรับปรุงการเรียกคืน LLM
เมตริกการดึงข้อมูลต้องได้รับการตรวจสอบแยกกัน
ทีมมีแนวโน้มที่จะวัดคุณภาพคำตอบตั้งแต่ต้นทางถึงปลายทางเท่านั้น การดึงข้อมูลนั้นมีตัวชี้วัดที่คุณสามารถใช้ได้:precision@k (ส่วนใดของชิ้นส่วนที่ดึงมามีความเกี่ยวข้อง ), การเรียกคืน@k (ส่วนใดของชิ้นส่วนที่เกี่ยวข้องที่คุณดึงมา ) ค่าเฉลี่ยอันดับซึ่งกันและกัน (ชิ้นแรกที่เกี่ยวข้องสูงแค่ไหน ) และกำไรสะสมที่มีส่วนลดแบบปกติ (อันดับโดยรวมของคุณดีแค่ไหน)

หากคุณไม่วัดผลเหล่านี้ คุณจะไม่รู้ว่าความล้มเหลวนั้นมาจากการดึงข้อมูลที่ไม่ดีหรือตัวสร้างที่ไม่ดี แบบสอบถามทดสอบและชุดข้อมูลสีทองจะช่วยให้คุณสามารถประเมินแบบออฟไลน์ได้ หากคุณติดตามเมตริกเหล่านี้จากคำค้นหาจริง คุณจะแสดงการถดถอยในการใช้งานจริงได้
การวินิจฉัยความล้มเหลวในการเรียกข้อมูลด้วยตัวอย่าง
ข้อความค้นหาที่ไม่ชัดเจนและคำศัพท์ที่ไม่ตรงกันมักทำให้การเรียกข้อมูลไม่ถูกต้อง ผู้ใช้สามารถค้นหาคำว่า “เงินเดือน” ในขณะที่เอกสารอ้างอิงถึง “แพ็คเกจค่าตอบแทน” การฝังแบบหนาแน่นอาจล้มเหลวในการจดจำคำพ้องความหมาย ในขณะที่การดึงข้อมูลแบบไฮบริดจะแก้ไขปัญหานี้ อีกกรณีหนึ่งคือการจับคู่แบบตรงทั้งหมด เช่น ตัวระบุ คำค้นหาสำหรับ “SKU‑B4920” หรือ “ส่วนที่ 4.2.1” จำเป็นต้องมีการจับคู่คำศัพท์ทุกประการ
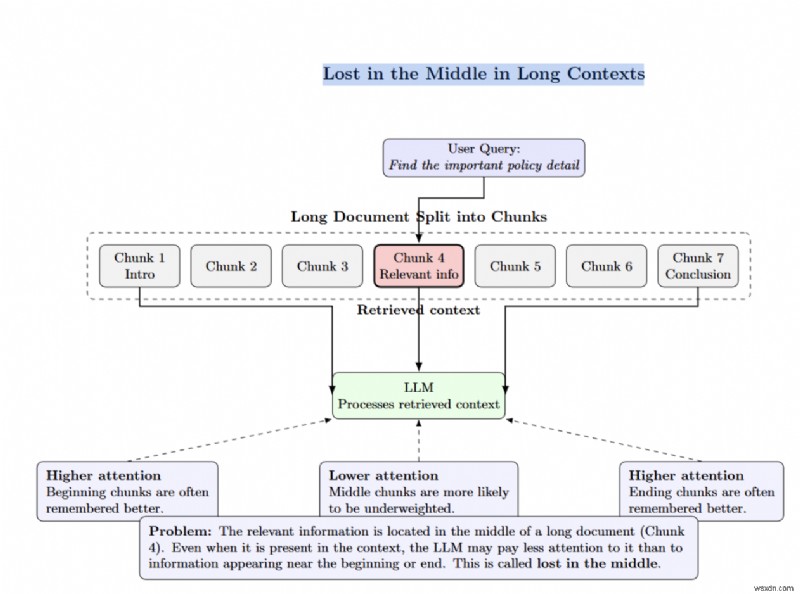
“หลงทางกลาง” เกิดขึ้นเมื่อข้อมูลที่เกี่ยวข้องถูกฝังลึกลงในเอกสารที่มีความยาว LLM จะมีน้ำหนักน้อยกว่าโทเค็นในส่วนตรงกลาง
สิ่งประดิษฐ์ที่เป็นก้อนเกิดขึ้นเมื่อคำตอบถูกแบ่งออกเป็นสองส่วน ดังนั้นจึงไม่มีคำตอบที่สมบูรณ์ การแบ่งส่วนตามลำดับชั้นจะช่วยบรรเทาปัญหานี้โดยการเชื่อมต่อโหนดหลักและโหนดย่อย
ความล้มเหลวเนื่องจากเวลาแฝงระเบิดในระบบจริง
เวลาแฝงเป็นหนึ่งในสาเหตุหลักที่ทำให้ระบบ RAG ที่ทำงานในการสาธิตประสบปัญหาในการผลิต เนื่องจากไปป์ไลน์การดึงข้อมูลมีความซับซ้อนมากขึ้น เวลาตอบสนองจึงเพิ่มขึ้นอย่างรวดเร็วและบังคับให้ทีมต้องแลกคุณภาพคำตอบกับการใช้งาน
การแลกเปลี่ยนการเรียกค้น-เวลาแฝง
ทีมผู้ผลิตมักจะต้องสร้างสมดุลระหว่างคุณภาพการดึงข้อมูลและงบประมาณเวลาแฝง ทุกสิ่งที่เพิ่มเวลาตอบสนอง (ขยายใหญ่ขึ้นด้วย top_k การเพิ่มการดึงข้อมูลแบบไฮบริด การจัดอันดับใหม่ หรือการรันโมเดลบริบทแบบยาว) จะช่วยลดงบประมาณเหล่านั้น การแลกเปลี่ยนเป็นเรื่องยากเป็นพิเศษ เนื่องจากผู้ใช้คาดหวังคำตอบที่ตอบสนอง และการบูรณาการระดับองค์กรมาพร้อมกับงบประมาณเวลาแฝงที่เข้มงวด อย่างไรก็ตาม ตามที่ Cornell และ NVIDIA แสดงให้เห็นผลงานล่าสุด RAG มีค่าใช้จ่ายด้านเวลาแฝงที่มีนัยสำคัญ การเรียกข้อมูลบ่อยเกินไปอาจเพิ่มความแม่นยำได้ แต่เพิ่มเวลาแฝงจากต้นทางถึงปลายทางเป็นเกือบ 30 วินาที ซึ่งสูงเกินไปสำหรับการใช้งานจริง
รุ่นมักจะมีอิทธิพลเหนือ แต่การดึงกลับมีความสำคัญ
การเปรียบเทียบด้วย RAGPerf แสดงให้เห็นว่า การสร้างมักจะเป็นส่วนสำคัญของไปป์ไลน์ RAG แบบข้อความเท่านั้น . การเลือก LLM ที่เล็กลงสามารถลดเวลาแฝงได้อย่างมากโดยไม่ทำให้คุณภาพคำตอบลดลง หากคุณภาพการดึงข้อมูลยังคงอยู่ ไปป์ไลน์ต่อเนื่องหลายรูปแบบ (PDF และการดึงข้อมูลรูปภาพ) มีความต้องการในการประมวลผลจำนวนมาก ส่วนหนึ่งเนื่องมาจากการจัดอันดับใหม่และโมเดลข้ามโมดัลที่เกี่ยวข้อง เวลาแฝงในการเรียกข้อมูลอาจเพิ่มขึ้นเมื่อฐานข้อมูลเวกเตอร์ช้าหรือไม่อนุญาตให้มีการค้นหาพร้อมกัน อย่างไรก็ตาม แม้จะมีการค้นหาที่รวดเร็ว การจัดอันดับใหม่ก็สามารถครอบงำเวลาแฝงทั้งหมดสำหรับปริมาณงาน RAG จำนวนมากได้
เวลาในการตอบสนอง ต้นทุน และกรอบเวลาบริบท
บางทีมพยายามแก้ปัญหาการเรียกคืนโดยเพิ่ม top_k หรืออัดเอกสารให้มากขึ้นในบริบทของ LLM การศึกษาพบว่าสิ่งนี้มีผลตรงกันข้าม ยิ่งคุณเพิ่มเอกสารในพรอมต์มากเท่าไร LLM ก็จะยิ่งสามารถเรียกคืนข้อมูลที่ถูกต้องได้น้อยลงเท่านั้น การจัดอันดับการเรียกข้อมูลใหม่ช่วยแก้ปัญหานี้ได้โดยการดึงเอกสารจำนวนมาก จากนั้นเลือกเฉพาะเอกสารที่ดีที่สุดสำหรับ LLM กรอบเวลาบริบทที่ยาวทำให้เกิด "การหายไปตรงกลาง" และต้นทุนการคำนวณทางดาราศาสตร์
การเพิ่มประสิทธิภาพเวลาในการตอบสนอง
การจัดการกับเวลาแฝงในระบบ RAG จำเป็นต้องมีการประสานงานอย่างตั้งใจทั่วทั้งไปป์ไลน์:
ความล้มเหลวเนื่องจากการฝังตัวล่องลอยและการเปลี่ยนแปลงความรู้
การฝังจะแสดงข้อความเป็นเวกเตอร์ที่มีมิติสูงซึ่งมีความหมายใกล้เคียงกัน ทีมงานมักจะฝังเอกสารของตนอีกครั้งด้วยโมเดลการฝังที่แตกต่างกันหรือสลับตัวเข้ารหัสแบบสอบถามโดยไม่ต้องกำหนดเวอร์ชันดัชนีอย่างถูกต้องหรือเปลี่ยนแปลงความเกี่ยวข้องในการวัดประสิทธิภาพ โมเดลใหม่อาจมีความแข็งแกร่งมากขึ้น แต่อาจเปลี่ยนแปลงโครงสร้างพื้นที่ใกล้เคียงในลักษณะที่ไม่คาดคิด ซึ่งส่งผลต่อการจัดอันดับ การเรียกคืน หรือแม้แต่ภาษาเฉพาะโดเมน โมเดลที่ยอดเยี่ยมจากเกณฑ์มาตรฐานทั่วไปอาจทำงานได้แย่มากกับศัพท์แสงองค์กรในโลกแห่งความเป็นจริงของคุณ
สาเหตุสามประการของการเบี่ยงเบน
- โมเดลดริฟท์ โมเดลการฝังได้รับการอัปเดตอย่างต่อเนื่อง เมื่อคุณสร้างดัชนีเอกสารโดยใช้เวอร์ชันของโมเดลการฝัง คุณจะไม่สามารถค้นหาเอกสารเหล่านั้นด้วยการฝังจากโมเดลอื่นได้ การสลับโมเดลการฝังโดยไม่จัดทำดัชนีคลังข้อมูลใหม่จะส่งผลต่อการเรียกข้อมูลของคุณ
- การเคลื่อนตัวของคลังข้อมูล เมื่อคุณเพิ่มเอกสารใหม่ลงในดัชนี โดยเฉพาะเอกสารประเภทใหม่ พื้นที่เวกเตอร์จะเปลี่ยนไป กระจุกเวกเตอร์หนาแน่นใหม่ปรากฏขึ้น คลัสเตอร์หนาแน่นเหล่านั้นเริ่มดึงข้อความค้นหาที่ควรจับคู่กับเอกสารอื่น การเพิ่มเนื้อหาที่ผู้ใช้สร้างขึ้นหรือมีเสียงรบกวนจะลดคุณภาพการดึงข้อมูลเมื่อเวลาผ่านไป แม้ว่าคุณจะไม่ได้เปลี่ยนรูปแบบการฝังก็ตาม
- การค้นหาที่คลาดเคลื่อน คำศัพท์ของผู้ใช้จะขยายและเปลี่ยนแปลงไปตามกาลเวลา มีการใช้คำศัพท์ใหม่ๆ (“การทำงานระยะไกล” “stablecoin” “วิศวกรรมที่รวดเร็ว”) และคำศัพท์เก่าๆ ก็ค่อยๆ หายไป การฝังที่มีอยู่แล้วไม่สามารถจับคู่กับคำที่ไม่มีอยู่เมื่อได้รับการฝึกอบรมได้ หากบริษัทเปลี่ยนชื่อของผลิตภัณฑ์ตัวใดตัวหนึ่ง การค้นหาชื่อใหม่จะล้มเหลวเนื่องจากการฝังยังคงสะท้อนถึงชื่อเก่า
การตรวจจับการฝังดริฟท์ด้วยอันดับซึ่งกันและกันเฉลี่ย
ด้านล่างนี้คือแผนภาพตัวอย่างที่แสดงให้เห็นว่าการฝังดริฟท์ตรวจพบได้อย่างไรโดยการตรวจสอบการเปลี่ยนแปลงในประสิทธิภาพการดึงข้อมูลก่อนและหลังการเปลี่ยนแปลงระบบหรือเมื่อเวลาผ่านไป ขั้นแรกแผนภาพจะคำนวณคะแนน MRR พื้นฐานโดยที่เอกสารที่เกี่ยวข้องจะปรากฏใกล้กับด้านบนสุดของการจัดอันดับ จากนั้นจะคำนวณคะแนน MRR ปัจจุบัน โดยที่เอกสารที่เกี่ยวข้องจะถูกจัดอันดับลงไปตามอันดับ จากนั้นระบบจะคำนวณเปอร์เซ็นต์ที่ลดลงระหว่าง MRR พื้นฐานและ MRR ปัจจุบัน หากการลดลงของ MRR สูงกว่าเกณฑ์ที่เลือกไว้ล่วงหน้า ระบบจะสร้างการแจ้งเตือนสำหรับการฝังดริฟท์ และแนะนำให้ตรวจสอบโมเดลการฝัง การกระจายข้อมูล และดัชนี มิฉะนั้น หากการลดลงต่ำกว่าเกณฑ์ ระบบจะกำหนดว่าระบบดึงข้อมูลมีความเสถียรและติดตามตรวจสอบต่อไป
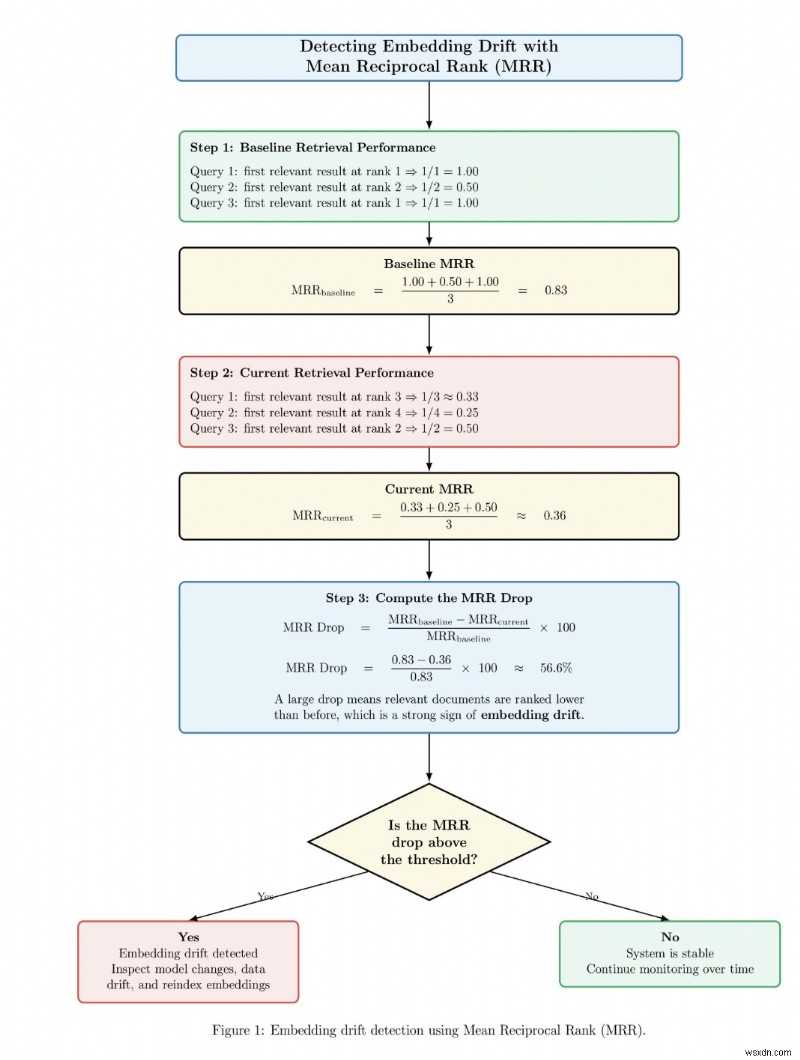
ด้วยเหตุนี้ ระบบ RAG ที่ใช้งานจริงจึงต้องมีเวอร์ชันที่ชัดเจนและสามารถสังเกตได้ การฝังควรได้รับเวอร์ชัน การสร้างดัชนีควรติดตามได้ นโยบายการแยกชิ้นส่วนควรได้รับการจัดทำเป็นเอกสารและทำซ้ำได้ หากคุณภาพเริ่มลดลง คุณจะต้องตอบคำถามต่างๆ ได้ เช่น โมเดลการฝังใดที่สร้างดัชนีนี้ กฎข้อใดที่สร้างเนื้อหาชิ้นนี้ เอกสารนี้ถูกนำเข้าใหม่เข้าสู่ระบบครั้งล่าสุดเมื่อใด รีทรีฟเวอร์และรีแรงเกอร์ตัวใดที่ตอบสนองคำขอนี้
หากคุณไม่สามารถมองเห็นไปป์ไลน์ได้ การดริฟท์จะดูเหมือนสุ่ม ด้วยสิ่งนี้ จึงสามารถวินิจฉัยได้
ความล้มเหลวเนื่องจากช่องว่างในการประเมิน:ซ่อนคอขวดที่แท้จริง
การประเมินที่อ่อนแอเป็นสาเหตุที่พบบ่อยเป็นอันดับสี่ที่ทีมล้มเหลวในการปรับใช้ระบบ RAG ในการผลิต เรามักจะประเมินเฉพาะคำตอบสุดท้ายเท่านั้น เท่านั้นยังไม่พอ
RAG ระดับการผลิตเป็นไปป์ไลน์ ไม่ว่าจะมีเลเยอร์กี่ชั้นก็ตาม อินพุตที่ไม่ดีอาจทำให้เกิดเอาต์พุตสุดท้ายที่แย่ได้ รีทรีฟเวอร์อาจล้มเหลวในการเรียกเอกสารที่ถูกต้อง ผู้จัดอันดับอาจจัดอันดับหลักฐานที่ดีที่สุดต่ำเกินไป แอสเซมเบลอร์บริบทอาจมีสัญญาณรบกวนมากเกินไป เครื่องกำเนิดไฟฟ้าอาจกลบเส้นทางที่แข็งแกร่งที่สุด คำตอบอาจถูกต้องในระดับกว้างแต่ยังคงไม่ซื่อสัตย์ต่อหลักฐานที่ดึงมาโดยสิ้นเชิง คุณไม่สามารถระบุขั้นตอนที่อ่อนแอได้หากคุณให้คะแนนเฉพาะข้อความเอาต์พุตสุดท้ายเท่านั้น
เมตริกการดึงข้อมูลควรได้รับการประเมินแยกกัน
ด้วยเหตุนี้ การประเมิน RAG จึงควรรวมตัววัดการดึงข้อมูลแยกจากตัววัดการสร้าง เมตริกการดึงข้อมูลควรมีความแม่นยำของบริบทและการเรียกคืนบริบท
- การเรียกคืนบริบท :การเรียกคืนบริบทจะตรวจสอบว่าข้อความที่ดึงมามีข้อมูลที่จำเป็นในการตอบคำถามหรือไม่
- ความแม่นยำของบริบท :ความแม่นยำของบริบทจะวัดว่าชุดที่ดึงมานั้นมีความเกี่ยวข้องเป็นส่วนใหญ่หรือปนเปื้อนด้วยเสียงรบกวน
- คุณภาพการจัดอันดับ: คุณภาพของการจัดอันดับก็มีความสำคัญเช่นกัน เนื่องจากข้อความที่เกี่ยวข้องในอันดับ 1 มีประโยชน์มากกว่าข้อความที่เกี่ยวข้องเดียวกันในอันดับ 10
ตัวชี้วัดรุ่นมีความสำคัญไม่แพ้กัน
เมื่อวัดการดึงข้อมูลแล้ว เลเยอร์การสร้างจะต้องได้รับการประเมินตามเงื่อนไขของตัวเอง ตัวชี้วัดหลักสองประการคือความมีเหตุผลและความซื่อสัตย์
- ความมีเหตุผล: ความมีเหตุผลถามว่าคำตอบสะท้อนถึงข้อมูลที่ให้ไว้ในบริบทที่ดึงมาหรือไม่
- ความซื่อสัตย์: ความซื่อสัตย์ถามว่าแบบจำลองแสดงถึงบริบทนั้นอย่างถูกต้องหรือไม่ เมตริกนี้มีความสำคัญเนื่องจากระบบอาจฟังดูเป็นไปได้ในขณะที่ยังคงนำเสนอเนื้อหาต้นฉบับอย่างไม่ถูกต้อง
ข้อมูลการทดสอบที่ไม่สมจริงจะซ่อนความล้มเหลวที่แท้จริงไว้
ข้อมูลการทดสอบที่ไม่สมจริงเป็นอีกประเด็นสำคัญ หลายทีมประเมินโดยใช้คำถามหรือคำแนะนำที่ชัดเจนและสังเคราะห์ซึ่งดูแลจัดการอย่างรอบคอบโดยทีมภายใน นั่นเป็นการซ่อนพื้นผิวความล้มเหลวที่แท้จริงโดยพื้นฐาน เงื่อนไขการประเมินในการผลิตควรรวมถึงคำถามที่ไม่ชัดเจน เอกสารที่ขัดแย้ง ข้อมูลที่ได้รับจากผู้ใช้บางส่วน เนื้อหาเก่า และสถานการณ์ที่คำตอบที่ถูกต้องคือการไม่ตอบเลย หากชุดข้อมูลไม่ได้สะท้อนถึงพฤติกรรมของผู้ใช้จริง การประเมินจะกลายเป็นกลไกที่สะดวกสบายมากกว่าเป็นเครื่องมือในการวินิจฉัย
การประเมินต้องดำเนินต่อไปหลังจากการปรับใช้
การประเมินไม่ควรหยุดหลังจากที่คุณดำเนินการเริ่มต้นเสร็จแล้ว RAG การผลิตเปลี่ยนไป เอกสารมีการเปลี่ยนแปลง การฝังจะถูกสลับออก ตรรกะการจัดอันดับพัฒนาขึ้น การเปลี่ยนแปลงเทมเพลตพร้อมท์ หากไม่มีการประเมินโดยเป็นส่วนหนึ่งของ CI/CD และการติดตามการผลิตหลังการปรับใช้งาน คุณจะได้เรียนรู้เกี่ยวกับการถดถอยจากผู้ใช้ที่ไม่พึงพอใจมากกว่าจากการตรวจสอบของพวกเขาเอง
เหตุใดการผลิต RAG จึงล้มเหลวแม้ว่าเกณฑ์มาตรฐานจะดูดีก็ตาม
นี่คือจุดที่หลายทีมสับสน เกณฑ์มาตรฐานดีขึ้น แต่ระบบที่ใช้งานจริงยังคงน่าผิดหวัง
ความล้มเหลวในการผลิตมักเกิดจากความไม่สอดคล้องกันของแรงจูงใจ ทีมพยายามปรับให้เหมาะสมสำหรับการเรียกคืนโดยไม่ต้องคำนึงถึงงบประมาณเวลาแฝงหรือปรับให้เหมาะสมสำหรับคะแนน LLM ที่สูงขึ้นโดยไม่ต้องติดตามความแม่นยำในการเรียกค้น การดึงข้อมูลอาจถูกปรับมากเกินไปโดยสูญเสียคุณภาพของการสร้าง ซึ่งทำให้เกิดเสียงรบกวน การสร้างอาจถูกปรับแต่งมากเกินไปโดยไม่คำนึงถึงการปรับปรุงการดึงข้อมูล อัตราส่วนที่เหมาะสมระหว่างความแม่นยำในการดึงข้อมูลและการสร้างขึ้นอยู่กับการใช้งาน กรณีการใช้งานการปฏิบัติตามข้อกำหนด กฎหมาย และความเสี่ยงสูงอื่นๆ ต้องใช้ความเที่ยงตรงและบริบทที่แม่นยำที่สุดเท่าที่จะเป็นไปได้ กรณีการใช้งานที่สร้างสรรค์อาจก่อให้เกิดเสียงรบกวนเพื่อแลกกับความเร็ว
การผลิตไม่ได้รับการปรับให้เหมาะสมบนเมตริกเดียว มีข้อดีข้อเสียระหว่างคุณภาพการดึงข้อมูล เวลาแฝง ความสดใหม่ ความมีเหตุผล และความเรียบง่ายในการปฏิบัติงาน นั่นเป็นสาเหตุที่ความสำเร็จของการสาธิตอาจทำให้เข้าใจผิดได้ สาธิตระบบการให้รางวัลที่ “ฟังดูถูกต้อง” การผลิตให้รางวัลความน่าเชื่อถือ
วิธีแก้ไขระบบ RAG การผลิต
เส้นทางข้างหน้าไม่ละทิ้ง RAG คือการปฏิบัติต่อมันเป็นระบบการดึงข้อมูลที่มีระเบียบวินัย
ส่วนคำถามที่พบบ่อย
คุณจะวัดคุณภาพการดึงข้อมูลใน RAG ได้อย่างไร
เราใช้เมตริกการดึงข้อมูล เช่น ความแม่นยำของบริบท การเรียกคืนบริบท และคุณภาพการจัดอันดับ และยังตรวจสอบว่าหลักฐานที่ดึงมาสนับสนุนการสร้างคำตอบจริงหรือไม่
อะไรทำให้ระบบ RAG ล้มเหลวในการผลิต
ความล้มเหลวในการผลิตมักเกิดจากการที่คุณภาพการดึงข้อมูลลดลง เวลาแฝงคืบคลาน การฝัง/การเคลื่อนตัวของคลังข้อมูล และแนวทางปฏิบัติในการประเมินที่ไม่ดีซึ่งซ่อนจุดเริ่มต้นของปัญหา
การฝังดริฟท์ในไปป์ไลน์ RAG คืออะไร
การดริฟท์การฝังเกิดขึ้นเมื่อการอัปเดตโมเดลการฝัง องค์กร หรือพฤติกรรมการสืบค้นแบบสดเปลี่ยนพฤติกรรมการดึงข้อมูลอย่างช้าๆ (ลดความเกี่ยวข้อง) โดยไม่ก่อให้เกิดพฤติกรรมของระบบที่เสียหายอย่างเห็นได้ชัด
เหตุใดเวลาแฝงของ RAG จึงเพิ่มขึ้นตามขนาด
เวลาแฝงเพิ่มขึ้นเนื่องจากระบบที่ใช้งานจริงมักเพิ่มการเขียนคิวรีใหม่ การเรียกข้อมูลหลายครั้ง การจัดอันดับใหม่ การเรียกโมเดลเพิ่มเติม และองค์กรที่ใหญ่ขึ้น ซึ่งทั้งหมดนี้เพิ่มเวลาการประมวลผลและความซับซ้อนในการดำเนินงาน
คุณประเมินความมีเหตุผลและความซื่อสัตย์ใน RAG อย่างไร
คุณเปรียบเทียบคำตอบที่สร้างขึ้นกับหลักฐานที่ดึงมา โดยตรวจสอบว่าแหล่งที่มาสนับสนุนการอ้างสิทธิ์หรือไม่ และถ้อยคำนั้นสะท้อนถึงแหล่งที่มาเหล่านั้นอย่างถูกต้องหรือไม่ โดยไม่มีการประดิษฐ์หรือบิดเบือน
บทสรุป
ความล้มเหลวในการผลิตในระบบ RAG ส่วนใหญ่ไม่ได้เป็นผลมาจากความล้มเหลวเพียงจุดเดียว วิศวกรที่รับผิดชอบจะสังเกตเห็นว่าการเสียส่วนใหญ่เริ่มต้นจากจุดอ่อนในห่วงโซ่ที่เชื่อมต่อกัน คุณภาพการดึงข้อมูลมักจะเป็นอันดับแรกที่ล้มเหลวเสมอไป วิศวกร "แก้ไข" ปัญหานี้โดยใช้ประโยชน์จากการดึงข้อมูลมากขึ้น บริบทมากขึ้น และเลเยอร์การประสานที่มากขึ้น การทำเช่นนี้จะช่วยเพิ่มเวลาในการตอบสนอง เนื่องจากการฝัง องค์กร และพฤติกรรมผู้ใช้ล้วนเลื่อนลอยไปตามกาลเวลา ตัวชี้วัดการประเมินที่อ่อนแอจึงซ่อนจุดที่ระบบล้มเหลวอย่างแท้จริง ผู้ใช้เริ่มสังเกตเห็นและสูญเสียความไว้วางใจก่อนที่ผู้จัดการจะรู้ว่ามีปัญหาเกิดขึ้น เมื่อถึงตอนนั้น การแยกรูปแบบก็ดูลึกลับ อย่างไรก็ตาม ปัญหาก็ชัดเจนตั้งแต่เริ่มต้น
RAG ล้มเหลวในวงกว้างไม่ใช่เพราะรูปแบบไม่ถูกต้อง แต่เนื่องจากระบบ RAG การผลิตในอาคารต้องใช้วิศวกรรมการดึงข้อมูลที่แข็งแกร่ง การจัดการเวลาแฝง การบรรเทาผลกระทบ และการประเมินอย่างต่อเนื่อง พวกเขาต้องการการจัดอันดับที่ดีขึ้น การแบ่งส่วนที่ดีขึ้น ความสามารถในการสังเกตที่ดีขึ้น และการวัดความมีเหตุผลและความซื่อสัตย์ สิ่งสำคัญที่สุดคือ ทีมจำเป็นต้องเข้าถึง RAG ในฐานะระบบที่มีชีวิต ไม่ใช่สถาปัตยกรรมสาธิตแบบ set-it-and-forget-it
ข้อมูลอ้างอิง
- ระบบ RAG ในการผลิต:เหตุใดจึงล้มเหลวและวิธีแก้ไข
- กลยุทธ์การแยกชิ้นส่วนที่ดีที่สุดสำหรับ RAG (และ LLM) ในปี 2026
- การประเมิน RAG คืออะไร การวัดคุณภาพการดึงข้อมูลและความมีเหตุผลของคำตอบ
- สู่การทำความเข้าใจการแลกเปลี่ยนของระบบในการอนุมานโมเดลการสร้างแบบดึงข้อมูล-เสริม
- RAGPerf:กรอบงานการเปรียบเทียบแบบครบวงจรสำหรับระบบการสร้างแบบดึงข้อมูล-Augmented
- การจัดอันดับใหม่และการดึงข้อมูลแบบสองขั้นตอน
- จาก RAG สู่บริบท - การทบทวน RAG สิ้นปี 2025
 งานนี้ได้รับอนุญาตภายใต้ Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License
งานนี้ได้รับอนุญาตภายใต้ Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License
