
ทางเลือกมากมายที่เราทำนั้นเกี่ยวข้องกับความสัมพันธ์เชิงตัวเลข
- เรากินอาหารบางชนิดเพราะวิทยาศาสตร์บอกว่าช่วยลดคอเลสเตอรอลของเราได้
- เราศึกษาต่อเพราะเรามีแนวโน้มที่จะได้เงินเดือนเพิ่มขึ้น
- เราซื้อบ้านในละแวกใกล้เคียงที่เราเชื่อว่าจะได้รับความคุ้มค่ามากที่สุด
เรามาสรุปเหล่านี้ได้อย่างไร? เป็นไปได้มากว่ามีคนรวบรวมข้อมูลจำนวนมากและใช้เพื่อสร้างข้อสรุป เทคนิคทั่วไปอย่างหนึ่งคือการถดถอยเชิงเส้น ซึ่งเป็นรูปแบบของการเรียนรู้ภายใต้การดูแล สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการเรียนรู้ภายใต้การดูแลและตัวอย่างสิ่งที่มักใช้สำหรับ โปรดดูส่วนที่ 1 ของชุดนี้
ความสัมพันธ์เชิงเส้น
เมื่อสองค่า — เรียกมันว่า x และ y — มีความสัมพันธ์เชิงเส้นหมายความว่าเปลี่ยน x โดย 1 จะทำให้ y . เสมอ เพื่อเปลี่ยนตามจำนวนที่กำหนด ยกตัวอย่างง่ายกว่า:
- พิซซ่า 10 ถาด ราคา 10 เท่าของราคาพิซซ่า 1 ถาด
- กำแพงสูง 10 ฟุตต้องการสีสองเท่าของผนัง 5 ฟุต
ในเชิงคณิตศาสตร์ ความสัมพันธ์ประเภทนี้อธิบายโดยใช้สมการของเส้นตรง:
y = mx + b
คณิตศาสตร์อาจทำให้สับสนได้ แต่บ่อยครั้งที่คณิตศาสตร์ดูเหมือนเป็นเรื่องมหัศจรรย์ เมื่อฉันเรียนรู้สมการของเส้นตรงครั้งแรก ฉันจำได้ว่ามันสวยงามเพียงใดที่สามารถคำนวณระยะทาง ความชัน และจุดอื่นๆ บนเส้นด้วยสูตรเพียงสูตรเดียว
แต่คุณจะได้สูตรนี้ได้อย่างไรถ้าคุณมีจุดข้อมูลทั้งหมด? คำตอบคือการถดถอยเชิงเส้น ซึ่งเป็นเครื่องมือการเรียนรู้ของเครื่องที่ได้รับความนิยมอย่างมาก
ตัวอย่างการถดถอยเชิงเส้น
ในโพสต์นี้ เราจะสำรวจว่าจังหวะต่อนาที (BPM) ในเพลงทำนายความนิยมใน Spotify หรือไม่
การถดถอยเชิงเส้นจำลองความสัมพันธ์ระหว่างสองตัวแปร ตัวหนึ่งเรียกว่า "ตัวแปรอธิบาย" และอีกตัวเรียกว่า "ตัวแปรตาม"
ในตัวอย่างของเรา เราต้องการดูว่า BPM สามารถ "อธิบาย" ความนิยมได้หรือไม่ ดังนั้น BPM จะเป็นตัวแปรอธิบายของเรา นั่นทำให้ความนิยมเป็นตัวแปรตาม
ตัวแบบจะใช้การถดถอยกำลังสองน้อยที่สุดเพื่อค้นหาเส้นที่เหมาะสมที่สุดของแบบฟอร์ม คุณเดาได้เลยว่า y = mx + b .
แม้ว่าจะมีตัวแปรอธิบายได้หลายตัว แต่สำหรับตัวอย่างนี้ เราจะทำการถดถอยเชิงเส้นอย่างง่ายโดยที่มีตัวแปรเพียงตัวเดียว
กำลังสองน้อยที่สุดคืออะไร
มีหลายวิธีในการถดถอยเชิงเส้น หนึ่งในนั้นเรียกว่า "กำลังสองน้อยที่สุด" โดยจะคำนวณเส้นที่เหมาะสมที่สุดโดยลดผลรวมของกำลังสองของการเบี่ยงเบนแนวตั้งจากจุดข้อมูลแต่ละจุดไปยังเส้น
ฉันรู้ว่าฟังดูสับสน แต่โดยพื้นฐานแล้วการพูดว่า "สร้างบรรทัดที่ลดจำนวนช่องว่างระหว่างบรรทัดดังกล่าวกับจุดข้อมูล"
สาเหตุของการยกกำลังสองและการรวมคือไม่มีการยกเลิกใดๆ ระหว่างค่าบวกและค่าลบ
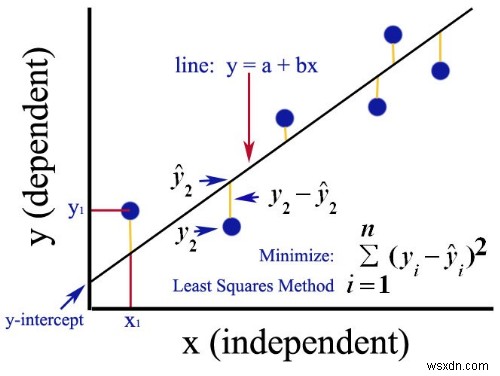
นี่คือรูปภาพที่ฉันพบใน Quora ซึ่งอธิบายได้ดีทีเดียว
ชุดข้อมูล
เราจะใช้ชุดข้อมูลนี้จาก Kaggle:https://www.kaggle.com/leonardopena/top50spotify2019 คุณสามารถดาวน์โหลดเป็น CSV
ชุดข้อมูลมี 16 คอลัมน์; อย่างไรก็ตาม เราสนใจแค่ 3 อย่างเท่านั้น ได้แก่ "ชื่อเพลง" "จังหวะต่อนาที" และ "ความนิยม" ขั้นตอนที่สำคัญที่สุดขั้นตอนหนึ่งของแมชชีนเลิร์นนิงคือการจัดรูปแบบข้อมูลของคุณอย่างเหมาะสม ซึ่งมักเรียกว่า "การมุง" คุณสามารถลบข้อมูลทั้งหมดยกเว้นสามคอลัมน์ดังกล่าว
CSV ของคุณควรมีลักษณะดังนี้: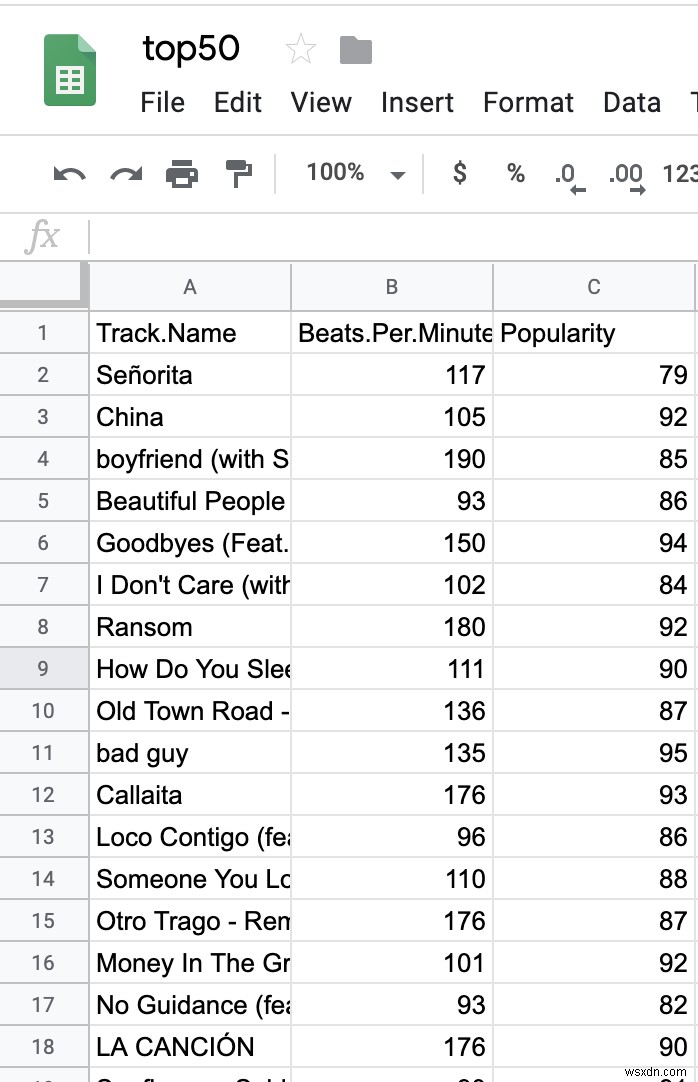
การใช้ Ruby ทำการถดถอย
ในตัวอย่างนี้ เราจะใช้ ruby_linear_regression อัญมณี. ในการติดตั้ง ให้เรียกใช้:
gem install ruby_linear_regression
ตกลง เราพร้อมที่จะเริ่มเขียนโค้ดแล้ว! สร้างไฟล์ Ruby ใหม่และเพิ่มข้อกำหนดเหล่านี้:
require "ruby_linear_regression"
require "csv"
ต่อไป เราอ่านข้อมูล CSV และเรียก #shift เพื่อละทิ้งแถวส่วนหัว หรือคุณสามารถลบแถวแรกออกจากไฟล์ CSV ได้
csv = CSV.read("top50.csv")
csv.shift
มาสร้างอาร์เรย์ว่างสองอันเพื่อเก็บจุดข้อมูล x และจุดข้อมูล y กัน
x_data = []
y_data = []
...และเราทำซ้ำโดยใช้ .each วิธีการเพิ่ม Beats Per Minute ข้อมูลไปยังอาร์เรย์ x ของเราและ Popularity ข้อมูลไปยังอาร์เรย์ y ของเรา
หากคุณอยากรู้ว่าเกิดอะไรขึ้นที่นี่ คุณสามารถทดลองโดยการบันทึก
row. ของคุณ ด้วยputsหรือp. ตัวอย่างเช่นputs row
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
ตอนนี้ได้เวลาใช้ ruby_linear_regression อัญมณี. เราจะสร้างตัวอย่างใหม่ของโมเดลการถดถอย โหลดข้อมูล และฝึกโมเดลของเรา:
linear_regression = RubyLinearRegression.new
linear_regression.load_training_data(x_data, y_data)
linear_regression.train_normal_equation
ต่อไป เราจะพิมพ์ค่าความคลาดเคลื่อนกำลังสองเฉลี่ย (MSE) — การวัดความแตกต่างระหว่างค่าที่สังเกตได้และค่าที่คาดการณ์ไว้ ผลต่างถูกยกกำลังสองเพื่อไม่ให้ค่าลบและค่าบวกหักล้างกัน เราต้องการลด MSE เนื่องจากเราไม่ต้องการให้ระยะห่างระหว่างค่าที่คาดการณ์และค่าจริงมีมาก
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
สุดท้าย ให้คอมพิวเตอร์ใช้แบบจำลองของเราในการทำนาย โดยเฉพาะเพลงที่มี 250 BPM จะดังขนาดไหน? อย่าลังเลที่จะเล่นกับค่าต่างๆ ใน prediction_data อาร์เรย์
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
ผลลัพธ์
มารันโปรแกรมในคอนโซลของเรากัน และดูว่าเราได้อะไร!
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 91
เย็น! มาเปลี่ยน "250" เป็น "50" และดูว่าโมเดลของเราคาดการณ์อะไร
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 86
ปรากฏว่าเพลงที่มีจังหวะต่อนาทีมากกว่าจะได้รับความนิยมมากกว่า
ทั้งโปรแกรม
ไฟล์ทั้งหมดของฉันมีลักษณะดังนี้:
require 'csv'
require 'ruby_linear_regression'
x_data = []
y_data = []
csv = CSV.read("top50.csv")
csv.shift
# Load data from CSV file into two arrays -- one for independent variables X (x_data) and one for the dependent variable y (y_data)
# Row[0] = title
# Row[1] = BPM
# Row[2] = Popularity
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
# Create regression model
linear_regression = RubyLinearRegression.new
# Load training data
linear_regression.load_training_data(x_data, y_data)
# Train the model using the normal equation
linear_regression.train_normal_equation
# Output the cost
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
# Predict the popularity of a song with 250 BPM
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
ขั้นตอนต่อไป
นี่เป็นตัวอย่างง่ายๆ แต่อย่างไรก็ตาม คุณเพิ่งเรียกใช้การถดถอยเชิงเส้นครั้งแรก ซึ่งเป็นเทคนิคหลักที่ใช้สำหรับการเรียนรู้ของเครื่อง หากคุณต้องการมากกว่านี้ ต่อไปนี้คือสิ่งที่คุณสามารถทำได้ต่อไป:- ลองดูซอร์สโค้ดสำหรับ Ruby gem ที่เราเคยใช้เพื่อดูการคำนวณที่เกิดขึ้นภายใต้ประทุน - กลับไปที่ชุดข้อมูลเดิมแล้วลอง การเพิ่มตัวแปรเพิ่มเติมให้กับโมเดลและรันการถดถอยเชิงเส้นแบบหลายตัวแปรเพื่อดูว่าสามารถลด MSE ของเราได้หรือไม่ ตัวอย่างเช่น บางที "วาเลนซ์" (เพลงเป็นบวกแค่ไหน) ก็มีบทบาทในความนิยมเช่นกัน - ลองใช้โมเดลการไล่ระดับการไล่ระดับสี ซึ่งยังสามารถเรียกใช้โดยใช้ ruby_linear_regression อัญมณี.
