
ทรีคำนำหน้า (หรือที่เรียกว่า tri) คือโครงสร้างข้อมูลที่ช่วยคุณจัดระเบียบรายการคำและค้นหาคำที่ขึ้นต้นด้วยคำนำหน้าเฉพาะได้อย่างรวดเร็ว
ตัวอย่างเช่น คุณสามารถค้นหาคำทั้งหมดในพจนานุกรมที่ขึ้นต้นด้วยตัวอักษร “ca” เช่น “cat” หรือ “cape”
ดูภาพนี้:
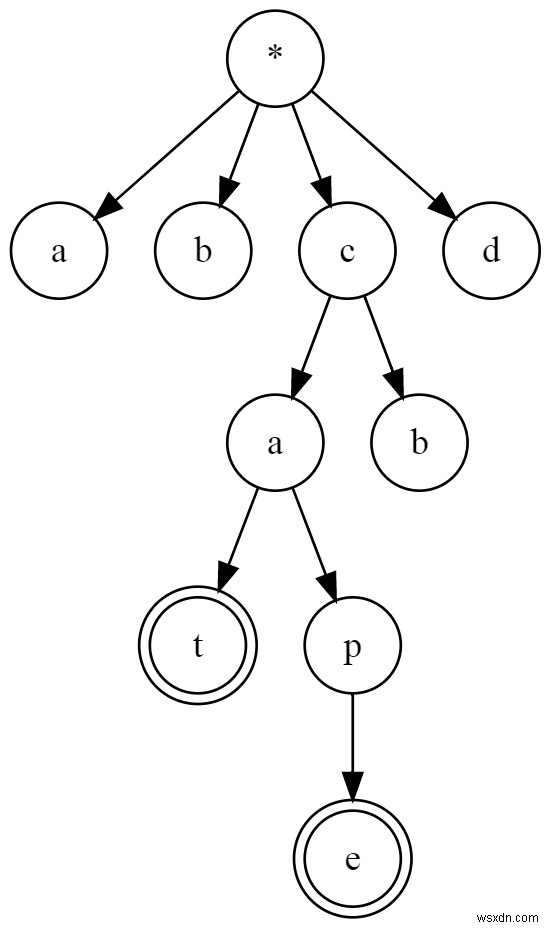
นี่คือคำนำหน้าต้นไม้
ติดตามได้จากรูท (* ) ไปยังโหนดที่ทำเครื่องหมายไว้ (เช่น e และ t ) เพื่อค้นหาคำศัพท์
ในบทความนี้ คุณจะได้เรียนรู้วิธีติดตั้ง prefix tree ของคุณเองใน Ruby และวิธีใช้งานเพื่อแก้ปัญหา!
การใช้งานทรีคำนำหน้า
เพื่อใช้งานสิ่งนี้ใน Ruby ฉันตัดสินใจใช้ Node คลาสที่มีคุณสมบัติบางอย่าง:
- ค่า (หนึ่งตัวอักษร)
- ตัวแปร "คำ" ค่าจริง/เท็จ ซึ่งจะบอกคุณว่าคำนี้เป็นคำที่ถูกต้องหรือไม่
- อาร์เรย์ "ถัดไป" เก็บอักขระทั้งหมด (เช่น
Nodeวัตถุ) ที่ตามหลังสิ่งนี้ในต้นไม้
นี่คือรหัส :
class Node
attr_reader :value, :next
attr_accessor :word
def initialize(value)
@value = value
@word = false
@next = []
end
end
ตอนนี้เราต้องการคลาสเพื่อเก็บโหนดรูท &วิธีการทำงานกับโหนดเหล่านี้
มาดูที่ Trie คลาส:
class Trie
def initialize
@root = Node.new("*")
end
end
ภายในคลาสนี้ เรามีเมธอดดังต่อไปนี้:
def add_word(word)
letters = word.chars
base = @root
letters.each { |letter| base = add_character(letter, base.next) }
base.word = true
end
def find_word(word)
letters = word.chars
base = @root
word_found =
letters.all? { |letter| base = find_character(letter, base.next) }
yield word_found, base if block_given?
base
end
ทั้งสองวิธีแบ่งคำที่กำหนดออกเป็นอาร์เรย์ของอักขระ (โดยใช้ chars วิธีการ)
จากนั้นเรานำทางต้นไม้โดยเริ่มต้นที่รูท &ค้นหาตัวละครหรือเพิ่มมัน
นี่คือวิธีการสนับสนุน (รวมถึงใน Trie คลาส):
def add_character(character, trie)
trie.find { |n| n.value == character } || add_node(character, trie)
end
def find_character(character, trie)
trie.find { |n| n.value == character }
end
def add_node(character, trie)
Node.new(character).tap { |new_node| trie << new_node }
end
หากต้องการเพิ่มอักขระให้ตรวจสอบว่ามีอยู่แล้วหรือไม่ (โดยใช้ find กระบวนการ). หากเป็นเช่นนั้น เราจะส่งคืนโหนด
มิฉะนั้น เราจะสร้างมันขึ้นมาและส่งคืนโหนดใหม่
แล้วเราก็มี include? วิธีการ:
def include?(word)
find_word(word) { |found, base| return found && base.word }
end
ตอนนี้เราพร้อมที่จะเริ่มใช้โครงสร้างข้อมูลใหม่และดูว่าเราสามารถทำอะไรกับมันได้บ้าง 🙂
ตัวอย่างการใช้งานและตัวอย่าง
เริ่มต้นด้วยการเพิ่มคำบางคำในต้นไม้ของเรา:
trie = Trie.new
trie.add_word("cat")
trie.add_word("cap")
trie.add_word("cape")
trie.add_word("camp")
คุณสามารถตรวจสอบว่ามีคำใดรวมอยู่ในแผนผังนี้หรือไม่:
p trie.include?("cape")
# true
p trie.include?("ca")
# false
โครงสร้างข้อมูลนี้มีประโยชน์อย่างไร
- แก้เกมคำศัพท์
- ตรวจการสะกด
- เติมข้อความอัตโนมัติ
คุณจะต้องมีพจนานุกรมที่ดีเพื่อโหลดลงในต้นไม้ของคุณ
ฉันพบสิ่งเหล่านี้ที่อาจเป็นประโยชน์กับคุณ:
- https://raw.githubusercontent.com/first20hours/google-10000-english/master/20k.txt
- https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt
ค้นหาคำนำหน้า
ในตัวอย่างโค้ด ฉันแสดงให้คุณเห็นก่อนที่เราจะใช้งาน add &find การดำเนินงาน
แต่เราต้องการ find_words_starting_with . ด้วย วิธีการ
เราสามารถทำได้โดยใช้อัลกอริทึม "Depth First Search" (DFS) เรายังต้องการวิธีติดตามคำที่เรากำลังดูอยู่
โปรดจำไว้ว่าโหนดของเรามีอักขระแต่ละตัวเท่านั้น เราจึงต้องสร้างสตริงจริงใหม่โดยการเดินข้ามต้นไม้
นี่คือวิธีการที่ทำได้ทั้งหมด :
def find_words_starting_with(prefix)
stack = []
words = []
prefix_stack = []
stack << find_word(prefix)
prefix_stack << prefix.chars.take(prefix.size-1)
return [] unless stack.first
until stack.empty?
node = stack.pop
prefix_stack.pop and next if node == :guard_node
prefix_stack << node.value
stack << :guard_node
words << prefix_stack.join if node.word
node.next.each { |n| stack << n }
end
words
end
เราใช้สองสแต็กที่นี่ หนึ่งสแต็กสำหรับติดตามโหนดที่ไม่ได้เยี่ยมชม (stack ) &อีกอันเพื่อติดตามสตริงปัจจุบัน (prefix_stack )
เราวนซ้ำจนกว่าเราจะเยี่ยมชมโหนดทั้งหมด &เพิ่มค่าของโหนดใน prefix_stack . แต่ละโหนดมีค่าสำหรับอักขระเดียวเท่านั้น เราจึงต้องรวบรวมอักขระเหล่านี้เพื่อสร้างคำ
:guard_node สัญลักษณ์ถูกเพิ่มลงใน prefix_stack เราจึงรู้ว่าเมื่อใดที่เราย้อนรอย เราต้องการสิ่งนี้เพื่อลบอักขระออกจากบัฟเฟอร์สตริงของเรา (prefix_stack ) ในเวลาที่เหมาะสม
แล้วถ้า node.word เป็นความจริงหมายความว่าเราพบคำเต็มและเราเพิ่มลงในรายการคำของเรา
ตัวอย่างการใช้วิธีนี้ :
t.find_words_starting_with("cap")
# ["cap", "cape"]
หากไม่พบคำใดๆ คุณจะได้รับอาร์เรย์ว่าง:
t.find_words_starting_with("b")
# []
สามารถใช้วิธีนี้เพื่อใช้คุณลักษณะเติมข้อความอัตโนมัติได้
สรุป
คุณได้เรียนรู้เกี่ยวกับทรีคำนำหน้า (หรือที่เรียกว่าพยายาม) ซึ่งเป็นโครงสร้างข้อมูลที่ใช้ในการจัดระเบียบรายการคำให้เป็นต้นไม้ คุณสามารถค้นหาต้นไม้นี้ได้อย่างรวดเร็วเพื่อตรวจสอบว่าคำนั้นถูกต้องหรือไม่ &เพื่อค้นหาคำที่มีคำนำหน้าเดียวกัน
อย่าลืมแชร์โพสต์นี้เพื่อให้คนอื่นได้เรียนรู้!
