
เผยแพร่ครั้งแรกเมื่อวันที่ 17 มิถุนายน 2020 ที่ Onica.com/blog
องค์กรในอุตสาหกรรมต่างๆ มากมายมองหาการใช้การวิเคราะห์ข้อมูลสำหรับการดำเนินงานและฟังก์ชันอื่นๆ ที่มีความสำคัญต่อความสำเร็จ อย่างไรก็ตาม เมื่อปริมาณข้อมูลเพิ่มขึ้น การจัดการและการดึงมูลค่าอาจมีความซับซ้อนมากขึ้น
Amazon Redshift
Amazon® Redshift® เป็นบริการคลังข้อมูลที่ทรงพลังจาก Amazon Web Services® (AWS) ที่ทำให้การจัดการและวิเคราะห์ข้อมูลง่ายขึ้น มาดู Amazon Redshift และแนวทางปฏิบัติที่ดีที่สุดบางส่วนที่คุณสามารถนำไปใช้เพื่อเพิ่มประสิทธิภาพการสืบค้นข้อมูล
Data lake กับ Data warehouse
ก่อนที่จะเจาะเข้าไปใน Amazon Redshift สิ่งสำคัญคือต้องทราบความแตกต่างระหว่าง Data Lake และคลังสินค้า Data Lake เช่น Amazon S3 เป็นที่เก็บข้อมูลแบบรวมศูนย์ที่จัดเก็บข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง ในทุกขนาดและจากแหล่งที่มาต่างๆ โดยไม่ต้องแก้ไขข้อมูล ในทางกลับกัน Data warehouses จัดเก็บข้อมูลในสถานะที่กระทบยอดซึ่งปรับให้เหมาะสมเพื่อดำเนินการวิเคราะห์อย่างต่อเนื่องและ โหลดเฉพาะข้อมูลที่จำเป็นสำหรับการวิเคราะห์จาก data lake เท่านั้น
Amazon Redshift นำพื้นที่จัดเก็บสำหรับการวิเคราะห์ข้อมูลไปอีกระดับ โดยผสมผสานคุณภาพของ Data Lake และคลังข้อมูลให้เป็นแนวทาง “Lake House” ช่วยให้สามารถสืบค้นข้อมูลทะเลสาบขนาดใหญ่ในระดับเอกซาไบต์ได้ในขณะที่ยังคงความคุ้มค่า ลดความซ้ำซ้อนของข้อมูล และลดค่าใช้จ่ายในการบำรุงรักษาและค่าใช้จ่ายในการดำเนินงาน
สถาปัตยกรรม Amazon Redshift
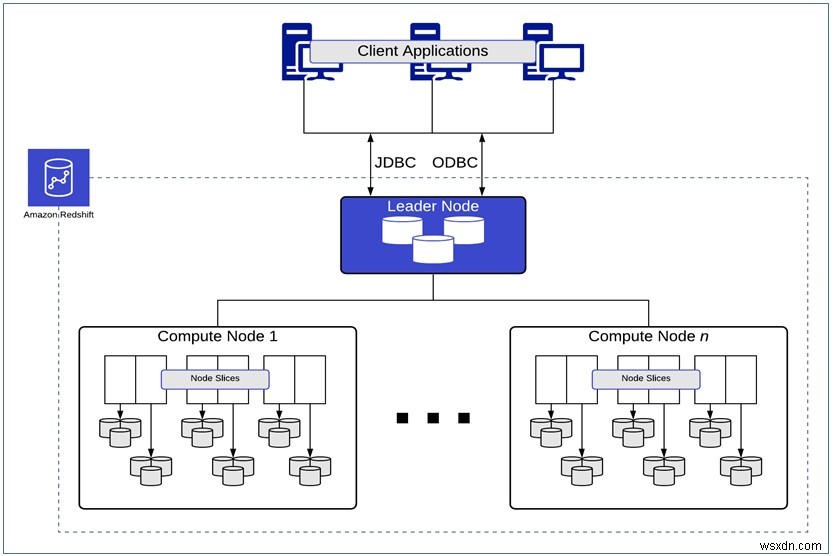
เพื่อประมวลผลการสืบค้นข้อมูลที่ซับซ้อนอย่างรวดเร็วบนชุดข้อมูลขนาดใหญ่ สถาปัตยกรรม Amazon Redshift รองรับการประมวลผลแบบขนานขนาดใหญ่ (MPP) ที่กระจายงานผ่านโหนดประมวลผลจำนวนมากสำหรับการประมวลผลพร้อมกัน
โหนดเหล่านี้จัดกลุ่มเป็นกลุ่ม และแต่ละคลัสเตอร์ประกอบด้วยโหนดสามประเภท:
-
โหนดผู้นำ :สิ่งเหล่านี้จัดการการเชื่อมต่อ ทำหน้าที่เป็นจุดปลาย SQL และการประมวลผล SQL แบบคู่ขนาน
-
โหนดคอมพิวท์ :ประกอบด้วย slices , ดำเนินการค้นหาแบบขนานกับข้อมูลที่จัดเก็บในรูปแบบคอลัมน์และในบล็อกที่ไม่เปลี่ยนรูป 1 MB คลัสเตอร์ Amazon Redshift สามารถบรรจุได้ระหว่างโหนดประมวลผล 1 ถึง 128 โหนด โดยแบ่งเป็นส่วนย่อยที่มีข้อมูลตารางและทำหน้าที่เป็นโซนการประมวลผลในเครื่อง
-
โหนด Amazon Redshift Spectrum :ดำเนินการค้นหาเหล่านี้กับ Data Lake ของ Amazon S3
กำลังเพิ่มประสิทธิภาพการสืบค้น
การนำรูปแบบทางกายภาพของข้อมูลในคลัสเตอร์มาสอดคล้องกับรูปแบบการสืบค้นของคุณ คุณจะสามารถดึงประสิทธิภาพการสืบค้นที่เหมาะสมที่สุดได้ หาก Amazon Redshift ทำงานไม่ถูกต้อง ให้พิจารณากำหนดค่าการจัดการปริมาณงานใหม่
กำหนดค่าการจัดการภาระงานใหม่ (WLM)
มักจะทิ้งไว้ในการตั้งค่าเริ่มต้น การปรับ WLM สามารถปรับปรุงประสิทธิภาพได้ คุณสามารถทำให้งานนี้เป็นแบบอัตโนมัติหรือดำเนินการด้วยตนเอง เมื่อทำงานอัตโนมัติ Amazon Redshift จะจัดการการใช้หน่วยความจำและการทำงานพร้อมกันตามการใช้งานทรัพยากรคลัสเตอร์ ซึ่งช่วยให้คุณตั้งค่าคิวที่กำหนดลำดับความสำคัญได้แปดรายการ เมื่อดำเนินการด้วยตนเอง คุณจะปรับจำนวนการสืบค้นข้อมูลพร้อมกัน การจัดสรรหน่วยความจำ และเป้าหมายได้
คุณยังสามารถปรับประสิทธิภาพการสืบค้นให้เหมาะสมผ่านพารามิเตอร์การกำหนดค่า WLM ต่อไปนี้:
-
การตรวจสอบข้อความค้นหา กฎจะช่วยคุณจัดการคำค้นหาที่มีราคาแพงหรือหนีไม่พ้น
-
ข้อความค้นหาสั้นๆ การเร่งความเร็วช่วยให้คุณจัดลำดับความสำคัญของการสืบค้นที่ใช้เวลาสั้นมากกว่าการสืบค้นที่ใช้เวลานานโดยใช้อัลกอริธึมการเรียนรู้ของเครื่องเพื่อคาดการณ์เวลาดำเนินการสืบค้น
-
การปรับขนาดพร้อมกัน ช่วยให้คุณเพิ่มกลุ่มชั่วคราวหลายกลุ่มในไม่กี่วินาทีเพื่อเพิ่มความเร็วในการสืบค้นข้อมูลการอ่านพร้อมกัน
แนวทางปฏิบัติที่ดีที่สุดของ WLM
แนวทางปฏิบัติที่ดีที่สุดในการปรับแต่ง WLM ได้แก่:
- การสร้างการสืบค้น WLM ที่แตกต่างกันสำหรับปริมาณงานประเภทต่างๆ
- จำกัดการทำงานพร้อมกันทั้งหมดสูงสุดสำหรับคลัสเตอร์หลักไว้ที่ 15 หรือน้อยกว่าเพื่อเพิ่มปริมาณงานให้สูงสุด
- เปิดใช้งานการปรับขนาดพร้อมกัน
- การลดจำนวนทรัพยากรในคิว
กำลังปรับแต่งการกระจายข้อมูล
แถวของตารางจะกระจายโดยอัตโนมัติโดย AmazonRedshift ข้ามส่วนของโหนด โดยอิงตามรูปแบบการแจกจ่ายต่อไปนี้:
AUTO:เริ่มต้นด้วย ALL และเปลี่ยนเป็น EVEN เมื่อตารางเติบโตขึ้นALL:ประกอบด้วยตารางขนาดเล็กที่เข้าร่วมบ่อยๆ และมีการดัดแปลงไม่บ่อยนัก โดยวางไว้บนส่วนแรกของโหนดประมวลผลแต่ละโหนดEVEN:ประกอบด้วยตารางข้อเท็จจริงขนาดใหญ่แบบสแตนด์อโลนที่ไม่ได้รวมหรือรวมกันบ่อยครั้งในการกระจายแบบวนซ้ำทั่วทั้งส่วนต่างๆKEY:ประกอบด้วยตารางข้อเท็จจริงหรือตารางไดเมนชันขนาดใหญ่ที่เข้าร่วมบ่อยๆ ในสไตล์นี้ ค่าคอลัมน์จะถูกแฮช และค่าแฮชเดียวกันจะวางอยู่บนสไลซ์เดียวกัน
การใช้รูปแบบการกระจายที่เหมาะสมสามารถเพิ่มประสิทธิภาพของ JOIN . ได้สูงสุด , GROUP BY และ INSERT INTO SELECT การดำเนินงาน
ปรับแต่งการจัดเรียงข้อมูล
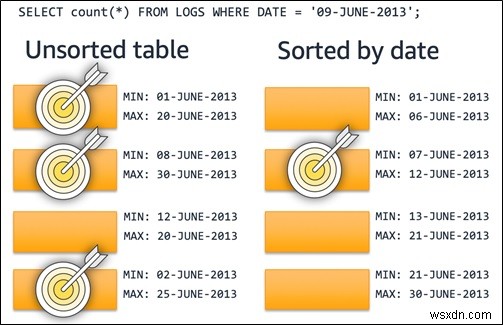
ปุ่มจัดเรียงกำหนดลำดับทางกายภาพของข้อมูลบนดิสก์ คอลัมน์ตารางที่ใช้ใน WHERE เพรดิเคตประโยคเป็นทางเลือกที่ดีสำหรับคีย์การจัดเรียงและมักใช้คอลัมน์ที่เกี่ยวข้องกับวันที่หรือเวลา ใช้แผนที่โซนที่จัดเก็บไว้ในหน่วยความจำและสร้างโดยอัตโนมัติ เพื่อกำหนดค่าสุดขั้วสำหรับแต่ละบล็อกของข้อมูล การใช้คีย์การจัดเรียงและแผนที่โซนร่วมกันอย่างมีประสิทธิภาพสามารถช่วยคุณได้ จำกัดการสแกนให้จำกัดจำนวนบล็อกขั้นต่ำที่ต้องการ
ไดอะแกรมต่อไปนี้แสดงให้เห็นว่าการเรียงลำดับตารางมุ่งเน้นการสแกนเป้าหมายสำหรับการค้นหาตามเวลา ซึ่งจะช่วยปรับปรุงประสิทธิภาพของคิวรี
แนวทางปฏิบัติที่ดีที่สุดสำหรับประสิทธิภาพการค้นหาที่ดีที่สุด
การใช้การเปลี่ยนแปลงของ Amazon Redshift ที่กล่าวถึงก่อนหน้านี้สามารถปรับปรุงประสิทธิภาพการสืบค้น และปรับปรุงต้นทุนและประสิทธิภาพของทรัพยากร ต่อไปนี้คือแนวทางปฏิบัติที่ดีที่สุดบางส่วนที่คุณสามารถนำไปใช้เพื่อการปรับปรุงประสิทธิภาพเพิ่มเติม:
- ใช้
SORTปุ่มบนคอลัมน์ที่มักใช้ในWHEREตัวกรองประโยค - ใช้
DISTKEYในคอลัมน์ที่มักใช้ในJOINภาคแสดง - บีบอัดคอลัมน์ทั้งหมดยกเว้นคอลัมน์คีย์การจัดเรียงแรก
- แบ่งข้อมูลใน Data Lake ตามตัวกรองการสืบค้น เช่น รูปแบบการเข้าถึง .
หากต้องการสำรวจแนวทางปฏิบัติที่ดีที่สุดเพิ่มเติม เจาะลึกการเปลี่ยนแปลงของ Amazon Redshift และดูตัวอย่างการวิเคราะห์การค้นหาเชิงลึก อ่านบล็อก AWS Partner Network (APN)
หากคุณกำลังเริ่มต้นการเดินทางของข้อมูลและต้องการใช้ประโยชน์จากบริการของ AWS เพื่อพัฒนาแพลตฟอร์มข้อมูลของคุณอย่างรวดเร็ว เชื่อถือได้ และคุ้มค่า โปรดติดต่อทีม Data Engineering &Analytics ของเราวันนี้
ดูข้อมูลเพิ่มเติมเกี่ยวกับบริการของ Onica
ใช้แท็บคำติชมเพื่อแสดงความคิดเห็นหรือถามคำถาม คุณยังสามารถคลิกแชทขาย เพื่อแชทตอนนี้และเริ่มการสนทนา
