
Redis เป็นเทคโนโลยีพื้นฐาน และด้วยเหตุนี้ เราจึงเห็นผู้คนกำลังพิจารณาสถาปัตยกรรมทางเลือกในบางครั้ง เมื่อไม่กี่ปีที่ผ่านมา KeyDB นำเสนอสิ่งนี้และเมื่อเร็ว ๆ นี้โครงการใหม่ Dragonfly อ้างว่าเป็นพื้นที่เก็บข้อมูลในหน่วยความจำที่เข้ากันได้กับ Redis ที่เร็วที่สุด เราเชื่อว่าโครงการเหล่านี้นำเทคโนโลยีและแนวคิดที่น่าสนใจมากมายมาพูดคุยและโต้เถียงกัน ที่ Redis เราชอบความท้าทายประเภทนี้ เนื่องจากเราต้องยืนยันหลักการทางสถาปัตยกรรมที่ Redis ได้รับการออกแบบในขั้นต้นด้วย (ปลายหมวกถึง Salvatore Sanfilippo aka antirez)
ในขณะที่เรามองหาโอกาสในการคิดค้นและพัฒนาประสิทธิภาพและความสามารถของ Redis อยู่เสมอ เราต้องการแบ่งปันมุมมองและการไตร่ตรองว่าเหตุใดสถาปัตยกรรมของ Redis จึงยังคงดีที่สุดในกลุ่มสำหรับที่เก็บข้อมูลแบบเรียลไทม์ในหน่วยความจำ (แคช) ฐานข้อมูลและทุกสิ่งในระหว่างนั้น)
ดังนั้นในหัวข้อถัดไป เราจะเน้นมุมมองของเราเกี่ยวกับความเร็วและความแตกต่างทางสถาปัตยกรรมที่เกี่ยวข้องกับการเปรียบเทียบ ในตอนท้ายของโพสต์นี้ เรายังได้ให้รายละเอียดเกี่ยวกับการวัดประสิทธิภาพและการเปรียบเทียบประสิทธิภาพกับโครงการ Dragonfly ที่เราได้พูดคุยกันด้านล่าง และขอเชิญให้คุณตรวจสอบและทำซ้ำสิ่งเหล่านี้ด้วยตัวคุณเอง
ความเร็ว
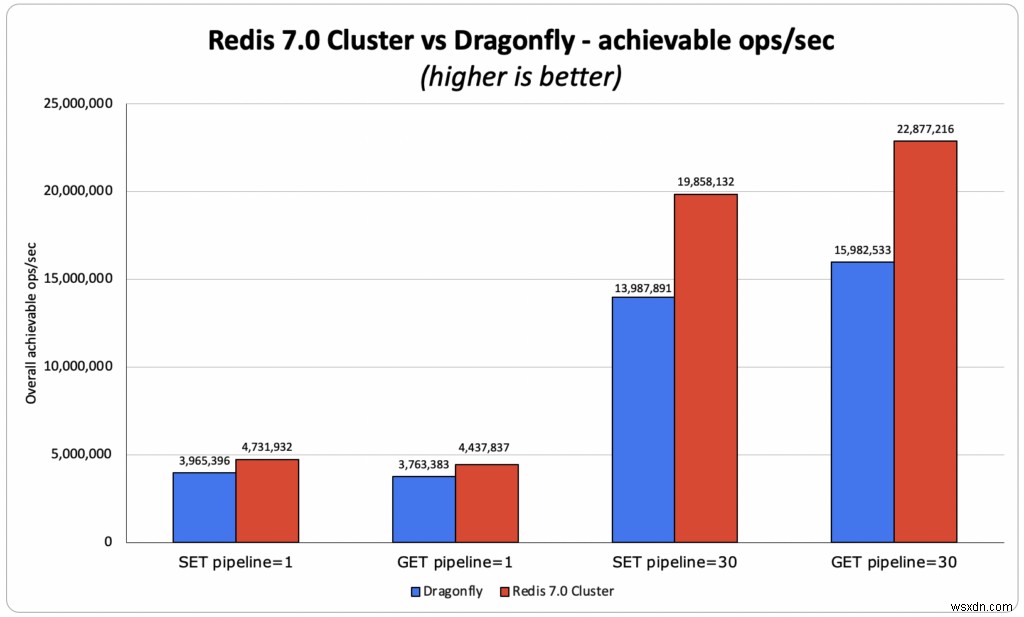
เกณฑ์มาตรฐาน Dragonfly เปรียบเทียบอินสแตนซ์ Redis กระบวนการเดี่ยวแบบสแตนด์อโลน (ที่สามารถใช้คอร์เดียวเท่านั้น) กับอินสแตนซ์ Dragonfly แบบมัลติเธรด (ที่สามารถใช้คอร์ที่มีอยู่ทั้งหมดบน VM/เซิร์ฟเวอร์) น่าเสียดายที่การเปรียบเทียบนี้ไม่ได้แสดงว่า Redis ทำงานอย่างไรในโลกแห่งความเป็นจริง ในฐานะผู้สร้างเทคโนโลยี เราพยายามทำความเข้าใจให้แน่ชัดว่าเทคโนโลยีของเราเปรียบเทียบกับเทคโนโลยีอื่นๆ อย่างไร ดังนั้นเราจึงทำในสิ่งที่เราเชื่อว่าเป็นการเปรียบเทียบที่ยุติธรรม และเปรียบเทียบคลัสเตอร์ Redis 7.0 ที่มีส่วนแบ่งข้อมูล 40 ส่วน (ที่สามารถใช้แกนอินสแตนซ์ส่วนใหญ่ได้) กับ Dragonfly โดยใช้ ชุดการทดสอบประสิทธิภาพของประเภทอินสแตนซ์ที่ใหญ่ที่สุดที่ใช้โดยทีม Dragonfly ในการวัดประสิทธิภาพ AWS c6gn.16xlarge ในการทดลองของเรา เราเห็นว่า Redis มีปริมาณงานมากกว่า 18% - 40% เมื่อเทียบกับ Dragonfly แม้ว่าจะใช้งานเพียง 40 จาก 64 vCores ก็ตาม
ความแตกต่างทางสถาปัตยกรรม
พื้นหลังบางส่วน
เราเชื่อว่าการตัดสินใจทางสถาปัตยกรรมจำนวนมากที่ทำโดยผู้สร้างโปรเจ็กต์แบบมัลติเธรดเหล่านี้ได้รับอิทธิพลจากจุดบอดที่พวกเขาพบในงานก่อนหน้านี้ เราเห็นด้วยว่าการเรียกใช้กระบวนการ Redis เดียวบนเครื่องมัลติคอร์ ซึ่งบางครั้งอาจมีหลายสิบคอร์และหน่วยความจำหลายร้อย GB จะไม่ใช้ประโยชน์จากทรัพยากรที่มีอยู่อย่างชัดเจน แต่นี่ไม่ใช่วิธีที่ Redis ออกแบบมาเพื่อใช้งาน นี่เป็นเพียงจำนวนผู้ให้บริการ Redis ที่เลือกใช้บริการของตน
Redis ปรับขนาดในแนวนอนโดยการเรียกใช้หลายกระบวนการ (โดยใช้ Redis Cluster) แม้ในบริบทของอินสแตนซ์คลาวด์เดียว ที่ Redis (บริษัท) เราได้พัฒนาแนวคิดนี้เพิ่มเติม และสร้าง Redis Enterprise ที่มีเลเยอร์การจัดการที่อนุญาตให้ผู้ใช้เรียกใช้ Redis ในปริมาณมาก โดยมีความพร้อมใช้งานสูง การเฟลโอเวอร์ทันที การคงอยู่ของข้อมูล และการสำรองข้อมูลที่เปิดใช้งานตามค่าเริ่มต้น
เราตัดสินใจแชร์หลักการบางอย่างที่เราใช้เบื้องหลังเพื่อช่วยให้ผู้คนเข้าใจสิ่งที่เราเชื่อว่าเป็นแนวทางปฏิบัติทางวิศวกรรมที่ดีสำหรับการเรียกใช้ Redis ในสภาพแวดล้อมการผลิต
หลักการทางสถาปัตยกรรม
เรียกใช้ Redis หลายอินสแตนซ์ต่อ VM
การเรียกใช้ Redis หลายอินสแตนซ์ต่อ VM ช่วยให้เรา:
- ปรับขนาดเชิงเส้นทั้งในแนวตั้งและแนวนอน โดยใช้สถาปัตยกรรมที่ไม่มีการแบ่งปันอย่างสมบูรณ์ ซึ่งจะให้ความยืดหยุ่นมากกว่าเมื่อเปรียบเทียบกับสถาปัตยกรรมแบบมัลติเธรดที่ขยายในแนวตั้งเท่านั้น
- เพิ่มความเร็วของการจำลองแบบ เนื่องจากการจำลองแบบขนานกันในหลายกระบวนการ
- กู้คืนได้อย่างรวดเร็วจากความล้มเหลวของ VM เนื่องจากอินสแตนซ์ Redis ของ VM ใหม่จะถูกเติมด้วยข้อมูลจากอินสแตนซ์ Redis ภายนอกหลายรายการพร้อมกัน
จำกัดแต่ละกระบวนการ Redis ให้มีขนาดที่เหมาะสม
เราไม่อนุญาตให้กระบวนการ Redis เดียวขยายเกิน 25 GB (และ 50 GB เมื่อเรียกใช้ Redis บน Flash) สิ่งนี้ทำให้เรา:
- เพลิดเพลินไปกับประโยชน์ของการคัดลอกเมื่อเขียนโดยไม่ต้องเสียค่าปรับสำหรับโอเวอร์เฮดหน่วยความจำขนาดใหญ่เมื่อฟอร์ก Redis สำหรับการจำลองแบบ สแนปชอต และการเขียนซ้ำเฉพาะไฟล์ (AOF) และ 'ใช่' ถ้าคุณไม่ทำ คุณ (หรือผู้ใช้ของคุณ) จะต้องจ่ายราคาสูง ดังที่แสดงไว้ที่นี่
- เพื่อจัดการคลัสเตอร์ของเราอย่างง่ายดาย ย้ายชาร์ด แบ่งใหม่ ปรับขนาด และปรับสมดุลอย่างรวดเร็ว เนื่องจาก Redis ทุกอินสแตนซ์มีขนาดเล็ก
การปรับขนาดแนวนอนเป็นสิ่งสำคัญยิ่ง
ความยืดหยุ่นในการเรียกใช้พื้นที่เก็บข้อมูลในหน่วยความจำของคุณด้วยการปรับขนาดในแนวนอนมีความสำคัญอย่างยิ่ง นี่เป็นเพียงเหตุผลบางประการ:
- ความยืดหยุ่นที่ดีขึ้น – ยิ่งคุณใช้โหนดในคลัสเตอร์ของคุณมากเท่าไร คลัสเตอร์ของคุณก็จะยิ่งแข็งแกร่งมากขึ้นเท่านั้น ตัวอย่างเช่น หากคุณเรียกใช้ชุดข้อมูลบนคลัสเตอร์แบบ 3 โหนด และโหนดหนึ่งโหนดถูกลดระดับลง แสดงว่า 1/3 ของคลัสเตอร์ของคุณไม่ทำงาน แต่ถ้าคุณเรียกใช้ชุดข้อมูลบนคลัสเตอร์แบบ 9 โหนดและโหนดหนึ่งโหนดถูกลดระดับลง แสดงว่าคลัสเตอร์ของคุณไม่ทำงานเพียง 1/9 เท่านั้น
- ปรับขนาดได้ง่ายขึ้น – ง่ายกว่ามากในการเพิ่มโหนดเพิ่มเติมไปยังคลัสเตอร์ของคุณและย้ายเพียงส่วนหนึ่งของชุดข้อมูลของคุณไปยังมัน แทนที่จะปรับขนาดในแนวตั้ง ซึ่งคุณต้องนำโหนดที่ใหญ่ขึ้นและคัดลอกชุดข้อมูลทั้งหมดของคุณ (และคิดถึงสิ่งเลวร้ายทั้งหมด ที่อาจเกิดขึ้นระหว่างกระบวนการที่อาจใช้เวลานานนี้…)
- การปรับขนาดทีละน้อยจะคุ้มค่ากว่ามาก – การปรับขนาดในแนวตั้งโดยเฉพาะในระบบคลาวด์นั้นมีราคาแพง ในหลายกรณี คุณต้องเพิ่มขนาดอินสแตนซ์ของคุณเป็นสองเท่า แม้ว่าคุณจะต้องเพิ่ม GB สองสามชุดในชุดข้อมูลของคุณก็ตาม
- ปริมาณงานสูง – ที่ Redis เราพบลูกค้าจำนวนมากที่ใช้ปริมาณงานปริมาณมากบนชุดข้อมูลขนาดเล็ก โดยมีแบนด์วิดท์เครือข่ายสูงมาก และ/หรือความต้องการแพ็กเก็ตต่อวินาที (PPS) สูง ลองนึกถึงชุดข้อมูลขนาด 1GB ที่มีกรณีการใช้งาน 1M+ ops/วินาที เหมาะสมหรือไม่ที่จะรันบนคลัสเตอร์ c6gn.16xlarge แบบโหนดเดียว (128GB พร้อม 64 CPU และ 100gbps ที่ $2.7684/ชม.) แทนที่จะเป็นคลัสเตอร์ c6gn.xlarge แบบ 3 โหนด (8GB. 4 CPU สูงสุด 25Gbps ที่ $0.1786/ชั่วโมงต่อเครื่อง) ) ที่น้อยกว่า 20% ของค่าใช้จ่ายและในลักษณะที่แข็งแกร่งมากขึ้น? ความสามารถในการเพิ่มปริมาณงานในขณะที่ยังคงความคุ้มค่าและการปรับปรุงความยืดหยุ่นดูเหมือนจะเป็นคำตอบที่ง่ายสำหรับคำถาม
- ความเป็นจริงของ NUMA – การปรับขนาดในแนวตั้งยังหมายถึงการรันเซิร์ฟเวอร์แบบสองซ็อกเก็ตที่มีหลายคอร์และ DRAM ขนาดใหญ่ สถาปัตยกรรมตาม NUMA นี้ยอดเยี่ยมสำหรับสถาปัตยกรรมหลายการประมวลผลเช่น Redis เนื่องจากมีลักษณะเหมือนเครือข่ายของโหนดที่เล็กกว่า แต่ NUMA นั้นท้าทายกว่าสำหรับสถาปัตยกรรมแบบมัลติเธรด และจากประสบการณ์ของเรากับโปรเจ็กต์มัลติเธรดอื่นๆ นั้น NUMA สามารถลดประสิทธิภาพของที่เก็บข้อมูลในหน่วยความจำได้มากถึง 80%
- ขีดจำกัดปริมาณงานของพื้นที่เก็บข้อมูล – ดิสก์ภายนอก เช่น AWS EBS ไม่ขยายขนาดเร็วเท่ากับหน่วยความจำและ CPU ที่จริงแล้ว มีขีดจำกัดปริมาณงานของพื้นที่เก็บข้อมูลที่กำหนดโดยผู้ให้บริการระบบคลาวด์ตามคลาสเครื่องที่ใช้ ดังนั้น วิธีเดียวที่จะปรับขนาดคลัสเตอร์ได้อย่างมีประสิทธิภาพเพื่อหลีกเลี่ยงปัญหาที่อธิบายไว้แล้วและตรงตามข้อกำหนดการคงอยู่ของข้อมูลสูงคือการใช้การปรับขนาดในแนวนอน กล่าวคือ โดยการเพิ่มโหนดและดิสก์ที่ต่อกับเครือข่ายมากขึ้น
- ดิสก์ชั่วคราว – ดิสก์ชั่วคราวเป็นวิธีที่ยอดเยี่ยมในการรัน Redis บน SSD (โดยที่ SSD ถูกใช้แทน DRAM แต่ไม่ใช่ที่เก็บข้อมูลถาวร) และเพลิดเพลินกับค่าใช้จ่ายของฐานข้อมูลบนดิสก์ในขณะที่ยังคงความเร็ว Redis (ดูวิธีการที่เราดำเนินการ) ด้วย Redis บน Flash) อีกครั้ง เมื่อดิสก์ชั่วคราวถึงขีดจำกัด วิธีที่ดีที่สุด และในหลายกรณี วิธีเดียวที่จะปรับขนาดคลัสเตอร์ของคุณคือการเพิ่มโหนดและดิสก์ชั่วคราวมากขึ้น
- ฮาร์ดแวร์สินค้าโภคภัณฑ์ – สุดท้ายนี้ เรามีลูกค้าในองค์กรจำนวนมากที่ทำงานอยู่ในศูนย์ข้อมูลในพื้นที่ คลาวด์ส่วนตัว และแม้แต่ในศูนย์ข้อมูล Edge ขนาดเล็ก ในสภาพแวดล้อมเหล่านี้ อาจเป็นเรื่องยากที่จะหาเครื่องที่มีหน่วยความจำมากกว่า 64 GB และ 8 CPU และวิธีเดียวที่จะปรับขนาดได้ก็คือแนวนอน
สรุป
เราขอขอบคุณแนวคิดและเทคโนโลยีที่สดใหม่และน่าสนใจจากชุมชนของเราซึ่งนำเสนอโดยคลื่นลูกใหม่ของโครงการแบบมัลติเธรด เป็นไปได้ด้วยซ้ำว่าแนวคิดเหล่านี้บางส่วนอาจเข้าสู่ Redis ได้ในอนาคต (เช่น io_uring ที่เราได้เริ่มมองหาแล้ว พจนานุกรมที่ทันสมัยกว่า ใช้เธรดทางยุทธวิธีมากขึ้น เป็นต้น) แต่สำหรับอนาคตอันใกล้ เราจะไม่ละทิ้งหลักการพื้นฐานของสถาปัตยกรรมหลายกระบวนการที่ไม่มีการแบ่งปันซึ่ง Redis มีให้ การออกแบบนี้ให้ประสิทธิภาพ การปรับขนาด และความยืดหยุ่นที่ดีที่สุด ขณะเดียวกันก็รองรับสถาปัตยกรรมการปรับใช้ที่หลากหลายซึ่งต้องการโดยแพลตฟอร์มข้อมูลแบบเรียลไทม์ในหน่วยความจำ
ภาคผนวก Redis 7.0 เทียบกับรายละเอียดการเปรียบเทียบแมลงปอ
สรุปเกณฑ์มาตรฐาน
เวอร์ชัน:
- เราใช้ Redis 7.0.0 และสร้างจากแหล่งที่มา
- แมลงปอถูกสร้างขึ้นจากแหล่งที่มาในวันที่ 3 มิถุนายน (hash=e806e6ccd8c79e002f721a1a5ecb847bd7a06489) ตามที่แนะนำใน https://github.com/Dragonfly/dragonfly#building-from-source
เป้าหมาย:
- ตรวจสอบว่าผลลัพธ์ของ Dragonfly นั้นทำซ้ำได้และพิจารณาเงื่อนไขทั้งหมดที่ดึงมา (เนื่องจากมีการกำหนดค่าบางอย่างหายไปใน memtier_benchmark เวอร์ชัน OS ฯลฯ… ) ดูข้อมูลเพิ่มเติมที่นี่
- กำหนดประสิทธิภาพของคลัสเตอร์ OSS Redis 7.0.0 ที่ดีที่สุดที่ทำได้เหนืออินสแตนซ์ AWS c6gn.16xlarge ซึ่งตรงกับเกณฑ์มาตรฐานของ Dragonfly
การกำหนดค่าไคลเอ็นต์:
- โซลูชัน OSS Redis 7.0 ต้องการการเชื่อมต่อแบบเปิดจำนวนมากกับ Redis Cluster โดยให้แต่ละ memtier_benchmark เธรดเชื่อมต่อกับชาร์ดทั้งหมด
- โซลูชัน OSS Redis 7.0 ให้ผลลัพธ์ที่ดีที่สุดด้วย memtier_benchmark สองรายการ ประมวลผลการรันเบนช์มาร์กแต่บน VM ไคลเอ็นต์เดียวกันเพื่อให้ตรงกับเกณฑ์มาตรฐานของ Dragonfly)
การใช้ทรัพยากรและการกำหนดค่าที่เหมาะสมที่สุด:
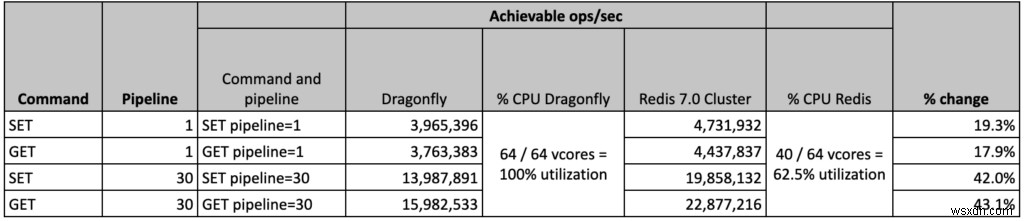
- คลัสเตอร์ OSS Redis ได้รับผลลัพธ์ที่ดีที่สุดด้วย 40 ชาร์ดหลัก ซึ่งหมายความว่ามี vCPU สำรอง 24 รายการบน VM แม้ว่าเครื่องจักรจะยังใช้งานไม่เต็มที่ แต่เราพบว่าการเพิ่มจำนวนชาร์ดไม่ได้ช่วยอะไร แต่ลดประสิทธิภาพโดยรวมลง เรายังคงตรวจสอบพฤติกรรมนี้อยู่
- ในทางกลับกัน โซลูชัน Dragonfly ได้เติม VM อย่างเต็มที่ด้วย VCPU ทั้ง 64 ตัวที่ใช้งานได้ 100%
- สำหรับโซลูชันทั้งสอง เราปรับเปลี่ยนการกำหนดค่าไคลเอ็นต์เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด ดังที่เห็นด้านล่าง เราจัดการการจำลองข้อมูล Dragonfly ส่วนใหญ่และทำได้ดีกว่าผลลัพธ์ที่ดีที่สุดสำหรับไปป์ไลน์ที่เท่ากับ 30
- ซึ่งหมายความว่ามีความเป็นไปได้ที่จะเพิ่มจำนวนที่เราทำได้ด้วย Redis
สุดท้าย เรายังพบว่าทั้ง Redis และ Dragonfly ไม่ได้ถูกจำกัดโดย PPS เครือข่ายหรือแบนด์วิดท์ เนื่องจากเราได้ยืนยันแล้วว่าระหว่าง 2 VM ที่ใช้ (สำหรับไคลเอนต์และเซิร์ฟเวอร์ บอทที่ใช้ c6gn.16xlarge) เราสามารถเข้าถึง> 10M PPS และ>30 Gbps สำหรับ TCP พร้อมเพย์โหลด ~300B
วิเคราะห์ผลลัพธ์
- รับไปป์ไลน์ 1 มิลลิวินาทีย่อย :
- OSS Redis:4.43M ops/วินาที โดยที่ทั้ง avg และ p50 มีเวลาในการตอบสนองต่ำกว่ามิลลิวินาที เวลาแฝงของไคลเอ็นต์โดยเฉลี่ยคือ 0.383 ms
- Dragonfly อ้างว่า 4M ops/วินาที:
- เราสามารถทำซ้ำได้ 3.8 ล้าน ops/วินาที โดยมีเวลาแฝงเฉลี่ยของไคลเอ็นต์ 0.390 ms
- Redis vs Dragonfly – ปริมาณงาน Redis มากกว่า 10% เทียบกับแมลงปออ้างผลและ 18% เทียบกับผลของแมลงปอ ซึ่งเราสามารถสืบพันธุ์ได้
- รับไปป์ไลน์ 30:
- OSS Redis:22.9M ops/วินาที โดยมีเวลาแฝงของไคลเอ็นต์เฉลี่ย 2.239 ms
- แมลงปออ้างสิทธิ์ 15M ops/วินาที:
- เราสามารถทำซ้ำได้ 15.9 ล้าน ops/วินาที โดยมีเวลาแฝงเฉลี่ยของไคลเอ็นต์ที่ 3.99 ms
- Redis vs Dragonfly – Redis ดีกว่า 43% (เทียบกับผลการสืบพันธุ์ของแมลงปอ) และโดย 52% (เทียบกับผลการอ้างสิทธิ์ของแมลงปอ)
- SET ไปป์ไลน์ 1 มิลลิวินาที :
- OSS Redis:4.74M ops/วินาที โดยที่ทั้ง avg และ p50 มีเวลาในการตอบสนองต่ำกว่ามิลลิวินาที เวลาแฝงของไคลเอ็นต์โดยเฉลี่ยคือ 0.391 ms
- Dragonfly อ้างว่า 4M ops/วินาที:
- เราสามารถทำซ้ำได้ 4M ops/วินาที โดยมีเวลาแฝงเฉลี่ยของไคลเอ็นต์ 0.500 ms
- Redis vs Dragonfly – Redis ดีกว่า 19% (เราทำซ้ำผลลัพธ์เดียวกันกับที่ Dragonfly อ้างว่ามี)
- SET ไปป์ไลน์ 30:
- OSS Redis:19.85M ops/วินาที โดยมีเวลาแฝงเฉลี่ยของไคลเอ็นต์ 2.879 ms
- Dragonfly อ้างสิทธิ์ 10M ops/วินาที:
- เราสามารถทำซ้ำได้ 14M ops/วินาที โดยมีเวลาแฝงเฉลี่ยของไคลเอ็นต์ 4.203 ms)
- Redis vs Dragonfly – Redis ดีกว่า 42% (เทียบกับผลการสืบพันธุ์ของแมลงปอ) และ 99% (เทียบกับผลการอ้างสิทธิ์ของแมลงปอ)
memtier_benchmark คำสั่งที่ใช้สำหรับแต่ละรูปแบบ:
- รับไปป์ไลน์ 1 มิลลิวินาทีย่อย
- เรดิส:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ฮิสโตแกรม
- แมลงปอ:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- เรดิส:
- รับไปป์ไลน์ 30
- เรดิส:
- 2X:memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -histogram –pipeline 30
- แมลงปอ:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- เรดิส:
- SET ไปป์ไลน์ 1 มิลลิวินาที
- เรดิส:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -ฮิสโตแกรม
- แมลงปอ:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- เรดิส:
- SET ไปป์ไลน์ 30
- เรดิส:
- 2X:memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide -histogram –pipeline 30
- แมลงปอ:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- เรดิส:
รายละเอียดโครงสร้างพื้นฐาน
เราใช้ประเภท VM เดียวกันสำหรับทั้งไคลเอนต์ (สำหรับการเรียกใช้ memtier_benchmark) และเซิร์ฟเวอร์ (สำหรับการเรียกใช้ Redis และ Dragonfly) นี่คือข้อมูลจำเพาะ:
- VM :
- AWS c6gn.16xlarge
- aarch64
- ARM Neoverse-N1
- คอร์ต่อซ็อกเก็ต:64
- เธรดต่อคอร์:1
- NUMA โหนด:1
- AWS c6gn.16xlarge
- เคอร์เนล:Arm64 เคอร์เนล 5.10
- Installed Memory: 126GB
