
วันนี้เรามีความยินดีที่จะประกาศเปิดตัว RedisGraph 2.8 ความพร้อมใช้งานทั่วไป โพสต์บล็อกนี้ให้รายละเอียดเกี่ยวกับคุณลักษณะใหม่ที่สำคัญที่มีให้บริการในขณะนี้
เกี่ยวกับ RedisGraph
RedisGraph เป็นโครงสร้างข้อมูลกราฟที่เน้นหน่วยความจำเป็นอันดับแรกสำหรับ Redis RedisGraph รองรับการเช่าหลายกราฟ (สามารถเก็บกราฟได้จำนวนมากพร้อมกัน) และสามารถให้บริการลูกค้าหลายรายที่เข้าถึงกราฟได้พร้อมกัน ตอนนี้มีให้ใช้งานโดยเป็นส่วนหนึ่งของ Redis Stack
ฟีเจอร์ใหม่ที่สำคัญใน RedisGraph 2.8
- รูปแบบกราฟที่สมบูรณ์ยิ่งขึ้น
- โหนดที่มีป้ายกำกับหลายรายการ
- เพิ่มความสามารถในการสืบค้นข้อมูล
- ปรับปรุงการค้นหาข้อความแบบเต็ม
- รองรับโครงสร้าง ฟังก์ชัน และตัวดำเนินการ Cypher เพิ่มเติม
- ปรับปรุงประสิทธิภาพ
- ดัชนีเหนือคุณสมบัติของความสัมพันธ์
- เดลต้าเมทริกซ์
- บัฟเฟอร์การสร้างโหนดที่ควบคุมได้
- เกณฑ์มาตรฐาน
https://redis.com/blog/redisgraph-2-8-is-generally-available/(เปิดในแท็บใหม่)
รูปแบบกราฟที่สมบูรณ์ยิ่งขึ้น
โหนดที่มีป้ายกำกับหลายรายการ
คำจำกัดความมากมายของแบบจำลองข้อมูลกราฟคุณสมบัติที่มีป้ายกำกับ (LPG) (เช่น แบบจำลองฐานข้อมูลกราฟคุณสมบัติ – มุม 2018 และร่าง ISO/IEC JTC 1/SC 32 – GQL) ระบุว่าโหนดสามารถมีป้ายกำกับได้หลายป้าย RedisGraph รองรับเพียงป้ายกำกับเดียวจนถึงเวอร์ชัน 2.8 ณ ตอนนี้ เราสามารถเพิ่มป้ายกำกับได้หลายป้ายในแต่ละโหนดโดยไม่ลดประสิทธิภาพการทำงานหรือหน่วยความจำเพิ่มขึ้นอย่างมาก
ในการสร้างโหนดที่มีป้ายกำกับหลายรายการ คุณเพียงแค่แสดงรายการป้ายกำกับทั้งหมดที่คั่นด้วยเครื่องหมายทวิภาค:
GRAPH.QUERY g "CREATE (e:Employee:BoardMember {Name:'Vincent Chan', Title:'Web marketing lead'}) return e" หากต้องการจับคู่โหนดที่มีป้ายกำกับหลายรายการ (เงื่อนไข AND) คุณควรใช้เครื่องหมายโคลอนเดียวกันเช่นกัน:
GRAPH.QUERY g "MATCH (e:Employee:BoardMember) return e"
ปรับปรุงความสามารถในการสืบค้น
ปรับปรุงการค้นหาข้อความแบบเต็ม
RedisGraph มาพร้อมกับ RedisSearch และใช้ประโยชน์จากการจัดทำดัชนีรอง แต่ยังสามารถใช้สำหรับการจัดทำดัชนีและการค้นหาขั้นสูงได้อีกด้วย ตัวอย่างเช่น ค้นหาโหนดตามความใกล้ชิดทางภูมิศาสตร์กับจุดที่กำหนดบนโลก หรือให้คะแนนรายการที่เกี่ยวข้องสูงขึ้น
เวอร์ชัน 2.8 เพิ่มตัวเลือกการกำหนดค่าภาษาและคำหยุด ภาษากำหนดภาษาที่จะใช้สำหรับการสร้างข้อความ ซึ่งเป็นการเพิ่มรูปแบบพื้นฐานของคำลงในดัชนี ซึ่งจะทำให้แบบสอบถามสำหรับ "going" สามารถส่งคืนผลลัพธ์สำหรับ "go" และ "gone" เป็นต้น คำหยุดเป็นคำทั่วไป (เช่น “is, the, an, and…”) ซึ่งไม่ได้เพิ่มข้อมูลในการค้นหามากนักแต่กินพื้นที่ในดัชนีค่อนข้างมาก คำเหล่านี้จะไม่ถูกสร้างดัชนีและละเว้นเมื่อทำการค้นหา คำค้นหาที่มีคำหยุดอยู่ในนั้น เช่น "ในปารีส" จะถูกมองว่าเป็น "ปารีส" เท่านั้น
ในการสร้างดัชนีข้อความแบบเต็มในคุณสมบัติชื่อเรื่องของภาพยนตร์โดยใช้ภาษาเยอรมันและใช้คำหยุดที่กำหนดเองของโหนดทั้งหมดที่มีป้ายกำกับ ภาพยนตร์:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex({ label:'Movie', ภาษา:'German', คำหยุด:['a', 'ab'] }, 'title')"
RediSearch มีตัวเลือกการกำหนดค่าช่องเพิ่มเติม 3 ตัวเลือก:
- น้ำหนัก – ความสำคัญของข้อความในช่อง
- nostem – ข้ามการต่อท้ายเมื่อสร้างดัชนีข้อความ
- สัทศาสตร์ – เปิดใช้งานการค้นหาแบบออกเสียงบนข้อความ
ในการสร้างดัชนีข้อความแบบเต็มในคุณสมบัติชื่อด้วยการค้นหาแบบออกเสียงของโหนดทั้งหมดที่มีป้ายกำกับ ภาพยนตร์:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex('Movie', {field:'title', phonetic:'dm:en'})" รองรับโครงสร้าง ฟังก์ชัน และตัวดำเนินการ Cypher เพิ่มเติม
RedisGraph 2.8 ขยายการรองรับ Cypher:
- ความเข้าใจรูปแบบ
- เพิ่มการรองรับ
allShortestPaths
ฟังก์ชัน - ฟังก์ชัน Cypher:
คีย์ ลด แทนที่ ไม่มี
และซิงเกิ้ล
- การคัดลอกชุดแอตทริบิวต์โหนดใน
SET
อนุประโยค - กรองตามป้ายกำกับโหนดใน
WHERE
อนุประโยค - ตัวดำเนินการ Cypher:
XOR
และ^
ความเข้าใจรูปแบบ
ความเข้าใจรูปแบบเป็นโครงสร้างวากยสัมพันธ์ที่มีอยู่ใน Cypher แม้ว่าการเข้าใจรายการจะช่วยให้เราสร้างรายการตามรายการที่มีอยู่ได้ ความเข้าใจรูปแบบเป็นวิธีเติมรายการด้วยผลลัพธ์ของการจับคู่รูปแบบ โดยจะจับคู่กับรูปแบบที่กำหนดตามมาตรฐาน
MATCHประโยคโดยมีภาคแสดงเหมือนในมาตรฐาน
WHEREข้อ แต่ให้ผลการฉายที่ระบุ
ตัวอย่างเช่น แบบสอบถามต่อไปนี้จะส่งคืนรายการที่มีประเภทการให้ทุนทั้งหมดที่ได้รับโดยพนักงานชาย โดยที่จำนวนเงินให้สิทธิ์มากกว่า $1,000
GRAPH.QUERY g "CREATE (e:Employee {gender:'Male'})-[:granted]->(g:Grant {type:'Research', amount:2000})"
GRAPH.QUERY g "MATCH (e:Employee {gender:'Male'}) RETURN [(e)-[:granted]->(g:Grant) WHERE g.amount> 1000 | g.type] AS GrantTypes" เพิ่มการสนับสนุนสำหรับ allShortestPaths ฟังก์ชัน
allShortestPathsฟังก์ชันส่งคืนเส้นทางที่สั้นที่สุดระหว่างคู่ของเอนทิตีที่ตรงกับเกณฑ์ทั้งหมด เอนทิตีทั้งสองต้องถูกผูกไว้ก่อนหน้า
WITH-กำหนดขอบเขต
GRAPH.QUERY DEMO_GRAPH "MATCH (c:Actor {name:'Charlie Sheen'}), (k:Actor {name:'Kevin Bacon'}) WITH c, k MATCH p =allShortestPaths((c)-[ :PLAYED_WITH*]->(k)) RETURN nodes(p) ในฐานะนักแสดง" ข้อความค้นหานี้จะสร้างเส้นทางทั้งหมดที่มีความยาวขั้นต่ำที่เชื่อมต่อโหนดนักแสดงที่เป็นตัวแทนของ Charlie Sheen กับเส้นทางที่เป็นตัวแทนของ Kevin Bacon มีเส้นทางแบบ 2 ฮอปหลายเส้นทางระหว่างนักแสดงสองคน และทั้งหมดนี้จะถูกส่งคืน การคำนวณเส้นทางจะสิ้นสุดลง เนื่องจากเราไม่สนใจเส้นทางใดที่มีความยาวมากกว่า 2
อาจระบุความยาวขั้นต่ำ (ต้องเป็น 1) และความยาวสูงสุด (อย่างน้อย 1) สำหรับการค้นหา อาจมีการระบุประเภทความสัมพันธ์ตั้งแต่ศูนย์ขึ้นไป (เช่น
[:R|Q*1..3]). ห้ามใช้ตัวกรองคุณสมบัติในรูปแบบ
เพิ่มการสนับสนุนสำหรับ กุญแจ ฟังก์ชัน Cypher
คีย์ฟังก์ชั่นยอมรับโหนด ความสัมพันธ์ หรือแผนที่เป็นอินพุต และส่งคืนอาร์เรย์ของคีย์ทั้งหมดที่อินพุตมี
MATCH (a) คีย์ RETURN (a)
MATCH ()-[e]->() คีย์ย้อนกลับ (e)
คีย์ RETURN ({a:1, b:2})
เพิ่มการสนับสนุนสำหรับ ลด ฟังก์ชัน Cypher
ลดฟังก์ชั่นยอมรับค่าเริ่มต้นและรายการ จากนั้นจะอัปเดตค่าโดยการประเมินนิพจน์เทียบกับแต่ละองค์ประกอบของรายการ
GRAPH.QUERY g "RETURN reduce(sum =0, n IN range(1,10) | sum + n)"
ผลลัพธ์ของฟังก์ชันนี้จะเป็น 55 – ผลรวมของจำนวนเต็มระหว่าง 1 ถึง 10
GRAPH.QUERY g "RETURN reduce(arr =[], n IN range(1,10) | arr + [n*n])"
ผลลัพธ์ของฟังก์ชันนี้จะเป็นอาร์เรย์ที่มีกำลังสองของจำนวนเต็มระหว่าง 1 ถึง 10
เพิ่มการรองรับการแทนที่ฟังก์ชันสตริง Cypher
แทนที่การเกิดขึ้นทั้งหมดของสตริงย่อยที่กำหนดด้วยสตริงย่อยอื่น ฟังก์ชันได้รับพารามิเตอร์ 3 ตัว ได้แก่ สตริงเดิม รายการที่จะแทนที่ และรายการที่จะแทนที่ด้วย
GRAPH.QUERY g "RETURN replace('abc*efg', '*', 'd')" ค่าที่ส่งคืนจะเป็น 'abcdefg'
ฟังก์ชันนี้ยังสามารถลบสตริงย่อยได้ด้วยการแทนที่ด้วยสตริงว่าง (‘’)
เพิ่มการสนับสนุนสำหรับ ไม่มี และ โสด ฟังก์ชัน Cypher
เมื่อระบุรายการ จะไม่มีการคืนค่าใดเป็น จริง หากเพรดิเคตไม่มีองค์ประกอบใด ๆ ในขณะที่รายการเดียว คืนค่า จริง หากเพรดิเคตที่ระบุมีองค์ประกอบเพียงรายการเดียว
GRAPH.QUERY g "RETURN none(x IN range(1,10) WHERE x>10)"
GRAPH.QUERY g "RETURN single(x IN range(1,10) WHERE x>9)"
ฟังก์ชันเหล่านี้คล้ายกับฟังก์ชันทั้งหมดและทุกฟังก์ชัน
กรณีการใช้งานที่เป็นไปได้อย่างหนึ่งคือการกรองเส้นทาง:
graph.query DEMO_GRAPH “MATCH p =(a {name:'Johnny Depp'})-[*2..5]->(b {name:'Kevin Bacon'}) WHERE none(n IN nodes(p) WHERE น.ปี> 2513) ผลตอบแทน p”
ข้อความค้นหานี้จะส่งคืนเส้นทางทั้งหมดที่มีความยาว 2 ถึง 5 จาก Johnny Depp ถึง Kevin Bacon ซึ่งรวมถึงไม่มีนักแสดงที่เกิดหลังปี 1970
เพิ่มการรองรับการคัดลอกชุดแอตทริบิวต์โหนดใน SET
อนุประโยค
SETสามารถใช้แทนหรือผนวกค่าคุณสมบัติทั้งหมดของโหนดหนึ่งกับค่าคุณสมบัติของโหนดอื่นได้
แบบสอบถามต่อไปนี้จะจับคู่สองเอนทิตี แล้วแทนที่คุณสมบัติของ a ทั้งหมดด้วยคุณสมบัติของ b:
GRAPH.QUERY g "MATCH (a {v:1}), (b {v:2}) SET a =b" แบบสอบถามต่อไปนี้จะจับคู่สองเอนทิตี แล้วเพิ่ม (หรือแทนที่ค่า) ของคุณสมบัติของ a ด้วยคุณสมบัติของ b
GRAPH.QUERY g "MATCH (a {v:1}), (b {v:2}) SET a +=b" นอกจากนี้เรายังสามารถเปลี่ยนประเภทของความสัมพันธ์โดยไม่ต้องเปลี่ยนคุณสมบัติ:
GRAPH.QUERY g "MATCH (a)-[b]->(c) WHERE ID(b)=0 CREATE (a)-[d:bar]->(c) SET d=b DELETE b RETURN ง"
เพิ่มการรองรับการกรองตามป้ายกำกับโหนดใน ที่ไหน ประโยค
ขณะนี้สามารถกรองตามป้ายกำกับโหนดหรือประเภทความสัมพันธ์ได้ในส่วนคำสั่ง WHERE:
GRAPH.QUERY g "MATCH (a) WHERE a:L RETURN a"
GRAPH.QUERY g "MATCH (a)-[b]-(c) WHERE b:L RETURN b"
เพิ่มการรองรับสำหรับตัวดำเนินการ Cypher XOR และ ^
GRAPH.QUERY g "RETURN true XOR true"
GRAPH.QUERY g "RETURN 2 ^ 3”
ผลลัพธ์
เท็จและ
8ตามลำดับ
ปรับปรุงประสิทธิภาพ
ดัชนีเหนือคุณสมบัติของความสัมพันธ์
สำหรับโหนด เราสามารถแนะนำดัชนีโดยออกคำสั่งต่อไปนี้
GRAPH.QUERY g "CREATE INDEX FOR (n:GRANTS) ON (n.GrantedBy)"
ขณะนี้สามารถแนะนำดัชนีสำหรับความสัมพันธ์ได้เช่นกัน:
GRAPH.QUERY g "CREATE INDEX FOR ()-[r:R]-() ON (r.prop)"
พิจารณาคำถามต่อไปนี้:
GRAPH.QUERY g "MATCH (a)-[r:R {prop:5}]-(b) return *" สังเกตแผนปฏิบัติการก่อนสร้างดัชนี:
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *" 1) "ผลลัพธ์" |
และนี่คือแผนการดำเนินการสำหรับแบบสอบถามเดียวกันหลังจากสร้างดัชนี:
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *" 1) "ผลลัพธ์" |
เดลต้าเมทริกซ์
ตั้งแต่เวอร์ชัน 2.8 โหนดกราฟและการเพิ่มและการลบความสัมพันธ์จะเร็วกว่ามาก เนื่องจากจะมีการอัปเดตครั้งแรกในเมทริกซ์เดลต้าขนาดเล็ก จากนั้นเมทริกซ์หลักจะอัปเดตเป็นกลุ่ม
ใน RedisGraph กราฟจะแสดงด้วยเมทริกซ์ที่อยู่ติดกัน ป้ายกำกับโหนดและทุกประเภทความสัมพันธ์ในกราฟมีเมทริกซ์ของตัวเอง ก่อนหน้านี้ ทุกครั้งที่มีการเพิ่มโหนดใหม่ลงในกราฟ เมทริกซ์ทั้งหมดจำเป็นต้องปรับขนาด และฐานข้อมูลที่ใหญ่ขึ้น ก็ยิ่งใช้เวลามากขึ้นเท่านั้น
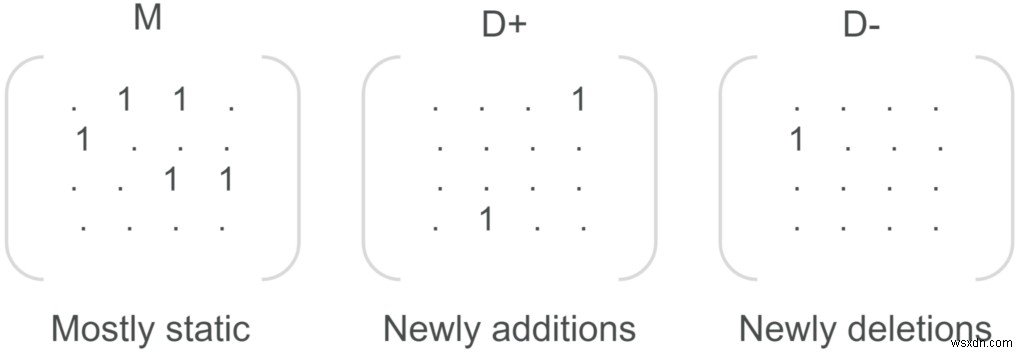
ตั้งแต่ v2.8 เวลาที่ใช้ในการแทรกโหนดใหม่และความสัมพันธ์จะน้อยลงอย่างมาก และไม่ขึ้นอยู่กับขนาดของกราฟอีกต่อไป การปรับให้เหมาะสมนี้ทำได้โดยการแนะนำเมทริกซ์เดลต้าสองตัวสำหรับทุกเมทริกซ์ในกราฟ:อันหนึ่งสำหรับการเพิ่มโหนด (D+) และอีกอันสำหรับการลบโหนด (D-) การเพิ่มและการลบโหนดจะแสดงในเมทริกซ์เดลต้าที่เหมาะสม และเมื่อเมทริกซ์เดลต้าถึงขีดจำกัด 10,000 โหนด (กำหนดค่าได้ผ่าน
DELTA_MAX_PENDING_CHANGESพารามิเตอร์การกำหนดค่า) จะซิงโครไนซ์กับเมทริกซ์หลักในการดำเนินการเป็นกลุ่มเดียว ว่าง และรอบเดียวกันสามารถเริ่มต้นใหม่ได้อีกครั้ง
บัฟเฟอร์การสร้างโหนดที่ควบคุมได้
พารามิเตอร์การกำหนดค่าเวลาในการโหลดใหม่ NODE_CREATION_BUFFER ควบคุมจำนวนหน่วยความจำที่สงวนไว้ในเมทริกซ์สำหรับการสร้างโหนดในอนาคต ตัวอย่างเช่น เมื่อตั้งค่าเป็น 16,384 เมทริกซ์จะมีพื้นที่เพิ่มเติมสำหรับโหนด 16384 เมื่อสร้าง เมื่อใดก็ตามที่พื้นที่ส่วนเกินหมด ขนาดของเมทริกซ์จะเพิ่มขึ้น 16384
การลดค่านี้จะลดการใช้หน่วยความจำ แต่ทำให้ประสิทธิภาพลดลงเนื่องจากความถี่ที่เพิ่มขึ้นของการจัดสรรใหม่ของเมทริกซ์ ในทางกลับกัน การเพิ่มขึ้นอาจช่วยปรับปรุงประสิทธิภาพสำหรับเวิร์กโหลดที่มีการเขียนมากแต่จะเพิ่มการใช้หน่วยความจำ
หากอาร์กิวเมนต์ที่ส่งผ่านไม่ใช่ยกกำลัง 2 อาร์กิวเมนต์นั้นจะถูกปัดเศษขึ้นเป็นยกกำลังสูงสุด 2 ตัวเพื่อปรับปรุงการจัดตำแหน่งหน่วยความจำ
เกณฑ์มาตรฐาน
เรายังได้เพิ่มการปรับปรุงประสิทธิภาพอื่นๆ อีกมากมายนอกเหนือจากเมทริกซ์เดลต้า เราสาธิตการปรับปรุงเหล่านี้ด้านล่างโดยใช้เกณฑ์มาตรฐาน LDBC SNB
LDBC SNB (Linked Data Benchmark Council – Social Network Benchmarks) เป็นเกณฑ์มาตรฐานอุตสาหกรรมสำหรับการเปรียบเทียบปริมาณงานการอ่านและเขียนฐานข้อมูลแบบกราฟในโลกแห่งความเป็นจริง
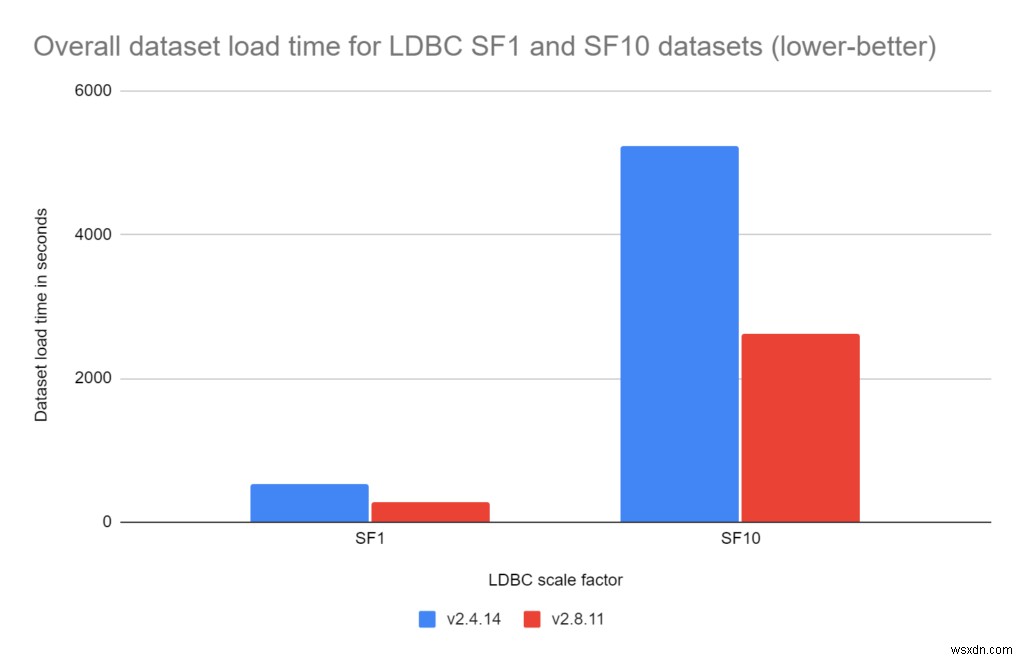
โหลดข้อมูลโดยรวมเร็วขึ้นมากใน RedisGraph 2.8:
- ตัวคูณสเกล LDBC 1:
RedisGraph 2.8 เร็วกว่า RedisGraph 2.4 . 1.92 เท่า
- ตัวคูณสเกล LDBC 10:
RedisGraph 2.8 เร็วกว่า RedisGraph 2.4 2.00 เท่า
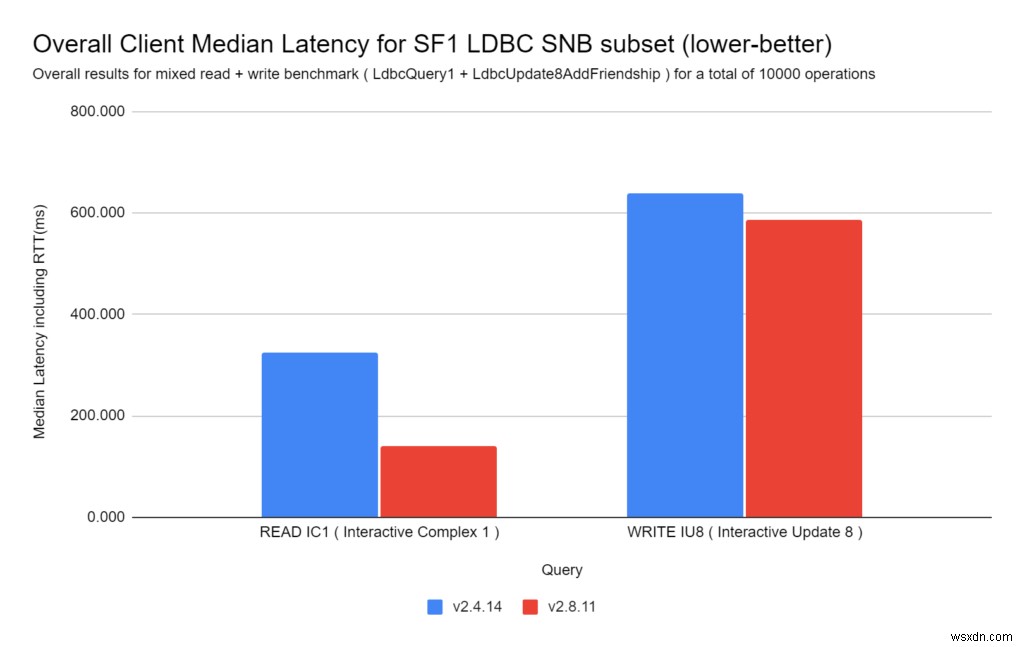
การสืบค้น LDBC (ทั้งการอ่านและการเขียน) ดำเนินการเร็วกว่ามากใน RedisGraph 2.8:
- อ่านข้อความค้นหา:
RedisGraph 2,8 เร็วกว่า RedisGraph 2.4 . 2.32 เท่า
- เขียนคำถาม:
RedisGraph 2,8 เร็วกว่า RedisGraph 2.4 ถึง 1.09 เท่า
การกู้คืนและการซิงค์ข้อมูล (RDB และ AOF) นั้นเร็วกว่ามากเช่นกัน (ขึ้นอยู่กับลำดับความสำคัญเร็วขึ้นหลายระดับในบางสถานการณ์)
RedisGraph เป็นส่วนหนึ่งของ Redis Stack
RedisGraph เป็นส่วนหนึ่งของ Redis Stack แล้ว คุณสามารถดาวน์โหลดไบนารี Redis Stack Server ล่าสุดสำหรับ macOS, Ubuntu หรือ Redhat หรือติดตั้งด้วย Docker, Homebrew หรือ Linux
สัมผัสประสบการณ์ RedisGraph โดยใช้ RedisInsight
RedisInsight เป็นเครื่องมือภาพสำหรับนักพัฒนาที่มอบวิธีที่ยอดเยี่ยมในการสำรวจข้อมูลจาก RedisTimes ระหว่างการพัฒนาโดยใช้ Redis หรือ Redis Stack
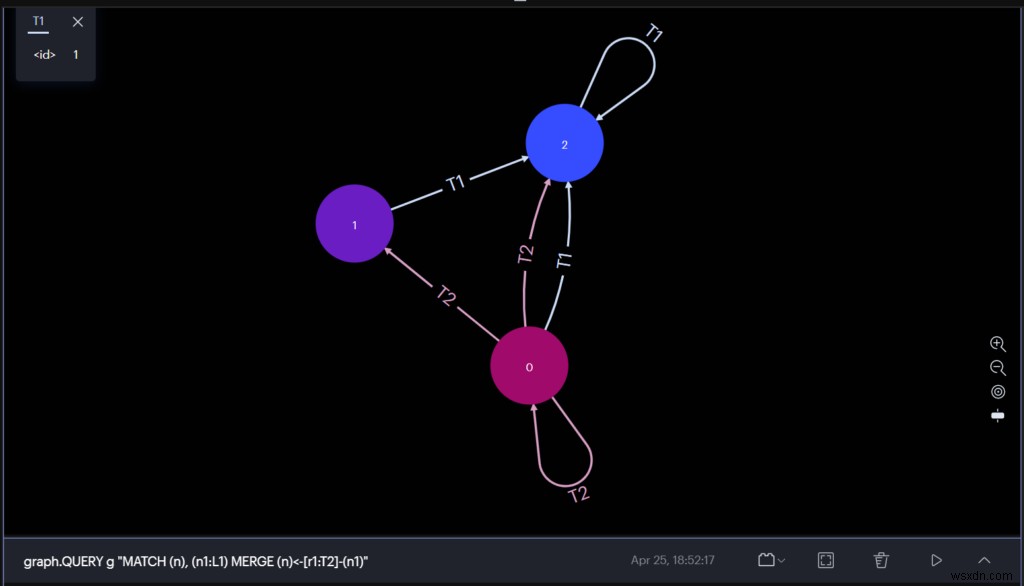
คุณสามารถดำเนินการสืบค้นข้อมูลแบบกราฟและสังเกตผลลัพธ์ได้โดยตรงจากส่วนต่อประสานกราฟิกกับผู้ใช้ RedisInsight สามารถแสดงภาพผลลัพธ์การสืบค้น RedisGraph ได้แล้ว
นอกจากนี้ RedisInsight ยังมีคำแนะนำและบทช่วยสอนฉบับย่อสำหรับการเรียนรู้ RedisGraph แบบโต้ตอบ
เรียนรู้เพิ่มเติมเกี่ยวกับ RedisGraph บน redis.io และ developer.redis.com
