
การถดถอยเชิงเส้นเป็นหนึ่งในเครื่องมือมาตรฐานที่ง่ายที่สุดในการเรียนรู้ของเครื่องเพื่อระบุว่ามีความสัมพันธ์เชิงบวกหรือเชิงลบระหว่างสองตัวแปร
การถดถอยเชิงเส้นเป็นหนึ่งในเครื่องมือที่ดีไม่กี่อย่างสำหรับการวิเคราะห์เชิงคาดการณ์อย่างรวดเร็ว ในส่วนนี้ เราจะใช้แพ็คเกจ python pandas เพื่อโหลดข้อมูล จากนั้นจึงประมาณ ตีความ และแสดงภาพโมเดลการถดถอยเชิงเส้น
ก่อนจะลงลึกกว่านี้ เรามาคุยกันก่อนว่าการถดถอยคืออะไร
การถดถอยคืออะไร
การถดถอยเป็นรูปแบบหนึ่งของเทคนิคการสร้างแบบจำลองการทำนายซึ่งช่วยในการสร้างความสัมพันธ์ระหว่างตัวแปรตามและตัวแปรอิสระ
ประเภทของการถดถอย
- การถดถอยเชิงเส้น
- โลจิสติกถดถอย
- การถดถอยพหุนาม
- การถดถอยแบบขั้นตอน
การถดถอยเชิงเส้นใช้ที่ไหน
- การประเมินแนวโน้มและการประเมินยอดขาย
- การวิเคราะห์ผลกระทบของการเปลี่ยนแปลงราคา
- การประเมินความเสี่ยง
ขั้นตอนในการสร้างแบบจำลองการถดถอยเชิงเส้น
-
อันดับแรก เราจะสร้างการตั้งค่าและดาวน์โหลดชุดข้อมูลและ jupyter (ซึ่งฉันใช้สำหรับบทช่วยสอนนี้ คุณสามารถใช้ IDE อื่นๆ เช่น anaconda หรือ like)
-
นำเข้าแพ็คเกจและชุดข้อมูลที่จำเป็น
-
เมื่อโหลดชุดข้อมูลแล้ว เราจะสำรวจชุดข้อมูลของเรา
-
จะทำการถดถอยเชิงเส้นกับชุดข้อมูลของเรา
-
จากนั้นเราจะสำรวจความสัมพันธ์ระหว่างตัวแปรกับช่วงเวลาของวัน
-
สรุป
ตั้งค่า
ดาวน์โหลดชุดข้อมูลได้จากลิงค์ด้านล่าง
http://en.openei.org/datasets/dataset/649aa6d3-2832-4978-bc6e-fa563568398e/resource/b710e97d-29c9-4ca5-8137-63b7cf447317/download/building1retail.csv
ซึ่งเราจะใช้ในการสร้างแบบจำลองกำลังของอาคารโดยใช้อุณหภูมิอากาศภายนอกอาคาร (OAT) เป็นตัวแปรอธิบาย
บันทึกไฟล์ csv ในโฟลเดอร์เดียวกับที่ติดตั้ง jupyter หรือ IDE ของเรา
นำเข้าไลบรารีและชุดข้อมูลที่จำเป็น
ประการแรก เราจะนำเข้าไลบรารีที่จำเป็น จากนั้นอ่านชุดข้อมูลโดยใช้ไลบรารี pandas python
# Importing Necessary Libraries
import pandas as pd
#Required for numerical functions
import numpy as np
from scipy import stats
from datetime import datetime
from sklearn import preprocessing
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
#For plotting the graph
import matplotlib.pyplot as plt
%matplotlib inline
# Reading Data
df = pd.read_csv('building1retail.csv', index_col=[0],
date_parser=lambda x: datetime.strptime(x, "%m/%d/%Y %H:%M"))
df.head() ผลลัพธ์

สำรวจชุดข้อมูล
ขั้นแรก เรามาลองนึกภาพชุดข้อมูลของเราโดยลงจุดกับแพนด้ากัน
df.plot(figsize=(22,6))
ผลลัพธ์
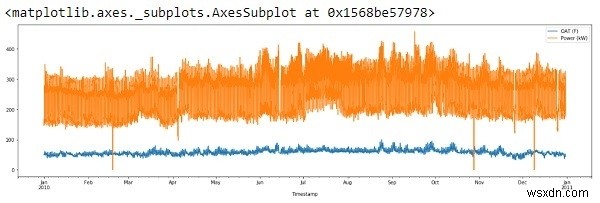
ดังนั้น แกน x กำลังแสดงข้อมูลตั้งแต่ ม.ค. 2553 – ม.ค. 2554
หากเราเห็นผลลัพธ์ข้างต้น เราจะสังเกตเห็นว่ามีสองสิ่งแปลก ๆ เกี่ยวกับโครงเรื่อง:
-
ดูเหมือนว่าจะไม่มีข้อมูลที่ขาดหายไป หากต้องการตรวจสอบ ให้เรียกใช้:
df.isnull().values.any()
ผลลัพธ์
False
ผลลัพธ์ที่เป็นเท็จกำลังบอกเราว่าไม่มีค่า Null ในดาต้าเฟรม
-
ปรากฏว่ามีความผิดปกติบางอย่างในข้อมูล (แหลมยาวลง)
ความผิดปกติหรือ 'ค่าผิดปกติ' โดยทั่วไปเป็นผลมาจากข้อผิดพลาดในการทดลองหรืออาจเป็นค่าที่แท้จริง ไม่ว่าในกรณีใด เราจะละทิ้งมันไปเพราะมันส่งผลกระทบอย่างรุนแรงต่อความชันของเส้นถดถอย
ก่อนที่เราจะทิ้ง 'ค่าผิดปกติ' ให้ตรวจสอบก่อนว่าข้อมูลของเราแสดงการกระจายประเภทใด:
df.hist()
ผลลัพธ์
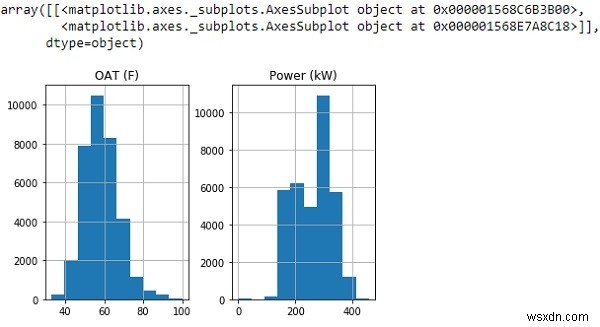
จากฮิสโตแกรมด้านบน เราจะเห็นกราฟของเราแสดงข้อมูลที่ประมาณการแจกแจงแบบปกติอย่างคร่าวๆ
ให้วางค่าทั้งหมดที่มากกว่าค่าเบี่ยงเบนมาตรฐานมากกว่า 3 ค่าจากค่าเฉลี่ยแล้วพลอตดาต้าเฟรมใหม่
std_dev = 3 df = df[(np.abs(stats.zscore(df)) < float(std_dev)).all(axis=1)] df.plot(figsize=(22, 6))
ผลลัพธ์
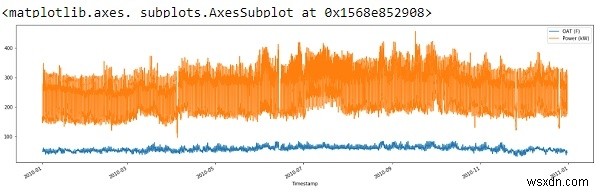
จากผลลัพธ์ข้างต้น เราจะเห็นได้ว่าเราได้ลบจุดแหลมออกในระดับหนึ่งและทำความสะอาดข้อมูลของเราแล้ว
ตรวจสอบความสัมพันธ์เชิงเส้น
เพื่อดูว่ามีความสัมพันธ์เชิงเส้นตรงระหว่าง OAT และกำลังหรือไม่ ให้ลองวาดแผนภาพแบบกระจายง่ายๆ:
plt.scatter(df['OAT (F)'], df['Power (kW)'])
ผลลัพธ์
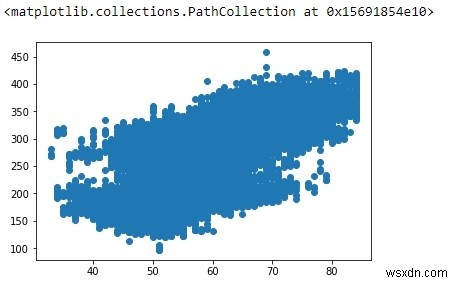
การถดถอยเชิงเส้น
ในการรันโมเดลและประเมินประสิทธิภาพ เราจะใช้โมดูล Scikit-learn ด้วย เราจะใช้ k-folds cross validation (k=3) เพื่อประเมินประสิทธิภาพของโมเดลของเรา
X = pd.DataFrame(df['OAT (F)']) y = pd.DataFrame(df['Power (kW)']) model = LinearRegression() scores = [] kfold = KFold(n_splits=3, shuffle=True, random_state=42) for i, (train, test) in enumerate(kfold.split(X, y)): model.fit(X.iloc[train,:], y.iloc[train,:]) score = model.score(X.iloc[test,:], y.iloc[test,:]) scores.append(score) print(scores)
ผลลัพธ์
[0.38768927735902703, 0.3852220878090444, 0.38451654781487116]
ในโปรแกรมข้างต้น model =LinearRegression() จะสร้างโมเดลการถดถอยเชิงเส้น และ for loop จะแบ่งชุดข้อมูลออกเป็นสามส่วน จากนั้นในลูป เราจะปรับข้อมูลให้พอดีแล้วประเมินประสิทธิภาพโดยผนวกคะแนนเข้ากับรายการ
อย่างไรก็ตาม ผลลัพธ์ดูไม่ดีและเราปรับปรุงประสิทธิภาพได้
ช่วงเวลาของวัน
กำลัง (ตัวแปร) ขึ้นอยู่กับช่วงเวลาของวันเป็นอย่างมาก ลองใช้ข้อมูลนี้เพื่อรวมเข้ากับโมเดลการถดถอยของเราโดยใช้การเข้ารหัสแบบใช้ครั้งเดียว
model = LinearRegression() scores = [] kfold = KFold(n_splits=3, shuffle=True, random_state=42) for i, (train, test) in enumerate(kfold.split(X, y)): model.fit(X.iloc[train,:], y.iloc[train,:]) scores.append(model.score(X.iloc[test,:], y.iloc[test,:])) print(scores)
ผลลัพธ์
[0.8074246958895391, 0.8139449185141592, 0.8111379602960773]
นั่นคือความแตกต่างอย่างมากที่เรามีในโมเดลของเรา
สรุป
ในส่วนนี้ เราได้เรียนรู้พื้นฐานของการสำรวจชุดข้อมูลและเตรียมชุดข้อมูลให้พอดีกับแบบจำลองการถดถอย เราประเมินประสิทธิภาพ ตรวจพบข้อบกพร่อง และแก้ไข
