
เมื่อเร็ว ๆ นี้ การค้นหาซอฟต์แวร์ Linux ใหม่ที่เจ๋งและไม่เหมือนใครได้กลายเป็นงานที่ยาก งานบ้าน และเมื่อเร็ว ๆ นี้ ฉันหมายถึงสี่หรือห้าปีที่ผ่านมาจริง ๆ แม้ว่าความกระตือรือร้นและนวัตกรรมในพื้นที่เดสก์ท็อปเริ่มลดลงอย่างช้าๆ ท้ายที่สุดแล้ว มีข้อจำกัดว่าของดีจะมีอยู่มากน้อยเพียงใดด้วยสติปัญญาที่จำกัด แต่อย่าลืมการเปลี่ยนโฟกัสที่ผิดไปที่อุปกรณ์พกพาและความฝันแห่งปีของ Linux ที่พังทลาย
สิ่งนี้ทำให้การทดสอบซอฟต์แวร์อายุสี่ขวบของฉันชื่อ OCRFeeder นั้นถูกต้อง ฉันคิดว่า ด้วยเหตุผลสองประการ ถ้ามันดีมันก็ดี ประการที่สอง ฉันสนใจความก้าวหน้าของการรู้จำอักขระด้วยแสงมาโดยตลอด และเครื่องมือของเรา (อ่านว่า AI) สามารถทำงานที่เหมาะสมได้หรือไม่ ฉันได้เขียนรายละเอียดเกี่ยวกับเรื่องนี้ไปเมื่อสักครู่ แล้วทบทวน YAGF ในปี 2015 ตอนนี้ มาดู OCRFeeder และสิ่งที่สามารถทำได้ หลังจากฉัน นักรบลินุกซ์ผู้กล้าหาญ
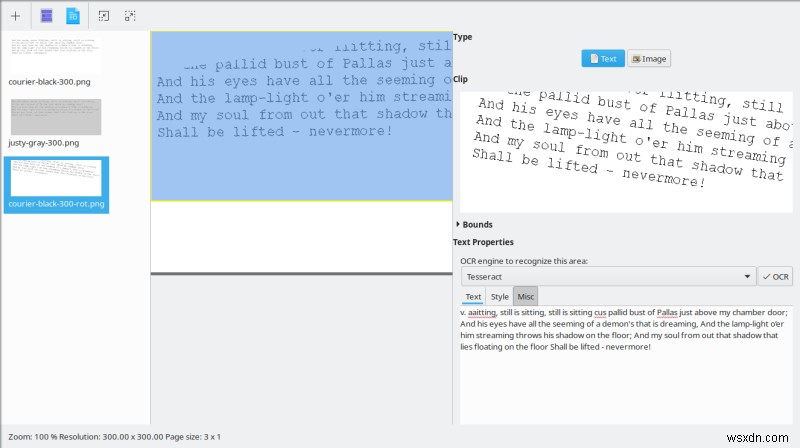
คำพูดไม่ใช่เรื่องง่ายสำหรับ jpg
ฉันติดตั้งโปรแกรม มีห้องสมุดไม่กี่แห่งที่คุณต้องคว้าไว้ ใน Ubuntu 18.04 รายการวิ่งข้ามสองสามบรรทัด คุณจะได้รับเอ็นจิ้น Tesseract OCR เป็นชุดอุปกรณ์เริ่มต้นสำหรับโปรแกรมนี้
แพ็คเกจเพิ่มเติมต่อไปนี้จะถูกติดตั้ง:
blt gir1.2-goocanvas-2.0 gir1.2-gtkspell3-3.0 libgoocanvas-2.0-9 libgoocanvas-2.0-common libgtkspell3-3-0 liblept5 libtesseract4 libyelp0 python-bs4 python- chardet python-enchant python-html5lib python-lxml python-numpy python-olefile python-pil python-renderpm python-reportlab python-reportlab-accel python-sane python-tk python-webencodings tesseract-ocr tesseract-ocr-eng tesseract-ocr -osd tk8.6-blt2.5 unpaper yelp yelp-xsl
แพ็คเกจที่แนะนำ:
blt-demo python-gobject python-wxgtk3.0 python-genshi python-lxml-dbg python- lxml-doc gfortran python-dev python-nose python-numpy-dbg python-numpy-doc python-pil-doc python-pil-dbg python-renderpm-dbg python-egenix-mxtexttools python-reportlab-doc python-sane-dbg python-tk-dbg
เปิดตัวแล้ว อินเทอร์เฟซมีประโยชน์เล็กน้อย ก่อนอื่นคุณต้องโหลดภาพอย่างน้อยหนึ่งภาพ ซึ่งคุณจะใช้เพื่อป้อนเอ็นจิ้น OCR ของคุณ และหวังว่ามันจะสร้างข้อความที่ถูกต้องตามสมควรในอีกด้านหนึ่ง เมื่อดำเนินการเสร็จแล้ว คุณจะสามารถส่งออกข้อความไปยัง LibreOffice ได้
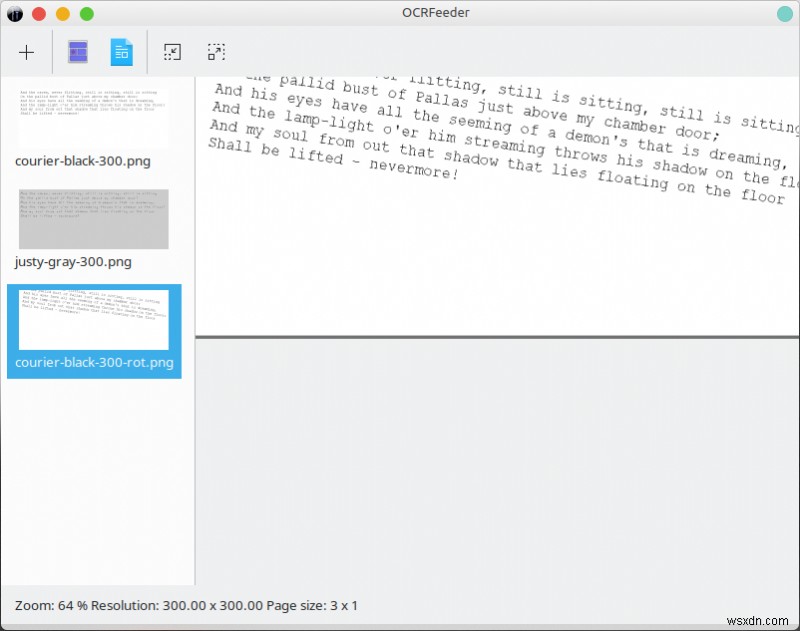
เครื่องยนต์ OCR
ดังที่ฉันได้กล่าวไปแล้ว โดยค่าเริ่มต้น OCRFeeder จะใช้ Tesseract แต่คุณสามารถเพิ่มเครื่องมืออื่น ๆ ที่คุณต้องการได้ อันที่จริง ฉันลองใช้ CuneiForm, GOCR และ Ocrad และโปรแกรมตรวจพบและโหลดทั้งหมดได้อย่างถูกต้อง เรียบร้อยมาก วิธีนี้ทำให้คุณสามารถลองใช้เอกสารของคุณได้หลายวิธี เนื่องจากคุณอาจมีโชคมากกว่ากับเครื่องมือบางอย่างเหล่านี้
sudo apt-get install ฟอร์ม gocr ocrad
การแปลงรูปภาพเป็นข้อความ
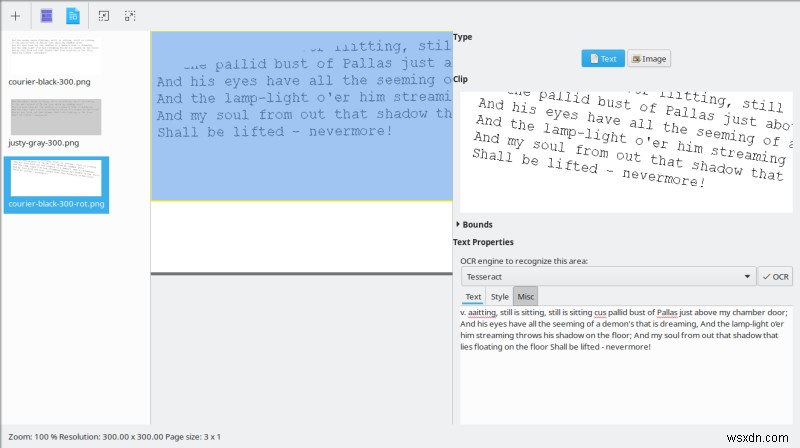
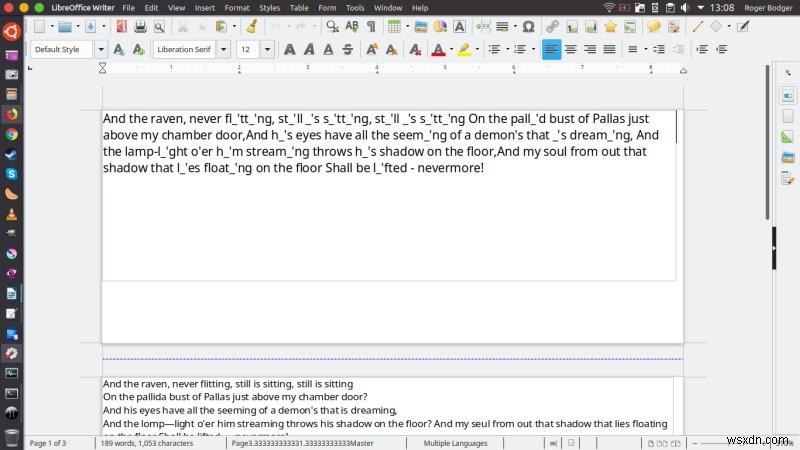
ตอนนี้ส่วนสำคัญ ฉันต่อสู้เล็กน้อยที่นี่ ฉันปล่อยให้โปรแกรมตรวจหาข้อความโดยอัตโนมัติ (จดจำทุกหน้า) ในทุกภาพที่มีอยู่ และฉันได้รับผลลัพธ์ที่มีเครื่องหมายสีแปลกๆ สิ่งนี้ใช้เวลาประมาณสามนาทีในการดำเนินการสำหรับไฟล์ PNG ที่โหลดสามไฟล์ และในช่วงเวลานั้น การใช้งาน CPU ของ OCRFeeder อยู่ที่ประมาณ 17% และ Tesseract ใช้งานประมาณ 4-5% ดังนั้นเวลาจะลดลงอย่างแน่นอนหากแอปพลิเคชันทำงานได้ดีขึ้นในการใช้แกนประมวลผลทั้งหมด จากนั้นผลลัพธ์ที่แปลกประหลาด ฉันไม่ค่อยแน่ใจว่าต้องทำอะไร แปลก. ดูเหมือนว่าฉันจะไม่คืบหน้าเลย

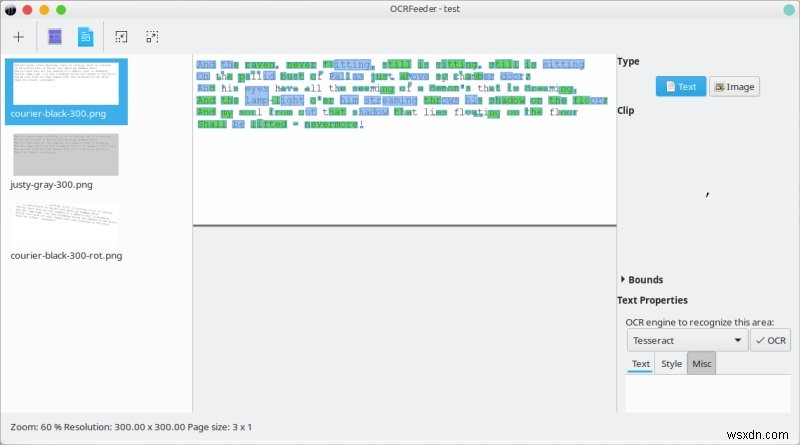
จากนั้น ฉันรู้ว่าฉันสามารถใช้เมาส์เพื่อลากและเลือกส่วนของรูปภาพที่แสดง จากนั้นบานหน้าต่างแยกต่างหากจะเปิดขึ้น ซึ่งฉันสามารถเลือกเครื่องมือ OCR ที่ต้องการ และเรียกใช้การแปลงจริง นอกเหนือจากความบกพร่องของภาพ วิธีนี้ทำงานได้ดีพอสมควร และใช้เวลาเพียงไม่กี่วินาทีในการประมวลผลแต่ละภาพ
หากไม่มีการฝึกอบรมหรือเปลี่ยนแปลงค่าเริ่มต้น ความแตกต่างของผลลัพธ์ระหว่างเครื่องยนต์ทั้งสี่ที่มีอยู่นั้นมีขนาดใหญ่มาก Tesseract แสดงการแปลงที่ดีที่สุดและยอมรับได้เท่านั้น ส่วนที่เหลือไม่ดีพอที่จะพิจารณาใช้เลย ฉันไม่แน่ใจว่าทำไม ก็เหมือนเดิม
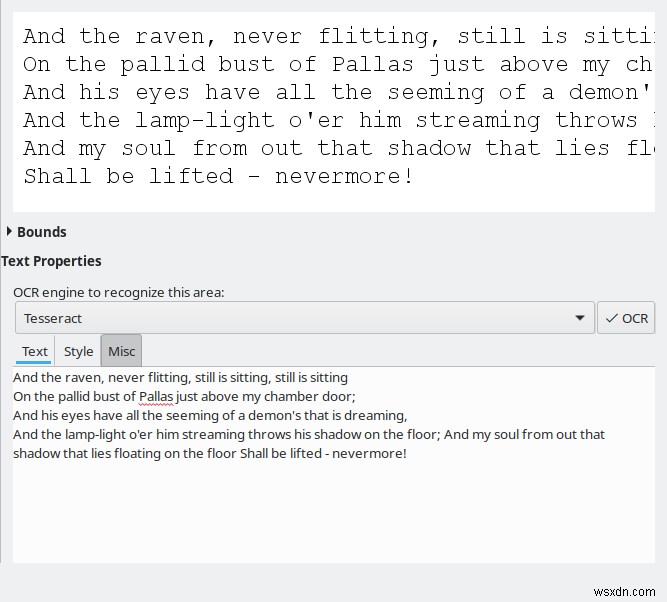
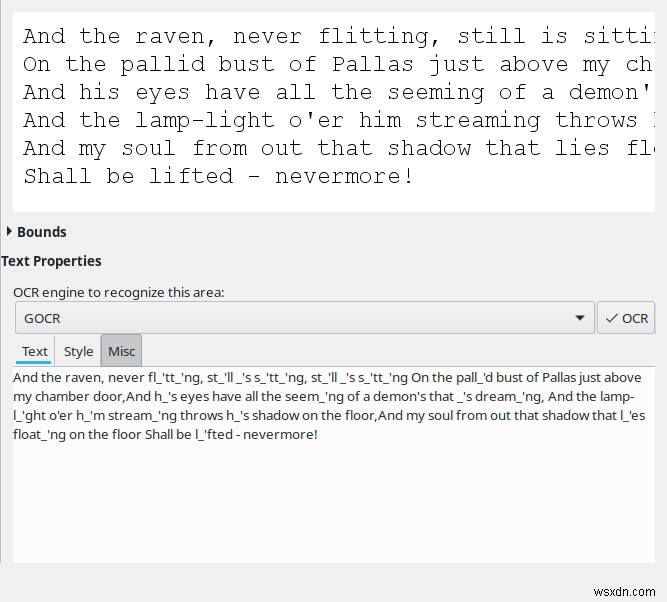
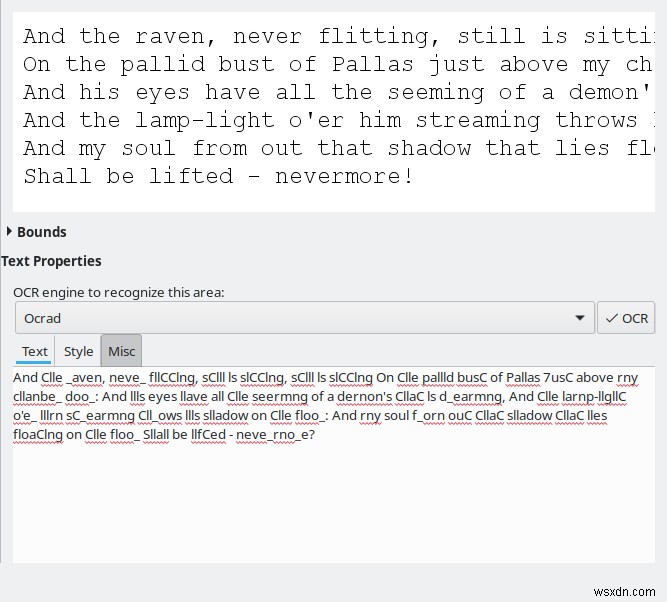
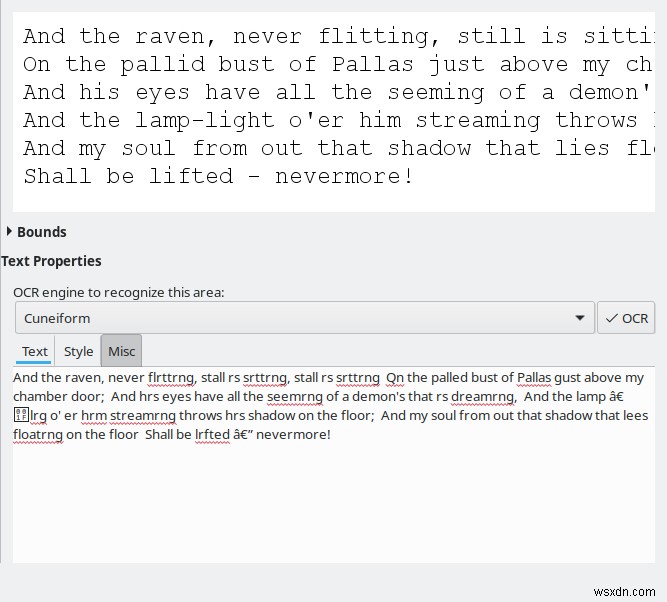
ฉันยังสังเกตเห็นผลลัพธ์ที่ดีขึ้นด้วยภาพพื้นหลังสีเทา ในอดีต Tesseract มีปัญหา ดังนั้นการปรับปรุงใด ๆ ที่เกิดขึ้นกับเครื่องมือนี้ พวกเขายินดีเป็นอย่างยิ่ง แต่นี่ไม่ใช่สิ่งที่ OCRFeeder เคร่งครัด และคุณสามารถเรียกใช้ Tesseract ด้วยตัวคุณเองจากบรรทัดคำสั่ง ถ้าคุณต้องการ
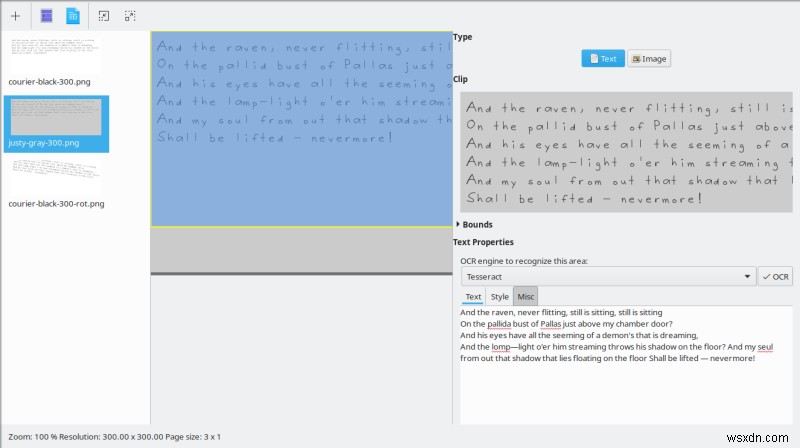
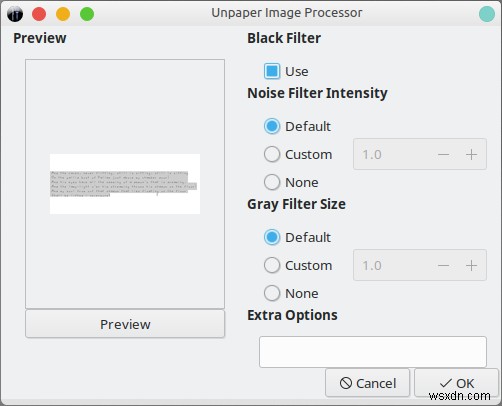
การลบมุมและการเปิดกระดาษ
OCRFeeder มาพร้อมกับสองฟังก์ชั่นที่ดี - ความสามารถในการลองหมุนข้อความอัตโนมัติในการสแกนภาพที่เอียง และความสามารถในการลบพื้นหลังกระดาษเพื่อลดสัญญาณรบกวนและช่วยให้การแปลงถูกต้องมากขึ้น ฉันลองใช้ทั้ง 2 ตัวเลือกแล้ว Deskew ก็ทำงานได้ดี Unpapering พอดูได้ แต่หลังจากที่ฉันหมุนข้อความ (ซึ่งฉันทำใน GIMP ในการควบคุมรูปภาพย้อนหลังไป) ผลลัพธ์ของการแปลงก็ดียิ่งขึ้น
ส่งออกเป็น ODT
นี่เป็นเรื่องยุ่งยากเล็กน้อย ฉันลองทำสองสามครั้งและพบข้อผิดพลาดมากมาย ในที่สุดมันก็ทำงาน ผลลัพธ์ไม่ได้สวยงามที่สุด แต่สิ่งที่ดีคือ คุณสามารถส่งออกการแปลงหลายรายการพร้อมกันได้ รวมถึงการใช้เครื่องมือที่แตกต่างกันสำหรับรูปภาพต่างๆ ค่อนข้างดี
การตั้งค่า
สุดท้าย คุณมีตัวเลือกในการเปลี่ยนลักษณะการทำงานของโปรแกรม ไม่มีอะไรสำคัญเกินไป แต่สามารถช่วยในการตรวจจับและความแม่นยำได้ ส่วนใหญ่ขึ้นอยู่กับวิธีที่คุณตรวจหาความกว้างของคอลัมน์ข้อความ ระยะขอบ การเลือกภาษา และอื่นๆ สำหรับคนส่วนใหญ่ ค่าเริ่มต้นจะเป็นจุดเริ่มต้นที่สมเหตุสมผล
บทสรุป
OCRFeeder เป็นซอฟต์แวร์ที่เหมาะสมและยืดหยุ่น สามารถใช้เอนจิ้นหลายตัวได้ และอัลกอริธึมการแก้ไขภาพก็เป็นส่วนเสริมที่ดี สิ่งนี้ทำให้ OCRFeeder น่าจะเป็นซอฟต์แวร์ประเภทนี้ที่มีแนวโน้มดีที่สุดในตลาดเสรี แต่ความหวังของคุณก็ต้องดับวูบลงทันที เพราะไม่น่าจะเห็นการอัปเดตในเร็วๆ นี้ เว้นแต่จะมีคนหยิบเรื่องนี้ขึ้นมา เนื่องจากมีตลาดรองรับในเรื่องนี้ แต่โลกของ Linux ติดอยู่ในตำแหน่งที่ยากลำบากระหว่างความเหนื่อยล้าและความเฉยเมย
นอกเหนือจากอายุและการอัปเดตสิ่งต่าง ๆ ส่วนใหญ่แล้ว OCRFeeder ก็ส่งมอบ คุณภาพการแปลงไม่เลว คุณจะไม่เสียอะไรไปจากการใช้ UI ในการทำงานของคุณ และฟังก์ชันการส่งออกช่วยให้คุณสร้างเอกสารที่สวยงามสำหรับการแก้ไขเพิ่มเติมและอื่นๆ ฉันยังมีความสุขกับการปรับปรุงใน Tesseract ดังนั้น หากคุณมีรูปภาพข้อความจำนวนมาก และคุณต้องการลองแปลงข้อความที่เขียนด้วยลายมือในรูปแบบโบราณให้เป็นสิ่งที่ทันสมัยและใช้งานได้ คุณสามารถทำได้ OCRFeeder รองรับ PDF เช่นเดียวกับการอ่านโดยตรงจากสแกนเนอร์ คุ้มค่ากับการทดลอง ถึงเวลาไปแล้ว บ๊ายบาย
ไชโย.
