
การพัฒนาซอฟต์แวร์อาจเป็นเรื่องที่ท้าทาย แต่การดูแลรักษาซอฟต์แวร์นั้นท้าทายกว่ามาก การบำรุงรักษารวมถึงแพตช์ซอฟต์แวร์และการบำรุงรักษาเซิร์ฟเวอร์ ในโพสต์นี้ เราจะเน้นที่การจัดการและบำรุงรักษาเซิร์ฟเวอร์
ตามเนื้อผ้าเซิร์ฟเวอร์อยู่ในองค์กร ซึ่งหมายถึงการซื้อและบำรุงรักษาฮาร์ดแวร์จริง ด้วยการประมวลผลแบบคลาวด์ เซิร์ฟเวอร์เหล่านี้ไม่จำเป็นต้องเป็นเจ้าของจริงอีกต่อไป ในปี 2549 เมื่อ Amazon เริ่มใช้ AWS และเปิดตัวบริการ EC2 ยุคของการประมวลผลบนคลาวด์สมัยใหม่ก็เริ่มต้นขึ้น ด้วยบริการประเภทนี้ เราไม่จำเป็นต้องบำรุงรักษาเซิร์ฟเวอร์จริงหรืออัพเกรดฮาร์ดแวร์จริงอีกต่อไป วิธีนี้ช่วยแก้ปัญหาได้มากมาย แต่การบำรุงรักษาเซิร์ฟเวอร์และการจัดการทรัพยากรยังขึ้นอยู่กับเรา การพัฒนาเหล่านี้ไปสู่อีกระดับ ตอนนี้เรามีเทคโนโลยีแบบไร้เซิร์ฟเวอร์
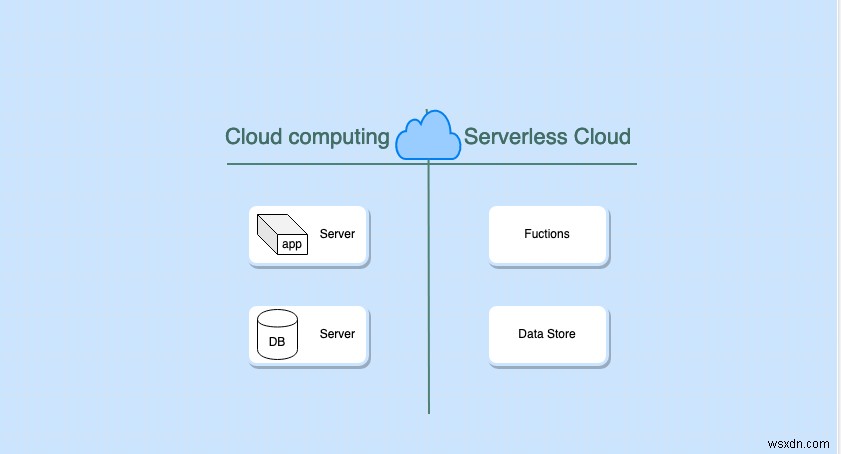
เทคโนโลยีไร้เซิร์ฟเวอร์คืออะไร
เทคโนโลยีไร้เซิร์ฟเวอร์ช่วยลดภาระงานในการจัดการและจัดเตรียมเซิร์ฟเวอร์ให้กับผู้ให้บริการระบบคลาวด์ ในโพสต์นี้ เราจะพูดถึง AWS
คำว่า Serverless ไม่ได้หมายความว่าไม่มีเซิร์ฟเวอร์เลย มีเซิร์ฟเวอร์ แต่ได้รับการจัดการโดยผู้ให้บริการระบบคลาวด์อย่างสมบูรณ์ ในแง่หนึ่งสำหรับผู้ใช้เทคโนโลยีไร้เซิร์ฟเวอร์ไม่มีเซิร์ฟเวอร์ที่มองเห็นได้ เราไม่สามารถมองเห็นเซิร์ฟเวอร์ได้โดยตรง และงานในการจัดการเซิร์ฟเวอร์นั้นเป็นไปโดยอัตโนมัติโดยผู้ให้บริการระบบคลาวด์ นี่คือคุณลักษณะบางประการที่ทำให้ไม่มีเซิร์ฟเวอร์:
- ไม่มีการจัดการการปฏิบัติงาน - ไม่จำเป็นต้องแพตช์เซิร์ฟเวอร์หรือจัดการเซิร์ฟเวอร์เพื่อให้มีความพร้อมใช้งานสูง
- ปรับขนาดได้ตามต้องการ - ตั้งแต่ให้บริการผู้ใช้เพียงไม่กี่รายไปจนถึงให้บริการผู้ใช้หลายล้านคน
- จ่ายเท่าที่ใช้ - จัดการค่าใช้จ่ายตามการใช้งาน
เทคโนโลยี Serverless สามารถจำแนกได้ดังนี้:
- คำนวณ (เช่น Lambda และ Fargate)
- ที่เก็บข้อมูล (เช่น S3)
- ที่เก็บข้อมูล (เช่น DynamoDB และ Aurora)
- บูรณาการ (เช่น API Gateway, SNS และ SQS)
- การวิเคราะห์ (เช่น Kinesis และ Athena)
เหตุใดจึงใช้เทคโนโลยีไร้เซิร์ฟเวอร์
ค่าใช้จ่าย
จ่ายตามการใช้งานเป็นหนึ่งในข้อได้เปรียบหลักของการใช้เทคโนโลยีไร้เซิร์ฟเวอร์ เมื่อมีการเปลี่ยนแปลงปริมาณการรับส่งข้อมูลที่คาดเดาไม่ได้ คุณจะต้องปรับขนาดเซิร์ฟเวอร์ขึ้นหรือลงตามรูปแบบการใช้งาน แต่การปรับขนาดด้วยการจัดการอัตโนมัติด้วยตนเองอาจทำได้ยากและไม่มีประสิทธิภาพ การประมวลผลแบบไร้เซิร์ฟเวอร์ เช่น AWS Lambda สามารถช่วยประหยัดค่าใช้จ่ายได้อย่างง่ายดาย เนื่องจากไม่ต้องจ่ายในช่วงเวลาว่าง
ความสามารถในการทำงานของนักพัฒนา
เนื่องจากการประมวลผลแบบไร้เซิร์ฟเวอร์หมายถึงบริการที่มีการจัดการเต็มรูปแบบซึ่งให้บริการโดยผู้ให้บริการระบบคลาวด์ นักพัฒนาจึงไม่จำเป็นต้องจัดเตรียมเซิร์ฟเวอร์หรือพัฒนาแอปพลิเคชันเซิร์ฟเวอร์ นักพัฒนาสามารถเริ่มเขียนโค้ดได้ทันทีโดยไม่ต้องจัดการเซิร์ฟเวอร์ วิธีการนี้ยังขจัดความจำเป็นในการแพตช์เซิร์ฟเวอร์หรือจัดการการปรับขนาดอัตโนมัติ การประหยัดเวลาทั้งหมดนี้ช่วยเพิ่มประสิทธิภาพการทำงานของนักพัฒนา
ความยืดหยุ่น
การประมวลผลแบบไร้เซิร์ฟเวอร์มีความยืดหยุ่นสูงและสามารถปรับขนาดขึ้นหรือลงตามการใช้งาน ผู้ใช้ที่พุ่งสูงขึ้นสามารถจัดการได้อย่างง่ายดาย นี่อาจเป็นข้อได้เปรียบที่สำคัญและช่วยประหยัดเวลาได้มากสำหรับนักพัฒนา
ความพร้อมใช้งานสูง
เมื่อการประมวลผลเป็นแบบไร้เซิร์ฟเวอร์และจัดการโดยผู้ให้บริการระบบคลาวด์ และเซิร์ฟเวอร์มีเวลาทำงานสูง ระบบจะได้รับการจัดการเมื่อเกิดข้อผิดพลาดโดยอัตโนมัติ การจัดการปัญหาประเภทนี้ต้องใช้ทักษะเฉพาะทาง ด้วยแนวทางแบบไร้เซิร์ฟเวอร์ งานของ ops และนักพัฒนาสามารถทำได้โดยบุคคลเพียงคนเดียว
วิธีใช้งานฟังก์ชันแบบไร้เซิร์ฟเวอร์ใน Ruby
จากข้อมูลของ AWS Ruby เป็นหนึ่งในภาษาที่ใช้กันอย่างแพร่หลายที่สุดใน AWS Lambda เริ่มรองรับ Ruby ในเดือนพฤศจิกายน 2018 เราจะสร้าง Web API ใน Ruby โดยใช้เทคโนโลยีไร้เซิร์ฟเวอร์ที่ AWS จัดหาให้
ในการสร้างอินฟาเรดแบบไร้เซิร์ฟเวอร์ใน AWS เราสามารถเข้าสู่ระบบคอนโซล AWS และเริ่มสร้างได้ อย่างไรก็ตาม เราต้องการพัฒนาบางสิ่งที่สามารถทดสอบได้ง่ายและอำนวยความสะดวกในการกู้คืนจากความเสียหาย เราจะเขียนคุณลักษณะแบบไร้เซิร์ฟเวอร์เป็นรหัส ในการดำเนินการดังกล่าว AWS ได้จัดเตรียมโมเดลแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ (SAM) SAM เป็นเฟรมเวิร์กที่ใช้สร้างแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ใน AWS มีไวยากรณ์ที่ใช้ YAML สำหรับการออกแบบแลมบ์ดา ฐานข้อมูล และ API แอปพลิเคชัน AWS SAM สามารถสร้างได้โดยใช้ AWS SAM-CLI ซึ่งสามารถดาวน์โหลดได้ทางลิงก์นี้
AWS SAM CLI สร้างขึ้นบน AWS Cloudformation หากคุณคุ้นเคยกับการเขียน IaC ด้วย CoudFormation สิ่งนี้จะง่ายมาก คุณยังสามารถใช้เฟรมเวิร์กแบบไร้เซิร์ฟเวอร์ได้อีกด้วย ในโพสต์นี้ ฉันจะใช้ AWS SAM
ก่อนใช้ SAM CLI ตรวจสอบให้แน่ใจว่าคุณมีสิ่งต่อไปนี้:
- ตั้งค่าโปรไฟล์ AWS
- ติดตั้ง Docker แล้ว
- ติดตั้ง SAM CLI แล้ว
เราจะพัฒนาแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ เราจะเริ่มต้นด้วยการสร้างอินฟาเรดแบบไร้เซิร์ฟเวอร์ เช่น DynamoDB และ Lambda ในแอปพลิเคชันของเรา ให้เราเริ่มต้นด้วยฐานข้อมูล:
DynamoDB
DynamoDB เป็นบริการฐานข้อมูลที่จัดการโดย AWS แบบไร้เซิร์ฟเวอร์ เนื่องจากไม่มีเซิร์ฟเวอร์ จึงตั้งค่าได้ง่ายและรวดเร็ว ในการสร้าง DynamoDB เรากำหนดเทมเพลต SAM ดังนี้:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
ด้วย SAM CLI และเทมเพลตด้านบน เราสามารถสร้างตาราง DynamoDB พื้นฐานได้ ก่อนอื่น เราต้องสร้างแพ็คเกจสำหรับแอปแบบไร้เซิร์ฟเวอร์ของเรา สำหรับสิ่งนี้ เราเรียกใช้คำสั่งต่อไปนี้ สิ่งนี้จะสร้างแพ็คเกจและพุชไปที่ s3 ตรวจสอบให้แน่ใจว่าคุณได้สร้างที่ฝากข้อมูล s3 ด้วยชื่อ serverless-users-bucket ก่อนรันคำสั่ง:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
ตอนนี้ s3 กลายเป็นแหล่งที่มาของเทมเพลตและโค้ดสำหรับแอปแบบไร้เซิร์ฟเวอร์ ซึ่งเราจะพูดถึงในขณะที่เราสร้างฟังก์ชัน Lambda สำหรับแอปนี้
ตอนนี้เราสามารถปรับใช้เทมเพลตนี้เพื่อสร้าง DynamoDB:
$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
ด้วยเหตุนี้ เราจึงได้ติดตั้ง DynamoDB ไว้แล้ว ต่อไป เราจะสร้าง Lambda ซึ่งจะใช้ตารางนี้
แลมบ์ดา
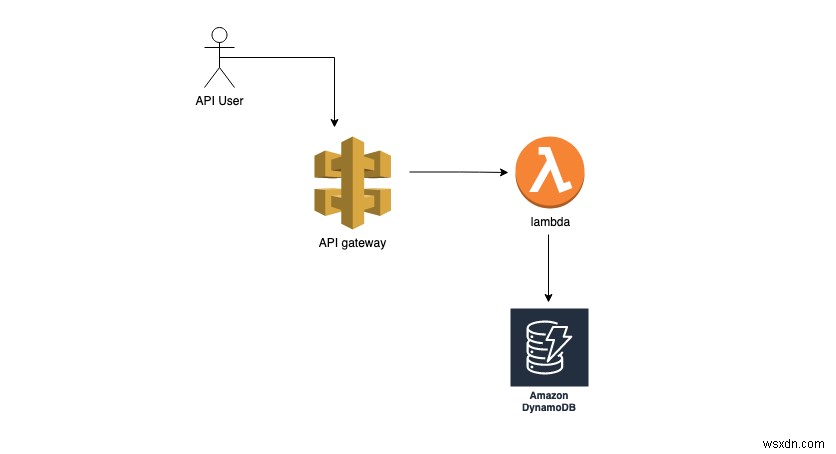
Lambda เป็นบริการประมวลผลแบบไร้เซิร์ฟเวอร์ที่ให้บริการโดย AWS สามารถใช้เพื่อรันโค้ดตามความจำเป็นโดยไม่ต้องมีการจัดการเซิร์ฟเวอร์จริง ซึ่งโค้ดจะถูกเรียกใช้งาน สามารถใช้ Lambda เพื่อเรียกใช้กระบวนการ Async, REST API หรืองานที่กำหนดเวลาไว้ สิ่งที่เราต้องทำคือเขียน ฟังก์ชันตัวจัดการ และผลักดันฟังก์ชันไปที่ AWS Lambda แลมบ์ดาจะทำงานตามเหตุการณ์ . เหตุการณ์สามารถถูกทริกเกอร์โดยแหล่งที่มาต่างๆ เช่น เกตเวย์ API, SQS หรือ S3 มันสามารถถูกทริกเกอร์โดยฐานรหัสอื่น เมื่อทริกเกอร์ ฟังก์ชัน Lambda นี้จะรับเหตุการณ์และพารามิเตอร์บริบท ค่าในพารามิเตอร์เหล่านี้แตกต่างกันไปตามแหล่งที่มาของทริกเกอร์ นอกจากนี้เรายังสามารถทริกเกอร์ฟังก์ชัน Lambda ด้วยตนเองหรือโดยทางโปรแกรมโดยส่งเหตุการณ์เหล่านี้ไปยังตัวจัดการ ตัวจัดการรับสองอาร์กิวเมนต์:
กิจกรรม - เหตุการณ์มักจะเป็นแฮชของคีย์-ค่าที่ส่งผ่านจากแหล่งที่มาของทริกเกอร์ ค่าเหล่านี้จะถูกส่งต่อโดยอัตโนมัติเมื่อมีการทริกเกอร์โดยแหล่งที่มาต่างๆ เช่น SQS, Kinesis หรือเกตเวย์ API เมื่อเรียกใช้ด้วยตนเอง เราสามารถส่งต่อเหตุการณ์ที่นี่ เหตุการณ์มีข้อมูลอินพุตสำหรับตัวจัดการฟังก์ชันแลมบ์ดา ตัวอย่างเช่น ในเกตเวย์ API เนื้อหาคำขอจะอยู่ภายในเหตุการณ์นี้
บริบท - บริบทเป็นอาร์กิวเมนต์ที่สองในฟังก์ชันตัวจัดการ ซึ่งมีรายละเอียดเฉพาะ ซึ่งรวมถึงแหล่งที่มาของทริกเกอร์ ชื่อฟังก์ชัน Lambda เวอร์ชัน รหัสคำขอ และอื่นๆ
เอาต์พุตของตัวจัดการจะถูกส่งกลับไปยังบริการที่ทริกเกอร์ฟังก์ชัน Lambda เอาต์พุตของฟังก์ชัน Lambda คือค่าส่งคืนของฟังก์ชันตัวจัดการ
AWS Lambda รองรับภาษาต่างๆ เจ็ดภาษาซึ่งคุณสามารถเขียนโค้ดได้ ซึ่งรวมถึง Ruby ที่นี่ เราจะใช้ AWS Ruby-sdk เพื่อเชื่อมต่อกับ DynamoDB
ก่อนเขียนโค้ด ให้เราสร้างอินฟราสำหรับ Lambda โดยใช้เทมเพลต SAM:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
ในตัวจัดการ เราเขียนการอ้างอิงถึงฟังก์ชันที่จะดำเนินการเป็น Handler: <filename>.<method_name> .
อ้างถึงเทมเพลตนโยบายแบบไร้เซิร์ฟเวอร์สำหรับนโยบายที่คุณสามารถแนบไปกับ Lambda ตามทรัพยากรที่ใช้ เนื่องจากฟังก์ชัน Lambda ของเราเขียนไปยัง DynamoDB เราจึงใช้ DynamoDBWritePolicy ในส่วนนโยบาย
นอกจากนี้เรายังจัดเตรียมตัวแปร env USERS_TABLE ให้กับฟังก์ชัน Lambda เพื่อให้สามารถส่งคำขอไปยังฐานข้อมูลที่ระบุได้
นั่นคือสิ่งที่เราต้องการสำหรับอินฟาเรดแลมบ์ดา ตอนนี้ ให้เราเขียนโค้ดเพื่อสร้างผู้ใช้ใน DynamoDB ซึ่งฟังก์ชัน Lambda จะดำเนินการ
เพิ่มระเบียน AWS ไปยัง Gemfile:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
เพิ่มโค้ดเพื่อเขียนอินพุตไปยัง DynamoDB:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
มันรวดเร็วและง่ายมาก AWS ให้ aws-record gem สำหรับการเข้าถึง DynamoDB ซึ่งคล้ายกับ activerecord ของ Rails มาก .
ถัดไป เรียกใช้คำสั่งต่อไปนี้เพื่อติดตั้งการพึ่งพา
หมายเหตุ:ตรวจสอบให้แน่ใจว่าคุณมี Ruby เวอร์ชันเดียวกับที่กำหนดไว้ใน Lambda ตัวอย่างเช่น คุณต้องติดตั้ง Ruby2.7 ในเครื่องของคุณ
# install dependencies
$ bundle install
$ bundle install --deployment
จัดแพ็คเกจการเปลี่ยนแปลง:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
ปรับใช้:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
ด้วยรหัสนี้ ตอนนี้เรามี Lambda ทำงานอยู่ ซึ่งสามารถเขียนอินพุตไปยังฐานข้อมูลได้ เราสามารถเพิ่มเกตเวย์ API หน้า Lambda เพื่อให้เราสามารถเข้าถึงได้ผ่านการเรียก HTTP เกตเวย์ API มีฟังก์ชันการจัดการ API มากมาย เช่น การจำกัดอัตราและการตรวจสอบสิทธิ์ อย่างไรก็ตามอาจมีราคาแพงตามการใช้งาน มีตัวเลือกที่ถูกกว่าในการใช้เฉพาะ HTTP API ที่ไม่มีการจัดการ API คุณสามารถเลือกแบบที่เหมาะสมที่สุดได้ตามกรณีการใช้งาน
AWS Lambda มีข้อจำกัดเล็กน้อย บางส่วนสามารถแก้ไขได้ แต่บางส่วนได้รับการแก้ไข:
- หน่วยความจำ - โดยค่าเริ่มต้น Lambda มีหน่วยความจำ 128 MB ระหว่างเวลาดำเนินการ สามารถเพิ่มได้สูงสุด 3,008 MB โดยเพิ่มทีละ 64 MB
- หมดเวลา - ฟังก์ชันแลมบ์ดามีเวลาจำกัดในการรันโค้ด ขีดจำกัดเริ่มต้นคือ 3 วินาที สามารถเพิ่มได้ถึง 900 วินาที
- ที่เก็บข้อมูล - Lambda ให้
/tmpไดเร็กทอรีสำหรับการจัดเก็บ ขีดจำกัดของพื้นที่เก็บข้อมูลนี้คือ 512 MB - ขนาดคำขอและการตอบสนอง - สูงสุด 6 MB สำหรับทริกเกอร์แบบซิงโครนัสและ 256 MB สำหรับทริกเกอร์แบบอะซิงโครนัส
- ตัวแปรสภาพแวดล้อม - สูงสุด 4KB
เนื่องจากแลมบ์ดามีข้อจำกัดบางประการ การเขียนโค้ดที่เหมาะสมกับข้อจำกัดเหล่านี้จึงดีกว่า ในกรณีที่ไม่เป็นเช่นนั้น เราสามารถแบ่งโค้ดเพื่อให้ Lambda ตัวหนึ่งเรียกใช้ตัวอื่นได้ นอกจากนี้ยังมีฟังก์ชันขั้นตอนที่ให้บริการโดย AWS ซึ่งสามารถใช้เพื่อจัดลำดับฟังก์ชัน Lambda หลายรายการได้
เราจะทดสอบแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ในเครื่องได้อย่างไร
สำหรับแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ เราจำเป็นต้องมีผู้จำหน่ายที่ให้บริการแบบไร้เซิร์ฟเวอร์ที่มีการจัดการ เราพึ่งพา AWS ในการทดสอบแอปพลิเคชันของเรา ในการทดสอบแอปพลิเคชัน มีตัวเลือกท้องถิ่นสองสามตัวที่ AWS มีให้ เครื่องมือโอเพนซอร์ซบางตัวที่เข้ากันได้กับเทคโนโลยีไร้เซิร์ฟเวอร์ของ AWS สามารถใช้ทดสอบแอปพลิเคชันในเครื่องได้
ให้เราทดสอบฟังก์ชัน Lambda และ DynamoDB ของเรา ในการทำเช่นนั้น เราจำเป็นต้องเรียกใช้สิ่งเหล่านี้ในเครื่อง
ขั้นแรก สร้างเครือข่ายนักเทียบท่า เครือข่ายจะช่วยสื่อสารระหว่างฟังก์ชัน Lambda และ DynamoDB
$ docker network create lambda-local --docker-network lambda-local
DynamoDB local เป็นเวอร์ชันท้องถิ่นของ DynamoDB ที่ให้บริการโดย AWS ซึ่งเราสามารถใช้เพื่อทดสอบในเครื่องได้ เรียกใช้ DynamoDB โลคัลโดยเรียกใช้อิมเมจนักเทียบท่าต่อไปนี้:
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
เพิ่มบรรทัดต่อไปนี้ใน user.rb ไฟล์. สิ่งนี้จะเชื่อมต่อ Lambda กับ DynamoDB ในพื้นที่:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
เพิ่ม input.json ไฟล์ซึ่งมีอินพุตสำหรับ Lambda:
{
"name": "Milap Neupane",
"location": "Global"
}
ก่อนดำเนินการ Lambda เราจำเป็นต้องเพิ่มตารางลงใน DynamoDB ในเครื่อง ในการดำเนินการดังกล่าว เราจะใช้ฟังก์ชันการย้ายข้อมูลที่มีให้โดย aws-migrate ให้เราสร้างไฟล์ migrate.rb และเพิ่มการโยกย้ายต่อไปนี้:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
สุดท้าย รัน Lambda ในเครื่องโดยใช้คำสั่งต่อไปนี้:
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
ซึ่งจะสร้างข้อมูลของผู้ใช้ในตาราง DynamoDB
มีตัวเลือกต่างๆ เช่น localstack สำหรับการเรียกใช้สแต็ค AWS ในเครื่อง
เมื่อใดควรใช้คอมพิวเตอร์แบบไร้เซิร์ฟเวอร์
เมื่อตัดสินใจว่าจะใช้การประมวลผลแบบไร้เซิร์ฟเวอร์หรือไม่ เราจำเป็นต้องตระหนักถึงทั้งข้อดีและข้อเสียของมัน จากลักษณะเฉพาะต่อไปนี้ เราสามารถตัดสินใจได้ว่าจะใช้วิธีไร้เซิร์ฟเวอร์เมื่อใด:
ค่าใช้จ่าย
- เมื่อแอปพลิเคชันมีเวลาว่างและปริมาณการใช้งานที่ไม่สอดคล้องกัน Lambdas ก็ดีเพราะช่วยลดค่าใช้จ่ายได้
- เมื่อแอปพลิเคชันมีปริมาณการรับส่งข้อมูลที่สม่ำเสมอ การใช้ AWS Lambda อาจมีค่าใช้จ่ายสูง
ประสิทธิภาพ
- หากแอปพลิเคชันไม่คำนึงถึงประสิทธิภาพ การใช้ AWS Lambda เป็นตัวเลือกที่ดี
- แลมบ์ดามีช่วง Cold boot ซึ่งอาจทำให้เวลาตอบสนองช้าในระหว่างการบู๊ตแบบเย็น
การประมวลผลพื้นหลัง
- Lambda เป็นตัวเลือกที่ดีสำหรับการประมวลผลพื้นหลัง เครื่องมือโอเพนซอร์สบางอย่าง เช่น Sidekiq มีการปรับขนาดเซิร์ฟเวอร์และค่าใช้จ่ายในการบำรุงรักษา เราสามารถรวมคิว AWS Lambda และ AWS SQS เพื่อประมวลผลงานเบื้องหลังโดยไม่ต้องยุ่งยากกับการบำรุงรักษาเซิร์ฟเวอร์
การประมวลผลพร้อมกัน
- อย่างที่เราทราบ การทำงานพร้อมกันใน Ruby ไม่ใช่สิ่งที่เราสามารถทำได้ง่ายๆ ด้วยแลมบ์ดา เราสามารถทำงานพร้อมกันได้โดยไม่ต้องมีการสนับสนุนภาษาโปรแกรม สามารถใช้ Lambda พร้อมกันและช่วยปรับปรุงประสิทธิภาพได้
การเรียกใช้สคริปต์เป็นระยะหรือแบบครั้งเดียว
- เราใช้งาน cron เพื่อรันโค้ด Ruby แต่การบำรุงรักษาเซิร์ฟเวอร์สำหรับงาน cron อาจเป็นเรื่องยากสำหรับแอปพลิเคชันขนาดใหญ่ การใช้ Lambdas ตามเหตุการณ์ช่วยในการปรับขนาดแอปพลิเคชัน
นี่คือกรณีการใช้งานบางส่วนสำหรับฟังก์ชัน Lambda ในแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ เราไม่ต้องสร้างทุกอย่างแบบไร้เซิร์ฟเวอร์ เราสามารถสร้างแบบจำลองไฮบริดสำหรับกรณีการใช้งานที่ระบุข้างต้นได้ ซึ่งช่วยในการปรับขนาดแอปพลิเคชันและเพิ่มประสิทธิภาพการทำงานของนักพัฒนา เทคโนโลยีไร้เซิร์ฟเวอร์กำลังพัฒนาและดีขึ้นเรื่อยๆ มีเทคโนโลยีไร้เซิร์ฟเวอร์อื่นๆ เช่น AWS Fatgate และ Google CloudRun ซึ่งไม่มีข้อจำกัดของ AWS Lambda
