
ที่มาแบบเต็มบน Github
มีการใช้งานภาษาการเขียนโปรแกรม Stoffle อย่างสมบูรณ์ที่ GitHub การใช้งานข้อมูลอ้างอิงนี้มีความคิดเห็นมากมายเพื่อช่วยให้อ่านโค้ดได้ง่ายขึ้น อย่าลังเลที่จะเปิดปัญหาหากคุณพบข้อบกพร่องหรือมีคำถาม
ในบล็อกโพสต์นี้ เราจะใช้โปรแกรมแยกวิเคราะห์สำหรับ Stoffle ซึ่งเป็นภาษาโปรแกรมของเล่นที่สร้างขึ้นใน Ruby ทั้งหมด คุณสามารถอ่านเพิ่มเติมเกี่ยวกับโครงการนี้ได้ในส่วนแรกของชุดนี้
การสร้าง parser จากศูนย์ทำให้ฉันได้รับข้อมูลเชิงลึกและความรู้ที่ไม่คาดคิด ฉันเดาว่าประสบการณ์นี้อาจแตกต่างกันไปในแต่ละบุคคล แต่ฉันคิดว่ามันปลอดภัยที่จะสรุปว่าหลังจากบทความนี้ คุณจะได้รับหรือเพิ่มพูนความรู้ของคุณอย่างน้อยหนึ่งอย่างต่อไปนี้:
- คุณจะเริ่มเห็นซอร์สโค้ดแตกต่างออกไป และสังเกตเห็น โครงสร้างเหมือนต้นไม้ ที่ปฏิเสธไม่ได้ ได้ง่ายขึ้นมาก
- คุณจะเข้าใจ น้ำตาลซินแทกติก และจะเริ่มเห็นได้ทุกที่ ไม่ว่าจะเป็น Stoffle, Ruby หรือแม้แต่ภาษาโปรแกรมอื่นๆ
ฉันรู้สึกว่า parser เป็นตัวอย่างที่สมบูรณ์แบบของหลักการ Pareto ปริมาณงานที่จำเป็นในการสร้างคุณลักษณะพิเศษบางอย่าง เช่น ข้อความแสดงข้อผิดพลาดที่ยอดเยี่ยม มีจำนวนมากขึ้นอย่างชัดเจนและไม่สมส่วนกับความพยายามที่จำเป็นในการเริ่มต้นใช้งานพื้นฐาน เราจะมุ่งเน้นไปที่สิ่งสำคัญและปล่อยให้การปรับปรุงเป็นสิ่งที่ท้าทายสำหรับคุณผู้อ่านที่รัก เราอาจจะหรืออาจจะไม่จัดการกับส่วนเสริมที่น่าสนใจกว่านี้ในบทความต่อๆ ไปของชุดนี้
น้ำตาลซินแทคติก
น้ำตาลวากยสัมพันธ์คือนิพจน์ที่ใช้เพื่อแสดงถึงโครงสร้างที่ทำให้ภาษาใช้งานง่ายขึ้น แต่การลบออกจะไม่ทำให้ภาษาการเขียนโปรแกรมสูญเสียฟังก์ชันการทำงาน ตัวอย่างที่ดีคือ
elsif. ของ Ruby สร้าง. ใน Stoffle เราไม่มีโครงสร้างดังกล่าว ดังนั้นเพื่อแสดงแบบเดียวกัน เราจึงถูกบังคับให้ต้องใช้ความละเอียดมากขึ้น:if some_condition # ... else # oops, no elsif available if another_condition # ... end end
พาร์เซอร์คืออะไร
เราเริ่มต้นด้วยซอร์สโค้ด ลำดับของอักขระแบบดิบ จากนั้น ดังที่แสดงในบทความก่อนหน้าในชุดนี้ lexer จะจัดกลุ่มอักขระเหล่านี้เป็นโครงสร้างข้อมูลที่เหมาะสมซึ่งเรียกว่าโทเค็น อย่างไรก็ตาม เรายังคงเหลือข้อมูลที่แบนราบโดยสิ้นเชิง ซึ่งเป็นสิ่งที่ยังไม่แสดงถึงลักษณะที่ซ้อนกันของซอร์สโค้ดอย่างเหมาะสม ดังนั้น parser จึงมีหน้าที่สร้างต้นไม้จากลำดับของอักขระนี้ เมื่อเสร็จสิ้นภารกิจ เราจะลงเอยด้วยข้อมูลที่ในที่สุดสามารถแสดงว่าแต่ละส่วนของโปรแกรมของเราซ้อนกันและเกี่ยวข้องกันอย่างไร
ต้นไม้ที่สร้างโดย parser โดยทั่วไปจะเรียกว่าโครงสร้างไวยากรณ์นามธรรม (AST) ตามชื่อที่สื่อถึง เรากำลังจัดการกับโครงสร้างข้อมูลแบบต้นไม้ โดยรูทของมันเป็นตัวแทนของตัวโปรแกรมเอง และโหนดลูกของโหนดโปรแกรมนี้เป็นนิพจน์มากมายที่ประกอบขึ้นเป็นโปรแกรมของเรา คำว่า นามธรรม ใน AST หมายถึงความสามารถของเราในการนามธรรมออกไป ส่วนที่, ในขั้นตอนก่อนหน้านี้, มีอยู่อย่างชัดเจน. ตัวอย่างที่ดีคือตัวยุตินิพจน์ (บรรทัดใหม่ในกรณีของ Stoffle); สิ่งเหล่านี้ได้รับการพิจารณาเมื่อสร้าง AST แต่เราไม่ต้องการประเภทโหนดเฉพาะเพื่อเป็นตัวแทนของตัวยุติ อย่างไรก็ตาม โปรดจำไว้ว่า เรามี โทเค็น . ที่ชัดเจน เพื่อเป็นตัวแทนของเทอร์มิเนเตอร์
การสร้างภาพตัวอย่าง AST จะมีประโยชน์หรือไม่ ความปรารถนาของคุณคือคำสั่ง! ด้านล่างนี้เป็นโปรแกรม Stoffle อย่างง่าย ซึ่งเราจะแยกวิเคราะห์ทีละขั้นตอนในภายหลังในโพสต์นี้ และแผนผังไวยากรณ์ที่เป็นนามธรรมที่เกี่ยวข้อง:
fn double: num
num * 2
end
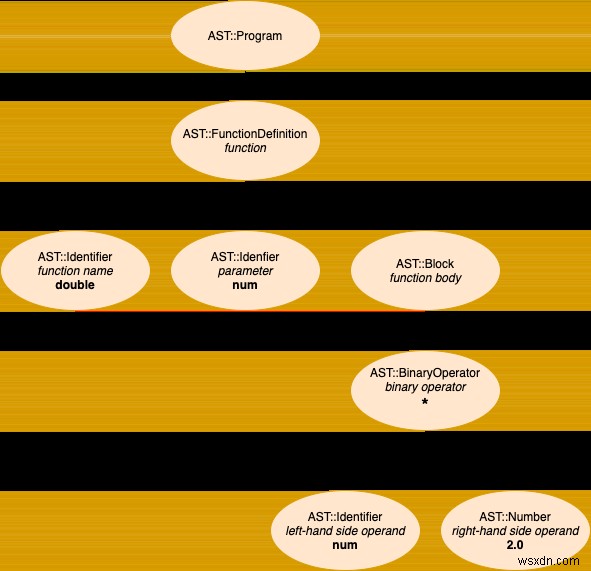
จากแหล่งที่มาสู่ AST ตัวอย่างแรก
ในส่วนนี้ของโพสต์ เราจะมาสำรวจทีละขั้นตอนว่า parser ของเราจัดการกับมากอย่างไร โปรแกรม Stoffle อย่างง่าย ประกอบด้วยบรรทัดเดียวที่แสดงการเชื่อมโยงตัวแปร (เช่น เรากำหนดค่าให้กับตัวแปร) นี่คือที่มา การแสดงโทเค็นที่ผลิตโดย lexer อย่างง่าย (โทเค็นเหล่านี้เป็นอินพุตที่ป้อนให้กับ parser ของเรา) และสุดท้าย การแสดงภาพของ AST ที่เราจะผลิตเพื่อเป็นตัวแทนของโปรแกรม:
ที่มา
my_var = 1
โทเค็น (เอาต์พุตของ Lexer, อินพุตสำหรับ Parser)
[:identifier, :'=', :number]
การแสดงภาพเอาต์พุตของ Parser (แผนผังไวยากรณ์ที่เป็นนามธรรม)
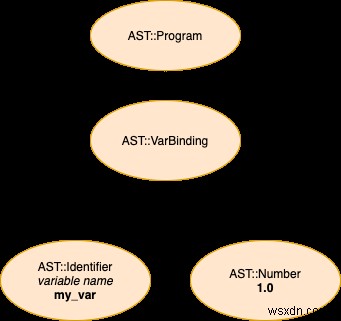
อย่างที่คุณอาจจินตนาการ แก่นของ parser ของเราคล้ายกับ core ของ lexer ของเรามาก ในกรณีของ lexer เรามีตัวละครมากมายที่ต้องดำเนินการ ตอนนี้ เรายังต้องวนซ้ำในคอลเล็กชัน แต่ในกรณีของ parser เราจะไปดูรายการโทเค็นที่เพื่อน lexer ของเราสร้าง เรามีตัวชี้เดียว (@next_p ) เพื่อติดตามตำแหน่งของเราในการรวบรวมโทเค็น ตัวชี้นี้ทำเครื่องหมาย ถัดไป โทเค็นที่จะประมวลผล แม้ว่าเราจะมีตัวชี้เพียงตัวเดียว แต่เราก็มีพอยน์เตอร์ "เสมือน" อื่นๆ อีกมากมายที่เราสามารถใช้ได้ตามต้องการ จะปรากฏขึ้นเมื่อเราดำเนินการตามขั้นตอน ตัวชี้ "เสมือน" ตัวหนึ่งคือ ปัจจุบัน (โดยทั่วไปโทเค็นที่ @next_p - 1 )
#parse เป็นวิธีเรียกให้แปลงโทเค็นเป็น AST ซึ่งจะอยู่ที่ @ast ตัวแปรอินสแตนซ์ การใช้งาน #parse ตรงไปตรงมา เราดำเนินการต่อไปในคอลเล็กชันโดยเรียก #consume และย้าย @next_p จนกว่าจะไม่มีโทเค็นให้ประมวลผลอีกต่อไป (เช่น ในขณะที่ next_p #parse_expr_recursively อาจส่งคืนโหนด AST หรือไม่มีอะไรเลย จำไว้ว่าเราไม่จำเป็นต้องเป็นตัวแทนของเทอร์มิเนเตอร์ใน AST เป็นต้น หากโหนดถูกสร้างขึ้นในการวนซ้ำปัจจุบันของลูป เราจะเพิ่มลงใน @ast ก่อนดำเนินการต่อ สิ่งสำคัญคือต้องจำไว้ว่า #parse_expr_recursively กำลังย้าย @next_p . ด้วย เนื่องจากเมื่อเราพบโทเค็นที่เป็นจุดเริ่มต้นของโครงสร้างเฉพาะ เราต้องก้าวหน้าหลายครั้งจนกว่าเราจะสามารถสร้างโหนดได้อย่างสมบูรณ์ซึ่งแสดงถึงสิ่งที่เรากำลังแยกวิเคราะห์อยู่ในขณะนี้ ลองนึกภาพว่าเราต้องใช้โทเค็นจำนวนเท่าใดเพื่อสร้างโหนดที่เป็นตัวแทนของ if .
module Stoffle
class Parser
attr_accessor :tokens, :ast, :errors
# ...
def initialize(tokens)
@tokens = tokens
@ast = AST::Program.new
@next_p = 0
@errors = []
end
def parse
while pending_tokens?
consume
node = parse_expr_recursively
ast << node if node != nil
end
end
# ...
end
end
ในข้อมูลโค้ดด้านบนนี้ เป็นครั้งแรกที่เราได้รับการนำเสนอด้วยโหนด AST ประเภทใดประเภทหนึ่งที่เป็นส่วนหนึ่งของการใช้งานโปรแกรมแยกวิเคราะห์ของเรา ด้านล่างนี้ เรามีซอร์สโค้ดแบบเต็มสำหรับ AST::Program ประเภทของโหนด คุณอาจเดาได้ว่านี่คือรากของแผนผังของเรา ซึ่งแสดงถึงโปรแกรมทั้งหมด มาดูส่วนที่น่าสนใจที่สุดกันดีกว่า:
- โปรแกรม Stoffle ประกอบด้วย
@expressions; นี่คือ#childrenของAST::Programโหนด; - อย่างที่คุณจะเห็นอีกครั้ง โหนดทุกประเภทใช้
#==กระบวนการ. ด้วยเหตุนี้ จึงเป็นเรื่องง่ายที่จะเปรียบเทียบโหนดธรรมดาสองโหนด เช่นเดียวกับโปรแกรมทั้งหมด! เมื่อเปรียบเทียบสองโปรแกรม (หรือโหนดที่ซับซ้อนสองโหนด) ความเท่าเทียมกันจะถูกกำหนดโดยความเท่าเทียมกันของเด็กทุกคน ความเท่าเทียมกันของเด็กทุกคนของเด็กทุกคน และอื่นๆ กลยุทธ์ที่เรียบง่ายแต่ทรงพลังนี้ใช้โดย#==มีประโยชน์อย่างมากสำหรับการทดสอบการใช้งานของเรา
class Stoffle::AST::Program
attr_accessor :expressions
def initialize
@expressions = []
end
def <<(expr)
expressions << expr
end
def ==(other)
expressions == other&.expressions
end
def children
expressions
end
end
นิพจน์เทียบกับคำสั่ง
ในบางภาษา โครงสร้างจำนวนมากไม่ได้สร้างมูลค่า เงื่อนไขเป็นตัวอย่างคลาสสิก สิ่งเหล่านี้เรียกว่า ข้อความ . อย่างไรก็ตาม โครงสร้างอื่นๆ จะประเมินค่า (เช่น การเรียกใช้ฟังก์ชัน) สิ่งเหล่านี้เรียกว่า นิพจน์ . อย่างไรก็ตาม ในภาษาอื่น ๆ ทุกอย่างเป็นการแสดงออกและสร้างคุณค่า Ruby เป็นตัวอย่างของแนวทางนี้ ตัวอย่างเช่น ลองพิมพ์ข้อมูลโค้ดต่อไปนี้ลงใน IRB เพื่อค้นหาว่าคำจำกัดความของวิธีการประเมินค่าใด:
irb(main):001:0> def two; 2; endหากคุณไม่รู้สึกอยากเลิกใช้ IRB ให้ฉันแจ้งข่าวให้คุณทราบ ใน Ruby นิยามเมธอด นิพจน์ ประเมินเป็นสัญลักษณ์ (ชื่อเมธอด) ดังที่คุณทราบ Stoffle ได้รับแรงบันดาลใจอย่างมากใน Ruby ดังนั้นในภาษาของเล่นตัวน้อยของเรา ทุกสิ่งทุกอย่างจึงเป็นการแสดงออก
โปรดทราบว่าคำจำกัดความเหล่านี้ดีเพียงพอสำหรับวัตถุประสงค์ในทางปฏิบัติ แต่ไม่มีฉันทามติจริงๆ และคุณอาจเห็นว่าคำชี้แจงและนิพจน์ถูกกำหนดแตกต่างกันที่อื่น
ดำน้ำลึก:การเริ่มต้นใช้งาน #parse_expr_recursively
ตามที่เราเพิ่งเห็นในตัวอย่างด้านบน #parse_expr_recursively เป็นวิธีการที่เรียกเพื่อสร้างโหนด AST ใหม่ #parse_expr_recursively ใช้วิธีอื่นๆ ที่มีขนาดเล็กกว่ามากมายในกระบวนการแยกวิเคราะห์ แต่เราสามารถพูดได้อย่างสบายใจว่ามันเป็นเอ็นจิ้นที่แท้จริงของ parser ของเรา แม้ว่าจะไม่นานนัก แต่วิธีนี้ย่อยยากกว่า ดังนั้นเราจะสับมันออกเป็นสองส่วน ในส่วนนี้ของโพสต์ มาเริ่มกันที่เซ็กเมนต์เริ่มต้น ซึ่งมีประสิทธิภาพเพียงพอที่จะแยกวิเคราะห์บางส่วนที่ง่ายกว่าของภาษาการเขียนโปรแกรม Stoffle เพื่อเป็นการทบทวน จำไว้ว่าเรากำลังดำเนินการตามขั้นตอนที่จำเป็นในการแยกวิเคราะห์โปรแกรมอย่างง่ายที่ประกอบด้วยนิพจน์การโยงตัวแปรเดียว:
ที่มา
my_var = 1
โทเค็น (เอาต์พุตของ Lexer, อินพุตสำหรับ Parser)
[:identifier, :'=', :number]
หลังจากดูโทเค็นแล้ว เราต้องจัดการและจินตนาการว่าเอาต์พุต lexer จะเป็นอย่างไรสำหรับนิพจน์ง่ายๆ อื่นๆ ที่คล้ายกัน ดูเหมือนว่าเป็นความคิดที่ดีที่จะลองเชื่อมโยงประเภทโทเค็นกับวิธีแยกวิเคราะห์เฉพาะ:
def parse_expr_recursively
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
send(parsing_function)
end
ในการใช้งานครั้งแรกของ #parse_expr_recursively นั่นคือสิ่งที่เราทำ เนื่องจากจะมี ค่อนข้างเยอะ ของโทเค็นประเภทต่างๆ ที่เราจะต้องจัดการ จะดีกว่าที่จะแยกกระบวนการตัดสินใจนี้ไปยังวิธีที่แยกต่างหาก -#determine_parsing_function ที่เราจะได้เห็นในไม่ช้านี้
เมื่อเราดำเนินการเสร็จแล้ว ไม่ควรมีโทเค็นใดที่เราไม่รู้จัก แต่เพื่อเป็นการป้องกัน เราจะตรวจสอบว่าฟังก์ชันการแยกวิเคราะห์เชื่อมโยงกับโทเค็นปัจจุบันหรือไม่ หากไม่เป็นเช่นนั้น เราจะเพิ่มข้อผิดพลาดให้กับตัวแปรอินสแตนซ์ @errors ซึ่งมีประเด็นทั้งหมดที่เกิดขึ้นระหว่างการแยกวิเคราะห์ เราจะไม่กล่าวถึงรายละเอียดที่นี่ แต่คุณสามารถตรวจสอบการใช้งาน parser แบบเต็มได้ที่ GitHub หากคุณสงสัย
#determine_parsing_function ส่งกลับสัญลักษณ์แทนชื่อของวิธีการแยกวิเคราะห์ที่จะเรียก เราจะใช้ send ของ Ruby เพื่อเรียกวิธีการที่เหมาะสมได้ทันที
การกำหนดวิธีการแยกวิเคราะห์และการแยกวิเคราะห์การเชื่อมโยงตัวแปร
ต่อไป มาดู #determine_parsing_function . กัน เพื่อทำความเข้าใจกลไกเริ่มต้นนี้สำหรับการเรียกเมธอดเฉพาะเพื่อแยกวิเคราะห์โครงสร้างต่างๆ ของ Stoffle #determine_parsing_function จะใช้สำหรับทุกอย่าง (เช่น คีย์เวิร์ดและโอเปอเรเตอร์เอก) ยกเว้นโอเปอเรเตอร์ไบนารี ต่อไปเราจะสำรวจเทคนิคที่ใช้ในกรณีของตัวดำเนินการไบนารี ตอนนี้ มาดู #determine_parsing_function . กัน :
def determine_parsing_function
if [:return, :identifier, :number, :string, :true, :false, :nil, :fn,
:if, :while].include?(current.type)
"parse_#{current.type}".to_sym
elsif current.type == :'('
:parse_grouped_expr
elsif [:"\n", :eof].include?(current.type)
:parse_terminator
elsif UNARY_OPERATORS.include?(current.type)
:parse_unary_operator
end
end
ตามที่อธิบายไว้ก่อนหน้านี้ #current เป็น เสมือน ตัวชี้ไปยังโทเค็นที่กำลังดำเนินการอยู่ในขณะนี้ การใช้งาน #determine_parsing_function ตรงไปตรงมามาก เราดูที่โทเค็นปัจจุบัน (โดยเฉพาะ ประเภท ) และส่งคืนสัญลักษณ์ที่แสดงวิธีการเรียกที่เหมาะสม
จำไว้ว่าเรากำลังดำเนินการตามขั้นตอนที่จำเป็นในการแยกวิเคราะห์การเชื่อมโยงตัวแปร (my_var =1 ) ดังนั้นประเภทโทเค็นที่เรากำลังจัดการคือ [:identifier, :'=', :number] . ประเภทโทเค็นปัจจุบันคือ :identifier ดังนั้น #determine_parsing_function จะส่งคืน :parse_identifier อย่างที่คุณอาจเดาได้ มาดูขั้นตอนต่อไปของเรา #parse_identifier วิธีการ:
def parse_identifier
lookahead.type == :'=' ? parse_var_binding : AST::Identifier.new(current.lexeme)
end
ในที่นี้ เรามีการแสดงให้เห็นอย่างง่าย ๆ โดยพื้นฐานแล้ว วิธีการแยกวิเคราะห์อื่นๆ ทั้งหมดทำกันอย่างไร ใน #parse_identifier - และในวิธีแยกวิเคราะห์อื่นๆ เราตรวจสอบโทเค็นเพื่อพิจารณาว่าโครงสร้างที่เราคาดว่ามีอยู่จริงหรือไม่ เรารู้ว่าเรามีตัวระบุ แต่เราต้องดูโทเค็นถัดไปเพื่อพิจารณาว่าเรากำลังจัดการกับการเชื่อมโยงตัวแปรหรือไม่ ซึ่งจะเป็นกรณีนี้หากโทเค็นประเภทถัดไปคือ :'=' หรือถ้าเราเพิ่งมีตัวระบุเองหรือมีส่วนร่วมในนิพจน์ที่ซับซ้อนมากขึ้น ตัวอย่างเช่น ลองนึกภาพนิพจน์เลขคณิตที่เราจัดการค่าที่เก็บไว้ในตัวแปร
เนื่องจากเรามี :'=' ต่อไป #parse_var_binding กำลังจะถูกเรียกว่า:
def parse_var_binding
identifier = AST::Identifier.new(current.lexeme)
consume(2)
AST::VarBinding.new(identifier, parse_expr_recursively)
end
ที่นี่ เราเริ่มต้นด้วยการสร้างโหนด AST ใหม่เพื่อแสดงตัวระบุที่เรากำลังดำเนินการอยู่ ตัวสร้างสำหรับ AST::Identifier ต้องการ lexeme ของโทเค็นตัวระบุ (เช่น ลำดับของอักขระ สตริง "my_var" ในกรณีของเรา) นั่นคือสิ่งที่เราจัดหาให้ จากนั้นเราจะเพิ่มจุดสองจุดในสตรีมของโทเค็นที่อยู่ระหว่างการประมวลผล ทำให้โทเค็นเป็นประเภท :number ต่อไปที่จะวิเคราะห์ จำไว้ว่าเรากำลังติดต่อกับ [:identifier, :'=', :number] .
สุดท้าย เราสร้างและส่งคืนโหนด AST ที่แสดงถึงการเชื่อมโยงตัวแปร ตัวสร้างสำหรับ AST::VarBinding ต้องการสองพารามิเตอร์:ตัวระบุโหนด AST (ด้านซ้ายมือของนิพจน์การโยง) และนิพจน์ที่ถูกต้องใดๆ (ด้านขวามือ) มีสิ่งสำคัญอย่างหนึ่งที่ควรทราบที่นี่ เพื่อสร้างด้านขวามือของนิพจน์การโยงตัวแปร เราเรียก #parse_expr_recursively อีกแล้ว . นี้อาจรู้สึกแปลกเล็กน้อยในตอนแรก แต่จำไว้ว่าตัวแปรสามารถผูกกับนิพจน์ที่ซับซ้อนมาก ไม่เพียงแต่เป็นตัวเลขเท่านั้น ดังเช่นในตัวอย่างของเรา ถ้าเรากำหนดกลยุทธ์การแยกวิเคราะห์ด้วยคำเดียว มันจะเป็น แบบเรียกซ้ำ . ฉันเดาว่าคุณกำลังเริ่มเข้าใจว่าทำไม #parse_expr_recursively มีชื่อที่มี
ก่อนจบส่วนนี้ เราควรสำรวจทั้ง AST::Identifier . อย่างรวดเร็ว และ AST::VarBinding . ก่อนอื่น AST::Identifier :
class Stoffle::AST::Identifier < Stoffle::AST::Expression
attr_accessor :name
def initialize(name)
@name = name
end
def ==(other)
name == other&.name
end
def children
[]
end
end
ไม่มีอะไรแฟนซีที่นี่ เป็นมูลค่าการกล่าวขวัญว่าโหนดเก็บชื่อของตัวแปรและไม่มีลูก
ตอนนี้ AST::VarBinding :
class Stoffle::AST::VarBinding < Stoffle::AST::Expression
attr_accessor :left, :right
def initialize(left, right)
@left = left
@right = right
end
def ==(other)
children == other&.children
end
def children
[left, right]
end
end
ด้านซ้ายมือคือ AST::Identifier โหนด ทางด้านขวามือเป็นโหนดเกือบทุกประเภทที่เป็นไปได้ - จากตัวเลขอย่างง่าย ดังในตัวอย่างของเรา ไปจนถึงบางสิ่งที่ซับซ้อนกว่า - แสดงถึงนิพจน์ที่ตัวระบุถูกผูกไว้ #children ของการเชื่อมโยงตัวแปรคือโหนด AST ที่อยู่ใน @left และ @right .
จากแหล่งที่มาสู่ AST ตัวอย่างที่สอง
ชาติปัจจุบันของ #parse_expr_recursively สามารถแยกวิเคราะห์นิพจน์ง่ายๆ บางอย่างได้แล้ว ดังที่เราเห็นในส่วนที่แล้ว ในส่วนนี้ เราจะดำเนินการให้เสร็จสิ้นเพื่อให้สามารถแยกวิเคราะห์เอนทิตีที่ซับซ้อนมากขึ้น เช่น ตัวดำเนินการไบนารีและตรรกะ ที่นี่ เราจะสำรวจทีละขั้นตอนว่า parser ของเราจัดการกับโปรแกรมที่กำหนดฟังก์ชันอย่างไร นี่คือที่มา การแสดงโทเค็นอย่างง่ายที่สร้างโดย lexer และดังที่เรามีในส่วนแรก การแสดงภาพของ AST ที่เราจะสร้างขึ้นเพื่อเป็นตัวแทนของโปรแกรม:
ที่มา
fn double: num
num * 2
end
โทเค็น (เอาต์พุตของ Lexer, อินพุตสำหรับ Parser)
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
การแสดงภาพแทนเอาต์พุต Parser (แผนผังไวยากรณ์ที่เป็นนามธรรม)
ก่อนที่เราจะดำเนินการต่อ ให้ย้อนกลับไปและพูดถึงกฎลำดับความสำคัญของตัวดำเนินการ สิ่งเหล่านี้มีพื้นฐานมาจากอนุสัญญาทางคณิตศาสตร์ ในวิชาคณิตศาสตร์ มันเป็นแค่ข้อตกลง และแน่นอน ไม่มีอะไรพื้นฐานที่ส่งผลในลำดับความสำคัญของตัวดำเนินการที่เราคุ้นเคย กฎเหล่านี้ยังช่วยให้เรากำหนดลำดับที่ถูกต้องสำหรับการประเมินนิพจน์ และในกรณีของเรา ให้แยกวิเคราะห์ก่อน ในการกำหนดลำดับความสำคัญของโอเปอเรเตอร์แต่ละตัว เราก็มีแผนที่ (เช่น แฮช ) ของประเภทโทเค็นและจำนวนเต็ม ตัวเลขที่สูงกว่าหมายถึงควรจัดการตัวดำเนินการ ก่อน :
# We define these precedence rules at the top of Stoffle::Parser.
module Stoffle
class Parser
# ...
UNARY_OPERATORS = [:'!', :'-'].freeze
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
LOWEST_PRECEDENCE = 0
PREFIX_PRECEDENCE = 7
OPERATOR_PRECEDENCE = {
or: 1,
and: 2,
'==': 3,
'!=': 3,
'>': 4,
'<': 4,
'>=': 4,
'<=': 4,
'+': 5,
'-': 5,
'*': 6,
'/': 6,
'(': 8
}.freeze
# ...
end
end
เทคนิคที่ใช้ใน #parse_expr_recursively ขึ้นอยู่กับอัลกอริธึม parser ที่มีชื่อเสียงที่นำเสนอโดยนักวิทยาศาสตร์คอมพิวเตอร์ Vaughan Pratt ในบทความปี 1973 ของเขา "Top Down Operator Precedence" อย่างที่คุณเห็น อัลกอริทึมนั้นง่ายมาก แต่เข้าใจยากเล็กน้อย หนึ่งสามารถพูดได้ว่ารู้สึกมีมนต์ขลังเล็กน้อย สิ่งที่เราจะทำในโพสต์นี้เพื่อพยายามทำความเข้าใจการทำงานของเทคนิคนี้โดยสัญชาตญาณคือไปทีละขั้นตอน ผ่านสิ่งที่เกิดขึ้นเมื่อเราแยกวิเคราะห์ข้อมูลโค้ด Stoffle ที่กล่าวถึงข้างต้น ดังนั้น โดยไม่ต้องกังวลใจอีกต่อไป นี่คือเวอร์ชันที่สมบูรณ์ของ #parse_expr_recursively :
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that, here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
#parse_expr_recursively ตอนนี้ยอมรับพารามิเตอร์ ลำดับความสำคัญ . มันแสดงถึงลำดับความสำคัญ "ระดับ" ที่จะพิจารณาในการเรียกเมธอดที่กำหนด นอกจากนี้ ส่วนแรกของวิธีการค่อนข้างจะเหมือนกัน ถ้าอย่างนั้น - ถ้าเราสามารถสร้างนิพจน์ในส่วนแรกนี้ได้ - ชิ้นส่วนใหม่ของวิธีการก็มาถึง ในขณะที่โทเค็นตัวถัดไปไม่ใช่ตัวสิ้นสุด (เช่น ตัวแบ่งบรรทัดหรือส่วนท้ายของไฟล์) และลำดับความสำคัญ (precedence พารามิเตอร์) ต่ำกว่าลำดับความสำคัญของโทเค็นถัดไป เราอาจใช้สตรีมโทเค็นต่อไป
ก่อนจะมองเข้าไปข้างใน ในขณะที่ ลองคิดกันสักนิดเกี่ยวกับความหมายของเงื่อนไขที่สอง (precedence expr ตัวแปรท้องถิ่น) น่าจะเป็นลูกของโหนดที่ยังไม่ได้สร้าง (จำไว้ว่าเรากำลังสร้าง AST ซึ่งเป็น ต้นไม้ ไวยากรณ์นามธรรม ). ก่อนดำเนินการแยกวิเคราะห์ข้อมูลโค้ด Stoffle ให้พิจารณาการแยกวิเคราะห์นิพจน์ทางคณิตศาสตร์อย่างง่าย:2 + 2 . เมื่อแยกวิเคราะห์นิพจน์นี้ ส่วนแรกของเมธอดของเราจะสร้าง AST::Number โหนดที่เป็นตัวแทนของ 2 . ตัวแรก และเก็บไว้ใน expr . จากนั้นเราจะก้าวเข้าสู่ ในขณะที่ เพราะลำดับความสำคัญของโทเค็นถัดไป (:'+' ) จะสูงกว่าลำดับความสำคัญเริ่มต้น จากนั้นเราจะมีวิธีการแยกวิเคราะห์เพื่อจัดการกับผลรวมที่เรียก โดยส่งผ่าน AST::Number โหนดและรับกลับโหนดที่เป็นตัวแทนของตัวดำเนินการไบนารี (AST::BinaryOperator ). สุดท้าย เราจะเขียนทับ ค่าที่เก็บไว้ใน expr , โหนดที่เป็นตัวแทนของ 2 . ตัวแรก ใน 2 + 2 โดยโหนดใหม่นี้เป็นตัวแทนของตัวดำเนินการบวก ขอให้สังเกตว่าในท้ายที่สุด อัลกอริธึมนี้ทำให้เรา จัดเรียงโหนดใหม่; เราเริ่มต้นด้วยการสร้าง AST::Number node และจบลงด้วยการเป็นโหนดที่ลึกกว่าในทรีของเรา ในฐานะหนึ่งในลูกของ AST::BinaryOperator โหนด
การแยกวิเคราะห์นิยามฟังก์ชันทีละขั้นตอน
ตอนนี้เราได้อ่านคำอธิบายโดยรวมของ #parse_expr_recursively . แล้ว กลับไปที่นิยามฟังก์ชันอย่างง่ายของเรา:
fn double: num
num * 2
end
แม้แต่แนวคิดในการดูคำอธิบายแบบง่ายของการดำเนินการ parser ขณะที่เราแยกวิเคราะห์ข้อมูลโค้ดนี้อาจรู้สึกน่าเบื่อ (และแน่นอน อาจจะเป็นอย่างนั้น!) แต่ฉันคิดว่ามันมีค่ามากสำหรับการทำความเข้าใจทั้ง #parse_expr_recursively#parse_expr_recursively /code> และการแยกวิเคราะห์บิตเฉพาะ (นิยามฟังก์ชันและตัวดำเนินการผลิตภัณฑ์) อย่างแรกเลย นี่คือประเภทโทเค็นที่เราจะจัดการ (ด้านล่างคือผลลัพธ์สำหรับ @tokens.map(&:type) , ภายใน parser หลังจากที่ lexer ทำโทเค็นข้อมูลโค้ดที่เราเพิ่งเห็นเสร็จแล้ว):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
ตารางด้านล่างแสดงลำดับการเรียกวิธีการที่สำคัญที่สุดเมื่อเราแยกวิเคราะห์โทเค็นด้านบน โปรดทราบว่านี่เป็นการทำให้เข้าใจง่าย และหากคุณต้องการเข้าใจขั้นตอนที่แน่นอนของการดำเนินการ parser จริงๆ ฉันขอแนะนำให้ใช้โปรแกรมแก้ไขข้อบกพร่อง Ruby เช่น Byebug และเลื่อนทีละบรรทัดขณะที่โปรแกรมดำเนินการ
ตัวแยกวิเคราะห์ของเราภายใต้กล้องจุลทรรศน์
มีการทดสอบที่ใช้ตัวอย่างที่เรากำลังสำรวจซึ่งมีอยู่ในแหล่งที่มาของ Stoffle คุณสามารถค้นหาได้ใน spec/lib/stoffle/parser_spec.rb; เป็นการทดสอบที่ใช้ตัวอย่างชื่อ
complex_program_ok_2.sfe.หากต้องการสำรวจการดำเนินการ parser ทีละขั้นตอน คุณสามารถแก้ไขแหล่งที่มาและเพิ่มการเรียกไปที่
byebugที่จุดเริ่มต้นของParser#parseให้รันเฉพาะการทดสอบดังกล่าวด้วย RSpec จากนั้นใช้ขั้นตอนของ Byebug คำสั่งให้เลื่อนโปรแกรมทีละบรรทัดดูข้อมูลเพิ่มเติมเกี่ยวกับวิธีการทำงานของ Byebug และคำสั่งที่มีอยู่ทั้งหมดโดยไปที่ไฟล์ README ของโครงการที่ GitHub
| วิธีการเรียก | โทเค็นปัจจุบัน | โทเค็นถัดไป | ตัวแปรเด่น / ผลการเรียก | Obs |
|---|---|---|---|---|
| แยกวิเคราะห์ | ไม่มี | :fn | ||
| parse_expr_recursively | :fn | :ตัวระบุ | ลำดับความสำคัญ =0, parsing_function =:parse_fn | |
| parse_function_definition | :fn | :ตัวระบุ | parse_fn เป็นนามแฝงของ parse_function_definition | |
| parse_function_params | :ตัวระบุ | :":" | ||
| parse_block | :"\n" | :ตัวระบุ | ||
| parse_expr_recursively | :ตัวระบุ | :* | ลำดับความสำคัญ =0, parsing_function =:parse_identifier, nxt_precedence() คืนค่า 6, infix_parsing_function =:parse_binary_operator | |
| parse_identifier | :ตัวระบุ | :* | ||
| parse_binary_operator | :* | :หมายเลข | op_precedence =6 | |
| parse_expr_recursively | :หมายเลข | :"\n" | ลำดับความสำคัญ =6, parsing_function =:parse_number, nxt_precedence() คืนค่า 0 | |
| parse_number | :หมายเลข | :"\n" |
ตอนนี้เรามีแนวคิดทั่วไปแล้วว่ามีการเรียกเมธอดใด เช่นเดียวกับลำดับ มาศึกษาวิธีการแยกวิเคราะห์บางวิธีที่เรายังไม่ได้เห็นในรายละเอียดมากกว่านี้
วิธี #parse_function_definition
เมธอด #parse_function_definition ถูกเรียกเมื่อโทเค็นปัจจุบันคือ :fn และอันต่อไปคือ :identifier :
def parse_function_definition
return unless consume_if_nxt_is(build_token(:identifier))
fn = AST::FunctionDefinition.new(AST::Identifier.new(current.lexeme))
if nxt.type != :"\n" && nxt.type != :':'
unexpected_token_error
return
end
fn.params = parse_function_params if nxt.type == :':'
return unless consume_if_nxt_is(build_token(:"\n", "\n"))
fn.body = parse_block
fn
end
#consume_if_nxt_is - อย่างที่คุณอาจเดาได้ - เลื่อนตัวชี้ของเราหากโทเค็นถัดไปเป็นประเภทที่กำหนด มิฉะนั้น จะเพิ่มข้อผิดพลาดใน @errors . #consume_if_nxt_is มีประโยชน์มาก - และใช้ในวิธี parser มากมาย - เมื่อเราต้องการตรวจสอบโครงสร้างของโทเค็นเพื่อตรวจสอบว่าเรามีไวยากรณ์ที่ถูกต้องหรือไม่ หลังจากทำเช่นนั้น โทเค็นปัจจุบันจะเป็นประเภท :identifier (เรากำลังจัดการ 'double' ชื่อของฟังก์ชัน) และเราสร้าง AST::Identifier และส่งไปยังคอนสตรัคเตอร์เพื่อสร้างโหนดเพื่อแสดงนิยามฟังก์ชัน (AST::FunctionDefinition ). เราจะไม่ดูรายละเอียดที่นี่ แต่โดยพื้นฐานแล้ว AST::FunctionDefinition โหนดคาดหวังชื่อฟังก์ชัน อาจเป็นอาร์เรย์ของพารามิเตอร์และเนื้อหาของฟังก์ชัน
ขั้นตอนต่อไปใน #parse_function_definition คือการตรวจสอบว่าโทเค็นถัดไปหลังจากตัวระบุเป็นตัวยุตินิพจน์ (เช่น ฟังก์ชันที่ไม่มีพารามิเตอร์) หรือโคลอน (เช่น ฟังก์ชันที่มีพารามิเตอร์หนึ่งตัวหรือหลายตัว) หากเรามีพารามิเตอร์เช่นเดียวกับ double ฟังก์ชันที่เรากำหนด เราเรียก #parse_function_params เพื่อแยกวิเคราะห์พวกเขา เราจะตรวจสอบวิธีการนี้ในอีกสักครู่ แต่ก่อนอื่นเรามาทำการสำรวจ #parse_function_definition ให้เสร็จสิ้นก่อน .
ขั้นตอนสุดท้ายคือการตรวจสอบไวยากรณ์อื่นเพื่อตรวจสอบว่ามีตัวสิ้นสุดหลังจากชื่อฟังก์ชัน + params จากนั้นให้ดำเนินการแยกวิเคราะห์เนื้อหาของฟังก์ชันโดยเรียก #parse_block . สุดท้าย เราคืน fn ซึ่งเก็บ AST::FunctionDefinition . ที่สร้างขึ้นอย่างสมบูรณ์ของเรา เช่น มีชื่อฟังก์ชัน พารามิเตอร์ และเนื้อหาครบถ้วน
การแยกวิเคราะห์ถั่วและสลักเกลียวของพารามิเตอร์ฟังก์ชัน
ในส่วนที่แล้ว เราเห็นว่า #parse_function_params ถูกเรียกภายใน #parse_function_definition . หากเรากลับไปที่ตารางของเราเพื่อสรุปขั้นตอนการดำเนินการและสถานะของ parser เราจะเห็นว่าเมื่อ #parse_function_params เริ่มทำงาน โทเค็นปัจจุบันเป็นประเภท :identifier และอันต่อไปคือ :":" (เช่น เราเพิ่งแยกวิเคราะห์ชื่อฟังก์ชันเสร็จ) เมื่อคำนึงถึงสิ่งนี้แล้ว มาดูโค้ดเพิ่มเติมกัน:
def parse_function_params
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers = []
identifiers << AST::Identifier.new(current.lexeme)
while nxt.type == :','
consume
return unless consume_if_nxt_is(build_token(:identifier))
identifiers << AST::Identifier.new(current.lexeme)
end
identifiers
end
ก่อนที่ฉันจะอธิบายแต่ละส่วนของวิธีนี้ มาสรุปโทเค็นที่เราต้องดำเนินการและเราอยู่ในงานนี้:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# here ▲
ส่วนแรกของ #parse_function_params ตรงไปตรงมา หากเรามีไวยากรณ์ที่ถูกต้อง (อย่างน้อยหนึ่งตัวระบุหลัง : ) ในที่สุดเราก็เลื่อนตัวชี้ไปสองตำแหน่ง:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
ตอนนี้ เรากำลังนั่งอยู่ที่พารามิเตอร์แรกที่จะแยกวิเคราะห์ (โทเค็นประเภท :identifier ). ตามที่คาดไว้ เราสร้าง AST::Identifier และส่งไปยังอาร์เรย์ของพารามิเตอร์อื่น ๆ ที่อาจยังไม่ได้แยกวิเคราะห์ ในบิตถัดไปของ #parse_function_params เราแยกวิเคราะห์พารามิเตอร์ต่อไปตราบใดที่ยังมีตัวคั่นพารามิเตอร์ (เช่น โทเค็นประเภท :',' ). เราสิ้นสุดวิธีการโดยส่งคืน var identifiers . ในเครื่อง อาร์เรย์ที่มี AST::Identifier หลายตัว โหนด แต่ละโหนดแทนหนึ่งพารามิเตอร์ อย่างไรก็ตาม ในกรณีของเรา อาร์เรย์นี้มีเพียงองค์ประกอบเดียว
แล้วเนื้อหาเกี่ยวกับฟังก์ชันล่ะ
ตอนนี้ มาเจาะลึกในส่วนสุดท้ายของการแยกวิเคราะห์นิยามฟังก์ชัน:การจัดการกับเนื้อหา เมื่อ #parse_block เรียกว่าเรากำลังนั่งอยู่ที่เทอร์มิเนเตอร์ที่ทำเครื่องหมายจุดสิ้นสุดของรายการพารามิเตอร์ฟังก์ชัน:
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, here's the implementation of #parse_block :
def parse_block
consume
block = AST::Block.new
while current.type != :end && current.type != :eof && nxt.type != :else
expr = parse_expr_recursively
block << expr unless expr.nil?
consume
end
unexpected_token_error(build_token(:eof)) if current.type == :eof
block
end
AST::Block is the AST node for representing, well, a block of code. In other words, AST::Block just holds a list of expressions, in a very similar fashion as the root node of our program, an AST::Program node (as we saw at the beginning of this post). To parse the block (i.e., the function body), we continue advancing through unprocessed tokens until we encounter a token that marks the end of the block.
To parse the expressions that compose the block, we use our already-known #parse_expr_recursively . We will step into this method call in just a moment; this is the point in which we will start parsing the product operation happening inside our double function. Following this closely will allow us to understand the use of precedence values inside #parse_expr_recursively and how an infix operator (the * in our case) gets dealt with. Before we do that, however, let's finish our exploration of #parse_block .
Before returning an AST node representing our block, we check whether the current token is of type :eof . If this is the case, we have a syntax error since Stoffle requires a block to end with the end keyword. To wrap up the explanation of #parse_block , I should mention something you have probably noticed; one of the conditions of our loop verifies whether the next token is of type :else . This happens because #parse_block is shared by other parsing methods, including the methods responsible for parsing conditionals and loops. Pretty neat, huh?!
Parsing Infix Operators
The name may sound a bit fancy, but infix operators are, basically, those we are very used to seeing in arithmetic, plus some others that we may be more familiar with by being software developers:
module Stoffle
class Parser
# ...
BINARY_OPERATORS = [:'+', :'-', :'*', :'/', :'==', :'!=', :'>', :'<', :'>=', :'<='].freeze
LOGICAL_OPERATORS = [:or, :and].freeze
# ...
end
end
They are expected to be used infixed when the infix notation is used, as is the case with Stoffle, which means they should appear in the middle of their two operands (e.g., as * appears in num * 2 in our double function). Something worth mentioning is that although the infix notation is pretty popular, there are other ways of positioning operators in relation to their operands. If you are curious, research a little bit about "Polish notation" and "reverse Polish notation" methods.
To finish parsing our double function, we have to deal with the * operator:
fn double: num
num * 2
end
In the previous section, we mentioned that parsing the expression that composes the body of double starts when #parse_expr_recursively is called within #parse_block . When that happens, here's our position in @tokens :
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
# ▲
And, to refresh our memory, here's the code for #parse_expr_recursively again:
def parse_expr_recursively(precedence = LOWEST_PRECEDENCE)
parsing_function = determine_parsing_function
if parsing_function.nil?
unrecognized_token_error
return
end
expr = send(parsing_function)
return if expr.nil? # When expr is nil, it means we have reached a \n or a eof.
# Note that here, we are checking the NEXT token.
while nxt_not_terminator? && precedence < nxt_precedence
infix_parsing_function = determine_infix_function(nxt)
return expr if infix_parsing_function.nil?
consume
expr = send(infix_parsing_function, expr)
end
expr
end
In the first part of the method, we will use the same #parse_identifier method we used to parse the num variable. Then, for the first time, the conditions of the while loop will evaluate to true; the next token is not a terminator, and the precedence of the next token is greater than the precedence of this current execution of parse_expr_recursively (precedence is the default, 0, while nxt_precedence returns 6 since the next token is of type :'*' ). This indicates that the node we already built (an AST::Identifier representing num ) will probably be deeper in our AST (i.e., it will be the child of a node yet to be built). We enter the loop and call #determine_infix_function , passing to it the next token (the * ):
def determine_infix_function(token = current)
if (BINARY_OPERATORS + LOGICAL_OPERATORS).include?(token.type)
:parse_binary_operator
elsif token.type == :'('
:parse_function_call
end
end
Since * is a binary operator, running #determine_infix_function will result in :parse_binary_operator . Back in #parse_expr_recursively , we will advance our tokens pointer by one position and then call #parse_binary_operator , passing along the value of expr (the AST::Identifier representing num ):
[:fn, :identifier, :":", :identifier, :"\n", :identifier, :*, :number, :"\n", :end, :"\n", :eof]
#▲
def parse_binary_operator(left)
op = AST::BinaryOperator.new(current.type, left)
op_precedence = current_precedence
consume
op.right = parse_expr_recursively(op_precedence)
op
end
class Stoffle::AST::BinaryOperator < Stoffle::AST::Expression
attr_accessor :operator, :left, :right
def initialize(operator, left = nil, right = nil)
@operator = operator
@left = left
@right = right
end
def ==(other)
operator == other&.operator && children == other&.children
end
def children
[left, right]
end
end
At #parse_binary_operator , we create an AST::BinaryOperator (its implementation is shown above if you are curious) to represent * , setting its left operand to the identifier (num ) we received from #parse_expr_recursively . Then, we save the precedence value of * at the local var op_precedence and advance our token pointer. To finish building our node representing * , we call #parse_expr_recursively again! We need to proceed in this fashion because the right-hand side of our operator will not always be a single number or identifier; it can be a more complex expression, such as something like num * (2 + 2) .
One thing of utmost importance that happens here at #parse_binary_operator is the way in which we call #parse_expr_recursively back again. We call it passing 6 as a precedence value (the precedence of * , stored at op_precedence ). Here we observe an important aspect of our parsing algorithm, which was mentioned previously. By passing a relatively high precedence value, it seems like * is pulling the next token as its operand. Imagine we were parsing an expression like num * 2 + 1; in this case, the precedence value of * passed in to this next call to #parse_expr_recursively would guarantee that the 2 would end up being the right-hand side of * and not an operand of + , which has a lower precedence value of 5 .
After #parse_expr_recursively returns an AST::Number node, we set it as the right-hand size of * and, finally, return our complete AST::BinaryOperator node. At this point, we have, basically, finished parsing our Stoffle program. We still have to parse some terminator tokens, but this is straightforward and not very interesting. At the end, we will have an AST::Program instance at @ast with expressions that could be visually represented as the tree we saw at the beginning of this post and in the introduction to the second section of the post:
Wrapping Up
In this post, we covered the principal aspects of Stoffle's parser. If you understand the bits we explored here, you shouldn't have much trouble understanding other parser methods we were not able to cover, such as parsing conditionals and loops. I encourage you to explore the source code of the parser by yourself and tweak the implementation if you are feeling more adventurous! The implementation is accompanied by a comprehensive test suite, so don't be afraid to try things out and mess up with the parser.
In subsequent posts in this series, we will finally breathe life into our little monster by implementing the last bit we are missing:the tree-walk interpreter. I can't wait to be there with you as we run our first Stoffle program!
