
ที่มาแบบเต็มบน Github
มีการใช้งานภาษาการเขียนโปรแกรม Stoffle อย่างสมบูรณ์ที่ GitHub อย่าลังเลที่จะเปิดปัญหาหากคุณพบข้อบกพร่องหรือมีคำถาม
ในบล็อกโพสต์นี้ เราจะเริ่มใช้งานล่ามสำหรับ Stoffle ซึ่งเป็นภาษาการเขียนโปรแกรมของเล่นที่สร้างขึ้นใน Ruby ทั้งหมด คุณสามารถอ่านเพิ่มเติมเกี่ยวกับโครงการนี้ได้ในส่วนแรกของชุดนี้
ล่ามที่เราจะสร้างมักเรียกกันว่าล่ามเดินตามต้นไม้ ในโพสต์ก่อนหน้าของซีรีส์นี้ เราได้สร้าง parser เพื่อแปลงลำดับของโทเค็นแบบเรียบๆ ให้เป็นโครงสร้างข้อมูลแบบทรี (แผนผังไวยากรณ์นามธรรมหรือ AST แบบสั้น) อย่างที่คุณอาจจินตนาการได้ ล่ามของเรามีหน้าที่ในการดำเนินการผ่าน AST ที่สร้างโดย parser ของเรา และนำชีวิตเข้าสู่โปรแกรม Stoffle ฉันพบว่าขั้นตอนสุดท้ายนี้เป็นขั้นตอนที่น่าตื่นเต้นที่สุดในการนำภาษาไปใช้ เมื่อสร้างล่าม ในที่สุดทุกอย่างก็คลิกเข้ามา และเราจะได้เห็นโปรแกรม Stoffle ทำงานจริง!
ฉันจะแสดงและอธิบายการใช้งานล่ามในสองส่วน ในส่วนแรกนี้ เราจะให้การทำงานพื้นฐาน:ตัวแปร เงื่อนไข ตัวดำเนินการยูนารีและไบนารี ชนิดข้อมูล และการพิมพ์ไปยังคอนโซล เรากำลังจองสิ่งที่มีเนื้อมากขึ้น (การกำหนดฟังก์ชัน การเรียกใช้ฟังก์ชัน การวนซ้ำ ฯลฯ) สำหรับโพสต์ที่สองและสุดท้ายเกี่ยวกับการใช้งานล่ามของเรา
สรุปย่อของ Lexer และ Parser
ก่อนที่เราจะลงลึกและเริ่มใช้งานล่าม เรามาเตือนตัวเองอย่างรวดเร็วว่าเราทำอะไรในโพสต์ก่อนหน้าของซีรีส์นี้ ขั้นแรก เราสร้าง lexer ซึ่งแปลงซอร์สโค้ดดิบเป็นโทเค็น จากนั้น เราใช้ parser ซึ่งเป็นองค์ประกอบที่รับผิดชอบในการเปลี่ยนโทเค็นให้เป็นโครงสร้างแบบต้นไม้ (AST) โดยสรุป นี่คือการเปลี่ยนแปลงที่เราสังเกตเห็น:
สถานะ 0:แหล่งที่มา
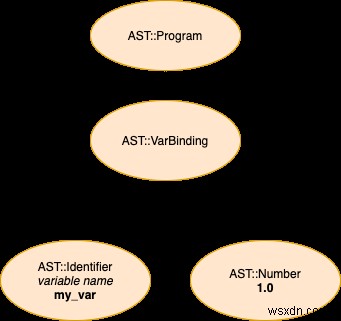
my_var = 1
สถานะ 1:Lexer แปลงซอร์สโค้ดดิบเป็นโทเค็น
[:identifier, :'=', :number]
สถานะ 2:Parser แปลงโทเค็นเป็นแผนผังไวยากรณ์นามธรรม
ทุกอย่างเกี่ยวกับการเดิน
ตอนนี้เรามี AST แล้ว งานของเราคือเขียนโค้ดเพื่อใช้โครงสร้างนี้ เราต้องเขียนโค้ด Ruby ที่สามารถให้ชีวิตกับสิ่งที่แต่ละโหนดใน AST อธิบายได้ หากเรามีโหนดที่อธิบายการเชื่อมโยงตัวแปร เช่น งานของเราคือการเขียนโค้ด Ruby ที่สามารถเก็บผลลัพธ์ทางด้านขวามือของนิพจน์การโยงตัวแปรของเราและเพื่อให้มีพื้นที่เก็บข้อมูลนี้สัมพันธ์กับ (และ เข้าถึงได้ผ่าน) ชื่อที่กำหนดให้กับตัวแปร
ดังที่เราทำในส่วนก่อนหน้าของชุดนี้ เราจะสำรวจการใช้งานโดยดำเนินการตามบรรทัดสำคัญของโค้ดที่เกี่ยวข้องในการจัดการโปรแกรมตัวอย่าง ส่วนของรหัส Stoffle ที่เราต้องตีความมีดังต่อไปนี้:
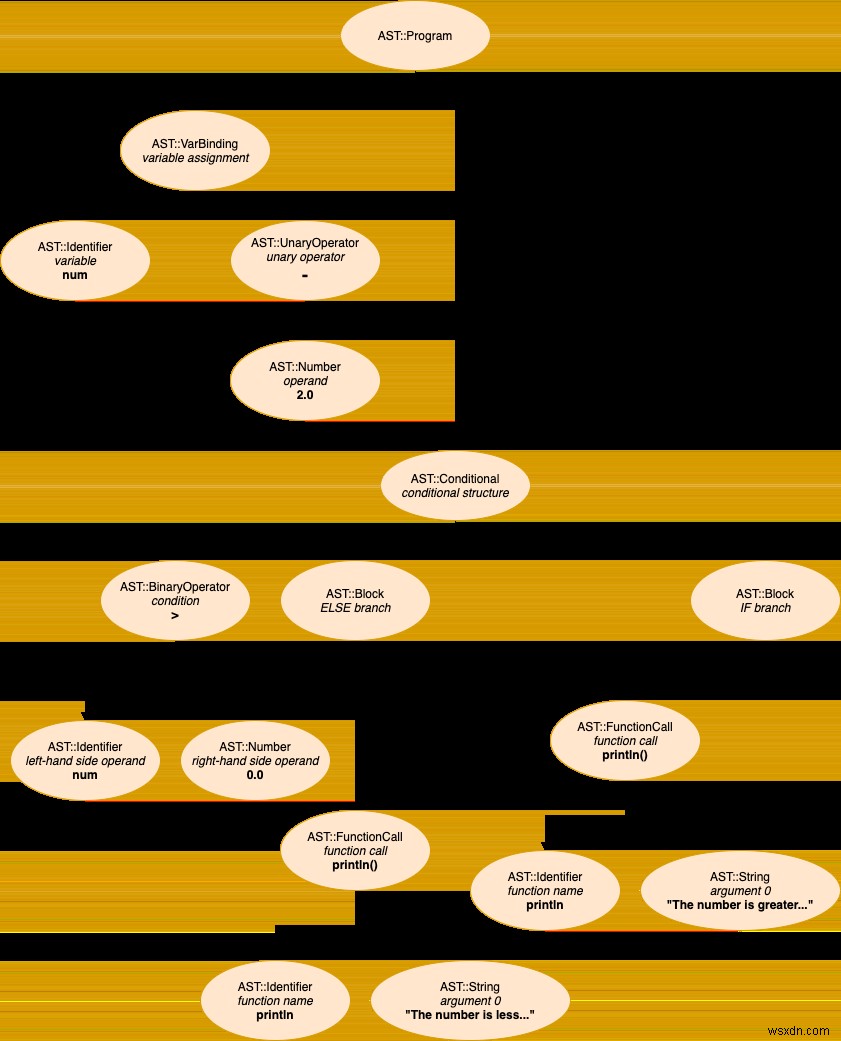
num = -2
if num > 0
println("The number is greater than zero.")
else
println("The number is less than or equal to zero.")
end
นี่คือ AST ที่สร้างขึ้นสำหรับโปรแกรมเดียวกัน:
ก้าวแรกในการเดินของเรา
อย่างที่คุณอาจจำได้จากโพสต์ล่าสุดในซีรีส์นี้ Stoffle AST จะมี AST::Program เป็นรูทเสมอ โหนด รูทนี้โดยทั่วไปมีลูกหลายคน บางส่วนจะตื้น (ลองนึกถึง AST ที่สร้างขึ้นสำหรับการกำหนดตัวแปรอย่างง่าย) เด็กคนอื่นๆ อาจเป็นรากของต้นไม้ย่อยที่ค่อนข้างลึก (ลองนึกถึงลูปที่มีเส้นหลายเส้นอยู่ภายในร่างกาย) นี่คือรหัส Ruby ที่เราต้องเริ่มดำเนินการผ่าน AST ที่ส่งผ่านไปยังล่ามของเรา:
module Stoffle
class Interpreter
attr_reader :program, :output, :env
def initialize
@output = []
@env = {}
end
def interpret(ast)
@program = ast
interpret_nodes(program.expressions)
end
private
def interpret_nodes(nodes)
last_value = nil
nodes.each do |node|
last_value = interpret_node(node)
end
last_value
end
def interpret_node(node)
interpreter_method = "interpret_#{node.type}"
send(interpreter_method, node)
end
#...
end
end
เมื่อ Interpreterใหม่ ถูกสร้างขึ้นทันทีตั้งแต่เริ่มต้น เราสร้างตัวแปรอินสแตนซ์สองตัว:@output และ @env . ความรับผิดชอบของอดีตคือการจัดเก็บทุกอย่างที่โปรแกรมของเราพิมพ์ออกมาตามลำดับเวลา การมีข้อมูลนี้อยู่ในมือมีประโยชน์มากเมื่อเขียนการทดสอบอัตโนมัติหรือการดีบัก ความรับผิดชอบของ @env แตกต่างกันเล็กน้อย เราตั้งชื่อมันว่าเป็นการอ้างอิงถึง "สิ่งแวดล้อม" ตามชื่อที่แนะนำ หน้าที่ของมันคือการรักษาสถานะของโปรแกรมที่ทำงานอยู่ของเรา หนึ่งในหน้าที่ของมันคือการนำการเชื่อมโยงระหว่างตัวระบุ (เช่น ชื่อตัวแปร) กับค่าปัจจุบัน
#interpret_nodes วิธีการวนซ้ำผ่านชายน์ทั้งหมดของโหนดรูท (AST::Program ). จากนั้นจะเรียก #interpret_node สำหรับแต่ละโหนด
#interpret_node เรียบง่ายแต่น่าสนใจ ที่นี่เราใช้ Ruby metaprogramming เล็กน้อยเพื่อเรียกวิธีการที่เหมาะสมในการจัดการประเภทโหนดที่อยู่ในมือ ตัวอย่างเช่น สำหรับ AST::VarBinding โหนด #interpret_var_binding วิธีการคือสิ่งที่ถูกเรียก
เราต้องพูดถึงตัวแปรอย่างสม่ำเสมอ
โหนดแรกที่เราต้องแปลใน AST ของโปรแกรมตัวอย่างที่เรากำลังดำเนินการคือ AST::VarBinding . มัน @left เป็น AST::Identifier และ @right . ของมัน เป็น AST::UnaryOperator . มาดูวิธีการที่รับผิดชอบในการตีความการโยงตัวแปรกัน:
def interpret_var_binding(var_binding)
env[var_binding.var_name_as_str] = interpret_node(var_binding.right)
end
อย่างที่คุณเห็น มันค่อนข้างตรงไปตรงมา เราเพิ่ม (หรือเขียนทับ) คู่คีย์-ค่าใน @env แฮช.
กุญแจสำคัญคือชื่อของตัวแปร (#var_name_as_str เป็นเพียงวิธีการช่วยเหลือที่เทียบเท่ากับ var_binding.left.name ). ในขณะนี้ ตัวแปรทั้งหมดเป็นสากล เราจะจัดการกับขอบเขตในโพสต์ถัดไป
ค่านี้เป็นผลจากการตีความนิพจน์ทางด้านขวามือของงานที่มอบหมาย ในการทำเช่นนั้น เราใช้ #interpret_node อีกครั้ง. เนื่องจากเรามี AST::UnaryOperator ทางด้านขวามือ วิธีถัดไปที่ถูกเรียกคือ #interpret_unary_operator :
def interpret_unary_operator(unary_op)
case unary_op.operator
when :'-'
-(interpret_node(unary_op.operand))
else # :'!'
!(interpret_node(unary_op.operand))
end
end
ความหมายของตัวดำเนินการเอกพจน์ที่รองรับของ Stoffle (- และ ! ) เหมือนกับใน Ruby ด้วยเหตุนี้ การใช้งานจึงไม่ง่ายไปกว่านี้:เราใช้ - ของ Ruby โอเปอเรเตอร์ต่อผลลัพธ์ของการตีความตัวถูกดำเนินการ ผู้ต้องสงสัยตามปกติ #interpret_node ปรากฏขึ้นอีกครั้งที่นี่ ตามที่คุณอาจจำได้จาก AST ของโปรแกรมของเรา ตัวถูกดำเนินการสำหรับ - เป็น AST::Number (เลข 2 ). ซึ่งหมายความว่าจุดต่อไปของเราคือ #interpret_number :
def interpret_number(number)
number.value
end
การใช้งาน #interpret_number เป็นเค้กชิ้นหนึ่ง การตัดสินใจของเราที่จะใช้ Ruby float เป็นการแสดงตัวเลข (สิ่งนี้เกิดขึ้นใน lexer!) จ่ายออกไปที่นี่ @value ของ AST::Number โหนดมีการแสดงตัวเลขภายในที่ต้องการอยู่แล้ว ดังนั้นเราจึงดึงมันมา
ด้วยเหตุนี้ เราจึงตีความลูกโดยตรงคนแรกของ AST::Program . ให้เสร็จ . เพื่อสรุปการแปลโปรแกรมของเรา เราต้องจัดการกับลูกอื่นที่มีขนดกมากขึ้น:โหนดประเภท AST::Conditional .
ข้อกำหนดและเงื่อนไขอาจมีผลบังคับใช้
ย้อนกลับไปใน #interpret_nodes , เพื่อนที่ดีที่สุดของเรา #interpret_node ถูกเรียกอีกครั้งเพื่อตีความลูกโดยตรงคนต่อไปของ AST::Program .
def interpret_nodes(nodes)
last_value = nil
nodes.each do |node|
last_value = interpret_node(node)
end
last_value
end
วิธีการที่รับผิดชอบในการตีความ AST::Conditional คือ #interpret_conditional . ก่อนที่เราจะดูมัน เรามารีเฟรชความทรงจำของเราโดยทบทวนการใช้งาน AST::Conditional ตัวเอง:
class Stoffle::AST::Conditional < Stoffle::AST::Expression
attr_accessor :condition, :when_true, :when_false
def initialize(cond_expr = nil, true_block = nil, false_block = nil)
@condition = cond_expr
@when_true = true_block
@when_false = false_block
end
def ==(other)
children == other&.children
end
def children
[condition, when_true, when_false]
end
end
โอเค งั้น @condition มีการแสดงออกที่จะเป็นจริงหรือเท็จ @when_true ถือบล็อกที่มีหนึ่งนิพจน์ขึ้นไปที่จะดำเนินการในกรณีที่ @condition เป็นความจริงและ @when_false (ELSE ข้อ) ถือบล็อกที่จะเรียกใช้ในกรณีที่ @condition เกิดขึ้นเป็นเท็จ
ทีนี้มาดูที่ #interpret_condition :
def interpret_conditional(conditional)
evaluated_cond = interpret_node(conditional.condition)
# We could implement the line below in a shorter way, but better to be explicit about truthiness in Stoffle.
if evaluated_cond == nil || evaluated_cond == false
return nil if conditional.when_false.nil?
interpret_nodes(conditional.when_false.expressions)
else
interpret_nodes(conditional.when_true.expressions)
end
end
ความจริงใน Stoffle เหมือนกับใน Ruby กล่าวอีกนัยหนึ่ง ใน Stoffle มีเพียง nil และ false เป็นเท็จ อินพุตอื่นใดของเงื่อนไขเป็นความจริง
ขั้นแรก เราประเมินเงื่อนไขโดยการตีความนิพจน์ที่ถือโดย conditional.condition . มาดู AST ของโปรแกรมของเราอีกครั้งเพื่อดูว่าเรากำลังจัดการกับโหนดใด:
ปรากฎว่าเรามี AST::BinaryOperator (> ใช้ใน num > 0 ). โอเค มันเป็นเส้นทางเดิมอีกครั้ง:first #interpret_node ซึ่งเรียก #interpret_binary_operator ครั้งนี้:
def interpret_binary_operator(binary_op)
case binary_op.operator
when :and
interpret_node(binary_op.left) && interpret_node(binary_op.right)
when :or
interpret_node(binary_op.left) || interpret_node(binary_op.right)
else
interpret_node(binary_op.left).send(binary_op.operator, interpret_node(binary_op.right))
end
end
ตัวดำเนินการเชิงตรรกะของเรา (and และ or ) ถือได้ว่าเป็นตัวดำเนินการไบนารี ดังนั้นเราจึงจัดการพวกมันที่นี่เช่นกัน เนื่องจากความหมายของมันเทียบเท่ากับ && . ของ Ruby และ || , การใช้งานเป็นแบบแล่นเรือธรรมดาอย่างที่คุณเห็นด้านบน
ต่อไปเป็นส่วนของวิธีการที่เราสนใจมากที่สุด ส่วนนี้จัดการตัวดำเนินการไบนารีอื่นๆ ทั้งหมด (รวมถึง > ). ที่นี่ เราสามารถใช้ประโยชน์จากไดนามิกของ Ruby เพื่อประโยชน์ของเราและคิดวิธีแก้ปัญหาที่รัดกุม ใน Ruby มีตัวดำเนินการไบนารีเป็นเมธอดในออบเจ็กต์ที่เข้าร่วมในการดำเนินการ:
-2 > 0 # is equivalent to
-2.send(:'>', 0) # this
# and the following line would be a general solution,
# very similar to what we have in the interpreter
operand_1.send(binary_operator, operand_2)
การใช้งานแบบละเอียดของโอเปอเรเตอร์ไบนารี
อย่างที่คุณเห็น การใช้งานตัวดำเนินการไบนารีของเรานั้นกระชับมาก หาก Ruby ไม่ใช่ภาษาแบบไดนามิก หรือความหมายของโอเปอเรเตอร์ระหว่าง Ruby และ Stoffle ต่างกัน เราก็ไม่สามารถเขียนโค้ดโซลูชันในลักษณะนี้ได้
หากคุณเคยพบว่าตัวเองอยู่ในตำแหน่งเช่นนักออกแบบ/ผู้ปรับใช้ภาษา คุณสามารถถอยกลับไปใช้โซลูชันที่เรียบง่าย (แต่ไม่หรูหรานั้น) ได้เสมอ:โดยใช้โครงสร้างสวิตช์ ในกรณีของเรา การใช้งานจะมีลักษณะดังนี้:
# ... inside #interpret_binary_operator ... case binary_op.operator when :'+' interpret_node(binary_op.left) + interpret_node(binary_op.right) # ... other operators end
ก่อนจะกลับไปที่ #interpret_conditional , ลองอ้อมไปอย่างรวดเร็วเพื่อให้แน่ใจว่าไม่มีอะไรถูกมองข้าม หากคุณจำโปรแกรมที่เรากำลังตีความได้ num ตัวแปรถูกใช้ในการเปรียบเทียบ (โดยใช้ตัวดำเนินการไบนารี > ) เราเพิ่งสำรวจด้วยกัน เราดึงตัวถูกดำเนินการทางซ้ายได้อย่างไร (เช่น ค่าที่เก็บไว้ใน num ตัวแปร) ของการเปรียบเทียบนั้น? เมธอดที่รับผิดชอบคือ #interpret_identifier และการใช้งานนั้นง่าย:
def interpret_identifier(identifier)
if env.has_key?(identifier.name)
env[identifier.name]
else
# Undefined variable.
raise Stoffle::Error::Runtime::UndefinedVariable.new(identifier.name)
end
end
กลับไปที่ #interpret_conditional . ในกรณีของโปรแกรมเล็กๆ ของเรา เงื่อนไขจะถูกประเมินเป็น Ruby false ค่า. เราใช้ค่านี้เพื่อกำหนดว่าเราต้องดำเนินการ IF หรือสาขา ELSE ของโครงสร้างตามเงื่อนไข เราดำเนินการตีความสาขา ELSE ซึ่งบล็อกรหัสที่เกี่ยวข้องถูกเก็บไว้ใน conditional.when_false . เรามี AST::Block ซึ่งคล้ายกับรูทโหนดของ AST ของเรามาก (AST::Program ). บล็อกเช่นเดียวกันอาจมีนิพจน์จำนวนมากที่ต้องตีความ เพื่อจุดประสงค์นี้ เรายังใช้ #interpret_nodes .
def interpret_conditional(conditional)
evaluated_cond = interpret_node(conditional.condition)
# We could implement the line below in a shorter way, but better to be explicit about truthiness in Stoffle.
if evaluated_cond == nil || evaluated_cond == false
return nil if conditional.when_false.nil?
interpret_nodes(conditional.when_false.expressions)
else
interpret_nodes(conditional.when_true.expressions)
end
end
โหนด AST ถัดไปที่เราต้องจัดการคือ AST::FunctionCall . เมธอดที่ทำหน้าที่ตีความการเรียกใช้ฟังก์ชันคือ #interpret_function_call :
def interpret_function_call(fn_call)
return if println(fn_call)
end
ดังที่เราได้พูดคุยกันในตอนต้นของบทความ คำจำกัดความของฟังก์ชันและการเรียกใช้ฟังก์ชันจะกล่าวถึงในโพสต์ถัดไปในชุดนี้ ดังนั้นเราจึงใช้เฉพาะกรณีพิเศษของการเรียกใช้ฟังก์ชันเท่านั้น ในภาษาของเล่นเล็ก ๆ ของเรา เรามี println เป็นส่วนหนึ่งของรันไทม์และนำไปใช้โดยตรงในล่ามที่นี่ เป็นทางออกที่ดีเมื่อพิจารณาถึงวัตถุประสงค์และขอบเขตของโครงการ
def println(fn_call)
return false if fn_call.function_name_as_str != 'println'
result = interpret_node(fn_call.args.first).to_s
output << result
puts result
true
end
อาร์กิวเมนต์แรกและตัวเดียวของ AST::FunctionCall . ของเรา เป็น AST::String ซึ่งจัดการโดย #interpret_string :
def interpret_string(string)
string.value
end
ใน #interpret_string เรามีกรณีเดียวกันกับ #interpret_number . AST::String มีค่าสตริง Ruby ที่พร้อมใช้งานอยู่แล้ว ดังนั้นเราจึงต้องดึงมันกลับมา
กลับไปที่ #println :
def println(fn_call)
return false if fn_call.function_name_as_str != 'println'
result = interpret_node(fn_call.args.first).to_s
output << result
puts result
true
end
หลังจากจัดเก็บอาร์กิวเมนต์ของฟังก์ชัน (แปลงเป็นสตริง Ruby) ใน result เรามีอีกสองขั้นตอนที่ต้องทำให้เสร็จ ขั้นแรก เราเก็บสิ่งที่เรากำลังจะพิมพ์ไปยังคอนโซลใน @output . ตามที่ได้อธิบายไว้ก่อนหน้านี้ แนวคิดในที่นี้คือการตรวจสอบสิ่งที่พิมพ์ออกมาได้อย่างง่ายดาย (และในลำดับใด) การมีสิ่งนี้อยู่ในมือทำให้ชีวิตของเราง่ายขึ้นเมื่อทำการดีบั๊กหรือทดสอบล่าม สุดท้าย ในการดำเนินการพิมพ์บางอย่างไปยังคอนโซล เราใช้ puts . ของ Ruby .
เรื่องการดำเนินการ
ตอนนี้เราได้สำรวจทุกสิ่งที่จำเป็นในการปรับใช้ส่วนเปล่าของ Stoffle แล้ว มาสร้างไฟล์สั่งการขั้นพื้นฐานเพื่อดูการทำงานของล่าม
#!/usr/bin/env ruby
require_relative '../lib/stoffle'
path = ARGV[0]
source = File.read(path)
lexer = Stoffle::Lexer.new(source)
parser = Stoffle::Parser.new(lexer.start_tokenization)
interpreter = Stoffle::Interpreter.new
interpreter.interpret(parser.parse)
exit(0)
เคล็ดลับ: หากต้องการใช้ล่ามของ Stoffle จากทุกที่ อย่าลืมเพิ่มไฟล์ปฏิบัติการลงใน PATH ของคุณ
ในที่สุดก็ถึงเวลาเรียกใช้โปรแกรมของเรา หากทุกอย่างทำงานได้ดี เราควรเห็นสตริง "ตัวเลขน้อยกว่าหรือเท่ากับศูนย์" พิมพ์ลงในคอนโซล นี่คือสิ่งที่เกิดขึ้นเมื่อเราเรียกใช้ล่าม:

เคล็ดลับ: หากคุณได้ติดตั้งล่ามไว้ ให้ลองเปลี่ยน
numตัวแปรในโปรแกรมตัวอย่างของเราเพื่อให้มีค่ามากกว่าศูนย์ ตามที่คาดไว้ ตอนนี้สาขา IF จะถูกดำเนินการ และสตริง "The number is more than zero" จะถูกพิมพ์ออกมา
สรุปผล
ในโพสต์นี้ เราเห็นจุดเริ่มต้นของล่ามของ Stoffle เราใช้ล่ามเพียงพอสำหรับจัดการกับพื้นฐานภาษาบางอย่าง:ตัวแปร เงื่อนไข ตัวดำเนินการ unary และไบนารี ชนิดข้อมูล และการพิมพ์ไปยังคอนโซล ในส่วนถัดไปและสุดท้ายในล่าม เราจะจัดการกับบิตที่เหลือที่จำเป็นสำหรับเราเพื่อให้ภาษาของเล่นเล็กๆ ของเราทำงานตามที่ออกแบบไว้:การกำหนดขอบเขตตัวแปร การกำหนดฟังก์ชัน การเรียกใช้ฟังก์ชัน และการวนซ้ำ ฉันหวังว่าคุณจะสนุกกับการอ่านบทความ (ฉันสนุกกับการเขียนมันอย่างแน่นอน!) แล้วพบกันใหม่ในโพสต์ถัดไปในซีรีส์นี้!
