
โครงสร้างข้อมูลคืออะไร
โครงสร้างข้อมูลเป็นวิธีเฉพาะในการจัดระเบียบและเข้าถึงข้อมูล .
ตัวอย่าง ได้แก่:
- อาร์เรย์
- ต้นไม้ไบนารี
- แฮช
โครงสร้างข้อมูลที่แตกต่างกันทำงานที่แตกต่างกัน
ตัวอย่างเช่น แฮชจะดีมาก หากคุณต้องการจัดเก็บข้อมูลที่ดูเหมือนพจนานุกรม (คำ &คำจำกัดความ) หรือสมุดโทรศัพท์ (ชื่อและหมายเลขของบุคคล)
รู้ว่ามีโครงสร้างข้อมูลใดบ้าง , และ ลักษณะของแต่ละคน จะทำให้คุณเป็นนักพัฒนา Ruby ที่ดีขึ้น
นั่นคือสิ่งที่คุณจะได้เรียนรู้ในบทความนี้!
ทำความเข้าใจอาร์เรย์
อาร์เรย์คือโครงสร้างข้อมูลแรกที่คุณเรียนรู้เมื่อคุณเริ่มอ่านเกี่ยวกับการเขียนโปรแกรม
อาร์เรย์ใช้หน่วยความจำที่ต่อเนื่องกันซึ่งวัตถุจะถูกเก็บไว้ทีละรายการโดยไม่มีช่องว่างระหว่างกัน
ไม่เหมือนกับภาษาโปรแกรมระดับล่างเช่น C Ruby ทำงานอย่างหนักในการจัดการหน่วยความจำของคุณ ขยายขนาดอาร์เรย์สูงสุดและกระชับเมื่อคุณลบองค์ประกอบ
การใช้งาน :
- เป็นฐานสำหรับโครงสร้างข้อมูลขั้นสูง
- เพื่อรวบรวมผลลัพธ์จากการวนซ้ำ
- รวบรวมไอเทม
คุณจะพบอาร์เรย์ได้ทุกที่ เช่น split &chars เมธอด ซึ่งแบ่งสตริงออกเป็นอาร์เรย์ของอักขระ
ตัวอย่าง :
out = []
10.times { |i| out << i }
out
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
ตารางต่อไปนี้แสดงให้เห็นว่าการทำงานของอาร์เรย์ต่างๆ ทำงานอย่างไรเมื่อขนาดของอาร์เรย์เพิ่มขึ้น
หากคุณไม่คุ้นเคยกับสัญลักษณ์ความซับซ้อนของเวลา โปรดอ่านบทความนี้
ความซับซ้อนของเวลาสำหรับอาร์เรย์ :
| การทำงาน | ความซับซ้อน |
|---|---|
| ดัน | O(1) |
| ป๊อป | O(1) |
| การเข้าถึง | O(1) |
| ค้นหา | O(n) |
| ลบ | O(n) |
เหตุใดจึงมีประโยชน์
เพราะจะบอกลักษณะการทำงานของอาร์เรย์
หากคุณกำลังทำ find . มาก การทำงานบนอาร์เรย์ขนาดใหญ่ที่จะช้า...
แต่ถ้าคุณรู้ว่าจะใช้ดัชนีอะไร อาร์เรย์ก็จะเร็วเพราะ O(1) ความซับซ้อนของเวลา
เลือกโครงสร้างข้อมูลของคุณด้วยเกณฑ์นี้ :
- คุณลักษณะด้านประสิทธิภาพ => คุณกำลังทำอะไรกับข้อมูล? ชุดข้อมูลของคุณใหญ่แค่ไหน
- รูปร่างและรูปแบบของข้อมูลของคุณ => คุณทำงานกับข้อมูลประเภทใด? คุณช่วยจัดระเบียบข้อมูลใหม่เพื่อให้เข้ากับโครงสร้างข้อมูลที่ดีขึ้นได้ไหม
โครงสร้างข้อมูลแฮช
คุณมีแผนที่ระหว่างรหัสประเทศและชื่อประเทศหรือไม่
หรือบางทีคุณแค่ต้องการนับสิ่งของ
นั่นคือสิ่งที่มีประโยชน์สำหรับแฮช!
แฮชคือโครงสร้างข้อมูลที่ทุกค่ามีคีย์ &คีย์นี้สามารถเป็นอะไรก็ได้ เช่น สตริง จำนวนเต็ม สัญลักษณ์ เป็นต้น
ทำงานอย่างไร
แฮชแปลงคีย์ของคุณเป็นตัวเลข (โดยใช้ hash วิธีใน Ruby) แล้วใช้ตัวเลขนั้นเป็นดัชนี แต่คุณไม่จำเป็นต้องเข้าใจว่าจะใช้แฮชในโปรแกรม Ruby ได้
การใช้งาน :
- การนับอักขระในสตริง
- การจับคู่คำกับคำจำกัดความ ชื่อกับหมายเลขโทรศัพท์ ฯลฯ
- ค้นหารายการที่ซ้ำกันภายในอาร์เรย์
ตัวอย่าง :
"aaabcd"
.each_char
.with_object(Hash.new(0)) { |ch, hash| hash[ch] += 1 }
# {"a"=>3, "b"=>1, "c"=>1, "d"=>1}
ความซับซ้อนของเวลา :
| การทำงาน | ความซับซ้อน |
|---|---|
| ร้านค้า | O(1) |
| การเข้าถึง | O(1) |
| ลบ | O(1) |
| ค้นหา (ค่า) | O(n) |
แฮชเป็นหนึ่งในโครงสร้างข้อมูลที่มีประโยชน์ที่สุดเมื่อพูดถึงประสิทธิภาพ เนื่องจากค่าคงที่ O(1) จัดเก็บ ลบ และเข้าถึงเวลา
ค้นหาในบริบทของแฮชหมายความว่าคุณกำลังมองหาค่าเฉพาะ
กอง
กองเป็นเหมือนกองของจาน คุณวางจานหนึ่งทับอีกจานหนึ่ง &คุณสามารถเอาจานที่อยู่ด้านบนออกเท่านั้น
สิ่งนี้มีประโยชน์มากกว่าเสียงในตอนแรก!
การใช้งาน :
- แทนที่เมธอดแบบเรียกซ้ำด้วยลูปปกติ
- ติดตามงานที่เหลือโดยปล่อยให้งานล่าสุดอยู่ด้านบน
- ย้อนกลับอาร์เรย์
ตัวอย่าง :
stack = [1,2,3,4,5]
(1..stack.size).map { stack.pop }
# [5, 4, 3, 2, 1]
ได้ คุณสามารถใช้ reverse แทน
นี่เป็นเพียงตัวอย่างเพื่อแสดงคุณลักษณะเฉพาะของสแต็ค
ความซับซ้อนของเวลา :
| การทำงาน | ความซับซ้อน |
|---|---|
| ดัน | O(1) |
| ป๊อป | O(1) |
| ค้นหา | --- |
| การเข้าถึง | --- |
ขอให้สังเกตว่าสแต็ก (และคิว) มีเพียงสองการดำเนินการ insert &delete , หรือ push &pop .
แม้ว่าจะสามารถค้นหาภายในสแต็กได้ แต่ก็หายากมาก
วิธีใช้ต้นไม้ไบนารี
นักพัฒนา Ruby ส่วนใหญ่คงเคยได้ยินเกี่ยวกับไบนารีทรีแต่ไม่เคยใช้เลย
ทำไมล่ะ
ก่อนอื่น เราไม่มีการนำไบนารีทรีมาใช้งาน
อย่างที่สอง ต้นไม้ไบนารีไม่เป็นประโยชน์สำหรับความท้าทายในการเขียนโปรแกรมทุกวัน ซึ่งต่างจากอาร์เรย์และแฮชที่คุณใช้ตลอดเวลา
แต่ไบนารีทรีเป็นโครงสร้างข้อมูลที่น่าสนใจมาก .
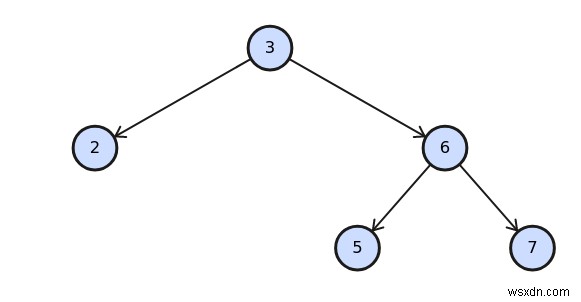
อันที่จริง มีหลายรูปแบบ เช่น Trie (ครอบคลุมในหัวข้อถัดไป) แผนผังหลายทาง เช่น B-Tree (ใช้ในฐานข้อมูล) และ Heap
การใช้งาน :
- การบีบอัดข้อมูล
- ตารางเส้นทาง
- ต้นไม้ไวยากรณ์นามธรรม (AST)
ตัวอย่าง :
# https://github.com/jamesconant/bstree require 'bstree' root = Bstree::Node.new(5) root.insert(2) root.insert(7) root.search(3) # nil
ความซับซ้อนของเวลา :
| การทำงาน | ความซับซ้อน |
|---|---|
| แทรก | O(log n) |
| ลบ | O(log n) |
| ค้นหา | O(log n) |
| การเข้าถึง | --- |
ต้นไม้ไบนารีที่สมดุลคือเมื่อโหนดทั้งหมดมีลูกสองคนและใบไม้ทั้งหมดมีระดับเท่ากัน
หากต้นไม้ไม่สมดุล ประสิทธิภาพจะลดลงเป็น O(n) .
ใน ต้นไม้ไบนารีที่สมดุลในตัวเอง (เช่น ต้นไม้สีแดง-ดำ หรือต้นไม้ AVL) ทุกการดำเนินการจะใช้เวลาตามสัดส่วนกับความสูง (หรือระดับ) ของต้นไม้
สังเกตว่าไม่มีเวลาเข้าถึงเพราะการเข้าถึงโหนดคุณต้องค้นหามันก่อน...
ในกรณีนี้ คุณจะมี O(log n) สำหรับการเข้าถึง
แต่ถ้าเก็บการอ้างอิง (เป็นตัวแปร) ไปยังโหนดเฉพาะ นั่นก็คือ O(1) เวลาเข้าใช้งาน
โครงสร้างข้อมูล Trie
การทดลองเป็นโครงสร้างข้อมูลแบบต้นไม้พิเศษ
การทำงานกับคำนั้นมีประโยชน์ จากนั้นจึงค้นหาคำที่ขึ้นต้นด้วยคำนำหน้าอย่างรวดเร็ว หรือค้นหาทั้งคำอย่างรวดเร็ว
การใช้งาน :
- เกมคำศัพท์
- ตัวตรวจสอบการสะกด
- คำแนะนำในการเติมข้อความอัตโนมัติ
ตัวอย่าง :
# https://github.com/gonzedge/rambling-trie
require 'rambling-trie'
trie = Rambling::Trie.create('words.txt')
trie.include?('chocolate')
# true
trie.include?('salmon')
# true
ความซับซ้อนของเวลา :
| การทำงาน | ความซับซ้อน |
|---|---|
| เพิ่ม | O(k) |
| รวมหรือไม่ | O(k) |
| คำ | O(k) |
ในตารางนี้ ฉันใช้ k เพื่อแสดงขนาดของสตริงอินพุต ในขณะที่ n ใช้เพื่อระบุขนาดของโครงสร้างข้อมูลเอง
ดังนั้นสำหรับคำว่า apple , k จะเท่ากับ 5.
สรุป
คุณได้เรียนรู้เกี่ยวกับโครงสร้างข้อมูลทั่วไป การใช้งานและคุณลักษณะหลัก และวิธีใช้ใน Ruby
เมื่อคุณใช้ความรู้ใหม่นี้ คุณจะสามารถแก้ปัญหาได้เร็วยิ่งขึ้น!
คุณช่วยแชร์โพสต์นี้ให้ฉันได้ไหมหากพบว่ามีประโยชน์
ขอบคุณค่ะ 🙂
