
ความซับซ้อนของเวลาเป็นหนึ่งในแนวคิดที่น่าสนใจที่สุดที่คุณสามารถเรียนรู้จากวิทยาการคอมพิวเตอร์ และคุณไม่จำเป็นต้องมีปริญญาเพื่อทำความเข้าใจมัน!
เป็นเรื่องที่น่าสนใจเพราะช่วยให้คุณเห็นทำไมอัลกอริทึมหรือโปรแกรมบางอย่างจึงอาจทำงานช้า และสิ่งที่คุณทำได้เพื่อให้เร็วขึ้น
คุณสามารถใช้สิ่งนี้กับรหัสของคุณเองได้
สิ่งนี้เหนือกว่าอัลกอริธึมแฟนซีทั้งหมด ที่คุณพบในหนังสือวิทยาการคอมพิวเตอร์ ดังที่ฉันจะสาธิตให้คุณเห็นในบทความนี้
แต่ก่อนอื่นเราต้องพูดถึงสิ่งที่ช้าและเร็ว
ช้าเทียบกับเร็ว
การเรียงลำดับ 1 ล้านตัวเลขใน 150ms (มิลลิวินาที) ช้าหรือเร็วหรือไม่
ฉันคิดว่ามันค่อนข้างเร็ว แต่นี่ไม่ใช่คำถามที่ความซับซ้อนของเวลาพยายามจะตอบ
เราต้องการทราบว่าอัลกอริธึมทำงานอย่างไรเมื่อ "ขนาดอินพุต" เพิ่มขึ้น
เมื่อเราพูดถึง "ขนาดอินพุต" เรากำลังพูดถึงอาร์กิวเมนต์สำหรับฟังก์ชันหรือเมธอด หากเมธอดรับสตริงหนึ่งสตริงเป็นอาร์กิวเมนต์ นั่นคืออินพุต และความยาวของสตริงคือขนาดอินพุต
สัญลักษณ์บิ๊กโอ
ด้วยสัญกรณ์ Big O เราสามารถจำแนกอัลกอริทึมตามประสิทธิภาพได้
ดูเหมือนว่านี้:
O(1)
ในกรณีนี้ O(1) แสดงถึงอัลกอริธึม "เวลาคงที่"
ซึ่งหมายความว่าอัลกอริธึมจะใช้เวลาเท่าเดิมในการทำงานให้เสร็จ โดยไม่คำนึงว่าจะต้องทำงานมากน้อยเพียงใด
อีกอย่างคือ “เวลาเชิงเส้น”:
O(n)
โดยที่ “n” แทนขนาดของอินพุต (ขนาดสตริง ขนาดอาร์เรย์ ฯลฯ) ซึ่งหมายความว่าอัลกอริทึมจะทำงานให้เสร็จในอัตราส่วน 1:1 กับขนาดอินพุต ดังนั้นการเพิ่มขนาดอินพุตเป็นสองเท่าจะเพิ่มเวลาในการทำงานให้เสร็จเป็นสองเท่า
นี่คือตาราง :
| สัญลักษณ์ | ชื่อ | คำอธิบาย |
|---|---|---|
| O(1) | คงที่ | ใช้เวลาเท่ากันเสมอ |
| O(log n) | ลอการิทึม | จำนวนงานหารด้วย 2 หลังจากการวนซ้ำทุกอัน (การค้นหาแบบไบนารี) |
| O(n) | เชิงเส้น | เวลาทำงานให้เสร็จเพิ่มขึ้นในความสัมพันธ์แบบ 1 ต่อ 1 กับขนาดอินพุต |
| O(n บันทึก n) | เชิงเส้น | นี่คือการวนซ้ำซ้อน โดยที่วงในทำงานใน log n เวลา. ตัวอย่าง ได้แก่ quicksort, mergesort &heapsort |
| O(n^2) | กำลังสอง | เวลาทำงานให้เสร็จเพิ่มขึ้นใน input size ^ 2 ความสัมพันธ์ คุณสามารถรับรู้สิ่งนี้ได้ทุกเมื่อที่คุณมีลูปที่ข้ามองค์ประกอบทั้งหมด &การวนซ้ำทุกครั้งของลูปยังครอบคลุมทุกองค์ประกอบด้วย คุณมีลูปที่ซ้อนกัน |
| O(n^3) | ลูกบาศก์ | เหมือนกับ n^2 แต่เวลาเพิ่มขึ้นใน n^3 สัมพันธ์กับขนาดอินพุต มองหาลูปที่ซ้อนกันสามชั้นเพื่อจดจำสิ่งนี้ |
| O(2^n) | เอกซ์โพเนนเชียล | เวลาทำงานให้เสร็จเพิ่มขึ้นใน 2 ^ input size ความสัมพันธ์ ช้ากว่า n^2 . มาก ดังนั้นอย่าสับสน! ตัวอย่างหนึ่งคืออัลกอริทึมฟีโบนักชีแบบเรียกซ้ำ |
การวิเคราะห์อัลกอริทึม
คุณสามารถเริ่มพัฒนาสัญชาตญาณสำหรับสิ่งนี้ได้หากคุณคิดว่าอินพุตเป็นอาร์เรย์ขององค์ประกอบ “n”
ลองนึกภาพว่าคุณต้องการหาองค์ประกอบทั้งหมดที่เป็นเลขคู่ วิธีเดียวที่จะทำได้คืออ่านทุกองค์ประกอบหนึ่งครั้งเพื่อดูว่าตรงกับเงื่อนไขหรือไม่
[1,2,3,4,5,6,7,8,9,10].select(&:even?)
คุณไม่สามารถข้ามตัวเลขได้ เนื่องจากคุณอาจพลาดตัวเลขบางตัวที่กำลังมองหา จึงทำให้เป็นอัลกอริธึมเวลาเชิงเส้น O(n) .
3 วิธีแก้ปัญหาที่แตกต่างกันสำหรับปัญหาเดียวกัน
การวิเคราะห์ตัวอย่างแต่ละรายการเป็นเรื่องที่น่าสนใจ แต่สิ่งที่ช่วยให้เข้าใจแนวคิดนี้ได้จริงๆ ก็คือการดูว่าเราจะแก้ปัญหาเดียวกันได้อย่างไรโดยใช้วิธีแก้ปัญหาที่แตกต่างกัน
เราจะสำรวจตัวอย่างโค้ด 3 ตัวอย่างสำหรับตัวตรวจสอบโซลูชัน Scrabble
Scrabble เป็นเกมที่ให้รายชื่อตัวละคร (เช่น ollhe ) ขอให้คุณสร้างคำ (เช่น hello ) โดยใช้อักขระเหล่านี้
นี่คือวิธีแก้ปัญหาแรก :
def scramble(characters, word)
word.each_char.all? { |c| characters.count(c) >= word.count(c) }
end
คุณรู้หรือไม่ว่าความซับซ้อนของเวลาของรหัสนี้คืออะไร? กุญแจอยู่ใน count วิธีการ ดังนั้นให้แน่ใจว่าคุณเข้าใจว่าวิธีการนั้นทำอะไร
คำตอบคือ:O(n^2) .
และเหตุผลก็คือด้วย each_char เราจะดูอักขระทั้งหมดในสตริง word . เพียงอย่างเดียวก็จะเป็นอัลกอริธึมเวลาเชิงเส้น O(n) แต่ภายในบล็อคเรามี count วิธีการ
วิธีนี้เป็นการวนซ้ำอย่างมีประสิทธิภาพซึ่งจะข้ามอักขระทั้งหมดในสตริงอีกครั้งเพื่อนับ
แนวทางที่สอง
ได้เลย
เราจะทำอย่างไรให้ดีขึ้น? มีวิธีช่วยให้เราวนซ้ำได้ไหม
แทนที่จะนับอักขระที่เราสามารถลบออกได้ ด้วยวิธีนี้เราจะมีอักขระที่ต้องอ่านน้อยลง
นี่คือวิธีที่สอง :
def scramble(characters, word)
characters = characters.dup
word.each_char.all? { |c| characters.sub!(c, "") }
end
อันนี้น่าสนใจกว่านิดหน่อย ซึ่งจะเร็วกว่า count . มาก ในกรณีที่ดีที่สุด โดยที่อักขระที่เรากำลังมองหานั้นอยู่ใกล้จุดเริ่มต้นของสตริง
แต่เมื่ออักขระอยู่ท้ายสุด จะพบใน word . ในลำดับที่กลับกัน , ประสิทธิภาพจะเหมือนกับของ count ดังนั้นเราสามารถพูดได้ว่านี่ยังเป็น O(n^2) อัลกอริทึม
เราไม่ต้องกังวลในกรณีที่ไม่มีอักขระใน word ได้เพราะว่า all? เมธอดจะหยุดทันทีที่ sub! ส่งกลับ false . แต่คุณจะรู้สิ่งนี้ก็ต่อเมื่อคุณได้ศึกษา Ruby อย่างละเอียดถี่ถ้วน มากกว่าที่หลักสูตร Ruby ทั่วไปเสนอให้คุณ
มาลองใช้วิธีอื่นกันเถอะ
เกิดอะไรขึ้นถ้าเราลบการวนซ้ำแบบใดแบบหนึ่งในบล็อก เราสามารถทำได้ด้วยแฮช
def scramble(characters, word)
available = Hash.new(1)
characters.each_char { |c| available[c] += 1 }
word.each_char.all? { |c| available[c] -= 1; available[c] > 0 }
end
การอ่านและเขียนค่าแฮชคือ O(1) ซึ่งหมายความว่ามันค่อนข้างเร็ว โดยเฉพาะเมื่อเทียบกับการวนซ้ำ
เรายังมีสองลูป :
อันหนึ่งเพื่อสร้างตารางแฮช และอีกอันหนึ่งสำหรับตรวจสอบ เนื่องจากลูปเหล่านี้ไม่ได้ซ้อนกัน นี่คือ O(n) อัลกอริทึม
หากเราเปรียบเทียบโซลูชัน 3 อย่างนี้ เราจะเห็นว่าการวิเคราะห์ของเราตรงกับผลลัพธ์:
hash 1.216667 0.000000 1.216667 ( 1.216007) sub 6.240000 1.023333 7.263333 ( 7.268173) count 222.866644 0.073333 222.939977 (223.440862)
นี่คือแผนภูมิเส้น:
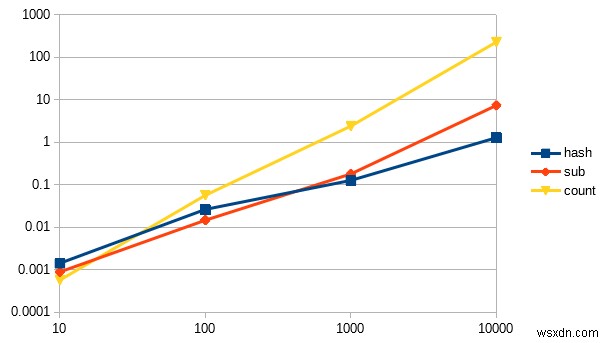
สังเกตบางสิ่ง :
- แกน Y (แนวตั้ง) แสดงถึงจำนวนวินาทีที่ใช้ในการทำงานให้เสร็จ ในขณะที่แกน X (แนวนอน) แสดงถึงขนาดอินพุต
- นี่คือแผนภูมิลอการิทึมซึ่งบีบอัดค่าในช่วงที่กำหนด แต่ในความเป็นจริง
countเส้นจะชันกว่ามาก - เหตุผลที่ฉันสร้างแผนภูมิลอการิทึมนี้คือเพื่อให้คุณได้ชื่นชมเอฟเฟกต์ที่น่าสนใจ โดยมีขนาดอินพุตที่เล็กมาก
countเร็วกว่าจริงๆ!
สรุป
คุณได้เรียนรู้เกี่ยวกับความซับซ้อนของเวลาอัลกอริทึม สัญกรณ์ O ขนาดใหญ่ และการวิเคราะห์ความซับซ้อนของเวลา คุณยังได้เห็นตัวอย่างบางส่วนที่เราเปรียบเทียบวิธีแก้ปัญหาต่างๆ กับปัญหาเดียวกันและวิเคราะห์ประสิทธิภาพด้วย
หวังว่าคุณจะได้เรียนรู้สิ่งใหม่และน่าสนใจ!
หากคุณได้โปรดแชร์โพสต์นี้บนโซเชียลมีเดียและสมัครรับจดหมายข่าวหากคุณยังไม่ได้ส่งเนื้อหาแบบนี้ให้คุณ
ขอบคุณสำหรับการอ่าน
