
ความสวยงามอย่างหนึ่งของเฟรมเวิร์ก Rails คือความสามารถในการใช้การเชื่อมโยง Ruby on Rails ในโมเดลของคุณ การเชื่อมโยงเหล่านี้ช่วยให้คุณเข้าถึงคอลเลกชันของบันทึกในโค้ดของคุณด้วยรูปแบบไวยากรณ์ที่น่าพอใจ ซึ่งช่วยลดความจำเป็นในการเขียนคำสั่ง SQL พื้นฐาน สิ่งที่เป็นนามธรรมนั้นจะคงอยู่ตราบเท่าที่ข้อมูลทั้งหมดของคุณอยู่ในที่เดียว ทันทีที่ตารางของคุณกระจายไปยังคลัสเตอร์ฐานข้อมูลที่แยกจากกัน การเชื่อมโยงบางประเภทจะหยุดทำงาน
บทความนี้จะอธิบายอย่างละเอียดว่าขอบเขตนั้นอยู่ที่ไหนและสิ่งที่ Rails มอบให้ในการทำงานภายในนั้น เราเริ่มต้นด้วยสาเหตุที่เกิดปัญหาและความสัมพันธ์ใดใน Rails ที่ได้รับผลกระทบ และย้ายไปยังการกำหนดค่าฐานข้อมูลและลำดับชั้นแบบจำลองที่รองรับหลายคลัสเตอร์และความสัมพันธ์แบบหลายต่อมาก จากนั้นเราจะอธิบายว่ารูปแบบการเข้าถึงข้อมูลที่แตกต่างกันแต่ละแบบโต้ตอบกับการแบ่งแยกนั้นอย่างไร
หากคุณกำลังมองหาบทช่วยสอนการเชื่อมโยง Rails ที่ครอบคลุมการตั้งค่าหลายฐานข้อมูลโดยเฉพาะ นี่คือคำตอบ นอกจากนี้เรายังจะพูดคุยเรื่องอื่นๆ อีกมากมาย ดังนั้นโปรดอดทนต่อไป
เหตุใดฐานข้อมูลจึงไปอยู่ในคลัสเตอร์ที่แตกต่างกัน
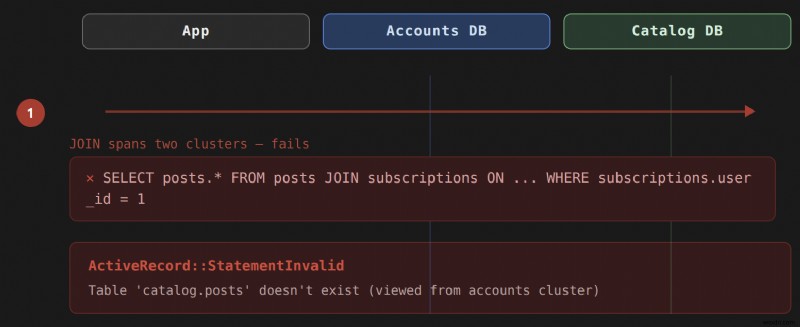
เมื่อแอปพลิเคชัน Rails เก็บข้อมูลทั้งหมดไว้ในฐานข้อมูลเดียว การเชื่อมโยง Active Record จะได้รับการจัดการอย่างโปร่งใส และคุณจะไม่คิดถึง SQL ที่ซ่อนอยู่เลย ทันทีที่ข้อมูลของคุณอยู่ในคลัสเตอร์ฐานข้อมูลหลายกลุ่ม ความโปร่งใสนั้นก็จะพังทลายลง 06 ต้องการให้ทั้งสองตารางมีอยู่ในเซิร์ฟเวอร์ฐานข้อมูลเดียวกัน การพยายามทำคลัสเตอร์เดียวจะสร้าง 11 ข้อผิดพลาดเช่นนี้:
ActiveRecord::StatementInvalid (Table 'people_cluster.humans' doesn't exist)
นี่ไม่ใช่ข้อผิดพลาดในการกำหนดค่า มันเป็นข้อจำกัดทางกายภาพที่เข้มงวด:เซิร์ฟเวอร์ฐานข้อมูลไม่สามารถ 25 เทียบกับตารางที่พวกเขาไม่ได้โฮสต์ เรามีปัญหานี้ใน 30 และ 41 การเชื่อมโยง เนื่องจากสิ่งเหล่านี้เป็นประเภทการเชื่อมโยงที่สร้างระดับกลาง 50 แบบสอบถาม โดยตรง 62 หรือ 73 ความสัมพันธ์ไม่จำเป็นต้องมีการเข้าร่วมเพื่อให้ทำงานข้ามคลัสเตอร์โดยไม่มีการแก้ไขใดๆ
ทำความเข้าใจว่า เมื่อใด คุณจะไปถึงขอบเขตนี้คือก้าวแรก ถ้าเป็น 86 อาศัยอยู่ใน 90 ฐานข้อมูลและ 100 อาศัยอยู่ใน 112 ฐานข้อมูล 124 ทำงานได้ดี แต่ถ้าคุณเพิ่มตัวกลาง 133 รุ่นใน 148 ฐานข้อมูลและกำหนด 151 Rails จะพยายามเข้าร่วม 165 และ 179 ในแบบสอบถามเดียว นั่นคือจุดที่ขอบเขตของคลัสเตอร์กลายเป็นปัญหา
การกำหนดค่าฐานข้อมูลสามชั้น
ก่อนที่จะเขียนโค้ดโมเดลใดๆ การกำหนดค่าฐานข้อมูลจำเป็นต้องสะท้อนเค้าโครงแบบหลายคลัสเตอร์ Rails ใช้โครงสร้างสามชั้นใน 183 เพื่อจุดประสงค์นี้ คีย์สภาพแวดล้อมระดับบนสุดแต่ละรายการมีชื่อฐานข้อมูลที่ซ้อนกัน และแต่ละคีย์มีรายละเอียดการเชื่อมต่อสำหรับคลัสเตอร์นั้น
# config/database.yml
default: &default
adapter: postgresql
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
primary:
<<: *default
database: myapp_primary_dev
accounts:
<<: *default
database: myapp_accounts_dev
migrations_paths: db/accounts_migrate
content:
<<: *default
database: myapp_content_dev
migrations_paths: db/content_migrate
production:
primary:
<<: *default
database: myapp_primary_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
accounts:
<<: *default
database: myapp_accounts_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
content:
<<: *default
database: myapp_content_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
191 รหัสไม่ใช่ตัวเลือกถ้าคุณต้องการตัวสร้าง Rails และ 209 เพื่อกำหนดเส้นทางการโยกย้ายไปยังไดเร็กทอรีที่ถูกต้อง หากไม่มีสิ่งนี้ การย้ายข้อมูลทั้งหมดจะมีค่าเริ่มต้นเป็น 216 และนำไปใช้กับฐานข้อมูลหลัก แต่ละฐานข้อมูลรองควรมีคลาสบันทึกนามธรรมที่เกี่ยวข้องซึ่งโมเดล Rails สืบทอดมา ตัวสร้างจะจัดการสิ่งนี้โดยอัตโนมัติเมื่อคุณผ่าน 227 ธง:
rails generate model Subscription plan:string --database accounts
สิ่งนี้จะสร้าง 237 คลาสหากไม่มีอยู่แล้วและสร้าง 247 โมเดลสืบทอดมาจากโมเดลนั้น
คลาสบันทึกนามธรรมและเส้นทางการเชื่อมต่อ
คลาสบันทึกนามธรรมเป็นกลไกที่ Rails ใช้เพื่อกำหนดเส้นทางการสืบค้นไปยังคลัสเตอร์ที่ถูกต้อง แต่ละคนเรียก 258 เพื่อประกาศว่าฐานข้อมูลใดที่จะจับคู่กับการเขียนและการอ่าน โดยทั่วไปใบสมัครของคุณจะมีสามชั้นในลำดับชั้นนี้
# app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary }
end
# app/models/accounts_record.rb
class AccountsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :accounts, reading: :accounts }
end
# app/models/content_record.rb
class ContentRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :content, reading: :content }
end
โมเดลผู้ใช้เป็นจุดยึดที่ดีในการทำความเข้าใจลำดับชั้นนี้ มันอยู่ใน 265 คลัสเตอร์และสืบทอดมาจาก 274 . รุ่นใน 285 คลัสเตอร์สืบทอดมาจาก 291 . ทุกสิ่งทุกอย่างสืบทอดมาจาก 304 และเข้าสู่ฐานข้อมูลหลัก สายการสืบทอดนี้เป็นวิธีที่ Active Record กำหนดพูลการเชื่อมต่อที่จะใช้เมื่อดำเนินการค้นหา มันจะเดินตามลำดับชั้นของคลาสจนกว่าจะพบคลาสที่เรียกว่า 313 . 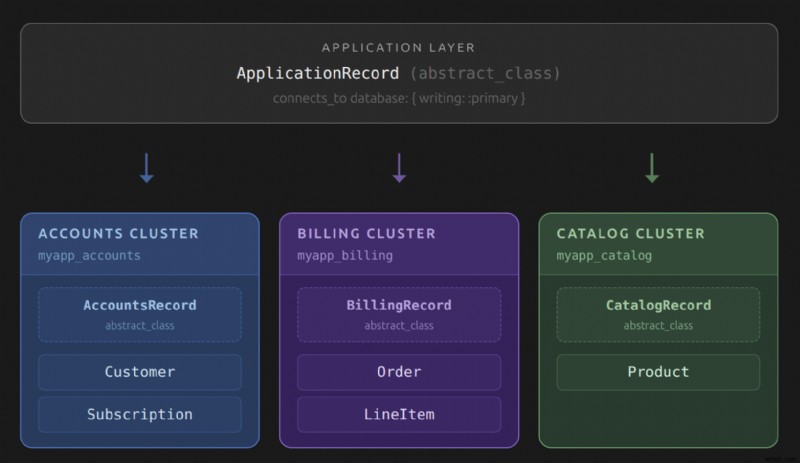
ข้อผิดพลาดทั่วไปคือการเรียก 326 ในแต่ละรุ่นแทนที่จะใช้คลาสนามธรรม 337 แต่ละตัว โทรเปิดกลุ่มการเชื่อมต่อแยกต่างหาก หากคุณมี 50 รุ่นใน 348 ฐานข้อมูลแต่ละสายเรียก 356 คุณจะพบพูลการเชื่อมต่อ 50 พูลที่ชี้ไปที่เซิร์ฟเวอร์เดียวกัน คลาสนามธรรมแก้ปัญหานี้ด้วยการแบ่งปันพูลเดียวในทุกโมเดลที่สืบทอดมาจากคลาสเหล่านั้น
การเชื่อมโยงข้ามคลัสเตอร์ใน Rails ทำงานอย่างไร
361 option เป็นกลไกโดยตรงในการสร้าง 374 การเชื่อมโยงจะทำงานเมื่อตารางที่เกี่ยวข้องอยู่ในคลัสเตอร์ที่แตกต่างกัน ราง 382 เป็นประเภทการเชื่อมโยงที่ใช้บ่อยที่สุด และเป็นประเภทที่ได้รับผลกระทบโดยตรงจากขอบเขตคลัสเตอร์ เมื่อ Rails พบตัวเลือกนี้ในการเชื่อมโยง ระบบจะละทิ้ง 399 เดี่ยว กลยุทธ์การสืบค้นและออก 406 ตามลำดับสองรายการ (หรือมากกว่า) แทน คำสั่ง piping ID จากแบบสอบถามแรกไปยัง 416 ข้อที่สอง
ต่อไปนี้เป็นการตั้งค่าโมเดลที่เป็นรูปธรรมซึ่งครอบคลุมสามกลุ่ม การตั้งค่าโมเดลด้านล่างเป็นความสัมพันธ์แบบกลุ่มต่อกลุ่ม ผู้ใช้เชื่อมต่อกับโพสต์ผ่านการสมัครสมาชิก และเป็นรูปแบบที่ทำให้เกิดปัญหาข้ามคลัสเตอร์ได้โดยตรงที่สุด
# app/models/user.rb - lives in the accounts database
class User < AccountsRecord
has_many :subscriptions
has_many :posts, through: :subscriptions, disable_joins: true
end
# app/models/subscription.rb - lives in the accounts database
class Subscription < AccountsRecord
belongs_to :user
has_many :posts
end
# app/models/post.rb - lives in the content database
class Post < ContentRecord
belongs_to :subscription
end
เมื่อคุณโทร 420 Rails สร้างการสืบค้นคู่นี้แทนที่จะเป็น 436 เดียว :
-- Query 1: fetch subscription IDs from the accounts cluster
SELECT "subscriptions"."id"
FROM "subscriptions"
WHERE "subscriptions"."user_id" = 1
-- Query 2: fetch posts from the content cluster using those IDs
SELECT "posts".*
FROM "posts"
WHERE "posts"."subscription_id" IN (4, 7, 12)
แบบสอบถามแรกทำงานกับ 447 ฐานข้อมูลเพื่อรวบรวมคีย์หลัก ครั้งที่สองทำงานกับ 459 . Rails แก้ไขความสัมพันธ์โดยทำตามคีย์ต่างประเทศ 461 ในการสมัครสมาชิกและ 475 บนเสาทั้งสองกลุ่ม ข้อความค้นหาแรกรวบรวมค่าคีย์หลักจากการสมัครสมาชิก จากนั้นส่งผ่านไปยัง 488 ประโยคคำถามที่สอง แบบสอบถามทั้งสองพยายามรวมข้ามคลัสเตอร์ Rails รวบรวมผลลัพธ์สุดท้ายที่ตั้งไว้ในหน่วยความจำแอปพลิเคชัน 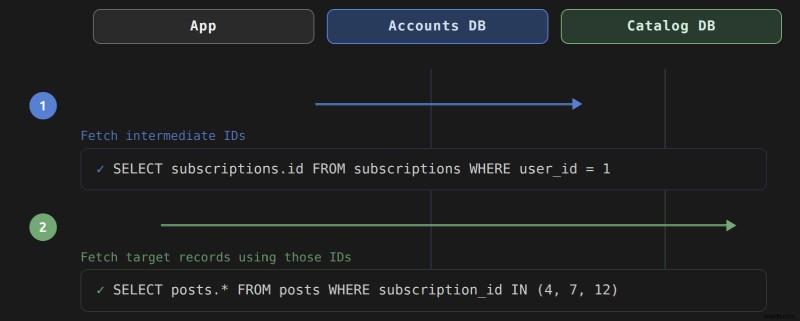
 ตัวเลือกเดียวกันนี้ทำงานเหมือนกันบน
ตัวเลือกเดียวกันนี้ทำงานเหมือนกันบน 495 :
# app/models/user.rb
class User < AccountsRecord
has_one :profile
has_one :avatar, through: :profile, disable_joins: true
end
# app/models/profile.rb - accounts database
class Profile < AccountsRecord
belongs_to :user
has_one :avatar
end
# app/models/avatar.rb - content database
class Avatar < ContentRecord
belongs_to :profile
end
503 จะดำเนินการสองแบบสอบถาม:หนึ่งรายการเพื่อรับ 518 อีกวิธีหนึ่งเพื่อดึงบันทึกอวาตาร์จากคลัสเตอร์เนื้อหา
เมื่อ 522 จะต้องตั้งค่าอย่างชัดเจน
Rails ไม่ตรวจจับขอบเขตของคลัสเตอร์โดยอัตโนมัติและแทรก 532 สำหรับคุณ การโหลดการเชื่อมโยงใน Active Record ขี้เกียจ SQL สำหรับการเชื่อมโยงจะถูกกำหนด ณ จุดที่มีการกำหนดการเชื่อมโยงบนโมเดล ไม่ใช่เมื่อมีการทริกเกอร์จริง เมื่อถึงเวลา 548 ดำเนินการ Rails ได้ตัดสินใจแล้วว่าจะใช้ 554 หรือไม่ หรือแยกคำถามตามประกาศของสมาคม
ซึ่งหมายความว่าทุกๆ 567 การเชื่อมโยงที่ข้ามขอบเขตคลัสเตอร์ต้องการ 575 ในการประกาศ
วิธีปฏิบัติจริงในการตรวจสอบโมเดลของคุณคือการค้นหา 585 การเชื่อมโยงโดยที่โมเดลต้นทางและโมเดลเป้าหมายสืบทอดมาจากคลาสบันทึกนามธรรมที่แตกต่างกัน ถ้า 590 และ 605 จากนั้น 618 ต้องการ 626 โดยไม่คำนึงถึงตำแหน่งที่ 630 ชีวิต
การโหลดข้ามคลัสเตอร์อย่างกระตือรือร้น
649 ตัวเลือกส่งผลต่อวิธีการโหลดการเชื่อมโยง แต่จะไม่เปลี่ยนวิธีที่กลยุทธ์การโหลดที่กระตือรือร้นโต้ตอบกับข้อมูลข้ามคลัสเตอร์ การทำความเข้าใจความแตกต่างนี้มีความสำคัญในการหลีกเลี่ยงการสืบค้น N+1 ในการตั้งค่าหลายฐานข้อมูล
654 อยู่นอกตารางสำหรับการเชื่อมโยงข้ามคลัสเตอร์ มันสร้าง 668 ซึ่งมีข้อจำกัดทางกายภาพเช่นเดียวกับ 673 ปกติ ทั้งสองตารางจะต้องอยู่บนเซิร์ฟเวอร์เดียวกัน หากคุณพยายาม 681 โดยที่โพสต์อยู่ในคลัสเตอร์อื่น คุณจะได้รับ 690 เดียวกัน ผิดพลาด
703 เป็นกลยุทธ์ที่ถูกต้อง โดยจะออกคำถามแยกกันสำหรับแต่ละการเชื่อมโยงและรวบรวมความสัมพันธ์ใน Ruby นี่เป็นโครงสร้างที่เหมือนกับสิ่งที่ 716 ทำเพื่อบันทึกเดียว ความแตกต่างคือขนาด:729 จัดกลุ่มแบบสอบถามที่สองในบันทึกหลักที่โหลดทั้งหมด
# This works across clusters.
# Query 1: SELECT "users".* FROM "users"
# Query 2: SELECT "posts".* FROM "posts" WHERE "posts"."subscription_id" IN (...)
users = User.preload(:posts).all
users.each do |user|
user.posts.each { |post| puts post.title } # No additional queries fired
end
733 จะทำงานในกรณีที่มอบหมายให้ 741 ภายใน ซึ่งจะทำโดยค่าเริ่มต้นเมื่อไม่มีเงื่อนไขที่อ้างอิงถึงตารางที่เกี่ยวข้อง หากคุณเพิ่ม 752 ส่วนคำสั่งที่แตะคอลัมน์ของตารางที่เกี่ยวข้อง 767 สลับไปที่ 776 พฤติกรรมและจะล้มเหลวข้ามคลัสเตอร์ เมื่อมีข้อสงสัยเกี่ยวกับกลยุทธ์ 782 จะเลือก ชัดเจน และใช้ 792 โดยตรง
# includes delegates to preload here, works across clusters
User.includes(:posts).all
# includes switches to eager_load because of the where clause, fails across clusters
User.includes(:posts).where("posts.published = ?", true)
# Use preload + a separate where for cross-cluster filtering
User.preload(:posts).all.select { |u| u.posts.any?(&:published?) }
# Or filter in application code after loading
การเชื่อมโยงที่กำหนดขอบเขตและการกรองข้ามคลัสเตอร์
การโต้ตอบที่ละเอียดอ่อนอย่างหนึ่งในการตั้งค่าหลายฐานข้อมูลคือการเชื่อมโยงที่กำหนดขอบเขต เมื่อคุณกำหนดขอบเขตบน 808 ที่ข้ามคลัสเตอร์ SQL ของขอบเขตจะทำงานกับฐานข้อมูลเป้าหมาย ไม่ใช่แหล่งที่มา
class User < AccountsRecord
has_many :subscriptions
has_many :published_posts,
-> { where(published: true) },
through: :subscriptions,
source: :posts,
class_name: "Post",
disable_joins: true
end
812 ส่วนคำสั่งจะถูกผนวกเข้ากับแบบสอบถามที่สอง ซึ่งเป็นแบบสอบถามที่ทำงานกับ 823 ฐานข้อมูล นี่เป็นพฤติกรรมที่ถูกต้อง และหมายความว่าขอบเขตของคุณสามารถอ้างอิงคอลัมน์บนตารางเป้าหมายได้โดยไม่มีปัญหา สิ่งที่คุณไม่สามารถทำได้คือการอ้างอิงคอลัมน์จากตารางระดับกลางในขอบเขตนั้น เนื่องจากการสืบค้นระดับกลางได้ดำเนินการเสร็จสิ้นแล้วตามเวลาที่ดำเนินการสืบค้นในขอบเขต
# This will fail because subscriptions.active is not a column in the content database
has_many :active_posts,
-> { where("subscriptions.active = ?", true) },
through: :subscriptions,
source: :posts,
disable_joins: true
กรองบันทึกระดับกลางโดยเพิ่มขอบเขตให้กับการเชื่อมโยงระดับกลางแทน:
class User < AccountsRecord
has_many :active_subscriptions, -> { where(active: true) }, class_name: "Subscription"
has_many :active_posts, through: :active_subscriptions, source: :posts, disable_joins: true
end
ตอนนี้การกรองบน 835 เกิดขึ้นในแบบสอบถามแรก เทียบกับ 843 ฐานข้อมูลและเฉพาะ ID จากการสมัครสมาชิกที่ใช้งานอยู่เท่านั้นที่จะถูกส่งไปยังแบบสอบถามที่สอง
การแบ่งส่วนแนวนอนและการเชื่อมโยงข้ามส่วน
การแยกฐานข้อมูลโลจิคัลหนึ่งฐานข้อมูลไปยังเซิร์ฟเวอร์หลายเครื่องโดยยึดตามพาร์ติชั่นคีย์ เช่น 859 แนะนำมิติที่สองให้กับปัญหาข้ามคลัสเตอร์ 860 กลไกยังคงใช้อยู่ แต่เส้นทางการเชื่อมต่อมีความเกี่ยวข้องมากขึ้น
Rails ให้ 871 สำหรับการสลับระหว่างส่วนต่างๆ ภายในคำขอ:
ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
User.find(1) # Hits shard_one
end
เมื่อการเชื่อมโยงครอบคลุมทั้งคลัสเตอร์และส่วนแบ่งข้อมูล คุณต้องตรวจสอบให้แน่ใจทั้งบริบทของส่วนแบ่งข้อมูลและ 880 มีตัวเลือกอยู่ 891 บน 906 เข้าถึงโพสต์ที่อยู่ใน 917 แยกต่างหาก ฐานข้อมูลยังคงต้องการการแยกย่อยสองแบบสอบถามเดียวกัน
Rails 8 เพิ่มวิธีการวิปัสสนาที่ทำให้การให้เหตุผลเกี่ยวกับโทโพโลยีชาร์ดง่ายขึ้นที่รันไทม์:
class ShardedBase < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
shard_one: { writing: :shard_one },
shard_two: { writing: :shard_two }
}
end
class User < ShardedBase; end
User.shard_keys # => [:shard_one, :shard_two]
User.sharded? # => true
ShardedBase.connected_to_all_shards do
User.current_shard # Yields :shard_one, then :shard_two
end
928 มีประโยชน์อย่างยิ่งสำหรับงานเบื้องหลังที่ต้องประมวลผลบันทึกในทุกส่วนย่อย โดยวนซ้ำแต่ละส่วนตามลำดับ โดยสลับบริบทการเชื่อมต่อสำหรับการดำเนินการแต่ละบล็อก
สำหรับการแบ่งส่วนตามผู้เช่า 934 ค่าเริ่มต้นในการสลับส่วนแบ่งข้อมูลจะป้องกันไม่ให้ผู้เช่ากระโดดข้ามคำขอกลางคันโดยไม่ตั้งใจ นี่เป็นกลไกด้านความปลอดภัย:เมื่อคำขอถูกส่งไปยังชาร์ดของผู้เช่าแล้ว รหัสแอปพลิเคชันจะไม่สามารถสลับไปยังชาร์ดของผู้เช่ารายอื่นได้โดยไม่ส่ง 947 อย่างชัดเจน . การเชื่อมโยงข้ามคลัสเตอร์ภายในส่วนแบ่งของผู้เช่ารายเดียวยังคงใช้ 957 สำหรับการเชื่อมโยงที่สัมผัสกับคลัสเตอร์ฐานข้อมูลอื่น
การทดสอบการเชื่อมโยงข้ามคลัสเตอร์
การทดสอบการตั้งค่าหลายฐานข้อมูลต้องการให้สภาพแวดล้อมการทดสอบของคุณสะท้อนโทโพโลยีฐานข้อมูลที่ใช้งานจริง กรอบการทดสอบของ Rails รองรับสิ่งนี้ แต่การกำหนดค่าจะต้องชัดเจน
แต่ละฐานข้อมูลใน 960 ต้องการ 970 บล็อกสิ่งแวดล้อม ข้อมูลการแข่งขันและข้อมูลการทดสอบตามโรงงานจะต้องกำหนดเป้าหมายฐานข้อมูลที่ถูกต้อง ถ้าเป็น 981 โรงงานสร้างบันทึกใน 999 ฐานข้อมูลและ 1004 โรงงานสร้างหนึ่งใน 1017 การเชื่อมโยงระหว่างทั้งสองจะใช้ได้ก็ต่อเมื่อมีบันทึกทั้งสองอยู่ในฐานข้อมูลตามลำดับภายในธุรกรรมทดสอบเดียวกัน
Rails ล้อมการทดสอบแต่ละรายการในธุรกรรมตามค่าเริ่มต้น แต่ธุรกรรมนั้นเป็นต่อการเชื่อมต่อ ด้วยฐานข้อมูลที่หลากหลาย แต่ละการเชื่อมต่อจะได้รับธุรกรรมของตัวเอง ซึ่งหมายความว่าการล้างการทดสอบ (การย้อนกลับอัตโนมัติเมื่อสิ้นสุดการทดสอบแต่ละครั้ง) จะเกิดขึ้นอย่างเป็นอิสระในแต่ละฐานข้อมูล หากการทดสอบของคุณเขียน 1026 ถึง 1033 และ 1049 ถึง 1059 ทั้งสองจะถูกย้อนกลับ แต่ถ้ากรอบการทดสอบรู้เกี่ยวกับการเชื่อมต่อทั้งสอง
1063 การประกาศจะจัดการสิ่งนี้โดยอัตโนมัติเมื่อโมเดลสืบทอดมาจากคลาสนามธรรมที่ถูกต้อง สำหรับการตั้งค่าตามโรงงาน (FactoryBot, Fabricator) โปรดตรวจสอบให้แน่ใจว่า 1079 ของแต่ละโรงงาน กลยุทธ์เข้าถึงฐานข้อมูลที่ถูกต้องโดยปล่อยให้ 1080 ของโมเดลเป็นของตัวเอง การกำหนดเส้นทางทำงานได้
# spec/factories/users.rb
FactoryBot.define do
factory :user do
# User inherits from AccountsRecord and writes to accounts DB automatically
name { Faker::Name.name }
end
end
# spec/factories/posts.rb
FactoryBot.define do
factory :post do
# Post inherits from ContentRecord and writes to content DB automatically
association :subscription
title { Faker::Lorem.sentence }
end
end
หากต้องการตรวจสอบว่าการเชื่อมโยงข้ามคลัสเตอร์เริ่มดำเนินการตามจำนวนที่คาดหวัง ให้สมัครรับ 1092 การแจ้งเตือน:
# spec/support/query_counter.rb
module QueryCounter
def assert_query_count(expected, &block)
count = 0
callback = ->(_name, _start, _finish, _id, payload) do
count += 1 unless payload[:name] == "SCHEMA" || payload[:sql].start_with?("EXPLAIN")
end
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
assert_equal expected, count, "Expected #{expected} queries, got #{count}"
end
end
1102 ด้วย 1118 ในบันทึกเดียวควรสร้างการสืบค้น 2 รายการพอดี หากคุณเห็น 1 แสดงว่ายังคงพยายามเข้าร่วมอยู่ (และจะล้มเหลวในการใช้งานจริงกับเซิร์ฟเวอร์ที่แยกจากกัน) หากคุณเห็น N+1 แสดงว่าการโหลดอย่างกระตือรือร้นไม่ทำงานตามที่คาดไว้
คำเตือนบางประการ
1121 แก้ปัญหาการโหลดการเชื่อมโยง แต่ไม่ขยายไปถึงการเชื่อมโยงแบบสอบถาม คุณไม่สามารถโยง 1136 ได้ , 1146 หรือ 1151 ส่วนคำสั่งที่อ้างอิงคอลัมน์ข้ามคลัสเตอร์ในความสัมพันธ์ Active Record เดียว:
# This does not work, you cannot filter products by order columns across clusters
customer.purchased_products.where("orders.total > ?", 100)
สำหรับการสืบค้นที่ต้องกรองหรือจัดเรียงตามข้อมูลในหลายคลัสเตอร์ ให้แยกย่อยด้วยตนเอง ดึงข้อมูล ID หรือค่าที่คุณต้องการจากคลัสเตอร์หนึ่ง จากนั้นใช้เป็นอินพุตในการสืบค้นเทียบกับอีกคลัสเตอร์:
high_value_order_ids = Order.where(customer_id: customer.id)
.where("total > ?", 100)
.pluck(:id)
line_item_product_ids = LineItem.where(order_id: high_value_order_ids).pluck(:product_id)
products = Product.where(id: line_item_product_ids)
นี่คือการสลายตัวแบบเดียวกับที่ 1163 ดำเนินการภายใน แต่ดำเนินการอย่างชัดเจน เพื่อให้คุณสามารถใช้การกรองในแต่ละขั้นตอนได้ มันละเอียดกว่า แต่มันทำให้ขอบเขตของคลัสเตอร์มองเห็นได้ในโค้ดแทนที่จะซ่อนไว้ด้านหลังการเชื่อมโยงในไวยากรณ์ Rails
หมายเหตุบรรณาธิการ:โพสต์นี้เผยแพร่ครั้งแรกในเดือนมกราคม 2023 และได้รับการอัปเดตเพื่อความถูกต้อง
