
คุณอ่านแผนปฏิบัติการอย่างไร? จากขวาไปซ้าย ซ้ายไปขวา หรือเช็คค่าใช้จ่าย? หรือสิ่งที่เกี่ยวกับวัตถุเช่นการสแกนดัชนี การสแกนตาราง และการค้นหา? บล็อกนี้อธิบายวิธีอ่านแผนการดำเนินการของ Microsoft® SQL Server
แนะนำตัว
แม้ว่าโดยปกติแล้ว SQL Server จะสร้างแผนที่ดี แต่บางครั้งก็ไม่ฉลาดพอที่จะตรวจสอบแผนและแก้ไขปัญหาที่ไม่ดี
คุณสามารถรับแผนการดำเนินการโดยประมาณและแผนการดำเนินการแบบกราฟิกจริงใน SQL Server สร้างแผนเหล่านี้โดยใช้คำสั่ง ctrl M หรือ ctrl L หรือโดยใช้ไอคอนซึ่งวางไว้ทางด้านขวาของไอคอนดำเนินการบนแถบเครื่องมือมาตรฐานของ SQL Server Management Studio (SSMS) SQL Server มีแผนประเภทอื่น แต่แผนเหล่านั้นไม่ครอบคลุมในโพสต์นี้
แผนปฏิบัติการโดยประมาณและตามจริง
แผนการดำเนินการมีสองประเภท:
-
แผนปฏิบัติการโดยประมาณ :แผนงานโดยประมาณเป็นการประเมินงานที่เซิร์ฟเวอร์ SQL คาดว่าจะดำเนินการเพื่อรับข้อมูล
-
แผนปฏิบัติการจริง :แผนการดำเนินการจริงจะถูกสร้างขึ้นหลังจากการสอบถาม Transact-SQL หรือดำเนินการชุดงาน ด้วยเหตุนี้ แผนการดำเนินการจริงจึงมีข้อมูลรันไทม์ เช่น เมตริกการใช้งานทรัพยากรจริงและคำเตือนรันไทม์
การประมวลผลข้อมูล
คุณเคยสังเกตความแตกต่างระหว่างแผนโดยประมาณและแผนจริงสำหรับแบบสอบถามเดียวกันหรือไม่? โดยส่วนใหญ่จะเหมือนกัน แต่อาจแตกต่างกันเนื่องจากการเปลี่ยนแปลงทางสถิติ การเปลี่ยนแปลงที่เกี่ยวข้องกับสคีมา หรือการเปลี่ยนแปลงในข้อมูล คุณควรตรวจสอบแผนปฏิบัติการจริงทุกครั้งเมื่อแก้ไขปัญหา
อ่านแผนปฏิบัติการให้ถูกต้องเพื่อระบุจุดที่แท้จริง เริ่มต้นด้วยการดูการไหลของข้อมูลมากกว่าต้นทุน อย่าคิดเกี่ยวกับตรรกะหรือการอ่านทางกายภาพ สิ่งสำคัญคือต้องลดจำนวนการดำเนินการอินพุต/เอาต์พุต (I/O) ในฐานะผู้ดูแลระบบฐานข้อมูล (DBA) คุณทราบดีว่าการเข้าถึงที่เก็บข้อมูลเป็นทรัพยากรฮาร์ดแวร์ที่ช้าที่สุด ดังนั้นคุณควรพยายามลดกิจกรรมนั้นให้น้อยที่สุด คุณสำรวจสถิติอย่างไรและแผนปฏิบัติการแสดงให้เห็นอย่างไร? ใช่แล้ว! ตรวจสอบเส้นทิศทางโดยวางเมาส์เหนือตัวบ่งชี้จากขวาไปซ้าย จะแสดงจำนวนเรคคอร์ดและขนาดข้อมูล แต่ละบรรทัดจะหนาขึ้นหรือบางลงตามปริมาณข้อมูลที่ส่งคืนโดยการดำเนินการดังแสดงในภาพประกอบต่อไปนี้:
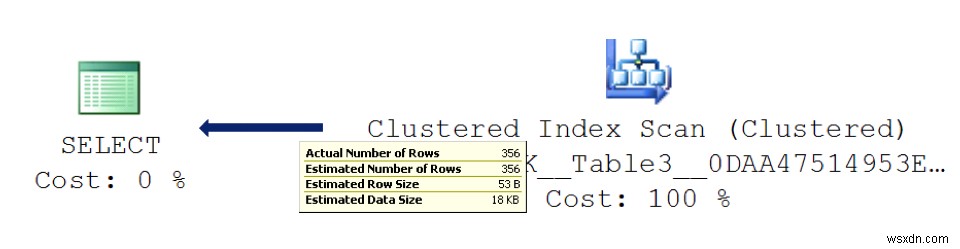
หากคุณมีออบเจ็กต์จำนวนมาก คุณต้องการวิธีที่ดีกว่าในการดูภาพรวมของจำนวนข้อมูลที่ประมวลผลโดยการดำเนินการแต่ละครั้ง ดาวน์โหลด SentryOne Plan Explorer และดูแผนโดยใช้เครื่องมือนี้เพื่อดูภาพรวมได้ง่ายๆ
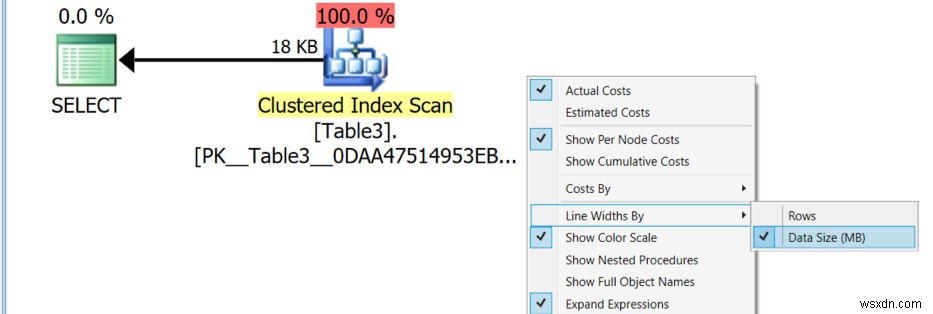
หลังจากที่คุณดาวน์โหลดและกำหนดค่า SentryOne บนระบบของคุณแล้ว ให้เปิดแผนการดำเนินการด้วย SentryOne มีมุมมองและคำอธิบายมากมาย ซึ่งคุณสามารถใช้ตามที่คุณต้องการ หากต้องการรับมุมมองการประมวลผลข้อมูล ให้เปลี่ยนมุมมองโดยเลือกData size in MB ตัวเลือกตามที่แสดงในภาพต่อไปนี้ เป้าหมายของคุณคือการหาโอกาสในการลดการประมวลผลข้อมูลโดยรวม
หากคุณต้องการลดความเครียดของ I/O คุณอาจดูที่ SET STATISTICS IO ON ค่า T-SQL เพื่อรับแนวคิดโดยรวมเกี่ยวกับการใช้ I/O สำหรับการสืบค้น คุณควรตั้งค่านี้ก่อนดำเนินการค้นหาใน SSMS เพื่อดูผลลัพธ์เปลี่ยนเป็นข้อความ แท็บใน ผลลัพธ์ แผงหน้าปัด. ควรมีลักษณะคล้ายกับผลลัพธ์ต่อไปนี้:
(356 row(s) affected)
Table 'Table3'. Scan count 1, logical reads 5, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
ตรรกะอ่าน 5 ผลลัพธ์แสดงว่า SQL Server อ่าน 40 KB (5 * 8 KB) หน้าเพื่อรับข้อมูลจากหน่วยความจำ เมื่อปรับการสืบค้นให้เหมาะสม อย่าละเลย การอ่านเชิงตรรกะ เนื่องจากอาจเป็นแบบจริงและแบบลอจิคัลบนเซิร์ฟเวอร์ที่ใช้งานจริง คุณไม่มีทางรู้หรอกว่าเพจที่คุณอ้างถึงนั้นอยู่ในหน่วยความจำหรือบนดิสก์ เป้าหมายควรเป็นเพื่อลดจำนวนการดำเนินการอ่านสะสม
ประมาณการกับแผนจริง
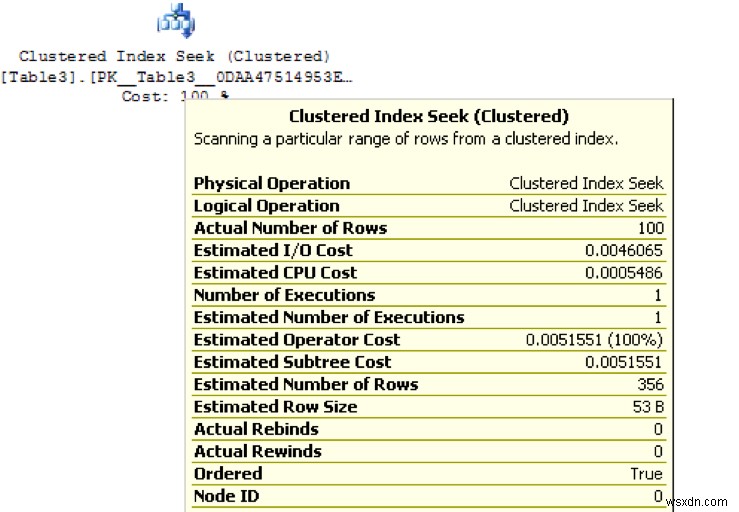
หลังจากสร้างแผนจริงแล้ว ให้วางเมาส์เหนือหน่วยปฏิบัติการใดๆ ในแผนปฏิบัติการ อ้างถึงรูปภาพต่อไปนี้เพื่อดูประเภทของการดำเนินการทางกายภาพ เช่น Clustered Index Seek or Scan ผลลัพธ์. ค้นหาจำนวนการดำเนินการและจำนวนแถวที่เกิดขึ้นจริงและโดยประมาณ หลีกเลี่ยงการพิจารณาต้นทุนของการดำเนินการแต่ละรายการ เนื่องจากเป็นค่าประมาณในไม่กี่วินาทีโดยอิงจากฮาร์ดแวร์เก่า และอาจไม่ได้ให้รายละเอียดที่ถูกต้องแม่นยำ ในภาพต่อไปนี้ Clustered Index Seek ตัวดำเนินการดำเนินการครั้งเดียวเพื่อรับ 100 ระเบียน และ SQL ประมาณ 356 ระเบียน ความแตกต่างอาจเนื่องมาจากสถิติที่ล้าสมัยหรือประสิทธิภาพการสืบค้น
การทำซ้ำการดำเนินการ
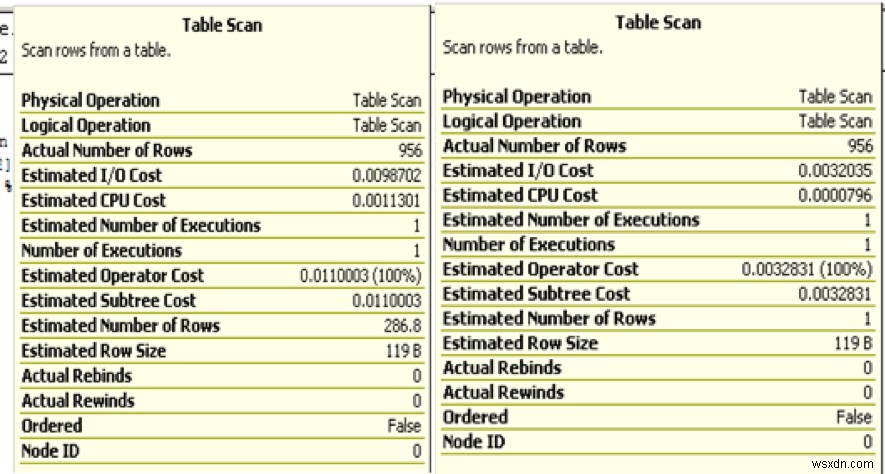
รูปภาพต่อไปนี้แสดงจำนวนการดำเนินการโดยประมาณคือ 1154121 ครั้งต่อดัชนีคลัสเตอร์เพื่อรับหนึ่งระเบียน นั่นเป็นสิ่งสำคัญ แม้ว่าค่าดำเนินการของผู้ปฏิบัติงานจะต่ำกว่า และเราอาจมองข้ามมันไปได้ โดยดูจากการดำเนินการอื่นๆ ที่มีต้นทุนสูงกว่า ซึ่งอาจพิสูจน์ได้ว่าเป็นทางเลือกที่มีค่าใช้จ่ายสูง การดำเนินการดังกล่าวมีผลกระทบสูงต่อประสิทธิภาพการสืบค้นแม้ว่าจะมีดัชนีคลัสเตอร์อยู่ก็ตาม การค้นหา Row ID (RID) เป็นการดำเนินการที่คล้ายกันสำหรับฮีป
ฐานข้อมูลชั่วคราว
ความแตกต่างระหว่างจำนวนบันทึกโดยประมาณและจำนวนจริงเป็นอีกสิ่งที่คุณควรพิจารณา การประมาณที่ไม่ถูกต้องอาจส่งผลให้มีการจัดสรรหน่วยความจำที่จำกัด เมื่อสิ่งนั้นเกิดขึ้น จะใช้ฐานข้อมูลชั่วคราว (tempdb) เพื่อทำสิ่งต่างๆ ให้เสร็จสิ้น ทางเลือกที่ไม่ถูกต้องของตัวดำเนินการหรือแผนโดย SQL Server อาจส่งผลให้การดำเนินการช้าและการแยกแบบสอบถามดังแสดงในรูปภาพต่อไปนี้ จำนวนระเบียนจริงเท่ากัน แต่ค่าประมาณต่างกัน อาจเป็นเพราะสถิติที่ล้าสมัยหรือขาดหายไป โปรดทราบว่าตัวแปรตารางไม่มีสถิติ ดังนั้นแผนจะคืนค่า 1 และ 1K ในรีลีสใหม่เสมอจนกว่าจะใช้ตัวเลือกในการคอมไพล์ใหม่ ดังนั้น ตัวแปรตารางจึงไม่ใช่ตัวเลือกที่ดีสำหรับเรคคอร์ดจำนวนมาก
ตัวดำเนินการจัดเรียง
คุณต้องพิจารณาถึงผลกระทบของการเรียงลำดับ ตัวดำเนินการเรียงลำดับส่วนใหญ่จะใช้สำหรับฟังก์ชันต่อไปนี้:รวม ผสานรวม หรือเรียงลำดับตามอนุประโยค การดำเนินการนี้อาจไม่ส่งผลกระทบกับระเบียนเพียงไม่กี่รายการ แต่เมื่อมีระเบียนเพิ่มเติมแต่ละรายการ การประมวลผลจะช้าลง พยายามหลีกเลี่ยงการเรียงลำดับหรือไม่ใช้การเรียงลำดับตามข้อ ถ้าต้องการการเรียงลำดับ ให้ใช้กริดของแอปพลิเคชันเพื่อทำการเรียงลำดับแทนการส่งข้อมูลที่เรียงลำดับไปยังแอปพลิเคชัน
รูปภาพต่อไปนี้แสดงต้นทุนการจัดเรียง:

ตัวดำเนินการสปูล
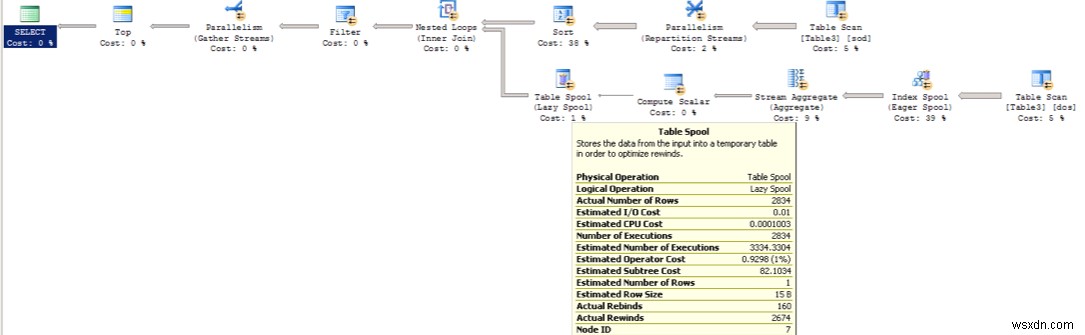
โอเปอเรเตอร์สำคัญอีกตัวที่คุณต้องดูคือสปูล สปูลเป็นตัวดำเนินการช้าเนื่องจากเก็บวัตถุที่ซ่อนอยู่หรือชั่วคราวหรือโต๊ะทำงาน intempdb สิ่งนี้ยังช้าลงด้วยตัวดำเนินการเฉพาะที่ทำให้ย้อนกลับได้ มีสพูลหลายประเภทใน SQL Server เช่น Eager, Lazy, Table/Index เป็นต้น SQL Server ใช้สปูลเมื่อดีกว่าที่จะอ้างถึงตารางงาน atemp แทนที่จะกลับไปที่ตารางต้นทางสำหรับชุดผลลัพธ์ระดับกลาง ภาพต่อไปนี้แสดงตัวอย่าง:
เมื่อใช้สปูล สิ่งสำคัญคือต้องสังเกตจำนวนการม้วนกลับและการกรอกลับ Rewindis มีราคาแพงกว่าการผูกใหม่ ตัวอย่างเช่น ในภาพต่อไปนี้ ตัวดำเนินการแสดงการกรอกลับ 2674 ครั้ง ซึ่งหมายความว่ามีการเรียกใช้แบบสอบถามอีกครั้ง 2674 ครั้งเพื่อรับข้อมูล จะส่งคืนโอเปอเรเตอร์แต่ละตัวจากสปูลของตารางไปยังการสแกนตารางเพื่อรับแต่ละเรคคอร์ดในการกรอกลับ Rebind หมายความว่าได้รับข้อมูลจากสปูลและไม่ส่งคืนการสแกนตาราง
ตัวดำเนินการแฮชและลูปที่ซ้อนกัน
เนื่องจากทำงานได้ดีในชุดระเบียนขนาดเล็ก แฮชและลูปที่ซ้อนกันจึงเป็นตัวดำเนินการถัดไปที่คุณควรพิจารณา อย่างไรก็ตาม สำหรับชุดระเบียนขนาดใหญ่ หรือเมื่อแผนโดยประมาณและแผนจริงมีความแตกต่างกันมาก ตัวดำเนินการเหล่านี้สามารถสร้างผลกระทบมหาศาลได้ เนื่องจากอาจใช้ tempdb แทนหน่วยความจำ SQL Server โพสต์คำเตือนต่อไปนี้ในรายละเอียดของโอเปอเรเตอร์:“operatorused tempdb to spill data during operation” หากเกิดเหตุการณ์นี้ ให้ความสนใจกับสถิติ ด้วยค่าประมาณที่ไม่ถูกต้อง ลูปขาดหายไปในการจัดสรรหน่วยความจำหรือวนซ้ำไปเรื่อยๆ ดูหน่วยความจำที่จัดสรรไว้สำหรับการดำเนินการ ในการจัดสรร viewmemory ให้เปิดกล่องคุณสมบัติโดยเลือกจุดเริ่มต้นของแผนการดำเนินการ (ซ้ายไปขวา) หากไม่มีอะไรผิดปกติ การปรับแต่งการค้นหาควรเป็นตัวเลือกที่เหมาะสมที่สุด
บทสรุป
เป้าหมายแรกของคุณสำหรับการเพิ่มประสิทธิภาพการสืบค้นควรลดการอ่านและเขียนโดยรวม (นั่นคือ I/O บนดิสก์) อย่าลืมการอ่านเชิงตรรกะสำหรับการอ่านและเขียนในหน่วยความจำ การลด I/O ช่วยแก้ปัญหาส่วนใหญ่และการสืบค้นทำงานเร็วขึ้นมาก
ถัดไป ดูการดำเนินการอื่นที่มีราคาแพงเนื่องจากกิจกรรม ontempdb จำไว้ว่า tempdb ใช้สำหรับการดำเนินการหลายอย่างและมีราคาแพงเสมอ มองหาการกรอกลับ - จำนวนการดำเนินการของการดำเนินการ สพูล การเรียงลำดับ และการวนซ้ำ
สิ่งเหล่านี้มีราคาแพงเมื่อใช้กับ tempdb อย่าลืมตรวจสอบคำเตือนเกี่ยวกับผู้ให้บริการแต่ละรายเพราะสิ่งเหล่านี้ให้เบาะแสที่ดี แม้ว่าโพสต์นี้จะไม่พูดถึงตัวดำเนินการดัชนีที่หายไป แต่ก็ไม่ได้หมายความว่าคุณจะเพิกเฉยได้
ตรวจทาน แต่อย่าสร้างดัชนีสุ่มสี่สุ่มห้า ตรวจสอบดัชนีอื่นๆ ที่มีอยู่ในคอลัมน์เดียวกัน และพิจารณาผลกระทบต่อการสืบค้นที่ทำงานอยู่ในฐานข้อมูลของคุณ
ใช้แท็บคำติชมเพื่อแสดงความคิดเห็นหรือถามคำถาม คุณสามารถเริ่มการสนทนากับเราได้
