

หนึ่งในคุณสมบัติใหม่ที่ยอดเยี่ยมที่สุดใน Elasticsearch 5 คือโหนดการนำเข้า ซึ่งเพิ่มการประมวลผลแบบ Logstash บางอย่างให้กับคลัสเตอร์ Elasticsearch จึงสามารถแปลงข้อมูลก่อนที่จะสร้างดัชนีได้โดยไม่ต้องใช้บริการและ/หรือโครงสร้างพื้นฐานอื่นเพื่อทำ ย้อนกลับไป เราได้โพสต์บล็อกสั้นๆ เกี่ยวกับวิธีแยกวิเคราะห์ไฟล์ csv ด้วย Logstash ดังนั้นฉันจึงอยากจะนำเสนอเวอร์ชันไปป์ไลน์ที่นำเข้ามาเพื่อการเปรียบเทียบ
สิ่งที่เราจะแสดงที่นี่คือตัวอย่างการใช้ Filebeat เพื่อส่งข้อมูลไปยังไปป์ไลน์นำเข้า จัดทำดัชนี และแสดงภาพด้วย Kibana
ข้อมูล
มีแหล่งข้อมูลดีๆ มากมายสำหรับข้อมูลฟรี แต่เนื่องจากพวกเราส่วนใหญ่ที่ ObjectRocket อยู่ในออสติน รัฐเท็กซัส เราจะใช้ข้อมูลบางส่วนจาก data.austintexas.gov ชุดข้อมูลการตรวจสอบร้านอาหารเป็นชุดข้อมูลขนาดพอเหมาะที่มีข้อมูลที่เกี่ยวข้องเพียงพอที่จะทำให้เราเห็นภาพตัวอย่างในโลกแห่งความเป็นจริง
ด้านล่างนี้คือสองสามบรรทัดจากชุดข้อมูลนี้เพื่อให้คุณเข้าใจถึงโครงสร้างของข้อมูล:
Restaurant Name,Zip Code,Inspection Date,Score,Address,Facility ID,Process Description
Westminster Manor,78731,07/21/2015,96,"4100 JACKSON AVE
AUSTIN, TX 78731
(30.314499, -97.755166)",2800365,Routine Inspection
Wieland Elementary,78660,10/02/2014,100,"900 TUDOR HOUSE RD
AUSTIN, TX 78660
(30.422862, -97.640183)",10051637,Routine Inspection
DOH… นี่จะไม่ใช่บรรทัดเดียวที่ดี เป็นมิตรต่อกรณีเข้าทำงาน แต่นั่นก็ใช้ได้ อย่างที่คุณจะได้เห็น Filebeat มีความสามารถในตัวเพื่อจัดการรายการหลายบรรทัดและแก้ปัญหาการขึ้นบรรทัดใหม่ที่ฝังอยู่ในข้อมูล
หมายเหตุบรรณาธิการ:ฉันกำลังวางแผนเกี่ยวกับตัวอย่างง่ายๆ ที่ดีโดยมี "ปัญหา" เล็กน้อย แต่ในท้ายที่สุด ฉันคิดว่าอาจน่าสนใจที่ได้เห็นเครื่องมือบางอย่างที่ Elastic Stack ให้คุณแก้ไขสถานการณ์เหล่านี้
การตั้งค่าไฟล์บีท
ขั้นตอนแรกคือการทำให้ Filebeat พร้อมที่จะเริ่มจัดส่งข้อมูลไปยังคลัสเตอร์ Elasticsearch ของคุณ เมื่อคุณดาวน์โหลด Filebeat แล้ว (ลองใช้เวอร์ชันเดียวกับคลัสเตอร์ ES ของคุณ) และแตกไฟล์ออกมา การติดตั้งผ่านไฟล์กำหนดค่า filebeat.yml ที่รวมมานั้นทำได้ง่ายมาก สำหรับสถานการณ์ของเรา นี่คือการกำหนดค่าที่ฉันใช้
filebeat.prospectors:
- input_type: log
paths:
- /Path/To/logs/*.csv
# Ignore the first line with column headings
exclude_lines: ["^Restaurant Name,"]
# Identifies the last two columns as the end of an entry and then prepends the previous lines to it
multiline.pattern: ',\d+,[^\",]+$'
multiline.negate: true
multiline.match: before
#================================ Outputs =====================================
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["https://dfw-xxxxx-0.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-1.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-2.es.objectrocket.com:xxxxx", "https://dfw-xxxxx-3.es.objectrocket.com:xxxxx"]
pipeline: "inspectioncsvs"
# Optional protocol and basic auth credentials.
username: "esuser"
password: "supersecretpassword"
ทุกอย่างค่อนข้างตรงไปตรงมาที่นี่ คุณมีส่วนที่จะระบุตำแหน่งและวิธีที่จะดึงไฟล์อินพุตและส่วนเพื่อระบุตำแหน่งที่จะจัดส่งข้อมูล ส่วนเดียวที่ฉันจะเรียกโดยเฉพาะคือบิตหลายบรรทัดและชิ้นส่วนการกำหนดค่า Elasticsearch
เนื่องจากการจัดรูปแบบสำหรับชุดข้อมูลนี้ไม่ได้เข้มงวดมากนัก ด้วยการใช้เครื่องหมายคำพูดคู่และการขึ้นบรรทัดใหม่ที่ไม่สอดคล้องกัน ทางเลือกที่ดีที่สุดคือมองหาจุดสิ้นสุดของรายการ ซึ่งประกอบด้วย ID ตัวเลขตามด้วยประเภทการตรวจสอบ โดยไม่มีการเปลี่ยนแปลงมากหรือ double-quotes/newline จากนั้น Filebeat จะจัดคิวบรรทัดที่ไม่ตรงกันและต่อท้ายบรรทัดสุดท้ายที่ตรงกับรูปแบบ หากข้อมูลของคุณสะอาดกว่าและยึดติดกับรูปแบบบรรทัดเดียวต่อรูปแบบรายการ คุณแทบจะเพิกเฉยการตั้งค่าหลายบรรทัดได้
เมื่อดูที่ส่วนผลลัพธ์ของ Elasticsearch จะเป็นการตั้งค่า Elasticsearch มาตรฐานพร้อมการเพิ่มชื่อของไปป์ไลน์ที่คุณต้องการใช้กับไปป์ไลน์:directive หากคุณอยู่ในบริการ ObjectRocket คุณสามารถดึงข้อมูลโค้ดเอาต์พุตจากแท็บ "เชื่อมต่อ" ใน UI ซึ่งจะมีโฮสต์ที่เหมาะสมทั้งหมดไว้ล่วงหน้า และเพียงเพิ่มไปป์ไลน์แล้วกรอกผู้ใช้และรหัสผ่านของคุณ . นอกจากนี้ ตรวจสอบให้แน่ใจว่าคุณได้เพิ่ม IP ของระบบลงใน ACL ของคลัสเตอร์แล้ว หากยังไม่ได้ดำเนินการ
การสร้างไปป์ไลน์การนำเข้า
ตอนนี้เรามีข้อมูลอินพุตและ Filebeat ที่พร้อมใช้งานแล้ว เราสามารถสร้างและปรับแต่งไปป์ไลน์การนำเข้าของเราได้ งานหลักที่ไปป์ไลน์ต้องดำเนินการคือ:
- แบ่งเนื้อหา csv เป็นฟิลด์ที่ถูกต้อง
- แปลงคะแนนการตรวจสอบเป็นจำนวนเต็ม
- ตั้งค่า
@timestampสนาม - ล้างการจัดรูปแบบข้อมูลอื่นๆ
นี่คือไปป์ไลน์ที่สามารถทำได้ทั้งหมด:
PUT _ingest/pipeline/inspectioncsvs
{
"description" : "Convert Restaurant inspections csv data to indexed data",
"processors" : [
{
"grok": {
"field": "message",
"patterns": ["%{REST_NAME:RestaurantName},%{REST_ZIP:ZipCode},%{MONTHNUM2:InspectionMonth}/%{MONTHDAY:InspectionDay}/%{YEAR:InspectionYear},%{NUMBER:Score},\"%{DATA:StreetAddress}\n%{DATA:City},?\\s+%{WORD:State}\\s*%{NUMBER:ZipCode2}\\s*\n\\(?%{DATA:Location}\\)?\",%{NUMBER:FacilityID},%{DATA:InspectionType}$"],
"pattern_definitions": {
"REST_NAME": "%{DATA}|%{QUOTEDSTRING}",
"REST_ZIP": "%{QUOTEDSTRING}|%{NUMBER}"
}
}
},
{
"grok": {
"field": "ZipCode",
"patterns": [".*%{ZIP:ZipCode}\"?$"],
"pattern_definitions": {
"ZIP": "\\d{5}"
}
}
},
{
"convert": {
"field" : "Score",
"type": "integer"
}
},
{
"set": {
"field" : "@timestamp",
"value" : "//"
}
},
{
"date" : {
"field" : "@timestamp",
"formats" : ["yyyy/MM/dd"]
}
}
],
"on_failure" : [
{
"set" : {
"field" : "error",
"value" : " - Error processing message - "
}
}
]
}
ไม่เหมือนกับ Logstash ไปป์ไลน์การนำเข้าไม่มี (ในขณะที่เขียนบทความนี้) มีตัวประมวลผล/ปลั๊กอิน csv ดังนั้น คุณจะต้องแปลง csv ด้วยตัวคุณเอง ฉันใช้ตัวประมวลผล grok ในการยกของหนัก เนื่องจากแต่ละแถวมีเพียงไม่กี่คอลัมน์ สำหรับข้อมูลที่มีคอลัมน์มากขึ้น ตัวประมวลผล grok อาจมีขนดก ดังนั้นอีกทางเลือกหนึ่งคือการใช้ตัวประมวลผลแบบแยกส่วนและการเขียนสคริปต์ที่ไม่เจ็บปวดเพื่อประมวลผลบรรทัดในลักษณะวนซ้ำมากขึ้น คุณอาจสังเกตเห็นตัวประมวลผล grok ตัวที่สองซึ่งมีไว้เพื่อจัดการกับสองวิธีที่แตกต่างกันในการป้อนรหัสไปรษณีย์ในชุดข้อมูลนี้
เพื่อจุดประสงค์ในการดีบัก ฉันได้รวมส่วน on_failure ทั่วไปซึ่งจะตรวจจับข้อผิดพลาดทั้งหมดและพิมพ์ว่าตัวประมวลผลประเภทใดที่ล้มเหลวและข้อความใดที่ทำลายไปป์ไลน์ ทำให้การดีบักง่ายขึ้น ฉันสามารถสอบถามดัชนีของฉันสำหรับเอกสารใดๆ ที่มีการตั้งค่าข้อผิดพลาด และสามารถดีบักด้วย API จำลองได้ เพิ่มเติมเกี่ยวกับที่ตอนนี้…
ทดสอบระบบท่อ
ตอนนี้เราได้กำหนดค่าไพพ์ไลน์การนำเข้าแล้ว มาทดสอบและรันมันด้วย API จำลอง ขั้นแรกคุณจะต้องมีเอกสารตัวอย่าง คุณสามารถทำได้สองวิธี คุณสามารถเรียกใช้ Filebeat โดยไม่ต้องตั้งค่าไปป์ไลน์ จากนั้นเพียงแค่หยิบเอกสารที่ยังไม่ได้ประมวลผลจาก Elasticsearch หรือคุณสามารถเรียกใช้ Filebeat โดยเปิดใช้งานเอาต์พุตคอนโซล โดยแสดงความคิดเห็นในส่วน Elasticsearch และเพิ่มสิ่งต่อไปนี้ลงในไฟล์ yml:
output.console:
pretty: true
นี่คือตัวอย่างเอกสารที่ฉันหยิบมาจากสภาพแวดล้อมของฉัน:
POST _ingest/pipeline/inspectioncsvs/_simulate
{
"docs" : [
{
"_index": "inspections",
"_type": "log",
"_id": "AVpsUYR_du9kwoEnKsSA",
"_score": 1,
"_source": {
"@timestamp": "2017-03-31T18:22:25.981Z",
"beat": {
"hostname": "systemx",
"name": "RestReviews",
"version": "5.1.1"
},
"input_type": "log",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"offset": 2109798,
"source": "/Path/to/my/logs/Restaurant_Inspection_Scores.csv",
"tags": [
"debug",
"reviews"
],
"type": "log"
}
}
]
}
และการตอบสนอง (ฉันได้ตัดมันลงไปยังฟิลด์ที่เราพยายามจะตั้งค่า):
{
"docs": [
{
"doc": {
"_id": "AVpsUYR_du9kwoEnKsSA",
"_type": "log",
"_index": "inspections",
"_source": {
"InspectionType": "Routine Inspection",
"ZipCode": "78660",
"InspectionMonth": "10",
"City": "AUSTIN",
"message": "Wieland Elementary,78660,10/02/2014,100,\"900 TUDOR HOUSE RD\nAUSTIN, TX 78660\n(30.422862, -97.640183)\",10051637,Routine Inspection",
"RestaurantName": "Wieland Elementary",
"FacilityID": "10051637",
"Score": 100,
"StreetAddress": "900 TUDOR HOUSE RD",
"State": "TX",
"InspectionDay": "02",
"InspectionYear": "2014",
"ZipCode2": "78660",
"Location": "30.422862, -97.640183"
},
"_ingest": {
"timestamp": "2017-03-31T20:36:59.574+0000"
}
}
}
]
}
ไปป์ไลน์ประสบความสำเร็จอย่างแน่นอน แต่ที่สำคัญที่สุด ข้อมูลทั้งหมดดูเหมือนจะมาถูกที่แล้ว
รันไฟล์บีต
ก่อนที่เราจะเรียกใช้ Filebeat เราจะทำสิ่งสุดท้าย ส่วนนี้เป็นทางเลือกโดยสมบูรณ์ หากคุณต้องการเพียงแค่ทำความคุ้นเคยกับไปป์ไลน์การนำเข้า แต่ถ้าคุณต้องการใช้ฟิลด์ตำแหน่งที่เราตั้งค่าในตัวประมวลผล grok เป็น Geo-point คุณจะต้องเพิ่มการแมปไปยัง filebeat template.json โดยเพิ่มข้อมูลต่อไปนี้ในส่วนคุณสมบัติ:
"Location": {
"type": "geo_point"
},
เท่านี้ก็เรียบร้อย เราสามารถเปิด Filebeat ได้ด้วยการเรียกใช้ ./filebeat -e -c filebeat.yml -d “elasticsearch”
การใช้ข้อมูล
GET /filebeat-*/_count
{}
{
"count": 25081,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
}
}
นั่นเป็นสัญญาณที่ดี! มาดูกันว่าเรามีข้อผิดพลาดหรือไม่:
GET /filebeat-*/_search
{
"query": {
"exists" : { "field" : "error" }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
อีกหนึ่งสัญญาณที่ดี!
ตอนนี้เราพร้อมที่จะแสดงภาพและแสดงข้อมูลของเราใน Kibana แล้ว เราสามารถดำเนินการสร้างแดชบอร์ด Kibana ได้อีกครั้ง แต่เนื่องจากเรามีวันที่ ชื่อร้านอาหาร คะแนน และสถานที่ เราจึงมีอิสระมากมายในการสร้างภาพที่สวยงาม
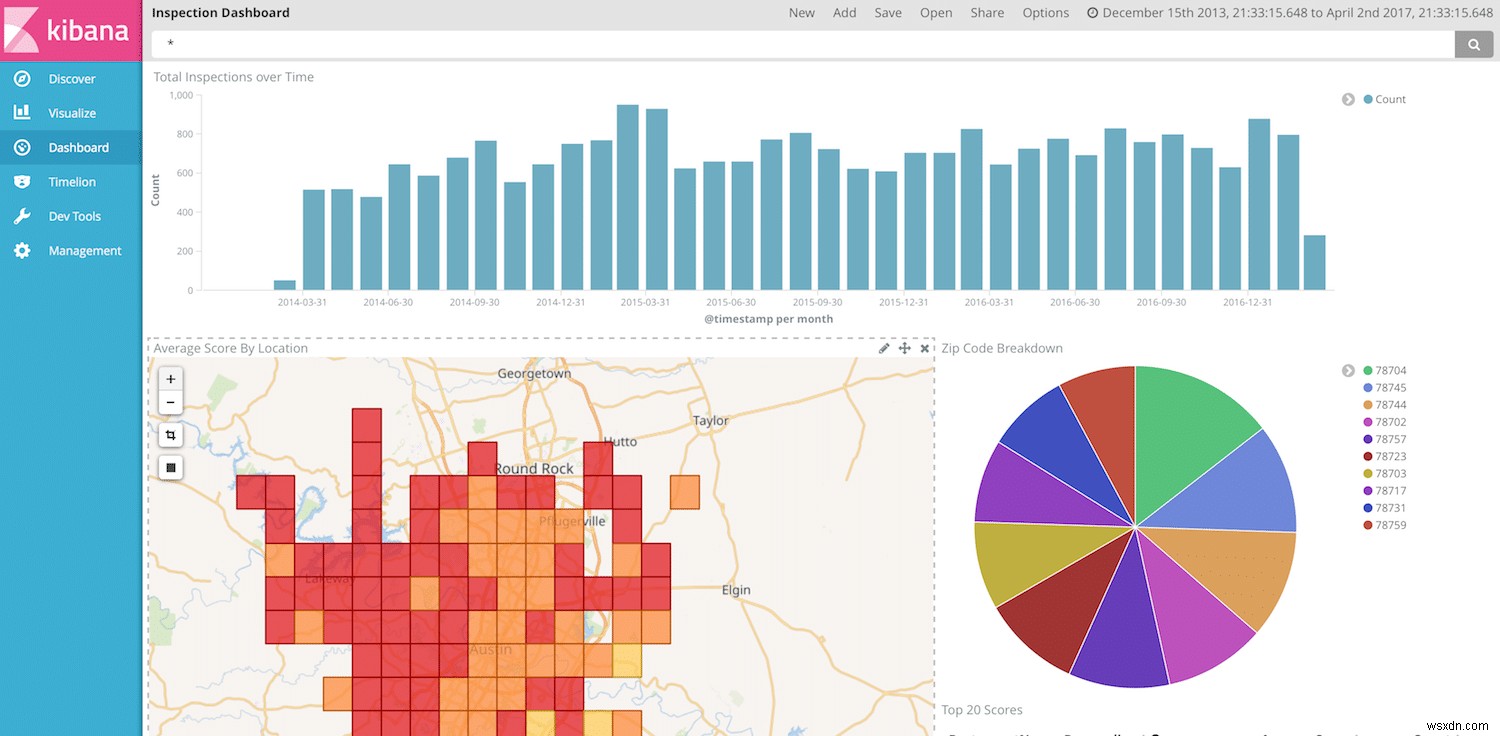
หมายเหตุสุดท้าย
อีกครั้งที่ไปป์ไลน์การส่งผ่านข้อมูลมีประสิทธิภาพมากและสามารถจัดการกับการเปลี่ยนแปลงได้อย่างง่ายดาย คุณสามารถย้ายการประมวลผลทั้งหมดของคุณไปที่ Elasticsearch และใช้ Beats แบบเบาบนโฮสต์ของคุณเท่านั้น โดยไม่ต้องใช้ Logstash ที่ใดที่หนึ่งในไปป์ไลน์ อย่างไรก็ตาม ยังมีช่องว่างในโหนดการนำเข้าเมื่อเทียบกับ Logstash ตัวอย่างเช่น จำนวนโปรเซสเซอร์ที่มีอยู่ในไพพ์ไลน์การนำเข้ายังคงมีจำกัด ดังนั้นงานง่ายๆ เช่น การแยกวิเคราะห์ CSV จึงไม่ง่ายเหมือนใน Logstash ดูเหมือนว่าทีม Elasticsearch จะเปิดตัวโปรเซสเซอร์ใหม่เป็นประจำ ดังนั้นหวังว่ารายการความแตกต่างจะเล็กลงเรื่อยๆ
