
Redis ได้รับการพัฒนาโดยเน้นที่ประสิทธิภาพอย่างมาก เราพยายามอย่างเต็มที่กับทุกรุ่นเพื่อให้แน่ใจว่าคุณจะได้สัมผัสกับผลิตภัณฑ์ที่เสถียรและรวดเร็ว
อย่างไรก็ตาม หากคุณกำลังหาช่องทางที่จะปรับปรุงประสิทธิภาพของ Redis หรือกำลังดำเนินการตรวจสอบการถดถอยของประสิทธิภาพ คุณจะต้องมีวิธีการตรวจสอบและวิเคราะห์ประสิทธิภาพของ Redis อย่างเป็นระบบ นี่คือเรื่องราวของหนึ่งในการปรับแต่งเหล่านั้น
ในท้ายที่สุด เราได้ปรับปรุงประสิทธิภาพการนำเข้าของสตรีมประมาณ 20% ซึ่งเป็นการปรับปรุงที่คุณสามารถใช้ประโยชน์จาก Redis v7.0 ได้แล้ว
สเปคมาตรฐาน
ก่อนที่จะเข้าสู่การเพิ่มประสิทธิภาพ เราต้องการให้คุณมีแนวคิดในระดับสูงว่าเราจะทำอย่างไร
ตามที่ระบุไว้ก่อนหน้านี้ เราต้องการระบุการถดถอยของประสิทธิภาพ Redis และ/หรือการปรับปรุงประสิทธิภาพบน CPU ที่อาจเกิดขึ้น ในการทำเช่นนั้น เรารู้สึกว่าจำเป็นต้องส่งเสริมชุดของมาตรฐานข้ามบริษัทและข้ามชุมชนในทุกเรื่องที่เกี่ยวข้องกับประสิทธิภาพและข้อกำหนดความสามารถในการสังเกตและความคาดหวัง
โดยสรุป เราเรียกใช้การวัดประสิทธิภาพของ SPEC อย่างต่อเนื่องโดยแยกย่อยตามสาขา/แท็ก และตีความข้อมูลประสิทธิภาพที่เป็นผลลัพธ์ซึ่งรวมถึงเครื่องมือสร้างโปรไฟล์/เอาท์พุตของผู้ตรวจสอบ และเอาต์พุตของไคลเอ็นต์ในโหมด "zero-touch" อัตโนมัติเต็มรูปแบบ
เครื่องมือที่ใช้เป็นโอเพ่นซอร์สทั้งหมดและพึ่งพาเครื่องมือ/เฟรมเวิร์กยอดนิยม เช่น memtier_benchmark, redis-benchmark, Linux perf_events, เครื่องมือติดตาม bcc/BPF และ FlameGraph repo ของ Brendan Greg
หากคุณสนใจรายละเอียดเพิ่มเติมเกี่ยวกับวิธีที่เราใช้ตัวสร้างโปรไฟล์กับ Redis เราขอแนะนำให้ดู “ ที่มีรายละเอียดมาก คู่มือวิศวกรรมประสิทธิภาพสำหรับการทำโปรไฟล์และการติดตามบน CPU "
หลีกเลี่ยงการคำนวณซ้ำเพื่อปรับปรุงประสิทธิภาพ
ทันทีที่ได้รับขั้นตอนแรกนี้ เราก็เริ่มตีความผลลัพธ์ของเครื่องมือสร้างโปรไฟล์/ผลลัพธ์ของผู้ตรวจสอบ เกณฑ์มาตรฐานอย่างหนึ่งที่นำเสนอรูปแบบที่น่าสนใจคือเกณฑ์มาตรฐานที่นำเข้าของ Streams ซึ่งเพียงนำเข้าข้อมูลไปยังสตรีมด้วยคำสั่งที่คล้ายกับคำสั่งด้านล่าง:
`คีย์ XADD * ค่าฟิลด์`
เราสังเกตว่าเมื่อเพิ่มไปยังสตรีมที่ไม่มี ID จะสร้างงานที่ซ้ำกันในการสร้าง/การปลดปล่อย/sdslen ของ SDS ซึ่งมีค่าใช้จ่ายประมาณ 10% ของรอบ CPU ดังที่แสดงในรายละเอียดในการพิมพ์รายงานประสิทธิภาพสองฉบับถัดไป
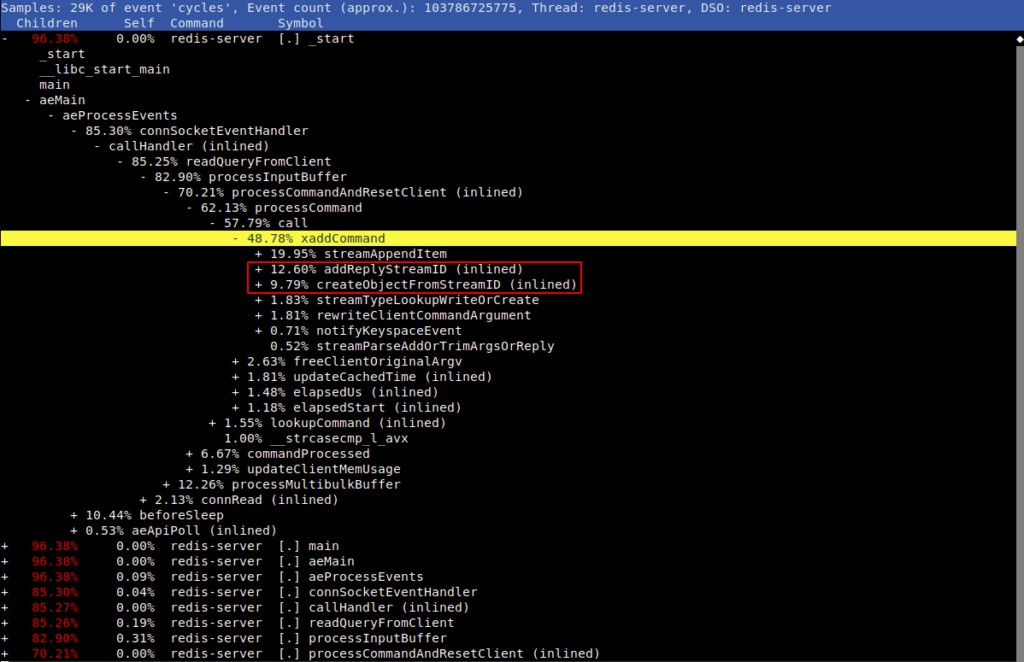
สำหรับอินพุตเดียวกัน sdscatfmt และ _sdsnewlen ถูกเรียกสองครั้ง:

ซึ่งช่วยให้เราเพิ่มประสิทธิภาพการนำเข้า Streams ได้ประมาณ 9-10% ตามที่ได้รับการยืนยันผลการเปรียบเทียบ:
เส้นฐานบนกิ่งที่ไม่เสถียร ( 6b403f5 ) :
การประชาสัมพันธ์ครั้งแรก (หลีกเลี่ยงการทำซ้ำ):

หลีกเลี่ยงการจัดสรรที่ซ้ำกันเพื่อปรับปรุงประสิทธิภาพ
จุดสนใจเริ่มต้นของการปรับปรุงกรณีการใช้งานนี้นำไปสู่การวิเคราะห์เพิ่มเติมจาก Oran (หนึ่งในสมาชิกหลักในทีม) ที่สังเกตเห็นการสูญเสียรอบ CPU อีกครั้ง ครั้งนี้เกิดจากการจัดการหน่วยความจำที่ไม่เหมาะสมภายในบล็อกโค้ดเดียวกัน เรากำลังจัดสรร SDS ที่ว่างเปล่า จากนั้นจึงจัดสรรใหม่ การลดจำนวนการโทรจะช่วยให้เราปรับปรุงความเร็วได้ดังที่แสดงด้านล่าง
คอมมิตครั้งที่สอง (หลีกเลี่ยง reallocs):

การปรับปรุงที่วัดได้
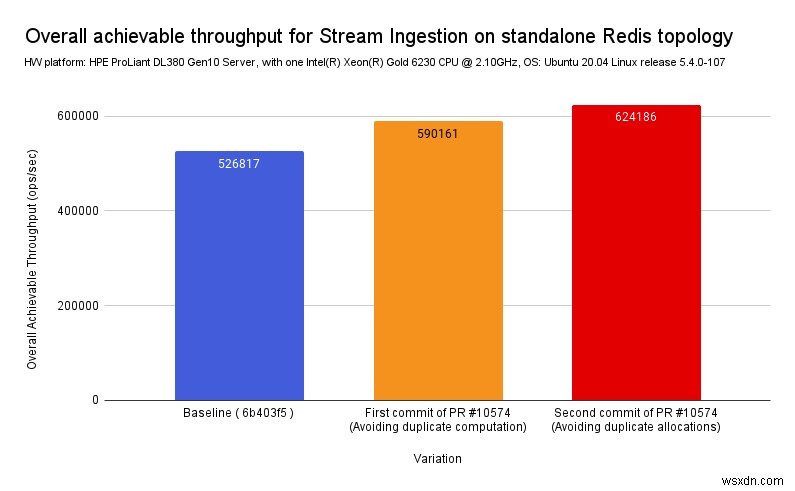
ตามที่คาดไว้ เพียงแค่นำการคำนวณระดับกลางมาใช้ใหม่ และลดการคำนวณซ้ำซ้อนและการจัดสรรภายในฟังก์ชันที่เรียกว่าภายใน เราได้วัดการลดลงของเวลา CPU โดยรวมประมาณ ~=20% ของ Redis Streams
เราเชื่อว่านี่คือตัวอย่างว่าการปรับปรุงอย่างง่ายอย่างมีระเบียบวิธีสามารถนำไปสู่การลดประสิทธิภาพได้อย่างมาก แม้แต่โค้ดที่ได้รับการเพิ่มประสิทธิภาพอย่างล้ำลึกอย่าง Redis อยู่แล้ว
เป้าหมายของเราคือการขยายการมองเห็นประสิทธิภาพที่เรามีของ Redis และสนับสนุนให้สมาชิกจากทั้งภาคอุตสาหกรรมและภาคการศึกษา รวมทั้งองค์กรและบุคคลต่างๆ หากเราไม่วัด เราไม่สามารถปรับปรุงได้
