
RediSearch ซึ่งเป็นดัชนีรองแบบเรียลไทม์ที่มีความสามารถในการค้นหาข้อความแบบเต็มสำหรับ Redis คือหนึ่งในโมดูล Redis ที่พัฒนาเต็มที่และมีคุณลักษณะมากที่สุด นอกจากนี้ยังได้รับความนิยมมากขึ้นทุกวัน—ในช่วงไม่กี่เดือนที่ผ่านมา RediSearch Docker pulls เพิ่มขึ้น 500%! ความนิยมที่เพิ่มสูงขึ้นนี้ทำให้ลูกค้าเกิดกรณีการใช้งานที่น่าสนใจมากมาย ตั้งแต่การจัดการสินค้าคงคลังแบบเรียลไทม์ไปจนถึงการค้นหาชั่วคราว
เพื่อขยายโมเมนตัมนั้น ตอนนี้เรากำลังเปิดตัวตัวอย่างสาธารณะของ RediSearch 2.0 ซึ่งออกแบบมาเพื่อปรับปรุงประสบการณ์ของนักพัฒนาซอฟต์แวร์ และเป็น เวอร์ชัน Redisearch ที่ปรับขนาดได้มากที่สุด . RediSearch 2.0 รองรับเทคโนโลยีการกระจายทางภูมิศาสตร์ของ Active-Active ของ Redis สามารถปรับขนาดได้โดยไม่ต้องหยุดทำงาน และรวม Redis บน Flash รองรับ (ขณะนี้อยู่ในการแสดงตัวอย่างส่วนตัว) เพื่อให้บรรลุเป้าหมายเหล่านั้นโดยไม่ส่งผลเสียต่อประสิทธิภาพ เราได้สร้างสถาปัตยกรรมใหม่ล่าสุดสำหรับ RediSearch 2.0 และได้ผล:RediSearch 2.0 เร็วขึ้น 2.4 เท่า กว่า RediSearch 1.6
ภายในสถาปัตยกรรมใหม่ของ RediSearch 2.0
การมีเอ็นจิ้นการสืบค้นและการรวมที่สมบูรณ์ในฐานข้อมูล Redis ของคุณทำให้มีกรณีการใช้งานใหม่ๆ ที่หลากหลาย ซึ่งขยายได้มากกว่าการแคช RediSearch ให้คุณใช้ Redis เป็นฐานข้อมูลหลักในสถานการณ์ที่คุณต้องการเข้าถึงข้อมูลโดยใช้การสืบค้นที่ซับซ้อน ยิ่งไปกว่านั้น ยังรักษาความเร็ว ความน่าเชื่อถือ และความสามารถในการปรับขนาดระดับโลกของ Redis และไม่ต้องการให้คุณเพิ่มความซับซ้อนให้กับโค้ดเพื่อให้คุณอัปเดตและจัดทำดัชนีข้อมูลได้
สำหรับ RediSearch 2.0 เราได้ออกแบบโครงสร้างใหม่เพื่อให้ดัชนีซิงค์กับข้อมูล แทนที่จะต้องเขียนข้อมูลผ่านดัชนี (โดยใช้คำสั่ง FT.ADD) RediSearch จะติดตามข้อมูลที่เขียนในแฮชและทำดัชนีแบบซิงโครนัส การปรับโครงสร้างใหม่นี้มาพร้อมกับการเปลี่ยนแปลงหลายอย่างใน API ซึ่งเราได้กล่าวถึงในโพสต์ก่อนหน้านี้เมื่อ RediSearch 2.0 เข้าสู่ก้าวแรก
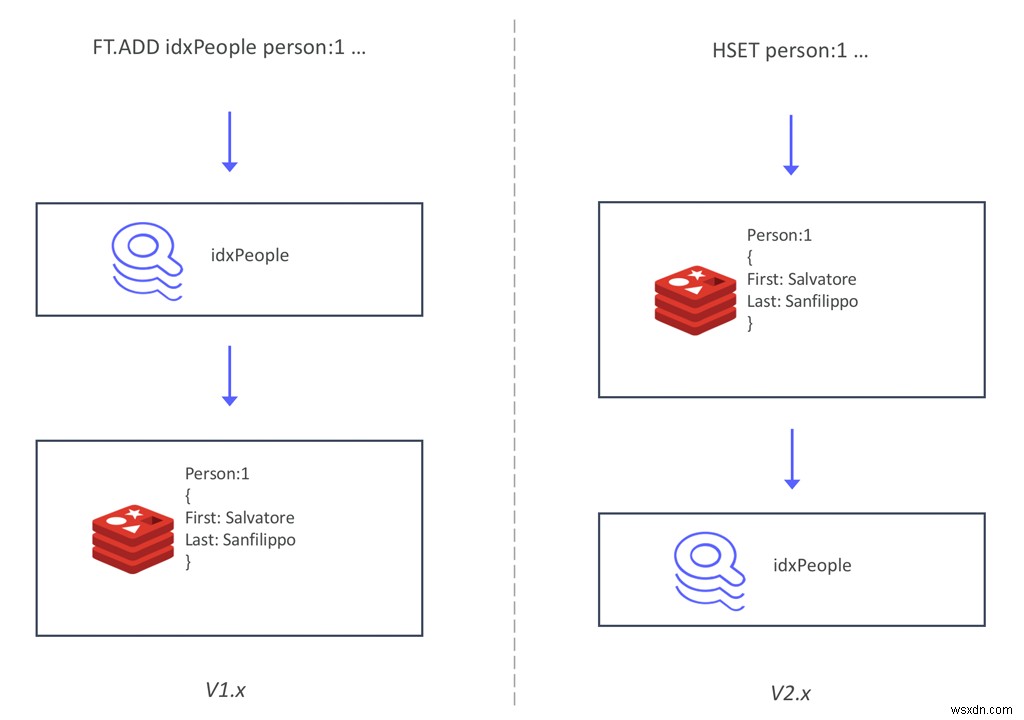
สถาปัตยกรรมใหม่นี้มีประโยชน์หลักสองประการ ประการแรก การสร้างดัชนีรองจากข้อมูลที่มีอยู่นั้นง่ายกว่าที่เคย คุณเพียงแค่ เพิ่ม RediSearch ลงในฐานข้อมูล Redis ที่มีอยู่ สร้างดัชนี และเริ่มสืบค้น โดยไม่ต้องย้ายข้อมูลหรือใช้คำสั่งใหม่ในการเพิ่มข้อมูลลงในดัชนี วิธีนี้ช่วยลดเส้นโค้งการเรียนรู้สำหรับผู้ใช้ RediSearch ใหม่ได้อย่างมาก และช่วยให้คุณสร้างดัชนีบนฐานข้อมูล Redis ที่มีอยู่ได้โดยไม่ต้องรีสตาร์ทด้วยซ้ำ
นอกจากการใช้วิธีการใหม่ในการจัดทำดัชนีข้อมูลแล้ว เรายังนำดัชนีออกจากคีย์สเปซอีกด้วย สิ่งนี้ทำให้เทคโนโลยี Active-Active ของ Redis Enterprise ใช้งานได้ ซึ่งอิงตามประเภทข้อมูลที่จำลองแบบไม่มีข้อขัดแย้ง (CRDT) การรวมดัชนีผกผันสองดัชนีที่ปราศจากข้อขัดแย้งนั้นเป็นเรื่องยาก แต่ Redis ได้นำ CRDTs ไปใช้งานที่พิสูจน์แล้วของ Hashes แล้ว ดังนั้น ประโยชน์ใหญ่อันดับสองของสถาปัตยกรรมใหม่นี้ทำให้ RediSearch 2.0 สามารถปรับขนาดได้มากขึ้น . เนื่องจากตอนนี้ RediSearch ติดตาม Hashes และดัชนีถูกย้ายออกจากคีย์สเปซ คุณจึงสามารถเรียกใช้ RediSearch ในฐานข้อมูลแบบกระจายทางภูมิศาสตร์แบบ Active-Active ได้
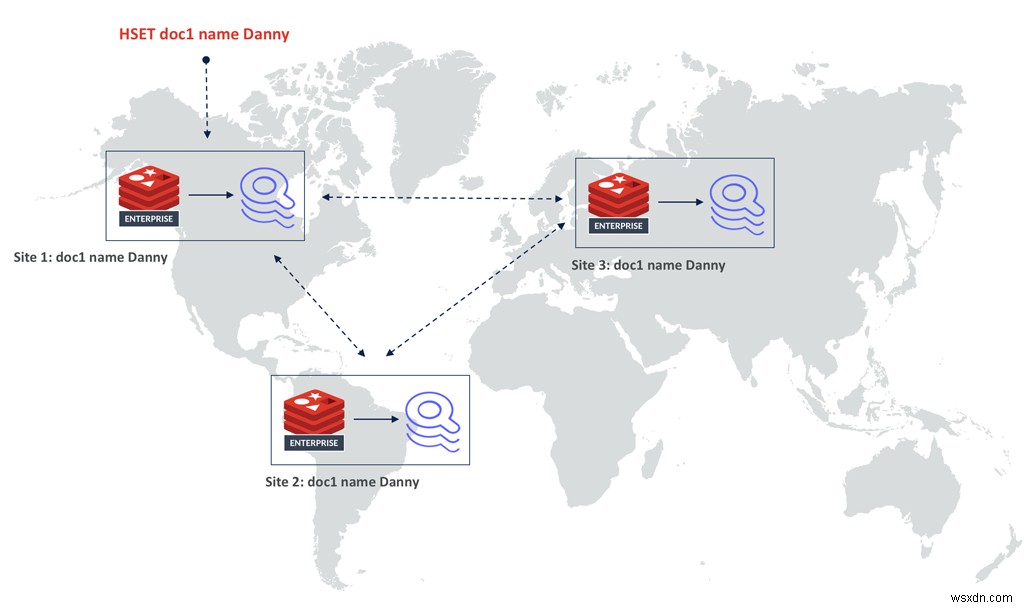
เอกสารจะถูกจำลองแบบไปยังฐานข้อมูลทั้งหมดในชุดการจำลองแบบในลักษณะที่สอดคล้องกันในที่สุด ในแต่ละแบบจำลอง RediSearch จะติดตามการอัปเดตทั้งหมดบนแฮช ซึ่งหมายความว่าดัชนีทั้งหมดมีความสอดคล้องอย่างยิ่งในท้ายที่สุดเช่นกัน
การสนับสนุนคลัสเตอร์ OSS สำหรับโอเพ่นซอร์ส Redis
เราไม่ต้องการจำกัดการเพิ่มความสามารถในการปรับขยายได้เฉพาะผู้ใช้ Redis Enterprise ดังนั้นเราจึงเพิ่มการสนับสนุนสำหรับการปรับขนาดดัชนีเดียวบนชาร์ดหลายรายการด้วย API คลัสเตอร์ Redis แบบโอเพนซอร์ส ก่อนหน้านี้ ดัชนี RediSearch เดียวและเอกสารของดัชนีต้องอยู่ในชาร์ดเดียว ซึ่งหมายความว่าขนาดชุดข้อมูลและปริมาณงานสำหรับ OSS Redis เชื่อมโยงกับกระบวนการ Redis เดียวที่สามารถจัดการได้ Redis Enterprise เสนอความสามารถในการแจกจ่ายเอกสารในฐานข้อมูลแบบคลัสเตอร์และรวมผลลัพธ์ในเวลาสืบค้น การกระจายและการรวมนี้ได้รับการจัดการโดยคอมโพเนนต์ที่เรียกว่า "ผู้ประสานงาน" ซึ่งขณะนี้ยังเผยแพร่ต่อสาธารณะภายใต้สิทธิ์ใช้งาน Redis Source Available License ดังนั้นจึงสามารถทำงานร่วมกับคลัสเตอร์ Redis แบบโอเพ่นซอร์สและ Redis Enterprise ผลลัพธ์ที่ได้คือ RediSearch เวอร์ชันที่ปรับขนาดได้มากที่สุด
แสดงตัวเลขให้ฉันดู!
ในการประเมินประสิทธิภาพการส่งผ่านข้อมูลของ RediSearch 2.0 เราได้ขยายชุดการวัดประสิทธิภาพการค้นหาข้อความแบบเต็ม (FTSB) ด้วยชุดข้อมูล NYC Taxi ที่เผยแพร่ต่อสาธารณะ ชุดข้อมูลนี้ถูกใช้ทั่วทั้งอุตสาหกรรมเนื่องจากชุดข้อมูลที่หลากหลาย (ข้อความ แท็ก ภูมิศาสตร์ และตัวเลข) และเอกสารจำนวนมาก
เกณฑ์มาตรฐานนี้มุ่งเน้นไปที่ประสิทธิภาพการเขียน โดยใช้ข้อมูลบันทึกการเดินทางของการโดยสารรถแท็กซี่สีเหลืองในนิวยอร์กซิตี้ โดยเฉพาะสำหรับการวัดประสิทธิภาพนี้ เราใช้ชุดข้อมูลเดือนมกราคม 2015 ซึ่งโหลดเอกสารมากกว่า 12 ล้านฉบับโดยมีขนาดเฉลี่ย 500 ไบต์ต่อเอกสาร สำหรับข้อกำหนดมาตรฐานฉบับสมบูรณ์ โปรดดู FTSB บน GitHub
รูปแบบการวัดประสิทธิภาพทั้งหมดทำงานบนอินสแตนซ์ Amazon Web Services ซึ่งจัดเตรียมผ่านโครงสร้างพื้นฐานการทดสอบเกณฑ์มาตรฐานของเรา การทดสอบดำเนินการบนคลัสเตอร์ 3 โหนดที่มีส่วนแบ่งข้อมูล 15 รายการ โดยมี RediSearch Enterprise เวอร์ชัน 1.6 และ 2.0 ทั้งไคลเอนต์การเปรียบเทียบและ 3 โหนดที่ประกอบด้วยฐานข้อมูลที่เปิดใช้งาน RediSearch กำลังทำงานบนอินสแตนซ์ c5.9xlarge แยกกัน
เนื่องจาก RediSearch 2.0 มาพร้อมกับความสามารถในการติดตามการเปลี่ยนแปลงในแฮชใน Redis และจัดทำดัชนีโดยอัตโนมัติ เราจึงได้เพิ่มตัวแปรสำหรับคำสั่ง FT.ADD และ HSET เพื่อให้การอัปเกรดง่ายขึ้น เราทำการรีแมปคำสั่ง FT.ADD ที่เลิกใช้แล้วในขณะนี้เป็นคำสั่ง HSET ใน RediSearch 2.0 แผนภูมิ 2 รายการด้านล่างแสดงอัตราการส่งผ่านข้อมูลโดยรวมและเวลาแฝงสำหรับทั้ง RediSearch 1.6 และ RediSearch 2.0 โดยคงเวลาแฝงในระดับย่อยเป็นมิลลิวินาทีไว้
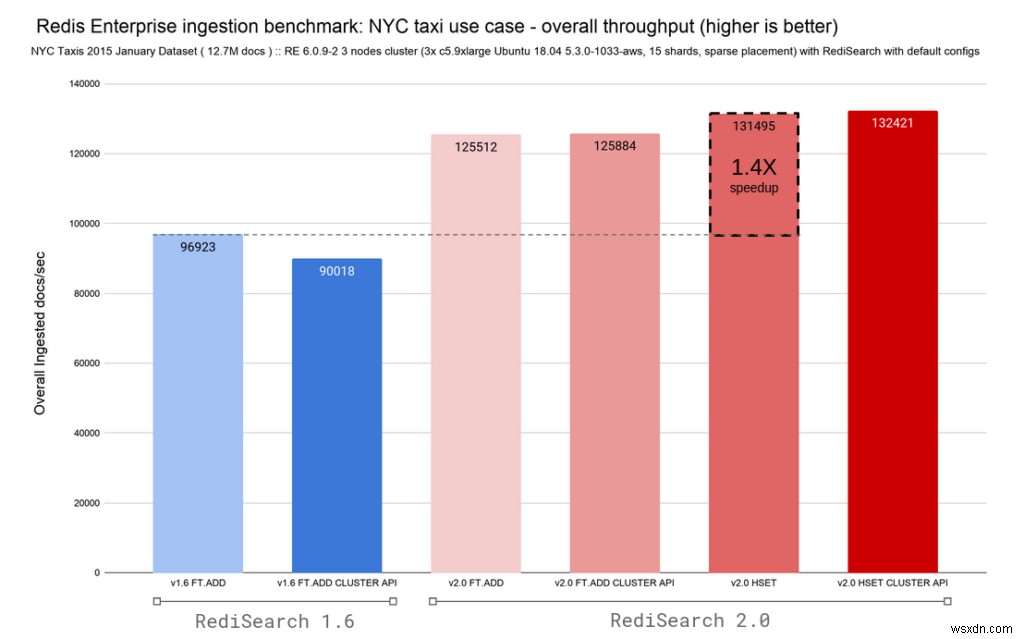
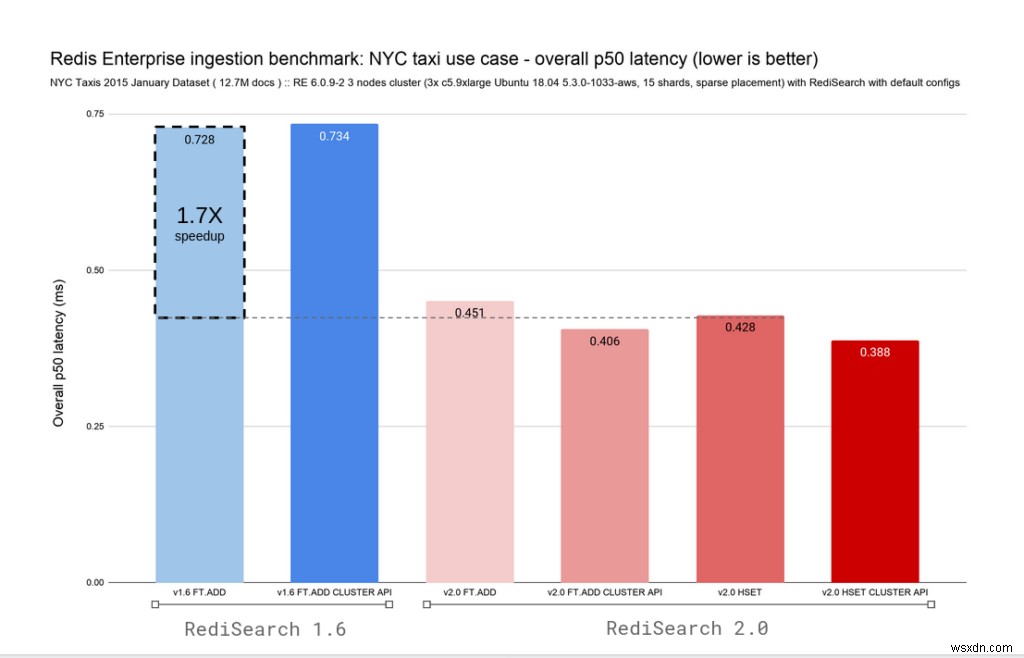
RediSearch นั้นรวดเร็วอยู่เสมอ แต่ด้วยการเปลี่ยนแปลงทางสถาปัตยกรรมนี้ เราได้ย้ายจากการจัดทำดัชนีเอกสาร 96K ต่อวินาทีเป็น 132K เอกสาร/วินาทีที่เวลาแฝงในการส่งผ่านข้อมูล p50 โดยรวมที่ 0.4ms ซึ่งช่วยปรับปรุงการปรับขนาดการเขียนได้อย่างมาก
ไม่เพียงแต่คุณจะได้รับประโยชน์จากการเพิ่มปริมาณงานเท่านั้น แต่การนำเข้าแต่ละครั้งยังเร็วขึ้นอีกด้วย นอกเหนือจากการปรับปรุงการนำเข้าโดยรวมอันเนื่องมาจากการเปลี่ยนแปลงในสถาปัตยกรรม ตอนนี้คุณยังสามารถพึ่งพาความสามารถของ OSS Redis Cluster API เพื่อปรับขนาดการนำเข้าฐานข้อมูลการค้นหาของคุณเป็นเส้นตรง
การผสมผสานระหว่างปริมาณงานและการปรับปรุงเวลาแฝง RediSearch 2.0 มอบความเร็ว 2.4 เท่า เทียบกับ RediSearch 1.6
สิ่งต่อไปสำหรับ RediSearch 2.0
โดยสรุปแล้ว RediSearch 2.0 เป็นเวอร์ชันที่เร็วและปรับขนาดได้มากที่สุดสำหรับผู้ใช้ Redis ทั้งหมดที่เราเคยเปิดตัว นอกจากนี้ สถาปัตยกรรมใหม่ของ RediSearch 2.0 ยังช่วยปรับปรุงประสบการณ์ของนักพัฒนาในการสร้างดัชนีสำหรับข้อมูลที่มีอยู่ภายใน Redis อย่างราบรื่น และไม่จำเป็นต้องย้ายข้อมูล Redis ของคุณไปยังฐานข้อมูลอื่นที่เปิดใช้งาน RediSearch สถาปัตยกรรมใหม่นี้ช่วยให้ RediSearch ติดตามและสร้างดัชนีโครงสร้างข้อมูลอื่นๆ โดยอัตโนมัติ เช่น สตรีมหรือสตริง ในรุ่นถัดไป จะช่วยให้คุณทำงานกับโครงสร้างข้อมูลเพิ่มเติม เช่น โครงสร้างข้อมูลที่ซ้อนกันใน RedisJSON
เราวางแผนที่จะเพิ่มคุณสมบัติต่อไปเพื่อปรับปรุงประสบการณ์ของนักพัฒนาต่อไป ต่อไป ให้มองหาคำสั่งใหม่ที่ช่วยให้คุณสร้างโปรไฟล์คำค้นหาของคุณเพื่อทำความเข้าใจได้ดีขึ้นว่าคอขวดของประสิทธิภาพเกิดขึ้นที่ใดระหว่างการดำเนินการค้นหา
พร้อมที่จะเริ่มต้นหรือยัง ดูบล็อกของ Tug Grall ใน … เริ่มต้นใช้งาน RediSearch 2.0! จากนั้นทำตามขั้นตอนในบทช่วยสอนนี้บน GitHub หรือสร้างฐานข้อมูลฟรีใน Redis Enterprise Cloud Essentials (โปรดทราบว่าการดูตัวอย่างสาธารณะของ RediSearch 2.0 มีให้บริการในภูมิภาค Redis Enterprise Cloud Essentials สองแห่ง ได้แก่ มุมไบและโอเรกอน)
