
- นี่คือความต่อเนื่องของบล็อกโพสต์ที่เผยแพร่ในเดือนเมษายน 2021
เราสร้างแอปพลิเคชันตัวอย่างที่เปรียบเทียบประสิทธิภาพของฐานข้อมูลแบบไร้เซิร์ฟเวอร์ชั้นนำโดยใช้กรณีการใช้งานเว็บทั่วไปและฟังก์ชันแบบไร้เซิร์ฟเวอร์ ฐานข้อมูล ได้แก่ DynamoDB, MongoDB (Atlas), Firestore, Cassandra (Datastax Astra), FaunaDB และ Redis (Upstash)
ตรวจสอบแอปพลิเคชันและซอร์สโค้ด
สิ่งที่เราเปรียบเทียบคือเวลาแฝงในการดึงบทความข่าว 10 อันดับแรกสำหรับแต่ละฐานข้อมูล ข้อมูลทั้งหมดเป็นบทความข่าวจริง 7001 ที่รวบรวมจาก New York Times API แบบสอบถามที่เราวัดซึ่งเวลาแฝงคือ:
select * from news where section = “World” order by view_count desc limit 10
แบ็กเอนด์ถูกนำไปใช้เป็นฟังก์ชันแบบไร้เซิร์ฟเวอร์บน AWS Lambda (ฟังก์ชัน Google Cloud สำหรับ Firestore) เราจัดวางฟังก์ชันแบบไร้เซิร์ฟเวอร์และฐานข้อมูลในภูมิภาคเดียวกัน (เมื่อเป็นไปได้) เพื่อลดเวลาในการตอบสนอง
เราไม่รวมเวลาเชื่อมต่อฐานข้อมูลจากการวัดเวลาแฝง และการประทับเวลาที่บันทึกไว้ก่อนและหลังการสืบค้น เวลาแฝงจะถูกวัดและบันทึกที่ส่วนหลัง (ภายในฟังก์ชันไร้เซิร์ฟเวอร์) ดังนั้นจึงไม่รวมเวลาแฝงของเครือข่ายระหว่างเบราว์เซอร์และเซิร์ฟเวอร์ นอกจากนี้ เวลาแฝงจะไม่ได้รับผลกระทบจากเวลาเริ่มเย็นของฟังก์ชันไร้เซิร์ฟเวอร์เช่นกัน
เพื่อจำลองข้อมูลโลกแห่งความเป็นจริงแบบไดนามิก เราได้กำหนดค่า view_count แบบสุ่มให้กับบทความ 10 อันดับแรก ดังนั้นทุกครั้งที่เราบังคับให้ฐานข้อมูลส่งคืนชุดบทความที่แตกต่างกัน เพื่อป้องกันไม่ให้ใช้แคช การดำเนินการอัปเดตจะไม่รวมอยู่ในการคำนวณเวลาแฝง
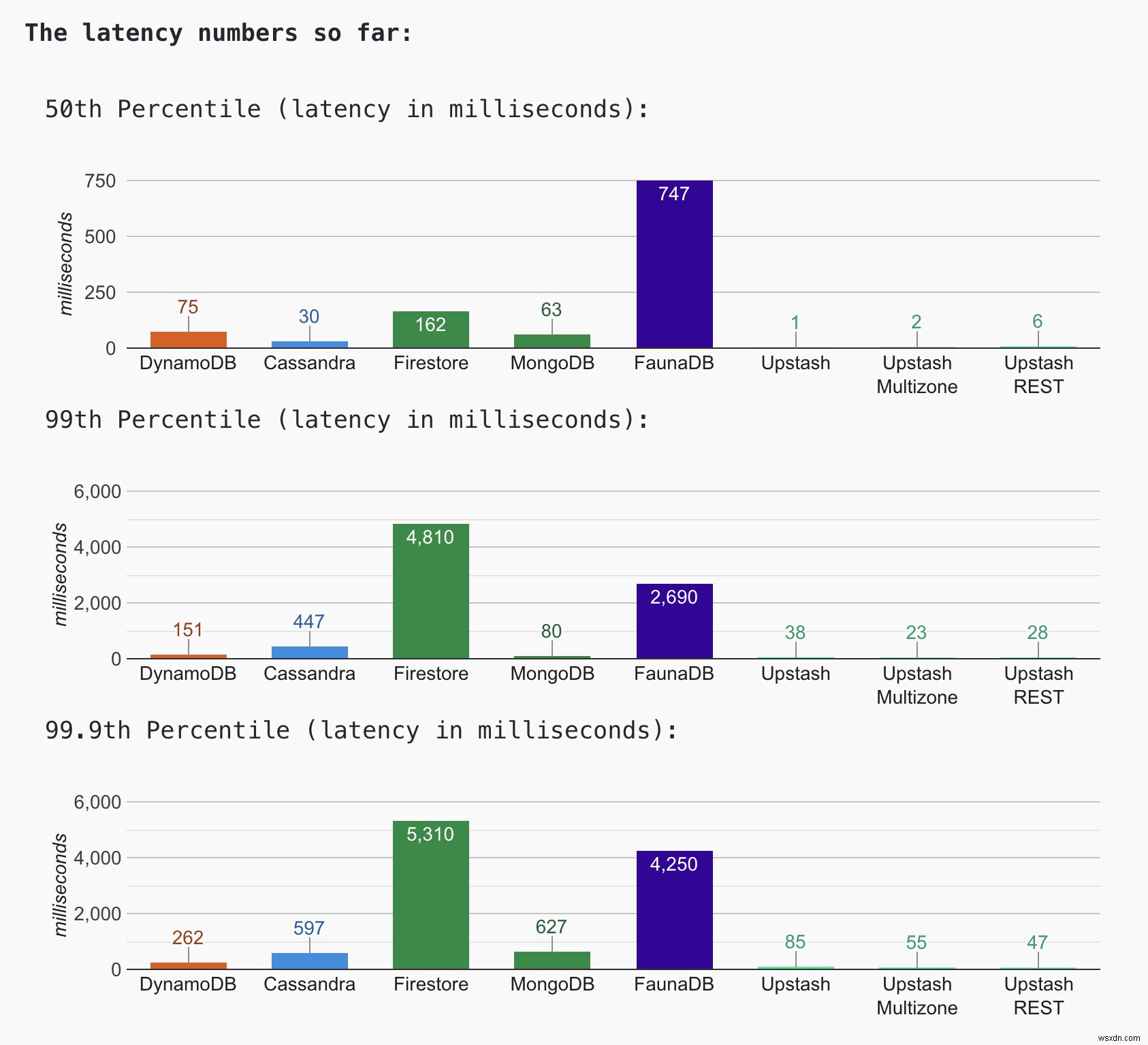
นี่คือตัวเลขเวลาในการตอบสนอง ณ วันนี้ (25 ส.ค.)
ด้านล่างนี้ ฉันจะแสดงรายการการกำหนดค่าแบบกำหนดเองที่ใช้กับแต่ละฐานข้อมูล:
DynamoDB
ภูมิภาค:US-West-1
ความสามารถในการอ่านและเขียน:50 (ค่าเริ่มต้นคือ 5)
ดัชนี:GSI พร้อมส่วนคีย์พาร์ติชั่น (สตริง) และคีย์การจัดเรียง view_count (หมายเลข)
หมายเหตุ:ตารางสากลไม่ได้เปิดใช้งานเนื่องจากไคลเอนต์อยู่ในภูมิภาคเดียวกันแล้ว (US-West-1)
ตรวจสอบรหัส
MongoDB (Atlas)
ภูมิภาค:AWS N. Virginia (us-east-1)
ระดับคลัสเตอร์:M5 (ทั่วไป)
ดัชนี:ดัชนีผสมในส่วนและจำนวนการดู
หมายเหตุ:ฉันหวังว่าฉันจะได้ลองใช้ MongoDB serverless เสนอ แต่ไม่มีไดรเวอร์ Node.js แต่ไม่น่าจะเป็นปัญหาเพราะฉันเก็บการเชื่อมต่อ db ไว้นอกส่วนที่คำนวณเวลาแฝง
ตรวจสอบรหัส
Firestore
ภูมิภาค:GCP US-Central
โหมด:ที่เก็บข้อมูล
ดัชนี:ดัชนีคอมโพสิตในส่วน (จากน้อยไปมาก) และ view_count (จากมากไปน้อย)
ตรวจสอบรหัส
คาสแซนดรา (Datastax Astra)
ภูมิภาค:AWS US-East-1
แผน:จ่ายตามที่คุณไป
ดัชนี:คีย์หลัก (ส่วน, view_count, id)
API:REST API
ตรวจสอบรหัส
FaunaDB
แผน:รายบุคคล ($25 ต่อเดือน)
ดัชนี:term=section,value=view_count
API:FQL
ตรวจสอบรหัส
เรดิส (อัพสแตช)
ภูมิภาค:AWS US-West-1
แผน:จ่ายตามที่คุณไป
ดัชนี:ใช้ SortedSet
หมายเหตุ:ฐานข้อมูลเดี่ยวและหลายโซนได้รับการทดสอบแยกกัน
ตรวจสอบรหัส
หมายเหตุพิเศษ
- FaunaDB มีการรับประกันความสอดคล้องที่ดีขึ้นและการจำลองแบบทั่วโลกโดยค่าเริ่มต้น นอกจากนี้ยังไม่อนุญาตให้คุณเลือกภูมิภาคที่จะปรับใช้ สิ่งเหล่านี้อาจเป็นสาเหตุของประสิทธิภาพที่ค่อนข้างต่ำ
- Firestore มีประสิทธิภาพคล้ายกับตัวอื่นๆ แต่มีความแปรปรวนมากกว่า อาจเป็นเพราะมีการเชื่อมต่อที่เย็นจัด ฉันไม่พบวิธีรักษาการเชื่อมต่อให้คงอยู่ แจ้งให้เราทราบหากคุณมีแนวคิดเกี่ยวกับเรื่องนี้
- คาสซานดราไม่อนุญาตให้อัปเดตฟิลด์คีย์หลัก ไม่แนะนำให้ใช้ดัชนีรองหากคุณจะอัปเดตดัชนีมาก ดังนั้นฉันจึงไม่สามารถอัปเดต view_count ซึ่งอาจส่งผลต่อประสิทธิภาพการทำงานในเชิงบวก
- แม้ว่า Upstash single zone จะดูเร็วกว่าเล็กน้อย แต่ก็ไม่มีความแตกต่างด้านประสิทธิภาพมากนักระหว่างการตั้งค่าโซนเดียวและหลายโซนสำหรับ Upstash REST API ดูเหมือนว่าจะมีประสิทธิภาพใกล้เคียงกับ Native API มากในเปอร์เซ็นไทล์ที่สูงกว่า
โปรดทราบว่านี่เป็นความพยายามอย่างต่อเนื่อง ดังนั้นเราจะดำเนินการสร้างโค้ดใหม่เพื่อปรับปรุงคุณภาพของเกณฑ์เปรียบเทียบ เมื่อเราปรับโครงสร้างรหัสของผลิตภัณฑ์ เราจะรีเซ็ตฮิสโตแกรมของรหัส โปรดตรวจสอบรหัสและแจ้งให้เราทราบหากมีสิ่งที่ต้องปรับปรุง คุณสามารถติดต่อเราได้ที่ twitter และ discord
