
ในบทความนี้ ฉันจะเปรียบเทียบเวลาแฝงของฐานข้อมูลไร้เซิร์ฟเวอร์สามตัว DynamoDB, FaunaDB, Upstash (Redis) สำหรับกรณีการใช้งานเว็บทั่วไป
ฉันสร้างเว็บไซต์ข่าวตัวอย่างและกำลังบันทึกเวลาแฝงที่เกี่ยวข้องกับฐานข้อมูลกับคำขอแต่ละรายการที่ส่งไปยังเว็บไซต์ ตรวจสอบเว็บไซต์และซอร์สโค้ด
ฉันได้แทรกบทความ 7001 NY Times ในแต่ละฐานข้อมูล บทความรวบรวมจาก New York Times Archive API (บทความทั้งหมดของเดือนมกราคม 2021) ฉันสุ่มคะแนนแต่ละบทความ ในแต่ละคำขอของหน้า ฉันค้นหาบทความ 10 อันดับแรกภายใต้ World จากแต่ละฐานข้อมูล
ฉันใช้ฟังก์ชันไร้เซิร์ฟเวอร์ (AWS Lambda) เพื่อโหลดบทความจากแต่ละฐานข้อมูล เวลาตอบสนองของการดึงบทความ 10 บทความจะถูกบันทึกเป็นเวลาแฝงภายในฟังก์ชันแลมบ์ดา โปรดทราบว่าเวลาแฝงที่บันทึกไว้เป็นเพียงระหว่างฟังก์ชันแลมบ์ดากับฐานข้อมูล ไม่ใช่เวลาแฝงระหว่างเบราว์เซอร์และเซิร์ฟเวอร์ของคุณ
หลังจากคำขออ่านแต่ละครั้ง ฉันจะอัปเดตคะแนนแบบสุ่มเพื่อจำลองข้อมูลแบบไดนามิก แต่ฉันแยกส่วนนี้ออกจากการคำนวณเวลาแฝง
ขั้นแรก เราจะตรวจสอบการใช้งาน จากนั้นเราจะดูผลลัพธ์:
การตั้งค่า AWS Lambda
ภูมิภาค:US-West-1
หน่วยความจำ:1024Mb
รันไทม์:nodejs14.x
การตั้งค่า DynamoDB
ฉันสร้างตาราง DynamoDB ใน US-West-1 ด้วยความสามารถในการอ่านและเขียน 50 (ค่าเริ่มต้นคือ 5)
ดัชนีของฉันคือ GSI พร้อมพาร์ทิชันคีย์ section (String) และคีย์การจัดเรียง view_count (Number) .
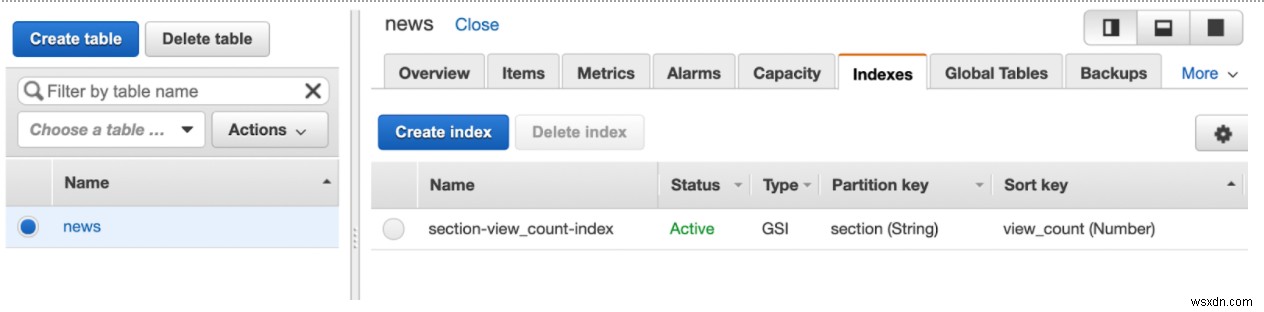
การตั้งค่า FaunaDB
FaunaDB เป็นฐานข้อมูลที่จำลองแบบทั่วโลก ไม่มีทางที่จะเลือกภูมิภาคได้ ฉันใช้ FQL โดยสมมติว่า GraphQL API อาจมีค่าใช้จ่าย
ฉันสร้างดัชนีด้วยส่วนเงื่อนไขและค่าอ้างอิงดังต่อไปนี้ ฉันทำให้มันไม่มีซีเรียลไลซ์โดยหวังว่าจะปรับปรุงประสิทธิภาพ
CreateIndex({
name: "section_by_view_count",
unique: false,
serialized: false,
source: Collection("news"),
terms: [
{ field: ["data", "section"] }
],
values: [
{ field: ["data", "view_count"], reverse: true },
{ field: ["ref"] }
]
})
ตั้งค่า Redis
ฉันสร้างฐานข้อมูลประเภทมาตรฐานในภูมิภาค US-West-1 ใน Upstash ฉันใช้ Sorted Set สำหรับแต่ละหมวดข่าว ดังนั้น World บทความข่าวจะอยู่ใน Sorted Set with key World .
เริ่มต้นฐานข้อมูล
ฉันดาวน์โหลดบทความข่าว 7001 เป็นไฟล์ JSON จากไซต์ NYTimes API จากนั้นจึงสร้างสคริปต์ NodeJS สำหรับแต่ละฐานข้อมูลที่อ่าน JSON และแทรกบันทึกข่าวลงในฐานข้อมูล ดูไฟล์:initDynamo.js, initFauna.js, initRedis.js
แบบสอบถาม DynamoDB
ฉันใช้ AWS SDK เพื่อเชื่อมต่อกับ DynamoDB เพื่อลดเวลาแฝง ฉันกำลังรักษาการเชื่อมต่อ DynamoDB ให้คงอยู่ ฉันใช้ perf_hooks ห้องสมุดเพื่อวัดเวลาตอบสนอง ฉันบันทึกเวลาปัจจุบันก่อนที่จะสอบถาม DynamoDB สำหรับบทความ 10 อันดับแรก ฉันคำนวณเวลาแฝงทันทีที่ได้รับการตอบสนองจาก DynamoDB จากนั้นฉันสุ่มให้คะแนนบทความและใส่หมายเลขเวลาแฝงไปยังชุดที่จัดเรียงของ Redis แต่ส่วนเหล่านี้อยู่นอกส่วนการคำนวณเวลาแฝง ดูรหัสด้านล่าง:
var AWS = require("aws-sdk");
AWS.config.update({
region: "us-west-1",
});
const https = require("https");
const agent = new https.Agent({
keepAlive: true,
maxSockets: Infinity,
});
AWS.config.update({
httpOptions: {
agent,
},
});
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const tableName = "news";
var params = {
TableName: tableName,
IndexName: "section-view_count-index",
KeyConditionExpression: "#sect = :section",
ExpressionAttributeNames: {
"#sect": "section",
},
ExpressionAttributeValues: {
":section": process.env.SECTION,
},
Limit: 10,
ScanIndexForward: false,
};
const docClient = new AWS.DynamoDB.DocumentClient();
module.exports.load = (event, context, callback) => {
let start = performance.now();
docClient.query(params, (err, result) => {
if (err) {
console.error(
"Unable to scan the table. Error JSON:",
JSON.stringify(err, null, 2)
);
} else {
// response is ready so we can set the latency
let latency = performance.now() - start;
let response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: result,
}),
};
// we are setting random score to top-10 items to simulate real time dynamic data
result.Items.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
var params2 = {
TableName: tableName,
Key: {
id: item.id,
},
UpdateExpression: "set view_count = :r",
ExpressionAttributeValues: {
":r": view_count,
},
};
docClient.update(params2, function (err, data) {
if (err) {
console.error(
"Unable to update item. Error JSON:",
JSON.stringify(err, null, 2)
);
}
});
});
// pushing the latency to the histogram
const client = new Redis(process.env.LATENCY_REDIS_URL);
client.lpush("histogram-dynamo", latency, (resp) => {
client.quit();
callback(null, response);
});
}
});
};
แบบสอบถาม FaunaDB
ฉันใช้ faunadb ห้องสมุดเพื่อเชื่อมต่อและสอบถาม FaunaDB ส่วนที่เหลือคล้ายกับโค้ด DynamoDB มาก เพื่อลดเวลาในการตอบสนอง ฉันกำลังรักษาการเชื่อมต่อ ฉันใช้ perf_hooks ห้องสมุดเพื่อวัดเวลาตอบสนอง ฉันบันทึกเวลาปัจจุบันก่อนที่จะสอบถาม FaunaDB สำหรับบทความ 10 อันดับแรก ฉันคำนวณเวลาแฝงทันทีที่ได้รับคำตอบจาก FaunaDB จากนั้นฉันสุ่มให้คะแนนบทความและส่งหมายเลขเวลาแฝงไปยังชุดที่จัดเรียงของ Redis แต่ส่วนเหล่านี้อยู่นอกส่วนการคำนวณเวลาแฝง ดูรหัสด้านล่าง:
const faunadb = require("faunadb");
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET,
keepAlive: true,
});
const section = process.env.SECTION;
module.exports.load = async (event) => {
let start = performance.now();
let ret = await client
.query(
// the below is Fauna API for "select from news where section = 'world' order by view_count limit 10"
q.Map(
q.Paginate(q.Match(q.Index("section_by_view_count"), section), {
size: 10,
}),
q.Lambda(["view_count", "X"], q.Get(q.Var("X")))
)
)
.catch((err) => console.error("Error: %s", err));
console.log(ret);
// response is ready so we can set the latency
let latency = performance.now() - start;
const rclient = new Redis(process.env.LATENCY_REDIS_URL);
await rclient.lpush("histogram-fauna", latency);
await rclient.quit();
let result = [];
for (let i = 0; i < ret.data.length; i++) {
result.push(ret.data[i].data);
}
// we are setting random scores to top-10 items asynchronously to simulate real time dynamic data
ret.data.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
client
.query(
q.Update(q.Ref(q.Collection("news"), item["ref"].id), {
data: { view_count },
})
)
.catch((err) => console.error("Error: %s", err));
});
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: result,
},
}),
};
};
การสืบค้นซ้ำ
ฉันใช้ ioredis ห้องสมุดเพื่อเชื่อมต่อและอ่านจาก Redis ใน Upstash ฉันใช้คำสั่ง ZREVRANGE เพื่อโหลดข้อมูลจาก Sorted Set เพื่อลดเวลาแฝง ฉันใช้การเชื่อมต่อซ้ำเพื่อสร้างไคลเอ็นต์ Redis นอกฟังก์ชัน เช่นเดียวกับ DynamoDB และ FaunaDB ฉันกำลังอัปเดตคะแนนและส่งหมายเลขเวลาแฝงไปยัง Redis DB อื่นสำหรับการคำนวณฮิสโตแกรม ดูรหัส:
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const client = new Redis(process.env.REDIS_URL);
module.exports.load = async (event) => {
let section = process.env.SECTION;
let start = performance.now();
let data = await client.zrevrange(section, 0, 9);
let items = [];
for (let i = 0; i < data.length; i++) {
items.push(JSON.parse(data[i]));
}
// response is ready so we can set the latency
let latency = performance.now() - start;
// we are setting random scores to top-10 items to simulate real time dynamic data
for (let i = 0; i < data.length; i++) {
let view_count = Math.floor(Math.random() * 1000);
await client.zadd(section, view_count, data[i]);
}
// await client.quit();
// pushing the latency to the histogram
const client2 = new Redis(process.env.LATENCY_REDIS_URL);
await client2.lpush("histogram-redis", latency);
await client2.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: items,
},
}),
};
};
การคำนวณฮิสโตแกรม
ฉันใช้ hdr-histogram-js ห้องสมุดเพื่อคำนวณฮิสโตแกรม นี่คือการใช้งาน js ของไลบรารี hdr-histogram ของ Gil Tene ดูโค้ดของฟังก์ชันแลมบ์ดาซึ่งรับตัวเลขแฝงและคำนวณฮิสโตแกรม
const Redis = require("ioredis");
const hdr = require("hdr-histogram-js");
module.exports.load = async (event) => {
const client = new Redis(process.env.LATENCY_REDIS_URL);
let dataRedis = await client.lrange("histogram-redis", 0, 10000);
let dataDynamo = await client.lrange("histogram-dynamo", 0, 10000);
let dataFauna = await client.lrange("histogram-fauna", 0, 10000);
const hredis = hdr.build();
const hdynamo = hdr.build();
const hfauna = hdr.build();
dataRedis.forEach((item) => {
hredis.recordValue(item);
});
dataDynamo.forEach((item) => {
hdynamo.recordValue(item);
});
dataFauna.forEach((item) => {
hfauna.recordValue(item);
});
await client.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify(
{
redis_min: hredis.minNonZeroValue,
dynamo_min: hdynamo.minNonZeroValue,
fauna_min: hfauna.minNonZeroValue,
redis_mean: hredis.mean,
dynamo_mean: hdynamo.mean,
fauna_mean: hfauna.mean,
redis_histogram: hredis,
dynamo_histogram: hdynamo,
fauna_histogram: hfauna,
},
null,
2
),
};
};
ผลลัพธ์
ตรวจสอบเว็บไซต์สำหรับผลลัพธ์ล่าสุด คุณยังสามารถเข้าถึงข้อมูลฮิสโตแกรมล่าสุดได้ ตราบใดที่เว็บไซต์ยังใช้งานได้ เราจะรวบรวมข้อมูลและอัปเดตฮิสโตแกรมต่อไป ผลลัพธ์ ณ วันนี้ (12 เมษายน 2021) แสดงให้เห็นว่า Upstash มีเวลาแฝงต่ำสุด (~50ms ที่เปอร์เซ็นไทล์ที่ 99) โดยที่ FaunaDB มีเวลาแฝงสูงสุด (~900ms ที่เปอร์เซ็นไทล์ที่ 99) DynamoDB มี (~200ms ที่เปอร์เซ็นไทล์ที่ 99)
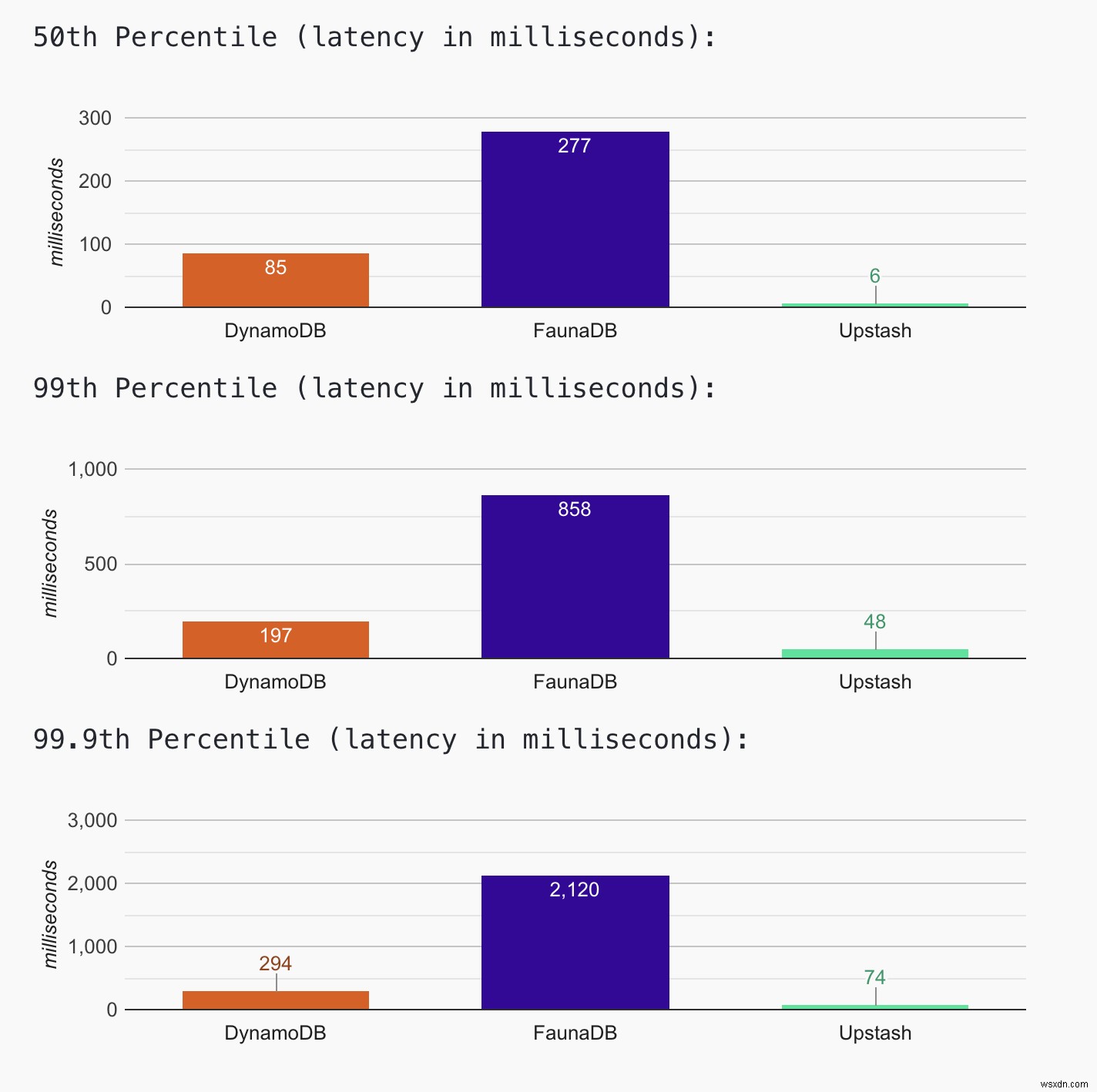
เอฟเฟกต์เริ่มเย็น
แม้ว่าเราจะวัดเวลาแฝงสำหรับส่วนการสืบค้นเท่านั้น แต่การเริ่มเย็นก็ยังมีผล เราปรับโค้ดของเราให้เหมาะสมโดยใช้การเชื่อมต่อไคลเอ็นต์ซ้ำ เราได้รับประโยชน์จากสิ่งนี้ตราบใดที่คอนเทนเนอร์แลมบ์ดายังร้อนและทำงานอยู่ เมื่อ AWS ฆ่าคอนเทนเนอร์ (cold start) โค้ดจะสร้างไคลเอนต์ขึ้นมาใหม่ นี่เป็นค่าใช้จ่าย ในเว็บไซต์แอปพลิเคชัน หากคุณรีเฟรชหน้า คุณจะเห็นตัวเลขแฝงลดลงเหลือ ~1ms สำหรับ Upstash; และ ~7ms สำหรับ DynamoDB
เหตุใด FaunaDB จึงช้า (ในเกณฑ์มาตรฐานนี้)
ในหน้าสถานะของ FaunaDB คุณจะเห็นตัวเลขแฝงเป็นร้อย ดังนั้นฉันคิดว่าการกำหนดค่าของฉันไม่มีข้อบกพร่องใหญ่ อาจมีสาเหตุสองประการที่อยู่เบื้องหลังความแตกต่างของเวลาในการตอบสนองนี้:
ความสม่ำเสมอที่แข็งแกร่ง: โดยค่าเริ่มต้น ทั้ง DynamoDB และ Upstash จะมีความสอดคล้องกันในที่สุดสำหรับการอ่าน FaunaDB ให้ความสม่ำเสมอและการแยกตัวที่แข็งแกร่งตาม Calvin ความสม่ำเสมอที่แข็งแกร่งมาพร้อมกับค่าใช้จ่ายด้านประสิทธิภาพ
การจำลองแบบทั่วโลก: สำหรับทั้ง Upstash และ DynamoDB เราสามารถกำหนดค่าฐานข้อมูลและฟังก์ชันแลมบ์ดาให้อยู่ในภูมิภาค AWS เดียวกันได้ ใน FaunaDB ข้อมูลของคุณจะถูกจำลองไปทั่วโลก ดังนั้นคุณจึงไม่มีตัวเลือกในการเลือกภูมิภาคของคุณ หากไคลเอนต์ฐานข้อมูลของคุณตั้งอยู่ทั่วโลก สิ่งนี้อาจเป็นข้อได้เปรียบ แต่หากคุณปรับใช้แบ็กเอนด์กับภูมิภาคใดภูมิภาคหนึ่ง จะทำให้เวลาในการตอบสนองเพิ่มขึ้น
Redis ให้เวลาแฝงในหน่วยมิลลิวินาที ทำไมมันไม่เป็นแบบนี้
การสร้างการเชื่อมต่อ Redis ใหม่ในฟังก์ชัน AWS Lambda ทำให้เกิดโอเวอร์เฮดที่โดดเด่น เนื่องจากแอปพลิเคชันไม่ได้รับการรับส่งข้อมูลที่เสถียร AWS Lambda จะสร้างการเชื่อมต่อขึ้นใหม่ (cold start) เกือบตลอดเวลา ดังนั้นตัวเลขแฝงส่วนใหญ่ในฮิสโตแกรมจึงรวมเวลาในการสร้างการเชื่อมต่อด้วย เราเรียกใช้งานที่ดึงข้อมูลเว็บไซต์ทุกๆ 15 วินาที; เราเห็นว่าเวลาแฝงสำหรับ Upstash ลดลงเหลือ ~1ms หากคุณรีเฟรชหน้า คุณจะเห็นเอฟเฟกต์ที่คล้ายกัน ดูบล็อกโพสต์ของเราสำหรับวิธีเพิ่มประสิทธิภาพแอปพลิเคชันแบบไร้เซิร์ฟเวอร์ของคุณสำหรับเวลาแฝงที่ต่ำ
เร็วๆ นี้
Upstash จะเปิดตัวผลิตภัณฑ์พรีเมียมในไม่ช้าซึ่งข้อมูลจะถูกจำลองไปยังโซนความพร้อมใช้งานหลายแห่ง ฉันจะเพิ่มเพื่อดูผลกระทบของการจำลองโซน
แจ้งให้เราทราบความคิดเห็นของคุณเกี่ยวกับ Twitter หรือ Discord
อัปเดต
มีการอภิปรายอย่างแข็งขันใน HackerNews เกี่ยวกับเกณฑ์มาตรฐานและประสิทธิภาพของ Fauna ของฉัน ฉันใช้คำแนะนำและเริ่มแอปพลิเคชัน FaunaDB ใหม่ ด้วยเหตุนี้ จำนวนระเบียน FaunaDB ในฮิสโตแกรมจึงน้อยกว่าจำนวนอื่นๆ
