
แอปพลิเคชันที่ขับเคลื่อนด้วย AI ที่ตอบสนองอย่างรวดเร็วช่วยปรับปรุงประสบการณ์ผู้ใช้โดยทำให้พวกเขารู้สึกว่าได้ยินและมองเห็นได้ในทันที ด้วยการสตรีม คุณสามารถสร้างแชทบอทที่ตอบคำถามได้ทันทีหรือให้คำแนะนำส่วนตัวแบบเรียลไทม์ ไม่ใช่แค่เรื่องความเร็วเท่านั้น แต่ยังเกี่ยวกับการตอบสนองความต้องการของผู้ใช้อย่างทันท่วงที เพื่อเพิ่มคุณค่าในการรับรู้
การสตรีมเกี่ยวข้องกับการส่งข้อมูลเป็นชิ้นเล็กๆ ต่อเนื่องกัน แทนที่จะเป็นบล็อกขนาดใหญ่บล็อกเดียว ในบริบทของแอปพลิเคชัน AI เช่น แชทบอทหรือระบบแนะนำ การสตรีมหมายถึงการส่งการตอบสนองบางส่วนไปยังผู้ใช้ทันทีที่พร้อมใช้งาน แทนที่จะรอเพื่อรวบรวมและส่งการตอบสนองทั้งหมดในครั้งเดียว แนวทางนี้ทำให้มั่นใจได้ว่าผู้ใช้จะได้รับคำติชมหรือข้อมูลทันที ซึ่งจะสร้างประสบการณ์ผู้ใช้ที่ไดนามิกและตอบสนองมากขึ้น
ในคู่มือนี้ คุณจะได้เรียนรู้วิธีใช้ประโยชน์จากเหตุการณ์ที่เซิร์ฟเวอร์ส่ง (SSE) เพื่อใช้งานการสตรีมในตำแหน่งข้อมูล Next.js ด้วยโมเดลภาษาของ LangChain และ OpenAI นอกจากนี้ คุณจะได้เรียนรู้วิธีแคชการตอบสนองแบบสตรีมด้วย Upstash
ข้อกำหนดเบื้องต้น
คุณจะต้องมีสิ่งต่อไปนี้:
- Node.js 18 หรือใหม่กว่า
- บัญชี OpenAI
- บัญชี Upstash
- บัญชี Vercel
กลุ่มเทคโนโลยี
สร้างโทเค็น OpenAI
เมื่อใช้ OpenAI API คุณสามารถสร้างการตอบกลับแชทบอทโดยใช้ AI ได้ คำขอใดๆ ไปยัง OpenAI API จำเป็นต้องมีโทเค็นการอนุญาต หากต้องการรับโทเค็น ให้ไปที่คีย์ API ในบัญชี OpenAI ของคุณ แล้วคลิก สร้างคีย์ลับใหม่ ปุ่ม คัดลอกและจัดเก็บโทเค็นนี้อย่างปลอดภัยเพื่อใช้ในภายหลังเป็น OPENAI_API_KEY ตัวแปรสภาพแวดล้อม
การตั้งค่า Upstash Redis
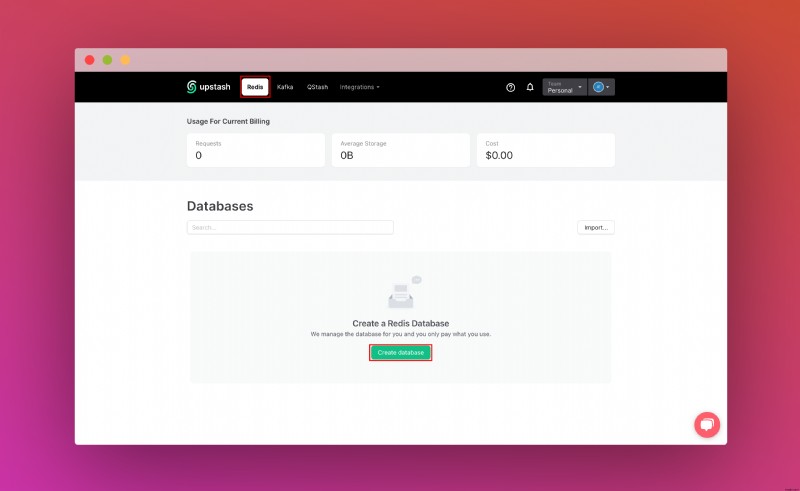
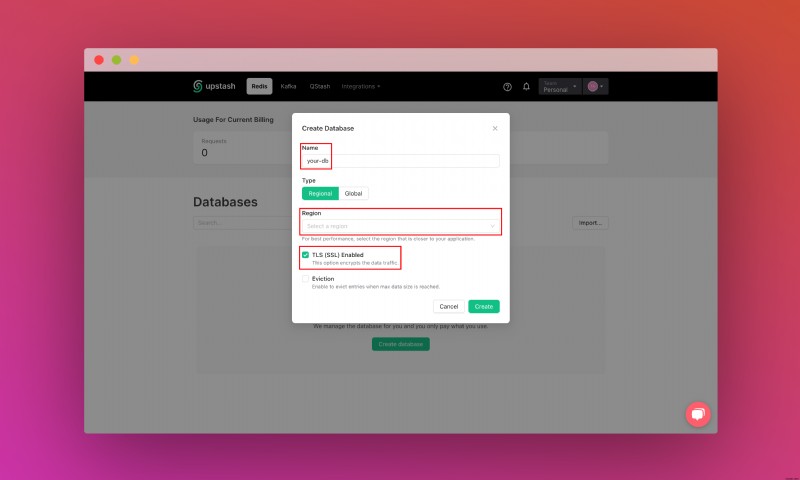
เมื่อคุณสร้างบัญชี Upstash และเข้าสู่ระบบแล้ว คุณจะไปที่แท็บ Redis และสร้างฐานข้อมูล
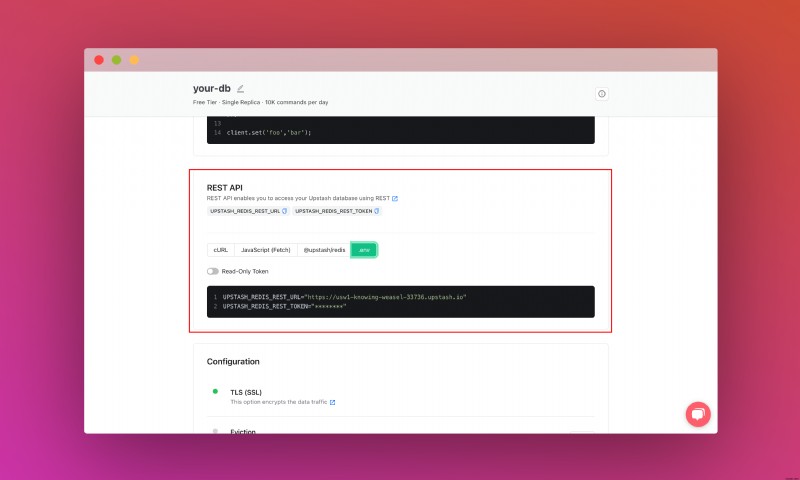
เลื่อนลงไปจนกว่าคุณจะพบส่วน REST API และเลือก 02 ปุ่ม คัดลอกเนื้อหาและบันทึกไว้ในที่ที่ปลอดภัย
สร้างแอปพลิเคชัน Next.js ใหม่
เริ่มต้นด้วยการสร้างโครงการ Next.js ใหม่ เปิดเทอร์มินัลของคุณและรันคำสั่งต่อไปนี้:
npx create-next-app@latest my-appเมื่อได้รับแจ้ง ให้เลือก:
18 เมื่อได้รับแจ้งให้ใช้ TypeScript21 เมื่อได้รับแจ้งให้ใช้ ESLint39 เมื่อได้รับแจ้งให้ใช้ Tailwind CSS49 เมื่อได้รับแจ้งให้ใช้54ไดเร็กทอรี62 เมื่อได้รับแจ้งให้ใช้ App Router72 เมื่อได้รับแจ้งให้ปรับแต่งนามแฝงการนำเข้าเริ่มต้น (80).
เมื่อเสร็จแล้ว ให้ย้ายไปยังไดเร็กทอรีโปรเจ็กต์และเริ่มแอปในโหมดการพัฒนาโดยดำเนินการคำสั่งต่อไปนี้:
cd my-app
npm run devแอปควรทำงานบน localhost:3000 หยุดเซิร์ฟเวอร์การพัฒนาเพื่อติดตั้งการพึ่งพา LangChain ในแอปพลิเคชันโดยดำเนินการคำสั่งต่อไปนี้:
npm install @langchain/openai @langchain/communityคำสั่งติดตั้งไลบรารีต่อไปนี้:
94 :แพ็คเกจ LangChain เพื่อเชื่อมต่อกับซีรีส์ OpenAI ของโมเดล103 :ชุดของการบูรณาการของบุคคลที่สามสำหรับ Plug-n-Play กับแกนหลักของ LangChain
ตอนนี้ สร้าง 118 ไฟล์ที่รากของโครงการของคุณ คุณจะเพิ่ม 122 คุณได้รับก่อนหน้านี้
มันควรมีลักษณะดังนี้:
# .env
# OpenAI Environment Variable
OPENAI_API_KEY="..."
# Upstash Redis Environment Variables
UPSTASH_REDIS_REST_URL="..."
UPSTASH_REDIS_REST_TOKEN="..."ในการสร้างตำแหน่งข้อมูล API ใน Next.js คุณจะต้องใช้ตัวจัดการเส้นทาง Next.js ซึ่งช่วยให้คุณสามารถตอบสนองผ่าน Web Request และ Response API หากต้องการเริ่มสร้างเส้นทาง API ใน Next.js ที่สตรีมการตอบกลับไปยังผู้ใช้ ให้ดำเนินการคำสั่งต่อไปนี้:
mkdir -p app/api/stream/completion/chat
mkdir app/lib
137 ธงสร้างไดเรกทอรีหลักสำหรับ 148 ไดเรกทอรีหากหายไป
นี่เป็นการตั้งค่าโครงการ Next.js ของเรา ตอนนี้ เรามาต่อกันที่การสร้างตัวจัดการแคชด้วย Upstash กัน
สร้างอินสแตนซ์ไคลเอ็นต์แคช Upstash Redis
ด้วย 157 คุณสามารถเริ่มต้นไคลเอนต์แคช Redis เพื่อแคชการตอบสนอง OpenAI API ได้ภายในโค้ดไม่กี่บรรทัด สร้างไฟล์ 169 ภายใน 170 ไดเรกทอรี:
การใช้ตัวจัดการแคชจะทำให้การแคชการสนทนาหรือการตอบกลับการเสร็จสิ้นที่สร้างโดย OpenAI API กลายเป็นเรื่องง่าย มาดูกันว่าคุณสามารถเริ่มใช้เหตุการณ์ที่เซิร์ฟเวอร์ส่งใน Next.js ได้อย่างไร
การสร้าง API เหตุการณ์ที่เซิร์ฟเวอร์ส่งในเราเตอร์แอป Next.js
เหตุการณ์ที่เซิร์ฟเวอร์ส่ง (SSE) ช่วยให้คุณสามารถส่งการอัปเดตข้อมูลแบบเรียลไทม์จากเซิร์ฟเวอร์ไปยังไคลเอนต์โดยไม่จำเป็นต้องทำการโพลอย่างต่อเนื่อง SSE ช่วยให้การไหลของข้อมูลในทิศทางเดียวผ่านการเชื่อมต่อ HTTP เดียวที่มีอายุการใช้งานยาวนาน
สร้างไฟล์ชื่อ 183 ด้วยรหัสต่อไปนี้ใน 197 ไดเร็กทอรีเพื่อทำความเข้าใจการตั้งค่าขั้นต่ำที่จำเป็นในการสตรีมการตอบกลับโดยใช้เหตุการณ์ที่เซิร์ฟเวอร์ส่ง:
// File: app/api/stream/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
export async function POST(request: Request) {
const encoder = new TextEncoder()
// Create a streaming response
const customReadable = new ReadableStream({
start(controller) {
const message = "A sample message."
controller.enqueue(encoder.encode(`data: ${message}\n\n`))
},
})
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
})
}โค้ดด้านบนทำหน้าที่ดังต่อไปนี้:
- ค่าคงที่ไดนามิกถูกตั้งค่าเป็น
207ป้องกันการแคชการตอบสนองบนแพลตฟอร์ม Vercel เพื่อให้แน่ใจว่าแต่ละคำขอสำหรับสตรีม SSE ได้รับข้อมูลใหม่และไม่ได้ให้บริการจากแคช - A
219 ถูกสร้างขึ้นเพื่อสร้างกระแสข้อมูลที่จะส่งไปยังไคลเอนต์ ในวิธีการเริ่มต้นของสตรีม ข้อความจะถูกเข้ารหัสและจัดคิวลงในตัวควบคุมของสตรีม ข้อความนี้จะถูกส่งไปยังไคลเอนต์โดยเป็นส่วนหนึ่งของสตรีม SSE 221วัตถุถูกสร้างขึ้นด้วยส่วนหัวเฉพาะสำหรับเหตุการณ์ที่เซิร์ฟเวอร์ส่ง ส่วนหัวเหล่านี้มีดังต่อไปนี้:230 เพื่อรักษาการเชื่อมต่อที่เปิดไว้สำหรับการสตรีม246 เพื่อป้องกันการแคชในเบราว์เซอร์259 เพื่อระบุประเภทเนื้อหาเป็นเหตุการณ์ที่เซิร์ฟเวอร์ส่ง
- ออบเจ็กต์การตอบสนองที่มี ReadableStream แบบกำหนดเองจะถูกส่งกลับจากจุดสิ้นสุด การตอบกลับนี้จะถูกส่งไปยังไคลเอนต์ที่ร้องขอสตรีม SSE
ด้วยเหตุนี้ คุณจึงได้สร้างอุปกรณ์ปลายทางที่สามารถสตรีมการตอบกลับได้ ในส่วนถัดไป คุณจะเข้าใจวิธีที่คุณสามารถสตรีมการตอบสนองของ Completion และ Chat Completion API จาก OpenAI ด้วยการเรียกกลับของ LangChain
การสตรีมการตอบสนองของ OpenAI Completion API ด้วย LangChain Callbacks
OpenAI Completion API มอบเครื่องมืออันทรงพลังสำหรับการสร้างข้อความตามข้อความแจ้งที่กำหนด ซึ่งมีประโยชน์ในสถานการณ์จริงต่างๆ เช่น การสร้างเนื้อหาและการแปลภาษา การรวมการโทรกลับของ LangChain ช่วยให้สามารถสตรีมการตอบสนองแบบเรียลไทม์ เพิ่มการตอบสนองในการรับรู้ในแอปพลิเคชัน
สร้างไฟล์ชื่อ 262 ใน 276 ไดเร็กทอรี ซึ่งกำหนดฟังก์ชันที่เริ่มต้นอินสแตนซ์ OpenAI โดยเปิดใช้งานการสตรีมและการเรียกกลับของ LangChain สร้างข้อความแบบเรียลไทม์
// File: app/lib/completionModel.tsx
import { OpenAI } from "@langchain/openai";
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});โค้ดด้านบนทำหน้าที่ดังต่อไปนี้:
- นำเข้า
280คลาสจาก299แพ็คเกจ - ส่งออกฟังก์ชันชื่อ
307ซึ่งรับสองพารามิเตอร์:- ตัวควบคุม:A
313ออบเจ็กต์ที่ช่วยให้คุณสามารถจัดคิวข้อความลงในสตรีมได้ - ตัวเข้ารหัส:A
324วัตถุที่เข้ารหัสข้อความเป็น335วัตถุ
- ตัวควบคุม:A
- สร้างอินสแตนซ์ใหม่ของ
344คลาสที่มีตัวเลือกการกำหนดค่าต่อไปนี้:355 :ตั้งค่าเป็นจริง ซึ่งบ่งชี้ว่า API ควรส่งคืนการตอบสนองแบบสตรีม362 :อาร์เรย์ที่มีออบเจ็กต์เดียวที่มีฟังก์ชันเรียกกลับสองฟังก์ชัน ใช้เพื่อสกัดกั้นการสร้างการตอบสนองโดย LLM ในแต่ละขั้นตอน
371 :การเรียกกลับจะถูกเรียกใช้เมื่อมีการสร้างโทเค็นใหม่โดยโมเดลภาษา โดยจะจัดคิวโทเค็นที่เข้ารหัสไว้กับคอนโทรลเลอร์382 :การเรียกกลับแบบอะซิงโครนัสจะถูกเรียกใช้เมื่อการสร้างโมเดลภาษาเสร็จสมบูรณ์ มันจะปิดคอนโทรลเลอร์
นอกจากนี้ ให้สร้างไฟล์ชื่อ 398 ด้วยรหัสต่อไปนี้ใน 401 ไดเรกทอรี การเปลี่ยนแปลงจากตัวจัดการเส้นทางสตรีมมิ่งเริ่มต้นที่คุณสร้างขึ้นได้รับการเน้นไว้ด้านล่าง:
// File: app/api/stream/completion/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import { completionModel } from "@/app/lib/completionModel";
export async function POST(request: Request) {
+ // Obtain the user message from request's body
+ const { message } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await completionModel(controller, encoder).invoke(message);
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}นอกเหนือจากสิ่งที่คุณทำก่อนหน้านี้เพื่อสร้างจุดสิ้นสุดการสตรีมใน Next.js แล้ว การเพิ่มโค้ดด้านบนยังทำสิ่งต่อไปนี้:
- นำเข้า
411ฟังก์ชั่น - แยกข้อความผู้ใช้ออกจากเนื้อหาคำขอโดยใช้
424. - ภายใน
434วิธีการของ ReadableStream445ฟังก์ชั่นถูกเรียกใช้แบบอะซิงโครนัสกับข้อความที่ได้รับจากการร้องขอ ฟังก์ชันนี้สร้างการตอบสนองแบบสตรีมจาก OpenAI ด้วย LangChain
หากต้องการแคชคำถามของผู้ใช้และการตอบกลับด้วย Upstash ให้นำเข้าไคลเอ็นต์แคช Upstash Redis ลงใน 453 ฟังก์ชันดังต่อไปนี้:
import { OpenAI } from "@langchain/openai";
+ import cache from '@/app/lib/upstashCache';
export const completionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new OpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});ด้วยการเปลี่ยนแปลงเพียงเล็กน้อย คุณได้เปิดใช้งานการแคชของการตอบสนอง OpenAI Completion API ด้วย Upstash แล้ว
ตอนนี้ เรามาเรียนรู้วิธีการสตรีมการตอบสนองของ OpenAI Chat Completion API บนอุปกรณ์ปลายทาง Next.js กันดีกว่า
การสตรีมการตอบสนองของ OpenAI Chat Completion API ด้วย LangChain Callbacks
OpenAI Chat Completion API มอบเครื่องมืออันทรงพลังสำหรับสร้างการตอบกลับการสนทนาแบบเรียลไทม์ตามข้อความที่ให้ไว้ แอปพลิเคชันครอบคลุมตั้งแต่การสร้างแชทบอทที่สามารถมีส่วนร่วมในการสนทนาที่เป็นธรรมชาติ ไปจนถึงการเพิ่มประสิทธิภาพระบบสนับสนุนลูกค้าด้วยความสามารถในการโต้ตอบที่ขับเคลื่อนด้วย AI ช่วยให้นักพัฒนาสามารถสร้างอินเทอร์เฟซการสนทนาแบบไดนามิกและตอบสนองได้
สร้างไฟล์ชื่อ 468 ใน 471 ไดเรกทอรี กำหนด 480 ฟังก์ชันที่สร้างอินเทอร์เฟซการสตรีมสำหรับ Chat Completion API ของ OpenAI พร้อมการโทรกลับของ LangChain อำนวยความสะดวกในการสร้างการสนทนาแบบเรียลไทม์ตามข้อความที่ให้ไว้
// File: app/lib/chatCompletionModel.tsx
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
streaming: true,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(`data: ${token}\n\n`));
},
async handleLLMEnd(output) {
controller.close();
},
},
],
});โค้ดด้านบนทำหน้าที่ดังต่อไปนี้:
- นำเข้า
497คลาสจาก503แพ็คเกจ - สร้างคำจำกัดความประเภทต่อไปนี้:
514 :กำหนดประเภทของข้อความเดียวในการสนทนา ประกอบด้วยสองคุณสมบัติ:บทบาท (ระบุบทบาทของผู้ส่ง) และเนื้อหา (เนื้อหาข้อความ)527 :กำหนดประเภทของอาร์เรย์ของข้อความการสนทนา
- ส่งออกฟังก์ชันชื่อ
533ซึ่งรับสองพารามิเตอร์:- ตัวควบคุม:A
544ออบเจ็กต์ที่ช่วยให้คุณสามารถจัดคิวข้อความลงในสตรีมได้ - ตัวเข้ารหัส:A
557วัตถุที่เข้ารหัสข้อความเป็น568วัตถุ
- ตัวควบคุม:A
- สร้างอินสแตนซ์ใหม่ของ
573คลาสที่มีตัวเลือกการกำหนดค่าต่อไปนี้:585 :ตั้งค่าเป็นจริง ซึ่งบ่งชี้ว่า API ควรส่งคืนการตอบสนองแบบสตรีม593 :อาร์เรย์ที่มีออบเจ็กต์เดียวที่มีฟังก์ชันเรียกกลับสองฟังก์ชัน ใช้เพื่อสกัดกั้นการสร้างการตอบสนองโดย LLM ในแต่ละขั้นตอน
600 :การเรียกกลับจะถูกเรียกใช้เมื่อมีการสร้างโทเค็นใหม่โดยโมเดลภาษา โดยจะจัดคิวโทเค็นที่เข้ารหัสไว้กับคอนโทรลเลอร์615 :การเรียกกลับแบบอะซิงโครนัสจะถูกเรียกใช้เมื่อการสร้างโมเดลภาษาเสร็จสมบูรณ์ มันจะปิดคอนโทรลเลอร์
นอกจากนี้ ให้สร้างไฟล์ชื่อ 620 ด้วยรหัสต่อไปนี้ใน 639 ไดเรกทอรี การเปลี่ยนแปลงจากตัวจัดการเส้นทางสตรีมมิ่งเริ่มต้นที่คุณสร้างขึ้นได้รับการเน้นไว้ด้านล่าง:
// File: app/api/stream/completion/chat/route.ts
// Prevents this route's response from being cached on Vercel
export const dynamic = "force-dynamic";
+ import {
+ type ConversationMessage,
+ chatCompletionModel,
+ } from "@/app/lib/chatCompletionModel";
export async function POST(request: Request) {
+ // Obtain the conversation messages from request's body
+ const { messages = [] } = await request.json();
const encoder = new TextEncoder();
// Create a streaming response
const customReadable = new ReadableStream({
async start(controller) {
+ // Generate a streaming response from OpenAI with LangChain
+ await chatCompletionModel(controller, encoder).invoke(
+ messages.map((i: ConversationMessage) => [i["role"], i["content"]])
+ );
},
});
// Return the stream response and keep the connection alive
return new Response(customReadable, {
// Set the headers for Server-Sent Events (SSE)
headers: {
Connection: "keep-alive",
"Content-Encoding": "none",
"Cache-Control": "no-cache, no-transform",
"Content-Type": "text/event-stream; charset=utf-8",
},
});
}นอกเหนือจากสิ่งที่คุณทำก่อนหน้านี้เพื่อสร้างจุดสิ้นสุดการสตรีมใน Next.js แล้ว การเพิ่มโค้ดด้านบนยังทำสิ่งต่อไปนี้:
- นำเข้า
645ฟังก์ชั่นและ651คำจำกัดความของประเภท - แยกข้อความในการสนทนาออกจากเนื้อหาคำขอโดยใช้
665. - ภายใน
672วิธีการของ ReadableStream683ฟังก์ชันถูกเรียกใช้แบบอะซิงโครนัสหลังจากอาร์เรย์ข้อความที่แปลงแล้ว แต่ละข้อความจะถูกแปลงเป็นอาร์เรย์ที่มีบทบาทและเนื้อหาของข้อความ ฟังก์ชันนี้สร้างการตอบสนองแบบสตรีมจาก OpenAI ด้วย LangChain
หากต้องการแคชประวัติการแชทด้วย Upstash ให้นำเข้าไคลเอ็นต์แคช Upstash Redis ลงใน 698 ฟังก์ชันดังต่อไปนี้:
+ import cache from '@/app/lib/upstashCache';
import { ChatOpenAI } from "@langchain/openai";
export type ConversationMessage = {
role: string;
content: string;
};
export type ConversationMessages = ConversationMessage[];
export const chatCompletionModel = (
controller: ReadableStreamDefaultController,
encoder: TextEncoder
) =>
new ChatOpenAI({
+ cache,
streaming: true,
temperature: 0.9,
callbacks: [
{
handleLLMNewToken(token) {
controller.enqueue(encoder.encode(token));
},
async handleLLMEnd(output) {
console.log(output.generations[0][0].text);
controller.close();
},
},
],
});ด้วยการเปลี่ยนแปลงเพียงเล็กน้อย คุณได้เปิดใช้งานการแคชประวัติการแชททั้งหมดด้วย Upstash
ตอนนี้ เรามาต่อกันที่การสร้างส่วนประกอบ React ฝั่งไคลเอ็นต์เพื่อใช้จุดสิ้นสุดการสตรีม
ตั้งค่าส่วนหน้า Next.js เพื่อฟังเหตุการณ์ที่เซิร์ฟเวอร์ส่ง
ในส่วนนี้ คุณจะได้เรียนรู้วิธีตั้งค่าผู้ฟังขั้นต่ำสำหรับข้อความ API เหตุการณ์ที่เซิร์ฟเวอร์ส่ง และวิธีการจัดการสถานะของข้อความที่แลกเปลี่ยนระหว่างผู้ใช้และ AI
การฟัง API เหตุการณ์ที่เซิร์ฟเวอร์ส่งใน React
หากต้องการฟัง SSE API ในส่วนประกอบฝั่งไคลเอ็นต์ของเราใน React คุณจะต้องเริ่มต้นคำขอ POST ไปยังเส้นทาง API ที่ระบุ เมื่อได้รับการตอบกลับ คุณจะต้องถอดรหัสข้อมูลที่เข้ามาเป็นสตริงโดยใช้ 703 และอ่านข้อมูลจากสตรีมอย่างต่อเนื่อง
"use client";
export default function () {
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) {
break;
}
if (value) {
// Do something
}
}
};
return <></>
}การจัดการสถานะของการสนทนาใน React
ในการจัดการสถานะของการสนทนาระหว่างผู้ใช้และแชทบอท คุณสามารถใช้ตัวแปรสถานะได้ คุณจะต้องอัปเดตตัวแปรสถานะ 715 และ 724 เพื่อจัดเก็บประวัติการสนทนาและข้อความล่าสุดตามลำดับ ด้วยการอัปเดตตัวแปรสถานะเหล่านี้ภายในลูปที่ประมวลผลข้อมูลขาเข้าจาก SSE API คุณสามารถรับประกันการอัปเดตแบบเรียลไทม์ของการแสดงการสนทนา การเพิ่มโค้ดเพื่อให้บรรลุสิ่งเดียวกันมีดังนี้:
"use client";
+ import { useEffect, useState } from "react";
+ import { ConversationMessages } from "@/app/lib/chatCompletionModel";
export default function () {
+ const [latestMessage, setLatestMessage] = useState<string>("");
+ const [messages, setMessages] = useState<ConversationMessages>([]);
const obtainAPIResponse = async (apiRoute: string, apiData: any) => {
// Initiate the first call to connect to SSE API
const apiResponse = await fetch(apiRoute, {
method: "POST",
headers: {
"Content-Type": "text/event-stream",
},
body: JSON.stringify(apiData),
});
if (!apiResponse.body) return;
// To decode incoming data as a string
const reader = apiResponse.body
.pipeThrough(new TextDecoderStream())
.getReader();
+ let incomingMessage = "";
while (true) {
const { value, done } = await reader.read();
if (done) {
+ // Insert the response received into the messages state
+ setMessages((messages) => [
+ ...messages,
+ { role: "assistant", content: incomingMessage },
+ ]);
+ // Reset the latest message's state received
+ setLatestMessage("");
break;
}
if (value) {
+ // Append the incoming data to latest message's value
+ incomingMessage += value;
+ setLatestMessage(incomingMessage);
}
}
};
return <></>
}การเพิ่มโค้ดด้านบนมีดังต่อไปนี้:
- มีการประกาศตัวแปรสถานะเพื่อจัดเก็บสตรีมข้อมูลขาเข้าที่ได้รับจาก SSE API
- เมื่อได้รับข้อความที่สมบูรณ์ (ระบุโดย
737หากเป็นจริง) ข้อความที่ได้รับล่าสุดจะถูกเพิ่มไปที่747อาร์เรย์ของรัฐ ข้อความนี้จัดรูปแบบด้วยบทบาทของผู้ช่วย เพื่อแยกความแตกต่างจากข้อความของผู้ใช้ นอกจากนี้ สถานะข้อความล่าสุดจะถูกรีเซ็ตเป็นสตริงว่างเพื่อเตรียมพร้อมสำหรับข้อความขาเข้าถัดไป - เนื่องจากข้อมูลได้รับเพิ่มขึ้นเรื่อยๆ (ยังไม่สร้างข้อความที่สมบูรณ์) ข้อมูลจึงถูกผนวกเข้ากับ
751ตัวแปร - สถานะข้อความล่าสุดได้รับการอัปเดตด้วยข้อมูลขาเข้าที่ต่อกัน ทำให้มั่นใจได้ว่าจะอัปเดตแบบเรียลไทม์เมื่อมีข้อมูลใหม่เข้ามา
เยี่ยมมาก! ด้วยปฏิกิริยา 765 และ 770 ตัวแปร ตอนนี้คุณสามารถสร้างอินเทอร์เฟซผู้ใช้แบบไดนามิกที่แสดงถึงข้อความที่แลกเปลี่ยนในการสนทนาและการตอบกลับที่ AI สร้างขึ้นล่าสุด
นั่นเป็นการเรียนรู้มากมาย! คุณทำเสร็จแล้วตอนนี้ ✨
ปรับใช้กับ Vercel
ขณะนี้พื้นที่เก็บข้อมูลพร้อมที่จะปรับใช้กับ Vercel แล้ว ใช้ขั้นตอนต่อไปนี้เพื่อปรับใช้:
- เริ่มต้นด้วยการสร้างพื้นที่เก็บข้อมูล GitHub ที่มีโค้ดของแอปของคุณ
- จากนั้น ไปที่แดชบอร์ด Vercel และสร้างโครงการใหม่ .
- เชื่อมโยงโปรเจ็กต์ใหม่กับที่เก็บ GitHub ที่คุณเพิ่งสร้างขึ้น
- ในการตั้งค่า ให้อัปเดต ตัวแปรสภาพแวดล้อม เพื่อให้ตรงกับที่อยู่ใน
788ในพื้นที่ของคุณ ไฟล์ - ปรับใช้! 🚀
ข้อมูลเพิ่มเติม
หากต้องการข้อมูลเชิงลึกโดยละเอียดเพิ่มเติม โปรดสำรวจข้อมูลอ้างอิงที่อ้างถึงในโพสต์นี้
- พื้นที่เก็บข้อมูล GitHub
- กิจกรรมที่เซิร์ฟเวอร์ส่ง
- สตรีมมิ่ง Next.js
- แคชเลเยอร์สำหรับ LLM
