
บทนำ
- แพลตฟอร์มการแบ่งส่วนมีบทบาทสำคัญในการทำความเข้าใจและจัดหมวดหมู่ลูกค้า ผลิตภัณฑ์ และข้อมูลอื่น ๆ ที่เกี่ยวข้อง
- การแบ่งส่วนเกี่ยวข้องกับการแบ่งกลุ่มใหญ่ออกเป็นกลุ่มย่อยที่มีขนาดเล็กลงและเป็นเนื้อเดียวกันมากขึ้นตามเกณฑ์ที่กำหนด
- ต่อไปนี้คือตัวอย่างบางส่วนของแพลตฟอร์มการแบ่งส่วนในโดเมนที่แตกต่างกัน เช่น การแบ่งส่วนลูกค้าสำหรับกลยุทธ์การตลาดส่วนบุคคล โปรโมชั่นที่ตรงเป้าหมาย และประสบการณ์การช็อปปิ้งที่กำหนดเองมากขึ้น
สารบัญ
- ทำความเข้าใจข้อกำหนด
- สถาปัตยกรรมพื้นฐาน
- ส่วนประกอบทางสถาปัตยกรรม
- ความท้าทายด้านการออกแบบ
- แนวทางแก้ไขที่เสนอ
- บันทึกการปิดท้าย
1. การทำความเข้าใจข้อกำหนด
การออกแบบแพลตฟอร์มการแบ่งส่วนเวลาแฝงต่ำสำหรับกลุ่มลูกค้าในอีคอมเมิร์ซทำให้เกิดความท้าทายเฉพาะที่เกี่ยวข้องกับการประมวลผลแบบเรียลไทม์ ประสบการณ์ผู้ใช้ และลักษณะแบบไดนามิกของพฤติกรรมของลูกค้า ต่อไปนี้เป็นความท้าทายบางประการที่คุณอาจพบในบริบทนี้:
-
ชุดข้อมูลขนาดใหญ่และไดนามิก
- แพลตฟอร์มอีคอมเมิร์ซจัดการกับชุดข้อมูลขนาดใหญ่และเปลี่ยนแปลงตลอดเวลา รวมถึงโปรไฟล์ลูกค้า แค็ตตาล็อกผลิตภัณฑ์ และประวัติการทำธุรกรรม
- การจัดการและประมวลผลชุดข้อมูลจำนวนมหาศาลเหล่านี้แบบเรียลไทม์โดยยังคงรักษาเวลาแฝงไว้ต่ำถือเป็นความท้าทายที่สำคัญ
-
ความสามารถในการขยายขนาด
- การออกแบบเพื่อความสามารถในการปรับขนาดถือเป็นสิ่งสำคัญในการจัดการกับปริมาณงานที่แตกต่างกัน การตรวจสอบให้แน่ใจว่าระบบสามารถปรับขนาดในแนวนอนโดยการเพิ่มหน่วยประมวลผลมากขึ้นโดยไม่สูญเสียเวลาแฝง จำเป็นต้องมีการวางแผนสถาปัตยกรรมอย่างรอบคอบ
-
การประมวลผลแบบอะซิงโครนัส
- การใช้ประโยชน์จากการประมวลผลแบบอะซิงโครนัสสามารถช่วยแยกส่วนประกอบและปรับปรุงการตอบสนองของระบบโดยรวม อย่างไรก็ตาม การจัดการการสื่อสารแบบอะซิงโครนัสโดยไม่ทำให้เกิดความซับซ้อนหรือความล่าช้าจำเป็นต้องมีการออกแบบอย่างระมัดระวัง
-
กระแสข้อมูลและไปป์ไลน์
- การออกแบบกระแสข้อมูลและไปป์ไลน์การประมวลผลที่มีประสิทธิภาพเป็นสิ่งสำคัญสำหรับระบบที่มีเวลาแฝงต่ำ
- การลดเวลาที่ใช้ในการถ่ายโอนข้อมูลระหว่างส่วนประกอบต่างๆ และการเพิ่มประสิทธิภาพลำดับขั้นตอนการประมวลผลอาจส่งผลกระทบอย่างมากต่อเวลาแฝงโดยรวม
-
สถาปัตยกรรมไมโครเซอร์วิส
- การนำสถาปัตยกรรมไมโครเซอร์วิสไปใช้สามารถเพิ่มความสามารถในการขยายขนาดและความยืดหยุ่นได้ อย่างไรก็ตาม การรับรองว่าการสื่อสารที่ราบรื่นระหว่างไมโครเซอร์วิสโดยไม่เพิ่มเวลาในการตอบสนองอาจเป็นเรื่องที่ท้าทาย
- การออกแบบ API ที่มีประสิทธิภาพและการจัดการการสื่อสารระหว่างบริการถือเป็นสิ่งสำคัญ
2. สถาปัตยกรรมพื้นฐาน
แพลตฟอร์มการแบ่งส่วนประกอบด้วยสามระบบย่อยหลัก: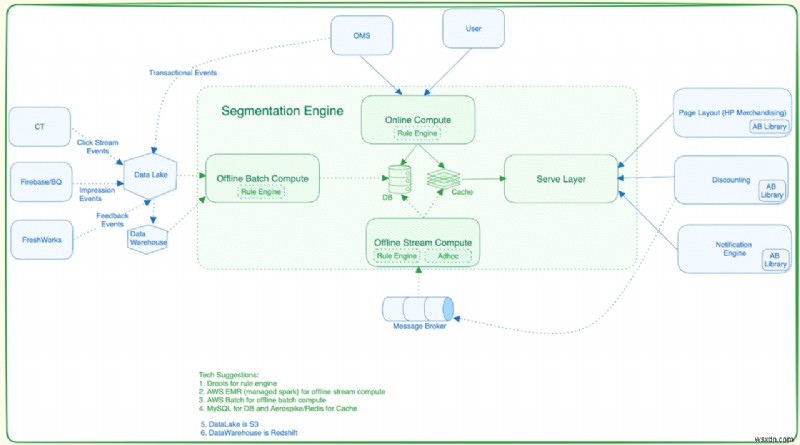
-
บริการประมวลผล (การประมวลผลแบบออฟไลน์/การประมวลผลแบบออนไลน์):
- แยกกลุ่มผู้ใช้ออกจากข้อมูลดิบโดยใช้ Spark Jobs
- งาน Spark ดึงข้อมูล ทำความสะอาด และตรวจสอบความถูกต้องของข้อมูลจาก Data Lake
- ข้อมูลผลลัพธ์จะถูกส่งไปยังระบบย่อยที่ให้บริการ
-
บริการนำเข้า:
- โอนส่วนที่คำนวณจากบริการประมวลผลไปยังบริการการแบ่งส่วน
- จัดการการรวมและการยกเว้นผู้ใช้ภายในกลุ่ม
-
บริการแบ่งกลุ่ม (Serve Layer):
-
จัดทำกลุ่มผู้ใช้ตามความต้องการเฉพาะสำหรับบริการผู้ใช้หรือบริการส่วนลด
-
บริการส่วนลดอาจสอบถามตามรหัสผู้ใช้และคำนวณส่วนลดที่มีอยู่
รหัสผู้ใช้ รหัสกลุ่ม สร้างเมื่อ 2521เซ็กเมนต์ X 3 ธันวาคม 20232788 เซ็กเมนต์ Y 3 ธันวาคม 20233943 เซ็กเมนต์ Z 3 ธันวาคม 20233. ส่วนประกอบทางสถาปัตยกรรม
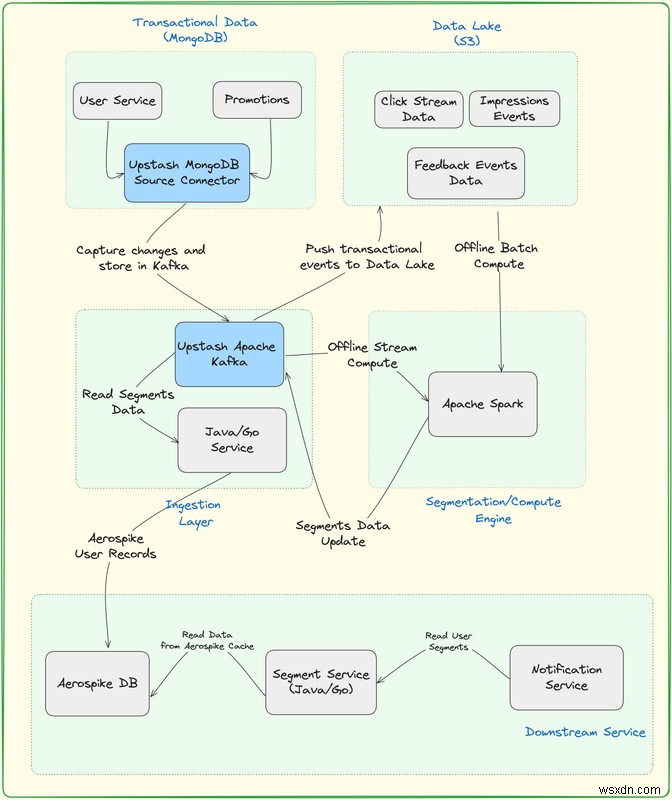
แพลตฟอร์มการแบ่งส่วนประกอบด้วยองค์ประกอบหลักดังต่อไปนี้:
-
ทะเลสาบข้อมูล - S3
- S3 เป็นตัวเลือกที่หลากหลายและนำมาใช้กันอย่างแพร่หลายสำหรับทำหน้าที่เป็น Data Lake ความสามารถในการจัดเก็บอ็อบเจ็กต์ที่ปรับขนาดได้และทนทานทำให้เหมาะสำหรับการจัดเก็บและจัดการข้อมูลประเภทต่างๆ จำนวนมากได้อย่างมีประสิทธิภาพ
- ด้วยการใช้ S3 เป็น Data Lake องค์กรจะได้รับประโยชน์จากฟีเจอร์ที่แข็งแกร่งสำหรับการจัดเก็บข้อมูล การเรียกค้น และการจัดการ ทำให้เป็นตัวเลือกยอดนิยมในแอปพลิเคชันและสถาปัตยกรรมที่เน้นข้อมูลเป็นศูนย์กลาง
-
ฐานข้อมูลธุรกรรม MongoDB
- โมเดลเชิงเอกสารของ MongoDB มีประโยชน์สำหรับกรณีการใช้งานด้านธุรกรรม เนื่องจากช่วยให้คุณสามารถจัดเก็บโครงสร้างข้อมูลที่ซับซ้อนในรูปแบบที่คล้ายกับ JSON ความยืดหยุ่นนี้มีประโยชน์อย่างยิ่งสำหรับแอปพลิเคชันที่โครงสร้างข้อมูลอาจมีการพัฒนาเมื่อเวลาผ่านไป
-
อัพสแตชคาฟคาคลัสเตอร์
- คุณสามารถสตรีมเหตุการณ์การรับส่งข้อมูล (คลิก) จากเว็บแอปพลิเคชันของคุณไปยัง Upstash Kafka จากนั้นคุณสามารถจัดเก็บไว้ใน Data Lake เพื่อการประมวลผลเพิ่มเติมได้
- Upstash Kafka เป็นข้อเสนอ Kafka แบบไร้เซิร์ฟเวอร์ตัวแรก ด้วยโมเดลแบบจ่ายต่อการร้องขอ คุณสามารถมีคลัสเตอร์ Kafka ที่มีการจัดการเต็มรูปแบบโดยไม่ต้องจ่ายเงินหลายร้อยดอลลาร์ ด้วย Free Tier คุณสามารถสร้างคลัสเตอร์ Kafka ได้ในไม่กี่วินาทีโดยไม่ต้องกรอกบัตรเครดิต ทีม Upstash ดูแลความพร้อมใช้งาน การบำรุงรักษา การปรับขนาด การอัปเกรด และสิ่งที่น่าเบื่ออื่นๆ ในขณะที่คุณมุ่งเน้นไปที่แอปของคุณ
-
ตัวเชื่อมต่อซอร์ส Upstash MongoDB
- ตัวเชื่อมต่อแหล่งที่มา MongoDB เป็นส่วนประกอบที่ใช้ในการรวมข้อมูลและแพลตฟอร์มการสตรีม เช่น Apache Kafka Connect เพื่อเชื่อมต่อกับฐานข้อมูล MongoDB และบันทึกการเปลี่ยนแปลงหรือเหตุการณ์แบบเรียลไทม์
- ตัวเชื่อมต่อ Upstash MongoDB Source อำนวยความสะดวกในการเคลื่อนย้ายข้อมูลจาก MongoDB ไปยังระบบหรือแพลตฟอร์มอื่น ช่วยให้สามารถผสานรวมและวิเคราะห์ข้อมูลที่ราบรื่น
-
อาปาเช่ สปาร์ค
- Apache Spark เป็นกลไกหลายภาษาสำหรับการดำเนินการวิศวกรรมข้อมูล วิทยาศาสตร์ข้อมูล และการเรียนรู้ของเครื่องบนเครื่องโหนดเดียวหรือคลัสเตอร์
- ด้วยการผสานรวม Upstash Kafka เข้ากับ Apache Spark ซึ่ง Upstash จัดเตรียมไว้ให้ทันที คุณจะสตรีมเหตุการณ์การรับส่งข้อมูล (คลิก) จากเว็บแอปพลิเคชันของคุณไปยัง Upstash Kafka จากนั้นคุณสามารถวิเคราะห์ได้แบบเรียลไทม์
- Apache Spark จะรับผิดชอบในการประมวลผลการอัปเดตไปยังกลุ่มผู้ใช้ จากนั้นการอัปเดตเหล่านี้จะถูกเขียนไปยัง Upstash Kafka ก่อนที่จะเผยแพร่เพื่ออัปเดตฐานข้อมูล Aerospike
4. ความท้าทายด้านการออกแบบ
การนำไปใช้และการใช้งานกลไกการแบ่งส่วนที่เพิ่มขึ้นอาจทำให้เกิดความท้าทายบางประการสำหรับระบบ
- คอขวดในการเขียน QPS:การสร้างเซ็กเมนต์เพิ่มมากขึ้นเรื่อยๆ อาจนำไปสู่ปัญหาคอขวดในการเขียนคิวรีต่อวินาที (QPS) ส่งผลให้ต้องรอนานสำหรับการสร้างเซ็กเมนต์
- คำขอเวลาแฝงที่ต่ำกว่า:การได้รับเวลาแฝงที่ต่ำมากเป็นสิ่งสำคัญสำหรับการส่งการสื่อสารบางอย่าง โดยเฉพาะอย่างยิ่งเมื่อพิจารณาว่าผู้ใช้อยู่ในกลุ่มเฉพาะหรือไม่
-
เวลาแฝงในการอ่าน
-
ยิ่งไปกว่านั้น เนื่องจากแพลตฟอร์มยังคงพัฒนาต่อไป แม้ว่าจะต้องมีเวลาแฝง <50ms สำหรับการอ่านก็ตาม มีความคาดหวังว่าความเร็วนี้อาจไม่เพียงพอสำหรับบริการบางอย่างและกรณีการใช้งานในอนาคต
-
ตัวอย่างเช่น บริการแจ้งเตือนคาดว่าจะต้องมีการตรวจสอบอย่างรวดเร็วเพื่อระบุความเป็นสมาชิกกลุ่มผู้ใช้ก่อนที่จะส่งการสื่อสาร การแนะนำเวลาแฝงที่เพิ่มขึ้นสำหรับคำขอการสื่อสารแต่ละรายการคาดว่าจะไม่สามารถยอมรับได้ในอนาคต
-
-
การจัดการโครงสร้างพื้นฐานของคาฟคา
-
การจัดการเหตุการณ์หลายล้านเหตุการณ์ต่อนาทีจากแหล่งที่มาของธุรกรรมสามารถก่อให้เกิดความท้าทายได้อย่างแท้จริงเมื่อใช้โครงสร้างพื้นฐานของ Kafka และการจัดการที่มีประสิทธิผลสำหรับปริมาณงานที่สูงเช่นนี้จำเป็นต้องพิจารณาอย่างรอบคอบจากปัจจัยต่างๆ
-
การทดสอบประสิทธิภาพและการเพิ่มประสิทธิภาพอย่างสม่ำเสมอเป็นกุญแจสำคัญในการรักษาโครงสร้างพื้นฐานของ Kafka ที่มีปริมาณงานสูง
-
-
MongoDB เปลี่ยนการเก็บข้อมูล
-
การรวมเหตุการณ์จากเว็บแอปพลิเคชัน โดยเฉพาะอย่างยิ่งเมื่อจัดเก็บไว้ในฐานข้อมูลธุรกรรมแบบดั้งเดิม เช่น MongoDB แล้วผลักเหตุการณ์เหล่านั้นไปที่ Data Lake อาจต้องใช้ความพยายามบางอย่างจริงๆ
-
ใช้กลไกการบันทึกการเปลี่ยนแปลงที่ MongoDB มอบให้ หรือใช้โซลูชันที่กำหนดเองเพื่อบันทึกการเปลี่ยนแปลงในฐานข้อมูล
-
5. แนวทางแก้ไขที่เสนอ
-
กระจายแคช Aerospike เพื่อปรับปรุงเวลาแฝงในการอ่าน
-
Aerospike จะประกอบด้วยส่วนของผู้ใช้โดยที่ ID ผู้ใช้ทำหน้าที่เป็นคีย์หลักสำหรับการเข้าถึงส่วนผู้ใช้
-
นอกจากนี้ คุณยังสามารถใช้ดัชนีรองกับรหัสเซ็กเมนต์ เพิ่มความคล่องตัวในการเรียกข้อมูลผู้ใช้เซ็กเมนต์ และขจัดความจำเป็นในการจัดเก็บผู้ใช้เซ็กเมนต์แยกกัน
-
นอกจากนี้ การออกแบบยังมีจุดมุ่งหมายเพื่อตอบสนองความต้องการด้านเวลาแฝง โดยมีศักยภาพในการทำงานเป็นแคช ซึ่งอาจเข้ามาแทนที่ความต้องการ Redis
-
การแทนที่ Aerospike ในปัจจุบันด้วย Upstash Redis จำเป็นต้องจัดการข้อมูลสองชุด:แบ่งกลุ่มผู้ใช้และแบ่งกลุ่มผู้ใช้
-
-
Upstash Kafka แบบไร้เซิร์ฟเวอร์เพื่อจัดการโครงสร้างพื้นฐานของ Kafka
-
ด้วย Upstash Kafka คุณจะได้รับบริการที่มีการจัดการอย่างสมบูรณ์ นี่หมายความว่า Upstash จัดการงานด้านเทคนิคทั้งหมด เช่น การจัดเตรียมเซิร์ฟเวอร์ การปรับขนาด และการบำรุงรักษาที่เกี่ยวข้องกับการเรียกใช้คลัสเตอร์ Kafka
-
วิธีนี้ช่วยให้คุณไม่ต้องกังวลเกี่ยวกับสิ่งต่างๆ เช่น การตั้งค่าโครงสร้างพื้นฐาน การทำให้ทุกอย่างทำงานได้อย่างถูกต้อง และการบำรุงรักษาเมื่อเวลาผ่านไป
-
สิ่งนี้ช่วยให้คุณมุ่งเน้นไปที่การใช้ประโยชน์จาก Kafka ให้ตรงตามความต้องการและวัตถุประสงค์เฉพาะของคุณ โดยไม่ต้องมีภาระในการจัดการโครงสร้างพื้นฐาน ตอนนี้คุณสามารถทุ่มเทพลังงานของคุณเพื่อปรับปรุงคุณภาพโดยรวมของแอปพลิเคชันของคุณ โดยเฉพาะอย่างยิ่งในสภาพแวดล้อมการพัฒนาที่มีการพัฒนาอย่างรวดเร็ว
-
ระดับราคาเป็นศูนย์: ข้อเสนอแบบไร้เซิร์ฟเวอร์ที่แท้จริงไม่ควรเรียกเก็บเงินจากคุณหากคุณไม่ได้ใช้งานอยู่ ราคาต่อคำขอเป็นคุณลักษณะที่โดดเด่นที่สุดของเรา คุณได้ออกแบบผลิตภัณฑ์และโครงสร้างพื้นฐานของคุณให้เหมาะกับรูปแบบการกำหนดราคานี้ตั้งแต่วันแรก ซึ่งจำเป็นต้องลดต้นทุนคงที่ให้เหลือน้อยที่สุด ซึ่งค่อนข้างยากสำหรับสัตว์ร้ายอย่างคาฟคา
-
ไม่มีภาระในการดำเนินงานสำหรับผู้ใช้: ผู้ใช้สร้างหัวข้อ Kafka และเริ่มใช้งาน ความพร้อมใช้งานสูง ความสามารถในการปรับขนาด การอัปเกรด การสำรองข้อมูล... ทั้งหมดนี้เป็นความรับผิดชอบของเรา
-
ไร้การเชื่อมต่อ: ฟังก์ชันไร้เซิร์ฟเวอร์ไม่คงสถานะ ดังนั้นคุณควรจะสามารถเข้าถึงข้อมูลของคุณด้วยการเชื่อมต่อแบบไร้สัญชาติ ข้อเสนอ Kafka ของเรารองรับโปรโตคอล Kafka TCP ดังนั้นไคลเอนต์ Kafka ทั้งหมดจะทำงานร่วมกับ Upstash ได้ คุณยังมี REST API ในตัวเพื่อเปิดใช้งานสภาพแวดล้อมแบบไร้การเชื่อมต่อ เช่น AWS Lambda หรือ Cloudflare Workers
-
-
MongoDB CDC โดยใช้ Upstash MongoDB Source Connector
-
Kafka Connect เป็นเครื่องมือสำหรับการสตรีมข้อมูลระหว่าง Apache Kafka และระบบอื่นๆ โดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว คุณสามารถส่งออกข้อมูลของคุณไปยังที่จัดเก็บข้อมูลอื่น ๆ ได้ด้วย Kafka Sink Connectors คุณสามารถดึงข้อมูลไปยังหัวข้อ Kafka ของเราจากระบบอื่นผ่าน Kafka Source Connectors
-
Kafka Connectors สามารถโฮสต์ได้เอง แต่คุณจะต้องตั้งค่าและบำรุงรักษากระบวนการ/เครื่องจักรเพิ่มเติม Upstash มีตัวเชื่อมต่อเวอร์ชันที่โฮสต์สำหรับคลัสเตอร์ Kafka ของคุณ สิ่งนี้จะรับภาระในการบำรุงรักษาระบบพิเศษจากคุณ และยังจะมีประสิทธิภาพมากขึ้นด้วยเนื่องจากระบบจะอยู่ใกล้กับคลัสเตอร์ของคุณ
-
6. บันทึกปิดท้าย
โพสต์ในบล็อกนี้สำรวจหลักการออกแบบของแพลตฟอร์มการแบ่งส่วนเวลาแฝงต่ำโดยใช้ประโยชน์จากเทคโนโลยีที่ Upstash มอบให้ โครงสร้างพื้นฐานได้รับการออกแบบทางวิศวกรรมให้ปรับขนาดได้อย่างราบรื่น รองรับผู้ใช้หลายล้านคนและจัดการข้อมูลเทราไบต์ที่จัดเก็บไว้ใน Data Lake
-
-
