
ในโพสต์นี้ ฉันพูดถึงวิธีที่ฉันสร้าง RAG Chatbot เนื้อหาแบบกำหนดเองแบบโอเพ่นซอร์สด้วย Upstash Vector, Upstash Redis, Hugging Face Inference API, Replicate LLAMA-2-70B Chat model และ Vercel Upstash Vector ช่วยให้ฉันแทรกและค้นหาเวกเตอร์ สร้างหรืออัปเดตบริบทที่เกี่ยวข้องแบบไดนามิกสำหรับข้อความผู้ใช้แต่ละข้อความ และ Upstash Redis ช่วยฉันจัดเก็บการสนทนาแชทบอท
ข้อกำหนดเบื้องต้น
คุณจะต้องมีสิ่งต่อไปนี้:
- Node.js 18 หรือใหม่กว่า
- บัญชี Upstash
- บัญชี Hugging Face
- บัญชีจำลอง
- บัญชี Vercel
กลุ่มเทคโนโลยี
การตั้งค่า Upstash Redis
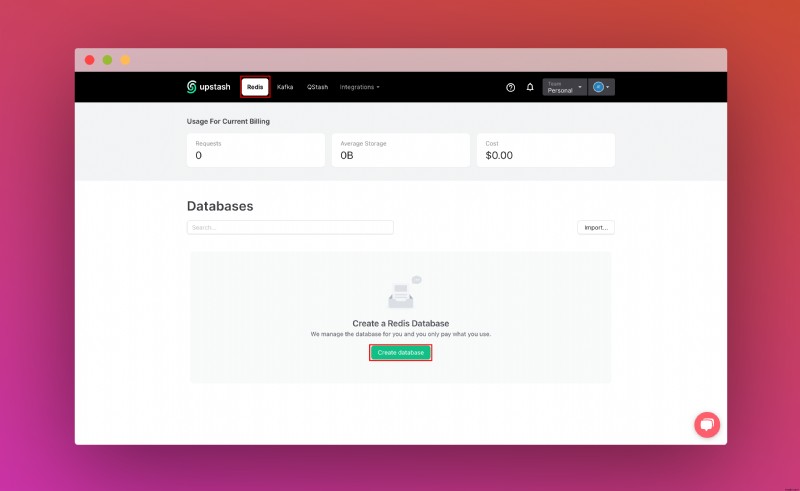
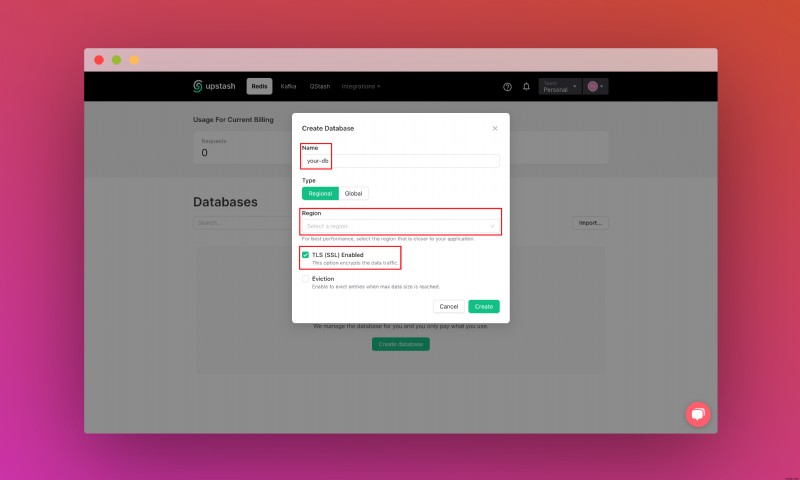
เมื่อคุณสร้างบัญชี Upstash และเข้าสู่ระบบแล้ว คุณจะไปที่แท็บ Redis และสร้างฐานข้อมูล
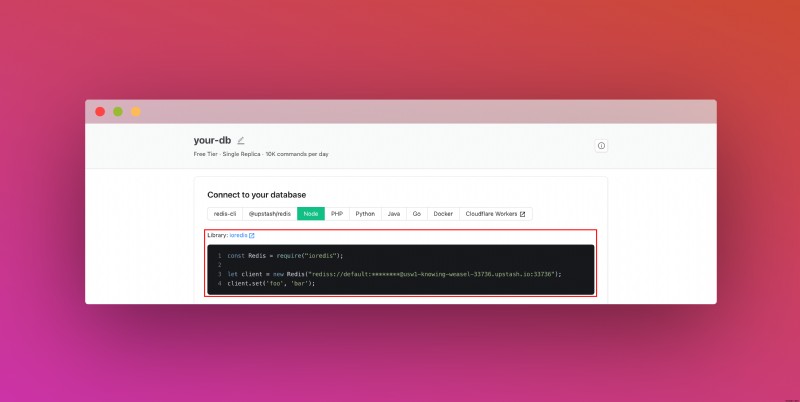
หลังจากที่คุณสร้างฐานข้อมูลแล้ว คุณจะไปที่แท็บรายละเอียด เลื่อนลงไปจนกว่าคุณจะพบส่วนเชื่อมต่อฐานข้อมูลของคุณ คัดลอกเนื้อหาและบันทึกไว้ในที่ที่ปลอดภัย
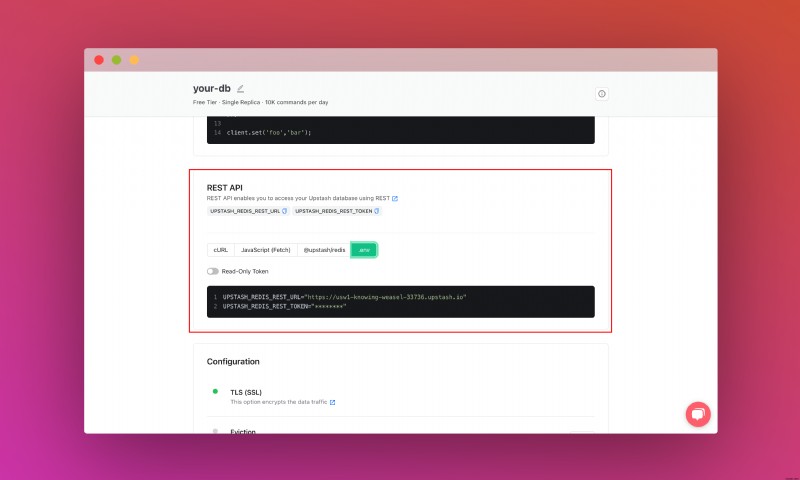
เลื่อนลงไปจนกว่าคุณจะพบส่วน REST API และเลือกปุ่ม .env คัดลอกเนื้อหาและบันทึกไว้ในที่ที่ปลอดภัย
การตั้งค่า Upstash Vector
เมื่อคุณสร้างบัญชี Upstash และเข้าสู่ระบบแล้ว คุณจะไปที่แท็บ Vector และสร้างดัชนี
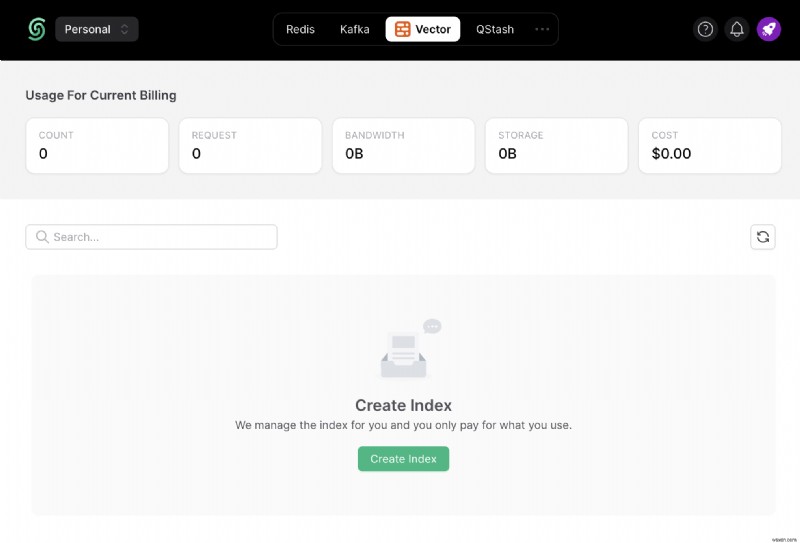
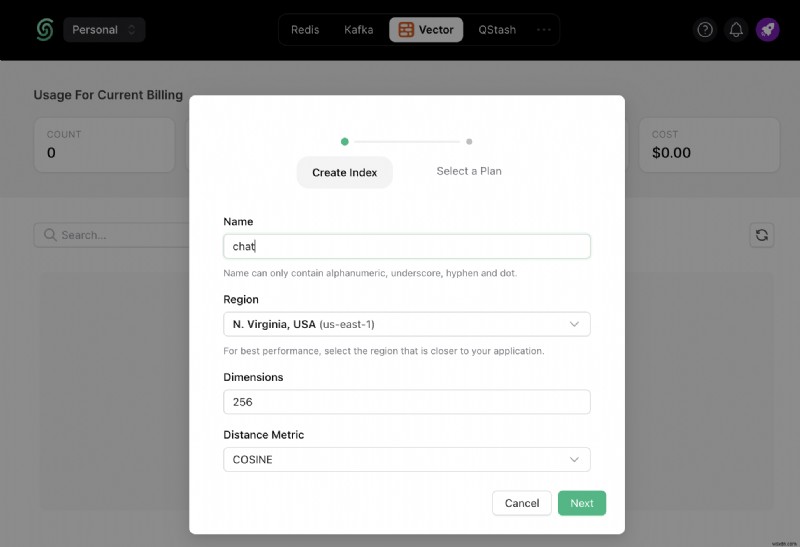
นอกจากนี้ เลื่อนลงไปจนกว่าคุณจะพบ เชื่อมต่อ และเลือก .env ปุ่ม คัดลอกเนื้อหาและบันทึกไว้ในที่ที่ปลอดภัย
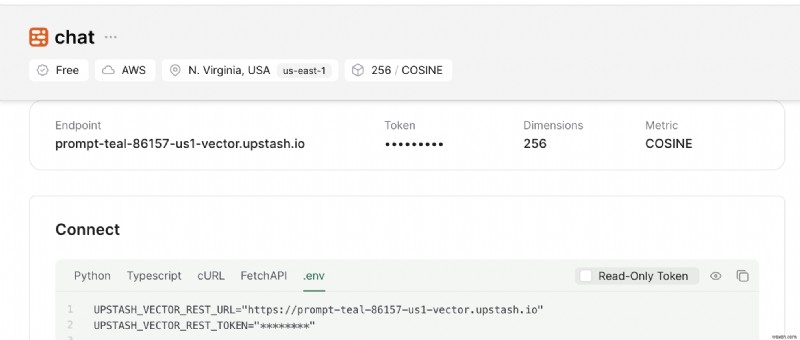
การตั้งค่าโครงการ
หากต้องการตั้งค่า เพียงโคลน repo ของแอปแล้วทำตามบทช่วยสอนนี้เพื่อเรียนรู้ทุกอย่างที่อยู่ในนั้น หากต้องการแยกโครงการ ให้รัน:
git clone https://github.com/rishi-raj-jain/custom-rag-chatbot-upstash-vector
cd custom-rag-chatbot-upstash-vector
pnpm install
เมื่อคุณโคลน repo แล้ว คุณจะต้องสร้าง .env ไฟล์. คุณกำลังจะเพิ่มรายการที่เราบันทึกไว้จากส่วนด้านบน
มันควรมีลักษณะดังนี้:
# .env
# Obtained from the steps as above
# Upstash Redis URL and Token
UPSTASH_REDIS_REST_URL="https://....upstash.io"
UPSTASH_REDIS_REST_TOKEN="..."
# Upstash Vector URL and Token
UPSTASH_VECTOR_REST_URL="https://...-vector.upstash.io"
UPSTASH_VECTOR_REST_TOKEN="..."
# Replicate API Key
REPLICATE_API_TOKEN="r8_..."
# Hugging Face Inference API Key
HUGGINGFACEHUB_API_KEY="hf_..."หลังจากขั้นตอนเหล่านี้ คุณควรจะสามารถเริ่มต้นสภาพแวดล้อมภายในเครื่องได้โดยใช้คำสั่งต่อไปนี้:
pnpm devโครงสร้างพื้นที่เก็บข้อมูล
นี่คือโครงสร้างโฟลเดอร์หลักสำหรับโปรเจ็กต์ ฉันได้ทำเครื่องหมายสีแดงในไฟล์ที่จะกล่าวถึงต่อไปในโพสต์นี้ที่เกี่ยวข้องกับการสร้างเส้นทาง API สำหรับการแชทกับ AI ที่ได้รับการฝึกอบรมในบริบทที่คุณกำหนดเอง และอัปเดตบริบทโดย upsert - ใส่เวกเตอร์ลงในดัชนีที่มีอยู่
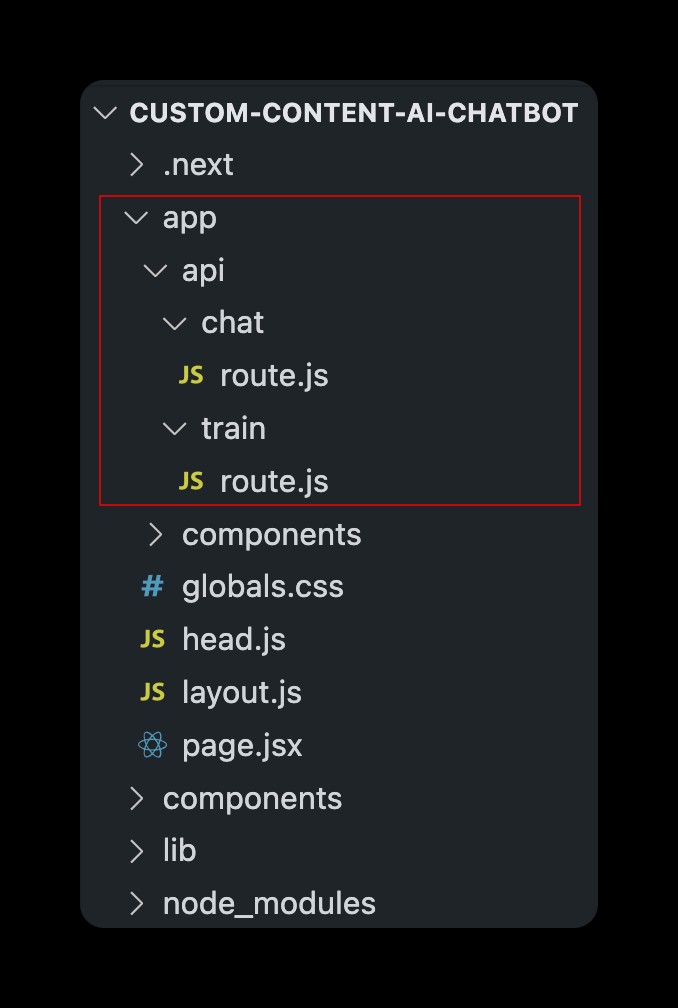
ตั้งค่าเส้นทางการแชทในเราเตอร์แอป Next.js
ในส่วนนี้ เราจะพูดถึงวิธีที่เราตั้งค่าเส้นทาง:app/api/chat/route.js เพื่อซิงค์การสนทนาในฐานข้อมูลแบบไร้เซิร์ฟเวอร์ของเรา สร้างการฝังสตริงแบบไดนามิก ค้นหาเวกเตอร์ที่เกี่ยวข้องจากดัชนีที่กำหนดเพื่อสร้างบริบท และขอการคาดการณ์ที่เกี่ยวข้องโดยใช้โมเดลการแชท LLAMA-2-70B เพื่อให้สิ่งต่าง ๆ ง่ายขึ้น เราจะแบ่งสิ่งนี้ออกเป็นส่วนเพิ่มเติม:
การจัดเก็บการสนทนา
หากต้องการแคชการสนทนาที่เกิดขึ้นกับ Upstash Redis เราจะใช้รายการ Redis ทันทีที่มีข้อความเข้ามาจากผู้ใช้เพื่อตอบกลับ เราจะผลักดันการตอบกลับจากแชทบอท (ก่อนหน้า) ไปยังรายการอย่างมีเงื่อนไข จากนั้น เราจะบันทึกข้อความล่าสุดจากผู้ใช้โดยกดลงในรายการด้วย และดำเนินการตอบกลับต่อไป
// File: app/api/chat/route.js
import { Redis } from '@upstash/redis'
// Instantiate the Upstash Redis
const upstashRedis = new Redis({
url: process.env.UPSTASH_REDIS_REST_URL,
token: process.env.UPSTASH_REDIS_REST_TOKEN,
})
export async function POST(req) {
try {
// the whole chat as array of messages
const { messages } = await req.json()
// assuming user - assistant chat
// add assitant's response to the chat history
if (messages.length > 1) {
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 2]))
}
// add user's request to the chat history
await upstashRedis.lpush('unique_conversation_id', JSON.stringify(messages[messages.length - 1]))
// Proceed to create a response
}สร้างการฝังข้อความล่าสุด
เพื่อตอบกลับข้อความล่าสุดของผู้ใช้อย่างมีประสิทธิภาพในทุกบริบทที่กำหนด (เช่น เนื้อหาที่กำหนดเองที่ผู้ใช้ระบุ) เราจะสร้างการฝังซึ่งจะช่วยให้เราดึงบริบทที่เกี่ยวข้อง (หรือที่เรียกว่าเวกเตอร์ที่คล้ายกัน) จากดัชนีที่มีอยู่ เราจะใช้ Hugging Face Inference API กับ LangChain เพื่อสร้างการฝังด้วยการเรียก API ที่ขอบ และแบ่งเวกเตอร์ที่ได้รับตามความยาวที่เรากำหนดค่าไว้ในขณะที่หมุน Upstash Vector Index (ที่นี่ 256 ).
// File: app/api/chat/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// ...
// get the latest question stored in the last message of the chat array
const userMessages = messages.filter((i) => i.role === 'user')
const lastMessage = userMessages[userMessages.length - 1].content
// generate embeddings of the latest question
const queryVector = (await embeddings.embedQuery(lastMessage)).slice(0, 256)
// Proceed to create a response
}ดึงข้อมูลเวกเตอร์บริบทที่เกี่ยวข้องตามข้อความล่าสุด
การดึงข้อมูลบริบททั้งหมดที่ผู้ใช้ระบุต่อข้อความแบบไดนามิกถือเป็นการดำเนินการที่มีราคาแพง เราต้องการใช้เฉพาะบริบทที่เกี่ยวข้องกับข้อความล่าสุดของผู้ใช้ และส่งต่อไปยังโมเดลแชท LLAMA-2-70B ตามที่ระบบแจ้ง เพื่อดึงเฉพาะบริบทที่เกี่ยวข้อง เราจะค้นหาชุดเวกเตอร์ที่มีอยู่เพื่อให้ได้เวกเตอร์ที่เกี่ยวข้องมากที่สุด 2 รายการ รวมถึงข้อมูลเมตาของเวกเตอร์เหล่านั้น และกรองผลลัพธ์ที่มีคะแนนความเชื่อมั่นมากกว่า 70%
// File: app/api/chat/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// query the relevant vectors from the embedding vector
const queryResult = await upstashVectorIndex.query({
vector: queryVector,
// get the top 2 relevant results
topK: 2,
// do not include the whole set of embeddings in the response
includeVectors: false,
// include the meta data so that can get the description out of the index
includeMetadata: true,
})
// console.log('The query result came in', queryResult.length)
// using the resulting set of relevant vectors
// filter the one that have score of greater than 70% match
// and get the description we stored while training
const queryPrompt = queryResult
.filter((match) => match.score && match.score > 0.7)
.map((match) => match.metadata.description)
.join('\n')
// console.log('The query prompt is', queryPrompt)
// Proceed to create a response
}แจ้งโมเดลการแชท LLAMA-2-70B พร้อมบริบทสำหรับการทำนาย
ตอนนี้เราได้รับบริบทที่เกี่ยวข้องเป็นสตริงแล้ว ขั้นตอนสุดท้ายคือการแจ้งให้โมเดลแชท llama-2-70B ตอบกลับข้อความล่าสุดของผู้ใช้ เราใช้ experimental_buildLlama2Prompt ของ Vercel AI SDK วิธีการดูแลการสร้างรูปแบบข้อความแจ้งที่เหมาะสมสำหรับโมเดลแชท llama-2-70B
// File: app/api/chat/route.js
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
import { ReplicateStream, StreamingTextResponse } from 'ai'
// Instantiate the Replicate API
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
})
export async function POST(req) {
try {
// ...
const response = await replicate.predictions.create({
// You must enable streaming.
stream: true,
// The model must support streaming. See https://replicate.com/docs/streaming
// This is the model ID for Llama 2 70b Chat
version: '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt([
{
// create a system content message to be added as
// the llama2prompt generator will supply it as the context with the API
role: 'system',
content: queryPrompt.substring(0, Math.min(queryPrompt.length, 2000)),
},
// also, pass the whole conversation!
...messages,
]),
},
})
// stream the result to the frontend
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}ตั้งค่าเส้นทางรถไฟในเราเตอร์แอป Next.js
ในส่วนนี้ เราจะพูดถึงวิธีที่เราตั้งค่าเส้นทาง:app/api/train/route.js เพื่อสร้างการฝังสตริงที่ส่งผ่านในออบเจ็กต์คำขอแบบไดนามิก และเพิ่มลงใน Upstash Vector Index เพื่อให้สิ่งต่าง ๆ ง่ายขึ้น เราจะแบ่งสิ่งนี้ออกเป็นส่วนเพิ่มเติม:
สร้างการฝังสตริง
เราจะสร้างการฝังสตริงซึ่งจะช่วยเราตั้งค่าหรืออัปเดตดัชนีที่มีอยู่ การทำเช่นนี้ช่วยให้เราสามารถรักษาบริบทสำหรับการตอบสนองในอนาคตของแชทบอทให้ทันสมัยอยู่เสมอ เราจะใช้ Hugging Face Inference API กับ LangChain เพื่อสร้างการฝังด้วยการเรียก API บน Edge
// File: app/api/train/route.js
import { HuggingFaceInferenceEmbeddings } from '@langchain/community/embeddings/hf'
// Instantiate the Hugging Face Inference API
const embeddings = new HuggingFaceInferenceEmbeddings()
export async function POST(req) {
try {
// a default set of messages to create vector embeddings on
let messagesToVectorize = [
'Rishi is pretty much active on Twitter nowadays.',
'Rishi loves writing for Upstash',
"Rishi's recent article on building chatbot using Upstash went viral",
'Rishi is enjoying building launchfa.st.',
]
// if the POST request is of type application/json
if (req.headers.get('Content-Type') === 'application/json') {
// and if the request contains array of messages to train on
const { messages } = await req.json()
if (typeof messages !== 'string' && messages.length > 0) {
messagesToVectorize = messages
}
}
// Call the Hugging Face Inference API to get emebeddings on the messages
const generatedEmbeddings = await Promise.all(messagesToVectorize.map((i) => embeddings.embedQuery(i)))
// ...
}จัดเก็บเวกเตอร์สำหรับการค้นหาที่เกี่ยวข้อง
ในการเพิ่มการฝังที่สร้างขึ้นให้กับดัชนีเวกเตอร์ เราจะแบ่งเวกเตอร์ที่ได้รับตามความยาวที่เรากำหนดค่าไว้ในขณะที่หมุน Upstash Vector Index (ที่นี่ 256 ) และใช้ upsert วิธีการแทรกการฝังด้วยข้อมูลเมตา เช่น ตัวสตริงเอง สิ่งนี้ช่วยให้เราดึงสตริงเมื่อมีการค้นหาเวกเตอร์ที่คล้ายกัน ดังนั้น ตั้งค่าฐานความรู้ของการสนทนาในขณะที่เราเรียกโมเดลการแชท LLAMA-2-70B เพื่อสร้างการตอบกลับ
// File: app/api/train/route.js
import { Index } from '@upstash/vector'
// Instantiate the Upstash Vector Index
const upstashVectorIndex = new Index()
export async function POST(req) {
try {
// ...
// Slice the vector into lengths of upto 256
await Promise.all(
generatedEmbeddings
.map((i) => i.slice(0, 256))
.map((vector, index) =>
// Upsert the vector with description to be further as the context to upcoming questions
upstashVectorIndex.upsert({
vector,
id: index.toString(),
metadata: { description: messagesToVectorize[index] },
}),
),
)
// Once done, return with a successful 200 response
return new Response(JSON.stringify({ code: 1 }), { status: 200, headers: { 'Content-Type': 'application/json' } })
}นั่นเป็นการเรียนรู้มากมาย! คุณทำเสร็จแล้วตอนนี้ ✨
ปรับใช้กับ Vercel
ตอนนี้พื้นที่เก็บข้อมูลพร้อมที่จะปรับใช้กับ Vercel แล้ว ใช้ขั้นตอนต่อไปนี้เพื่อปรับใช้ 👇🏻
- เริ่มต้นด้วยการสร้างพื้นที่เก็บข้อมูล GitHub ที่มีโค้ดของแอปของคุณ
- จากนั้น ไปที่แดชบอร์ด Vercel และสร้างโปรเจ็กต์ใหม่ .
- เชื่อมโยงโปรเจ็กต์ใหม่กับที่เก็บ GitHub ที่คุณเพิ่งสร้างขึ้น
- ในการตั้งค่า อัปเดต
Environment Variablesเพื่อจับคู่กับ.envในพื้นที่ของคุณ ไฟล์ - ปรับใช้! 🚀
ข้อมูลเพิ่มเติม
หากต้องการข้อมูลเชิงลึกโดยละเอียดเพิ่มเติม โปรดสำรวจข้อมูลอ้างอิงที่อ้างถึงในโพสต์นี้
บทสรุป
โดยสรุป โครงการนี้ได้มอบประสบการณ์อันมีค่าในการเรียนรู้วิธีสร้างการฝัง การสืบค้นจากชุดเวกเตอร์ที่มีอยู่ และใช้บริบทเพื่อสร้างการคาดการณ์ที่เกี่ยวข้องโดยใช้โมเดลแชท LLAMA-2-70B ในขณะที่ใช้บริการที่ปรับขนาดตามความต้องการของคุณ เช่น Upstash
