
หากต้องการเลือกชุดย่อยของแถว ให้ใช้เงื่อนไขและดึงข้อมูล
สมมติว่าต่อไปนี้คือเนื้อหาของไฟล์ CSV ของเราที่เปิดใน Microsoft Excel −
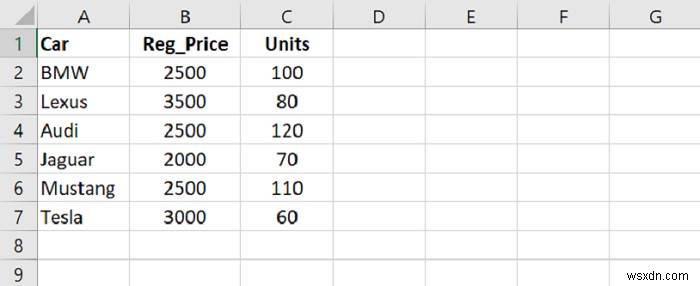
ขั้นแรก ให้โหลดข้อมูลจากไฟล์ CSV ลงใน Pandas DataFrame -
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv") สมมติว่าเราต้องการให้บันทึกรถยนต์ที่มี "หน่วย" มากกว่า 100 รายการ นั่นคือ ชุดย่อยของแถว สำหรับสิ่งนี้ ให้ใช้ −
dataFrame[dataFrame["Units"] > 100]
ในตอนนี้ สมมติว่าเราต้องการให้บันทึกรถยนต์ที่มี “Reg_Price” น้อยกว่า 100 เช่น เซตย่อยของแถว สำหรับสิ่งนี้ ให้ใช้ −
dataFrame[dataFrame["Reg_Price"] < 3000]
ตัวอย่าง
ต่อไปนี้เป็นรหัส -
import pandas as pd
# Load data from a CSV file into a Pandas DataFrame
dataFrame = pd.read_csv("C:\\Users\\amit_\\Desktop\\SalesData.csv")
print("\nReading the CSV file...\n",dataFrame)
# displaying two columns
res2 = dataFrame[['Reg_Price','Units']];
print("\nDisplaying two columns : \n",res2)
# selecting a subset of rows
print("\nSelect cars with Units more than 100: \n",dataFrame[dataFrame["Units"] > 100])
# selecting a subset of rows
print("\nSelect cars with Reg_Price less than 3000: \n",dataFrame[dataFrame["Reg_Price"] < 3000]) ผลลัพธ์
สิ่งนี้จะสร้างผลลัพธ์ต่อไปนี้ -
Reading the CSV file... Car Reg_Price Units 0 BMW 2500 100 1 Lexus 3500 80 2 Audi 2500 120 3 Jaguar 2000 70 4 Mustang 2500 110 Displaying only one column Car : Reg_Price Units 0 2500 100 1 3500 80 2 2500 120 3 2000 70 4 2500 110 Name: Car, dtype: object Select cars with Units more than 100: Car Reg_Price Units 2 Audi 2500 120 4 Mustang 2500 110 Select cars with Reg_Price less than 3000: Car Reg_Price Units 0 BMW 2500 100 2 Audi 2500 120 3 Jaguar 2000 70 4 Mustang 2500 110
