
Tensorflow คือเฟรมเวิร์กแมชชีนเลิร์นนิงที่ให้บริการโดย Google เป็นเฟรมเวิร์กโอเพนซอร์ซที่ใช้ร่วมกับ Python เพื่อใช้อัลกอริทึม แอปพลิเคชันการเรียนรู้เชิงลึก และอื่นๆ อีกมากมาย ใช้ในการวิจัยและเพื่อการผลิต มีเทคนิคการเพิ่มประสิทธิภาพที่ช่วยในการดำเนินการทางคณิตศาสตร์ที่ซับซ้อนได้อย่างรวดเร็ว เนื่องจากใช้ NumPy และอาร์เรย์หลายมิติ อาร์เรย์หลายมิติเหล่านี้เรียกอีกอย่างว่า 'เทนเซอร์' เฟรมเวิร์กรองรับการทำงานกับโครงข่ายประสาทเทียมระดับลึก สามารถปรับขนาดได้สูงและมาพร้อมกับชุดข้อมูลยอดนิยมมากมาย
Tensor เป็นโครงสร้างข้อมูลที่ใช้ใน TensorFlow ช่วยเชื่อมต่อขอบในแผนภาพการไหล แผนภาพการไหลนี้เรียกว่า 'กราฟการไหลของข้อมูล' เทนเซอร์เป็นเพียงอาร์เรย์หลายมิติหรือรายการ
เป้าหมายเบื้องหลังปัญหาการถดถอยคือการคาดการณ์ผลลัพธ์ของตัวแปรต่อเนื่องหรือตัวแปรที่ไม่ต่อเนื่อง เช่น ราคา ความน่าจะเป็น ฝนจะตกหรือไม่ เป็นต้น
ชุดข้อมูลที่เราใช้เรียกว่าชุดข้อมูล 'Auto MPG' ประกอบด้วยการประหยัดเชื้อเพลิงของรถยนต์ในยุค 1970 และ 1980 ซึ่งรวมถึงคุณลักษณะต่างๆ เช่น น้ำหนัก แรงม้า การกระจัด และอื่นๆ ด้วยเหตุนี้ เราจึงต้องคาดการณ์ประสิทธิภาพการใช้เชื้อเพลิงของรถยนต์แต่ละคัน
เรากำลังใช้ Google Colaboratory เพื่อเรียกใช้โค้ดด้านล่าง Google Colab หรือ Colaboratory ช่วยเรียกใช้โค้ด Python บนเบราว์เซอร์และไม่ต้องมีการกำหนดค่าใดๆ และเข้าถึง GPU ได้ฟรี (หน่วยประมวลผลกราฟิก) Colaboratory สร้างขึ้นบน Jupyter Notebook
ต่อไปนี้เป็นข้อมูลโค้ดที่เราจะได้เห็นว่าจะแยกและตรวจสอบข้อมูลเพื่อคาดการณ์ประสิทธิภาพการใช้เชื้อเพลิงด้วยชุดข้อมูล Auto MPG โดยใช้ TensorFlow ได้อย่างไร -
ตัวอย่าง
print("Splitting the training and testing dataset")
train_dataset = dataset.sample(frac=0.7, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
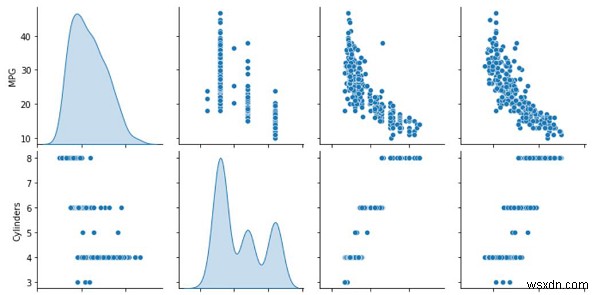
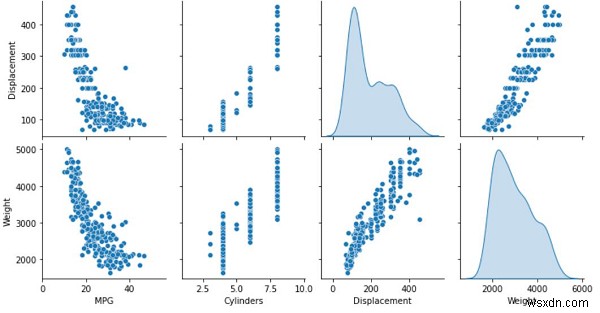
print("Plotting the training data as a visualization")
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
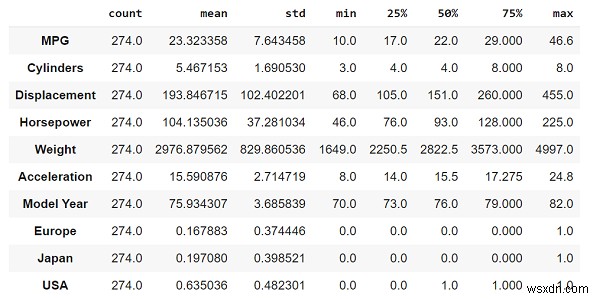
print("Understanding the statistics associated with the data")
train_dataset.describe().transpose() เครดิตโค้ด − https://www.tensorflow.org/tutorials/keras/regression
ผลลัพธ์
Splitting the training and testing dataset Plotting the training data as a visualization Understanding the statistics associated with the data
คำอธิบาย
-
เมื่อล้างข้อมูลแล้ว ข้อมูลจะแบ่งออกเป็นชุดข้อมูลการฝึกอบรมและทดสอบ
-
ข้อมูล 70 เปอร์เซ็นต์ใช้สำหรับการฝึกอบรมและอีก 30 เปอร์เซ็นต์ใช้สำหรับการทดสอบ
-
ข้อมูลการฝึกอบรมนี้แสดงเป็นภาพบนคอนโซลโดยใช้แพ็คเกจ Seaborn
-
สถิติของข้อมูล เช่น จำนวน ค่าเฉลี่ย ค่ามัธยฐาน และอื่นๆ จะแสดงโดยใช้ฟังก์ชัน "อธิบาย"
