แนะนำตัว..
ข้อได้เปรียบที่ใหญ่ที่สุดอย่างหนึ่งของการเขียน API คือการดึงข้อมูลปัจจุบัน/ข้อมูลสด แม้ว่าข้อมูลจะมีการเปลี่ยนแปลงอย่างรวดเร็ว API จะได้รับข้อมูลล่าสุดเสมอ โปรแกรม API จะใช้ URL ที่เจาะจงมากเพื่อขอข้อมูลบางอย่างเช่น Topp 100 เพลงที่เล่นมากที่สุดในปี 2020 ใน Spotify หรือ Youtube Music ข้อมูลที่ร้องขอจะถูกส่งคืนในรูปแบบที่ประมวลผลได้ง่าย เช่น JSON หรือ CSV
Python อนุญาตให้ผู้ใช้เขียนการเรียก API ไปยัง URL เกือบทั้งหมดที่คุณนึกออก ในตัวอย่างนี้ ฉันจะแสดงวิธีแยกผลลัพธ์ API จาก GitHub และแสดงเป็นภาพ
หมายเหตุ - แผนคือการแสดงผลลัพธ์ API จาก Spotify แต่ Spotify ต้องการข้อกำหนดเบื้องต้นเพิ่มเติม ซึ่งอาจต้องใช้มากกว่า 1 โพสต์ ดังนั้นเราจะยึด GitHUb สำหรับโพสต์นี้
Github ซึ่งมักถูกเรียกว่าเป็นนักพัฒนา Facebook ช่วยให้เราเขียนการเรียก API เพื่อดึงข้อมูลที่หลากหลาย สมมติว่าคุณต้องการค้นหาที่เก็บ Javascript Github ที่มีดาวมากกว่านี้ GitHub ไม่ต้องการคีย์ API ในขณะที่ตัวอื่นอาจต้องการ
ทำอย่างไร..
1. ติดตั้งแพ็คเกจคำขอโดยเปิดพรอมต์คำสั่ง python และเริ่มส่งคำขอติดตั้ง pip
import requests
# set the siteurl
site_url = 'https://api.github.com/search/repositories?q=language:javascript&sort=stars'
# set the headers
headers = {'Accept': 'application/vnd.github.v3+json'}
# call the url and save the response
response = requests.get(site_url, headers=headers)
# Get the response
print(f"Output \n *** Response from {site_url} is {response.status_code} ") ผลลัพธ์
*** Response from https://api.github.com/search/repositories?q=language:javascript&sort=stars is 200
2. API ส่งคืนข้อมูลในรูปแบบ JSON ดังนั้น เราจำเป็นต้องใช้เมธอด json() เพื่อแปลงข้อมูลเป็นพจนานุกรม Python
ตัวอย่าง
response_json = response.json()
print(f"Output \n *** keys in the Json file \n {response_json.keys()} \n")
print(f" *** Total javascript repositories in GitHub \n {response_json['total_count']}" ) ผลลัพธ์
*** keys in the Json file dict_keys(['total_count', 'incomplete_results', 'items']) *** Total javascript repositories in GitHub 11199577
-
ดังนั้นเราจึงมี 3 คีย์ซึ่งเราสามารถละเว้น incomplete_results ได้ ให้เราตรวจสอบที่เก็บแรกของเราตอนนี้
ตัวอย่าง
repositories = response_json['items']
first_repo = repositories[0]
print(f"Output \n *** Repository information keys total - {len(first_repo)} - values are -\n")
for keys in sorted(first_repo.keys()):
print(keys)
print(f" *** Repository name - {first_repo['name']}, Owner - {first_repo['owner']['login']}, total watchers - {first_repo['watchers_count']} ") ผลลัพธ์
*** Repository information keys total - 74 - values are - archive_url archived assignees_url blobs_url branches_url clone_url collaborators_url comments_url commits_url compare_url contents_url contributors_url created_at default_branch deployments_url description disabled downloads_url events_url fork forks forks_count forks_url full_name git_commits_url git_refs_url git_tags_url git_url has_downloads has_issues has_pages has_projects has_wiki homepage hooks_url html_url id issue_comment_url issue_events_url issues_url keys_url labels_url language languages_url license merges_url milestones_url mirror_url name node_id notifications_url open_issues open_issues_count owner private pulls_url pushed_at releases_url score size ssh_url stargazers_count stargazers_url statuses_url subscribers_url subscription_url svn_url tags_url teams_url trees_url updated_at url watchers watchers_count *** Repository name - freeCodeCamp, Owner - freeCodeCamp, total watchers - 316079
4. เวลาสำหรับการสร้างภาพข้อมูล มีข้อมูลมากมายให้ย่อย ดังนั้นวิธีที่ดีที่สุดคือเห็นภาพผลลัพธ์ จำไว้ว่า - "ภาพหนึ่งภาพมีค่าพันคำ"
ฉันได้กล่าวถึง matplotlib ในโพสต์อื่นแล้ว ดังนั้นสำหรับการเปลี่ยนแปลง เราจะสร้างแผนภูมิโดยใช้พล็อต
-
ติดตั้งโมดูล - พล็อต เราจะเริ่มต้นด้วยการนำเข้าพล็อต
ตัวอย่าง
from plotly.graph_objs import Bar from plotly import offline
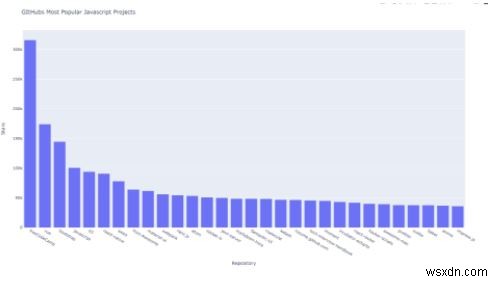
6. เราจะทำแผนภูมิแท่งที่มีที่เก็บเทียบกับจำนวนดาว ยิ่งมีดาวมากเท่าไร พื้นที่เก็บข้อมูลก็ยิ่งเป็นที่นิยมมากขึ้นเท่านั้น วิธีที่ดีในการดูว่าใครอยู่ด้านบน ดังนั้น เราต้องการตัวแปรสองชื่อที่เก็บและจำนวนดาว
ใน[6]:
ตัวอย่าง
repo_names, repo_stars = [], [] for repo_info in repositories: repo_names.append(repo_info['name']) repo_stars.append(repo_info['stargazers_count'])
7.เริ่มการแสดงภาพด้วยการเตรียมรายการข้อมูล ซึ่งมีพจนานุกรมซึ่งกำหนดประเภทของโครงเรื่องและจัดเตรียมข้อมูลสำหรับค่า x และ y คุณอาจเดาได้แล้วว่า ใช่ เราจะใช้แกน x เพื่อพล็อตชื่อโปรเจ็กต์ และแกน y สำหรับการพล็อตดาว
ตัวอย่าง
data_plots = [{'type' : 'bar', 'x':repo_names , 'y': repo_stars}] 8.เราจะเพิ่มชื่อสำหรับแกน x แกน y และสำหรับแผนภูมิโดยรวมด้วย
ตัวอย่าง
layout = {'title': 'GItHubs Most Popular Javascript Projects',
'xaxis': {'title': 'Repository'},
'yaxis': {'title': 'Stars'}} 9.เวลาวางแผน
import requests
from plotly.graph_objs import Bar
from plotly import offline
site_url = 'https://api.github.com/search/repositories?q=language:javascript&sort=stars'
headers = {'Accept': 'application/vnd.github.v3+json'}
response = requests.get(site_url, headers=headers)
response_json = response.json()
repo_names, repo_stars = [], []
for repo_info in repositories:
repo_names.append(repo_info['name'])
repo_stars.append(repo_info['stargazers_count'])
data_plots = [{'type' : 'bar', 'x':repo_names , 'y': repo_stars}]
layout = {'title': 'GItHubs Most Popular Javascript Projects',
'xaxis': {'title': 'Repository'},
'yaxis': {'title': 'Stars'}}
fig = {'data': data_plots, 'layout': layout}
offline.plot(fig, filename='Most_Popular_JavaScript_Repos.html') ตัวอย่าง
'Most_Popular_JavaScript_Repos.html'
ผลลัพธ์
Most_Popular_JavaScript_Repos.html จะถูกสร้างขึ้นในไดเร็กทอรีเดียวกันกับโค้ดที่มีเอาต์พุตด้านล่าง