

Python ใน Excel เป็นฟีเจอร์ Microsoft 365 อันทรงพลังที่ให้คุณเขียนและเรียกใช้โค้ด Python ภายในเซลล์ Excel ได้โดยตรง มันนำพลังของการวิเคราะห์ Python มาสู่ Excel คุณพิมพ์ Python ลงในเซลล์โดยตรง การคำนวณ Python จะรันใน Microsoft Cloud และผลลัพธ์ของคุณจะถูกส่งกลับไปยังเวิร์กชีต คุณสามารถรวมอินเทอร์เฟซที่คุ้นเคยของ Excel และการคำนวณใหม่เข้ากับระบบนิเวศที่สมบูรณ์ของ Python เพื่อการวิเคราะห์ข้อมูล การล้างข้อมูล สถิติ และการแสดงภาพ โดยไม่ต้องออกจากสเปรดชีตหรือติดตั้งสิ่งใดในเครื่อง
ในบทช่วยสอนนี้ เราจะแสดงวิธีใช้ Python ใน Excel และเมื่อใดและมีประโยชน์อย่างไร แทนที่จะเปลี่ยนไปใช้เครื่องมืออื่นๆ เช่น Jupyter หรือ VS Code คุณสามารถใช้ Python ได้โดยตรงใน Excel
ข้อกำหนดและความพร้อมใช้งาน
- การสมัครใช้งาน Microsoft 365: ใช้ได้กับแผนการชำระเงินหลายแผน (ครอบครัวผู้บริโภค/ส่วนบุคคล เชิงพาณิชย์ การศึกษา องค์กร) คุณลักษณะบางอย่างหรือการประมวลผลที่สูงกว่าอาจต้องมีส่วนเสริม
- แพลตฟอร์ม: พร้อมใช้งานบนเดสก์ท็อป Windows Excel เป็นหลัก การสนับสนุนจะแตกต่างกันไปสำหรับเว็บ, Mac และอุปกรณ์เคลื่อนที่ ไม่มีให้บริการบน Excel สำหรับ iPad, Excel สำหรับ iPhone หรือ Excel สำหรับ Android
- ไม่จำเป็นต้องใช้ Python ในเครื่อง: ทุกอย่างทำงานบนคลาวด์พร้อมกับไลบรารีที่ติดตั้งไว้ล่วงหน้า คุณไม่จำเป็นต้องมี Python เวอร์ชันท้องถิ่นเพื่อใช้ Python ใน Excel หากคุณติดตั้ง Python เวอร์ชันท้องถิ่นบนคอมพิวเตอร์ของคุณ การปรับแต่งใดๆ ที่คุณทำกับการติดตั้งนั้นจะไม่ปรากฏในการคำนวณ Python ใน Excel
สำคัญ: หากต้องการใช้ Python ใน Excel คุณต้องเชื่อมต่ออินเทอร์เน็ต เนื่องจากการคำนวณ Python ใน Excel ทำงานใน Microsoft Cloud โดยใช้ภาษา Python เวอร์ชันมาตรฐาน
การเริ่มต้นใช้งาน Python ใน Excel
เปิดใช้งาน Python ในเซลล์:
- เลือกเซลล์
- ไปที่สูตร แท็บ>> เลือก แทรก Python
- หรือพิมพ์ =PY ในเซลล์แล้วกด Tab
- แถบสูตรเปลี่ยนเป็นสีเขียว ซึ่งบ่งบอกถึงโหมด Python
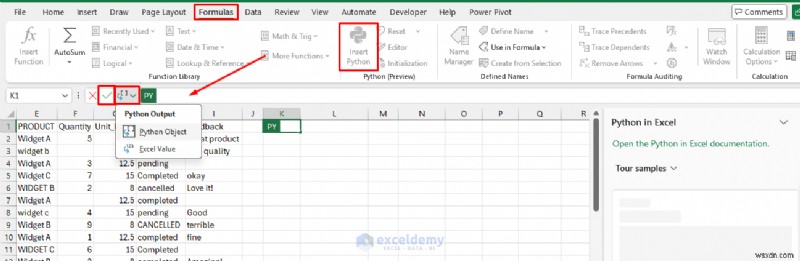
ฟังก์ชัน xl():การเชื่อมโยง Excel และ Python
สิ่งสำคัญในการใช้ Python ใน Excel คือฟังก์ชัน xl() ซึ่งช่วยให้โค้ด Python อ่านข้อมูลได้โดยตรงจากสเปรดชีต:
- ขณะอยู่ในโหมดแก้ไข คลิกและลากเพื่อเลือกเซลล์หรือช่วง (เช่น A1:D100)
- Excel แทรกข้อมูลอ้างอิง เช่น xl(“A1:D100”) หรือที่คล้ายกัน
# อ้างอิงช่วงเป็น DataFrame ของแพนด้า
df =xl(“A1:D100”, ส่วนหัว=True)
# อ้างอิงค่าเซลล์เดียว
เป้าหมาย =xl(“F1”)
นี่คือวิธีที่ Python “เห็น” ข้อมูลสเปรดชีตของคุณ คุณเขียนสิ่งนี้ภายในเซลล์ =PY() และทำงานกับผลลัพธ์เหมือนวัตถุ Python ปกติ
ตัวเลือกเอาต์พุต:
- ใช้เมนูแบบเลื่อนลงในแถบสูตรเพื่อส่งกลับเป็น ค่า Excel (แปลงเป็นเซลล์/ตาราง Excel ดั้งเดิม) หรือเก็บเป็น วัตถุ Python (สำหรับการผูกมัดในเซลล์ Python อื่น)
- กด Ctrl + Alt + Shift + M เพื่อสลับประเภทเอาต์พุต
- ใช้ print() เพื่อแก้ไขจุดบกพร่องหรือส่งออกในบางกรณี
การคำนวณใหม่: เซลล์ Python จะคำนวณใหม่โดยอัตโนมัติ เช่นเดียวกับสูตรอื่นๆ เมื่ออินพุตเปลี่ยนแปลง (ในโหมดอัตโนมัติ)
เคล็ดลับ: เริ่มเล็กๆ. เลือกข้อมูลของคุณ แทรก Python แปลงเป็น DataFrame จากนั้นสำรวจด้วย .head(), .describe() หรือการดำเนินการง่ายๆ
เมื่อ Python ใน Excel มีประโยชน์
1. การล้างและการเปลี่ยนแปลงข้อมูลขั้นสูง
Python สามารถแก้ไขวันที่ที่ยุ่งเหยิง สร้างมาตรฐานให้กับข้อความ (ตัวพิมพ์ใหญ่ การเว้นวรรค) จัดการค่าว่างและค่าที่ซ้ำกัน เปลี่ยนข้อมูลแบบกว้างเป็นรูปแบบยาว และจัดการรูปแบบที่ไม่สอดคล้องกันหรือค่าที่หายไป Pandas ทำให้งานเหล่านี้กระชับและทำซ้ำได้
หลาม:
import pandas as pd
df = xl("A1:I56", headers=True)
df.columns = df.columns.str.strip().str.title()
# Fix names: Title Case
df["Customer_Name"] = df["Customer_Name"].str.strip().str.title()
# Fix region: Title Case
df["Region"] = df["Region"].str.strip().str.title()
# Standardize product: Title Case
df["Product"] = df["Product"].str.strip().str.title()
# Standardize status and feedback
df["Status"] = df["Status"].str.strip().str.capitalize()
df["Feedback"] = df["Feedback"].str.strip().str.capitalize()
# Parse all messy date formats into one
df["Order_Date"] = pd.to_datetime(df["Order_Date"], dayfirst=True, errors="coerce")
# Fill missing quantity with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df
- คลิก เครื่องหมายถูก หรือกด Ctrl+Enter เพื่อเรียกใช้โค้ด
- คลิกไอคอนการ์ดบนเซลล์เอาต์พุต>> เลือก arrayPreview
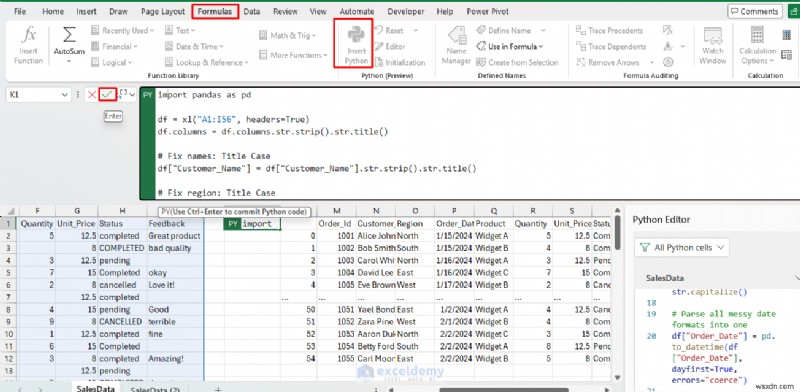
DataFrame ที่ทำความสะอาดแล้วจะหกกลับเข้าไปในแผ่นงานโดยอัตโนมัติ ส่งกลับผลลัพธ์เป็นค่า Excel เพื่อใช้ข้อมูลที่สะอาดสำหรับการวิเคราะห์และการคำนวณเพิ่มเติม
- ขยายเมนูแบบเลื่อนลงจาก แถบสูตร>> เลือก ค่า Excel
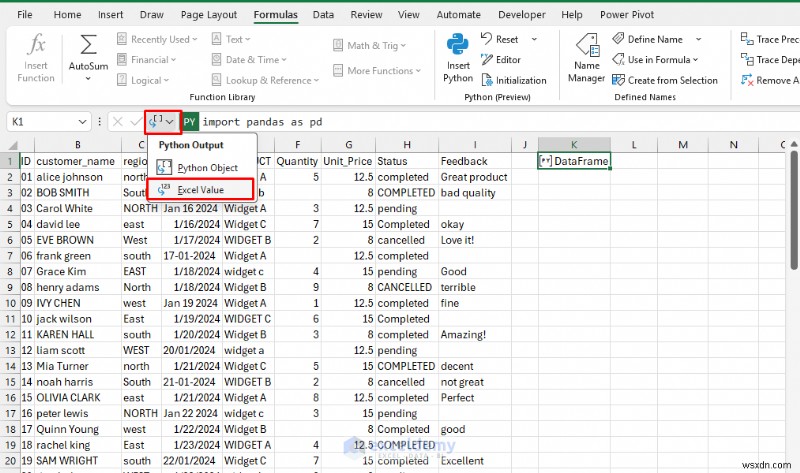
- ตอนนี้ใช้ข้อมูลใหม่ที่ล้างสะอาดแล้วในตัวอย่างนี้
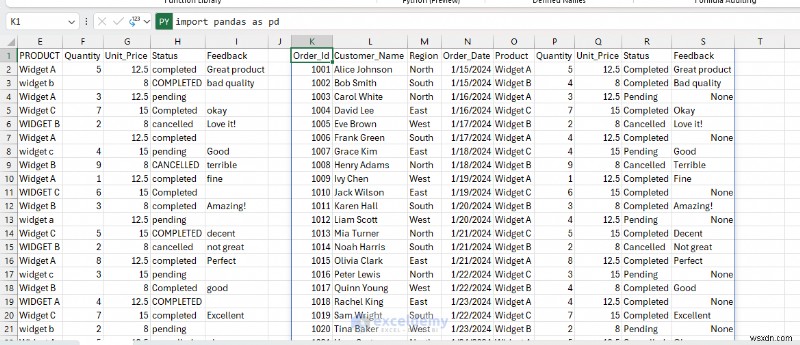
2. การวิเคราะห์ข้อมูลและสถิติที่ซับซ้อน
Python ช่วยให้สามารถดำเนินการนอกเหนือจากฟังก์ชันในตัวของ Excel รวมถึงการจัดกลุ่มที่ซับซ้อน การแปลงหลายขั้นตอน และการสรุปทางสถิติ นอกจากนี้ยังรองรับการวิเคราะห์อนุกรมเวลา การถดถอย การจัดกลุ่ม การตรวจจับค่าผิดปกติ การวิเคราะห์ความรู้สึกในข้อความ และการจำลองแบบมอนติคาร์โล
หลาม:
import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
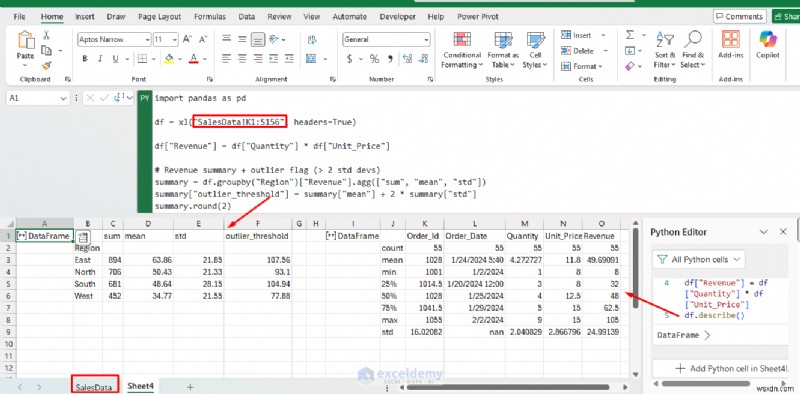
# Revenue summary + outlier flag (> 2 std devs)
summary = df.groupby("Region")["Revenue"].agg(["sum", "mean", "std"])
summary["outlier_threshold"] = summary["mean"] + 2 * summary["std"]
summary.round(2)
ผลลัพธ์จะไหลกลับเข้าไปในแผ่นงานของคุณโดยตรงเป็นตาราง คุณยังสามารถใช้ df.describe() ได้อีกด้วย เพื่อแสดงสถิติสรุปสำหรับ DataFrame ทั้งหมด
หลาม:
import pandas as pd
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
df.describe()
3. แผนภูมิและการแสดงภาพที่ดีขึ้น
เป็นเรื่องง่ายที่จะสร้างแปลงแบบมืออาชีพ เช่น แปลงความหนาแน่น แปลงฝูง เวิร์ดคลาวด์ หรือทวีคูณขนาดเล็กด้วย Matplotlib, Seaborn หรือ plotnine สิ่งเหล่านี้มีความยืดหยุ่นมากกว่าแผนภูมิ Excel มาก ก้าวไปไกลกว่าแผนภูมิดั้งเดิมของ Excel ด้วย matplotlib และ seaborn:
หลาม:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
fig, ax = plt.subplots(figsize=(8, 4))
sns.boxplot(data=df, x="Region", y="Revenue", palette="Set2", ax=ax)
ax.set_title("Revenue Distribution by Region")
ax.set_xlabel("Region")
ax.set_ylabel("Revenue ($)")
fig
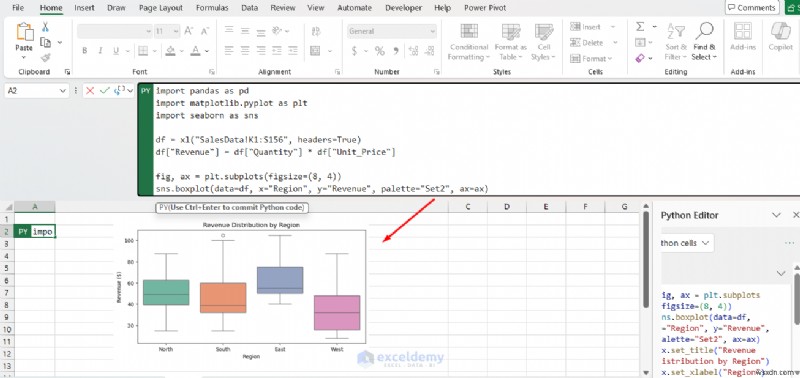
แผนภูมิแสดงผลเป็นวัตถุรูปภาพโดยตรงในเวิร์กชีต ปรับขนาดและเปลี่ยนตำแหน่งได้เช่นเดียวกับแผนภูมิ Excel ใดๆ
4. การเรียนรู้ของเครื่องบนข้อมูลสเปรดชีตของคุณ
Python เปิดใช้งานการสร้างแบบจำลองและการพยากรณ์เชิงคาดการณ์ คุณสามารถสร้างการคาดการณ์หรือโมเดลแมชชีนเลิร์นนิงแบบง่ายๆ ที่แม่นยำยิ่งขึ้นได้โดยใช้โมเดลสถิติหรือ scikit-learn บนข้อมูล Excel ของคุณโดยตรง
เรียกใช้แบบจำลองการคาดการณ์โดยไม่ต้องออกจาก Excel:
หลาม:
import pandas as pd
from sklearn.linear_model import LinearRegression
# Load data from the SalesData sheet
df = xl("SalesData!K1:S156", headers=True)
# Convert to numeric and fill missing values with median
df["Quantity"] = pd.to_numeric(df["Quantity"], errors="coerce")
df["Unit_Price"] = pd.to_numeric(df["Unit_Price"], errors="coerce")
df["Quantity"] = df["Quantity"].fillna(df["Quantity"].median())
df["Unit_Price"] = df["Unit_Price"].fillna(df["Unit_Price"].median())
# Calculate Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# One-hot encode Product
X = pd.get_dummies(df[["Product", "Unit_Price"]], drop_first=True)
y = df["Revenue"]
# Fit the Linear Regression model
model = LinearRegression().fit(X, y)
# Add predictions
df["Predicted_Revenue"] = model.predict(X).round(2)
# Create final result with useful columns
result = df[["Order_Id", "Product", "Revenue", "Predicted_Revenue"]].copy()
result["Difference"] = (result["Revenue"] - result["Predicted_Revenue"]).round(2)
# Optional: Show model performance
print("Model R² Score:", round(model.score(X, y), 4))
result
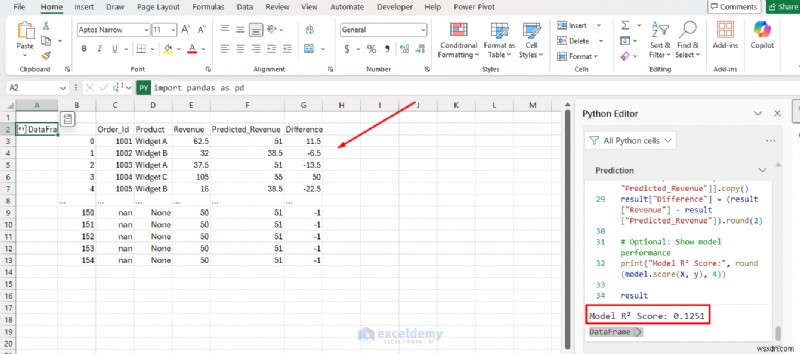
นักวิเคราะห์ธุรกิจสามารถใช้โมเดลการเรียนรู้ของเครื่องกับข้อมูลที่มีอยู่ได้โดยไม่ต้องเปลี่ยนไปใช้สภาพแวดล้อมที่แยกจากกัน
5. การคำนวณแบบโรลลิ่งและอนุกรมเวลา
การคำนวณค่าเฉลี่ยเคลื่อนที่ ผลรวมสะสม หรือคุณลักษณะความล่าช้าเป็นเรื่องยากโดยใช้สูตร Excel เท่านั้น Python ทำให้งานเหล่านี้ง่ายขึ้น
หลาม:
import pandas as pd
# Load your full sales data
df = xl("SalesData!K1:S156", headers=True)
# Calculate Daily Revenue
df["Revenue"] = df["Quantity"] * df["Unit_Price"]
# Rolling Calculations (Time Series)
# Sort by date first (important for time series)
df = df.sort_values("Order_Date").reset_index(drop=True)
# 7-day Rolling Metrics on Revenue (weekly trend)
df["Revenue_7d_Mean"] = df["Revenue"].rolling(window=7, min_periods=1).mean().round(2)
df["Revenue_7d_Sum"] = df["Revenue"].rolling(window=7, min_periods=1).sum().round(2)
df["Revenue_7d_Max"] = df["Revenue"].rolling(window=7, min_periods=1).max().round(2)
df["Revenue_7d_Std"] = df["Revenue"].rolling(window=7, min_periods=1).std().round(2)
# 30-day Rolling Mean (monthly trend)
df["Revenue_30d_Mean"] = df["Revenue"].rolling(window=30, min_periods=1).mean().round(2)
# Cumulative Revenue (running total)
df["Cumulative_Revenue"] = df["Revenue"].cumsum().round(2)
# Select columns to display
result = df[["Order_Id", "Order_Date", "Product", "Revenue",
"Revenue_7d_Mean", "Revenue_7d_Sum", "Revenue_30d_Mean",
"Cumulative_Revenue"]]
result
แนวทางนี้มีประโยชน์สำหรับการวิเคราะห์แนวโน้มการขาย ลดความผันผวนรายวันหรือรายสัปดาห์ การตรวจจับความผิดปกติ และการคาดการณ์โมเมนตัม
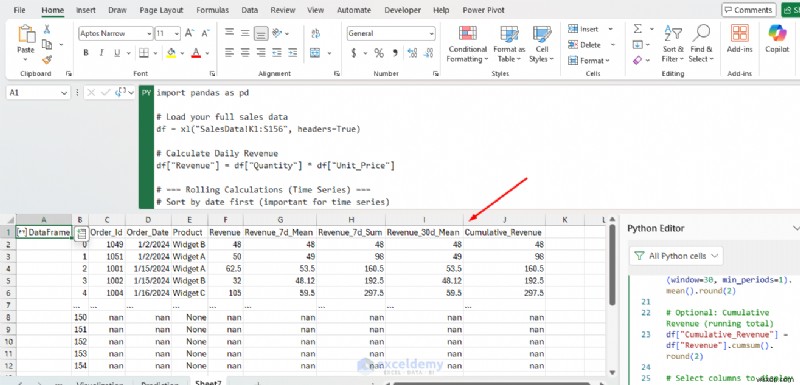
- รายได้_7d_ค่าเฉลี่ย: ค่าเฉลี่ยเคลื่อนที่ 7 วัน (ปรับแนวโน้มยอดขายรายสัปดาห์ให้ราบรื่น)
- รายได้_7d_Sum: รายได้รวมใน 7 วันที่ผ่านมา
- รายได้_30d_ค่าเฉลี่ย: ค่าเฉลี่ยเคลื่อนที่ 30 วัน (แนวโน้มระยะยาว)
- สะสม_รายได้: ยอดรวมของรายได้ทั้งหมดจนถึงวันนั้น
เคล็ดลับและแนวทางปฏิบัติที่ดีที่สุด
- เซลล์ลูกโซ่: อ้างอิงอ็อบเจ็กต์ Python ก่อนหน้า (ปรากฏเป็นตัวแปร) เพื่อสร้างเวิร์กโฟลว์แบบหลายขั้นตอนโดยไม่เกะกะเซลล์เดียว
- ประสิทธิภาพ: สำหรับการประมวลผลจำนวนมาก ให้คำนึงถึงโควต้าคลาวด์ แบ่งงานใหญ่ออกเป็นขั้นตอนหรือใช้การประมวลผลระดับพรีเมียมหากจำเป็น
- ความปลอดภัย: โค้ดทำงานในคอนเทนเนอร์บนคลาวด์ที่แยกออกจากกัน หลีกเลี่ยงการดำเนินการที่มีความละเอียดอ่อน Microsoft จัดการความเป็นส่วนตัว
- การแก้ไขจุดบกพร่อง: ใช้ print() หรือเอาต์พุต DataFrames ทีละขั้นตอน เกิดข้อผิดพลาดในเซลล์
- รวมกับ Excel: ใช้ Python สำหรับการยกของหนัก และใช้ Excel สำหรับการจัดรูปแบบ การหมุน หรือแดชบอร์ด
- เส้นโค้งแห่งการเรียนรู้: หากคุณยังใหม่กับ Python ให้เน้นไปที่แพนด้าก่อน มีบทช่วยสอนและไฟล์ตัวอย่างฟรีมากมาย
- การแบ่งปัน: ผู้รับที่มี Microsoft 365 ที่เข้ากันได้สามารถดูหรือรีเฟรชผลลัพธ์ได้ มิฉะนั้น ผลลัพธ์จะถูกแปลงเป็นค่าคงที่
ข้อจำกัดที่ต้องรู้
- การดำเนินการบนคลาวด์เท่านั้น จำเป็นต้องมีการเชื่อมต่ออินเทอร์เน็ต
- คำนวณโควต้าในแผนมาตรฐาน
- สภาพแวดล้อม Python ได้รับการจัดการโดย Anaconda; คุณไม่สามารถติดตั้งแพ็คเกจของคุณเองหรือใช้การปรับแต่งในเครื่องได้
- การสนับสนุนทางมือถือและเว็บมีจำกัดเมื่อเทียบกับเดสก์ท็อป
- ชุดข้อมูลขนาดใหญ่มากหรือโค้ดที่ทำงานเป็นเวลานานอาจถึงระยะหมดเวลา
บทสรุป
Python ใน Excel มีประโยชน์มากที่สุดเมื่องานของคุณยังใช้สเปรดชีตขั้นพื้นฐาน แต่การวิเคราะห์เองก็มีความก้าวหน้ามากขึ้น เป็นเลิศในด้านการทำความสะอาดข้อมูล การวิเคราะห์สไตล์ DataFrame สถิติขั้นสูง และการแสดงภาพ มันจะมีประโยชน์น้อยกว่าสำหรับงานสเปรดชีตในชีวิตประจำวันซึ่ง Excel จัดการได้ดีอยู่แล้ว Python ใน Excel เชื่อมช่องว่างระหว่างผู้ใช้สเปรดชีตและนักวิทยาศาสตร์ข้อมูล ทำให้สามารถเข้าถึงการวิเคราะห์ขั้นสูงได้โดยไม่รบกวนเวิร์กโฟลว์ที่คุ้นเคย แทนที่จะแทนที่ Excel ด้วย Python ให้ใช้ Python แบบคัดเลือกเมื่อการวิเคราะห์ซับซ้อนเกินไปสำหรับสูตรเพียงอย่างเดียว
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!