

Excel เป็นหนึ่งในเครื่องมือที่ทรงพลังที่สุดสำหรับการวิเคราะห์ข้อมูล แต่ก็มีข้อจำกัด เมื่อชุดข้อมูลขยายเป็นหลายล้านแถว เมื่อรายงานจำเป็นต้องทำงานโดยอัตโนมัติ หรือเมื่อการวิเคราะห์จำเป็นต้องมีการเรียนรู้ของเครื่อง Excel เพียงอย่างเดียวจะเริ่มแสดงอายุของมัน Python เติมเต็มช่องว่างเหล่านี้มากมาย การบูรณาการ Python ได้เปลี่ยน Excel จากเครื่องมือสเปรดชีตแบบดั้งเดิมให้เป็นแพลตฟอร์มการวิเคราะห์ข้อมูลที่ทรงพลังยิ่งขึ้น ด้วย Python ที่พร้อมใช้งานโดยตรงใน Excel ขณะนี้นักวิเคราะห์สามารถทำการคำนวณขั้นสูง สร้างแบบจำลองการคาดการณ์ และสร้างการแสดงภาพข้อมูลที่ซับซ้อนโดยไม่ต้องออกจากสมุดงาน
ในบทช่วยสอนนี้ เราจะแสดงไลบรารี Python ห้าไลบรารีสำหรับการวิเคราะห์ข้อมูล Excel ขั้นสูงที่มืออาชีพทุกคนควรใช้ ไลบรารีเหล่านี้ช่วยให้คุณสามารถจัดการข้อมูลขั้นสูง การแสดงภาพ และการเรียนรู้ของเครื่องได้โดยตรงภายใน Excel
1. Pandas – แกนหลักสำหรับการจัดการและวิเคราะห์ข้อมูล
หากคุณเรียนรู้ไลบรารี Python เพียงไลบรารีเดียวสำหรับการวิเคราะห์ Excel ให้เรียนรู้ Pandas ก่อน Pandas เป็นรากฐานสำหรับงานขั้นสูงที่เกี่ยวข้องกับ Excel เกือบทุกงานใน Python เปลี่ยนข้อมูล Excel ให้เป็น DataFrames อันทรงพลัง สำหรับการทำความสะอาด การแปลง การกรอง การจัดกลุ่ม การรวม การรวมกลุ่ม และการสำรวจชุดข้อมูลขนาดใหญ่อย่างมีประสิทธิภาพ
จุดแข็งหลักสำหรับ Excel Pro:
- อ่านและเขียนไฟล์ Excel แบบเนทิฟด้วย pd.read_excel() และ df.to_excel()
- จัดการข้อมูลที่ยุ่งเหยิง:ลบข้อมูลที่ซ้ำกัน เติมค่าที่หายไป และสร้างมาตรฐานให้กับรูปแบบ
- ดำเนินการจัดกลุ่มและการรวมกลุ่มขั้นสูงด้วยตรรกะที่นอกเหนือไปจาก PivotTable
- รวมหรือรวมหลายแผ่นงานหรือไฟล์
- สร้างสรุปทางสถิติด้วย df.describe()
- เรียกใช้โค้ดสองสามบรรทัดและรับผลลัพธ์เดียวกันทุกครั้ง
ตัวอย่าง:การล้างข้อมูลที่ยุ่งเหยิง
ปัญหาที่พบบ่อยใน Excel คือการรับข้อมูลที่มีประเภทผสม ค่าหายไป และการจัดรูปแบบไม่สอดคล้องกัน ด้วย Pandas คุณสามารถแก้ไขทุกสิ่งได้ในสคริปต์ที่ทำซ้ำได้เพียงสคริปต์เดียว
หลามใน Excel:
import pandas as pd
df = xl("A1:J10000", headers=True)
# Clean: strip spaces, convert types, fill missing
df['Category'] = df['Category'].str.strip()
df['Revenue'] = df['Units'] * df['UnitPrice'].fillna(0)
# Advanced summary: group by Region and Category
summary = df.groupby(['Region', 'Category']).agg({
'Revenue': 'sum',
'Units': 'sum'
}).reset_index()
summary
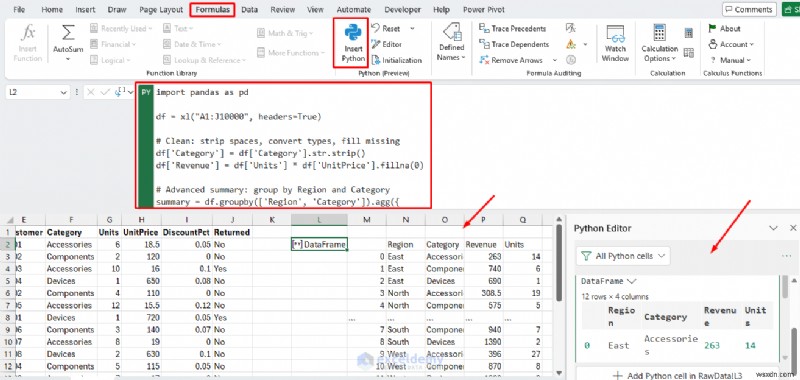
Python ในโค้ด VS:
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='RawData')
# Fix column types — handles numbers stored as text
df['Units'] = pd.to_numeric(df['Units'], errors='coerce').fillna(0).astype(int)
df['UnitPrice'] = pd.to_numeric(df['UnitPrice'], errors='coerce').fillna(0.0)
df['DiscountPct'] = pd.to_numeric(df['DiscountPct'], errors='coerce').fillna(0.0)
# Standardize boolean-like text columns
df['Returned'] = df['Returned'].astype(str).str.strip().str.lower() \
.map({'yes': True, 'no': False}).fillna(False)
# Add calculated columns
df['Revenue'] = df['Units'] * df['UnitPrice']
df['NetRevenue'] = df['Revenue'] * (1 - df['DiscountPct'])
# Write back as a new sheet — original data untouched
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
df.to_excel(writer, sheet_name='CleanData', index=False)
print('CleanData sheet created in', file_path)
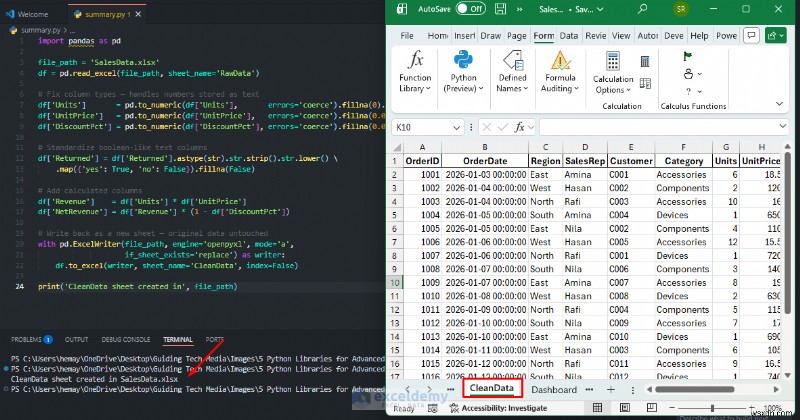
รายงานสรุปอัตโนมัติ
แทนที่ PivotTable แบบกำหนดเองด้วย Pandas groupby ขั้นตอนการทำงานที่ทำงานในไม่กี่วินาทีและส่งออกชีตที่พร้อมแชร์ทุกครั้งที่ข้อมูลของคุณอัปเดต:
summary = (
df.groupby(['Region', 'Category'], as_index=False)
.agg(
Orders = ('OrderID', 'count'),
Units = ('Units', 'sum'),
NetRevenue = ('NetRevenue', 'sum'),
Returns = ('Returned', 'sum')
)
)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
summary.to_excel(writer, sheet_name='Summary', index=False)
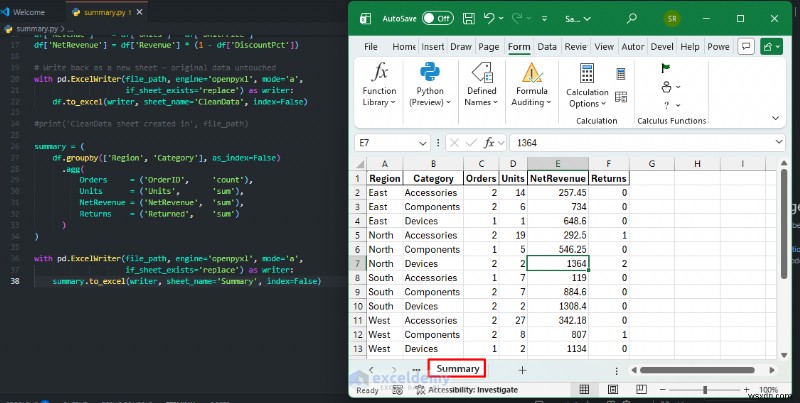
เมื่อใดควรใช้: คุณได้รับผลลัพธ์สไตล์ PivotTable แต่การล้างข้อมูลและตรรกะเกิดขึ้นในเวิร์กโฟลว์เดียวกัน นั่นหมายถึงรายงานที่เสียหายน้อยลงและการแทรกแซงด้วยตนเองน้อยลง ผู้ใช้ระดับสูงพึ่งพา Pandas ในการจัดการชุดข้อมูลที่มีขนาดใหญ่เกินไปหรือซับซ้อนเกินไปสำหรับ Excel แบบเนทีฟ โดยเฉพาะอย่างยิ่งเมื่อชุดข้อมูลมีจำนวนเกินสองสามพันแถว เมื่อคุณต้องการทำตามขั้นตอนการทำความสะอาดหรือการสรุปซ้ำ หรือเมื่อคุณต้องการผสานข้อมูลจากหลายแหล่งโดยอัตโนมัติ
2. OpenPyXL – การจัดการไฟล์ Excel ขั้นสูงและการจัดรูปแบบดั้งเดิม
ขณะที่ Pandas จัดการข้อมูล OpenPyXL เก่งในการควบคุม .xlsx แบบละเอียด ไฟล์:การจัดรูปแบบเซลล์ การเพิ่มแผนภูมิ ตาราง สไตล์ สูตร และรูปภาพ โดยไม่สูญเสียฟีเจอร์ดั้งเดิมของ Excel ช่วยให้คุณสามารถทำงานกับ .xlsx ได้โดยตรง ไฟล์ ดังนั้นเวิร์กโฟลว์ Python ของคุณสามารถสร้างเอาต์พุตที่พร้อมใช้งาน Excel แทนที่จะวิเคราะห์แบบดิบเพียงอย่างเดียว
จุดแข็งหลักสำหรับ Excel Pro:
- สร้างและแก้ไขสมุดงานโดยทางโปรแกรม
- ส่งออกตารางที่ล้างแล้วเป็นแผ่นงานใหม่
- เพิ่มแผนภูมิมืออาชีพโดยตรงในรูปแบบ Excel ที่อัปเดตอัตโนมัติ
- แทนที่แท็บรายงานเก่าโดยอัตโนมัติ
- ใช้การจัดรูปแบบตามเงื่อนไข เส้นขอบ แบบอักษร และสไตล์กับเซลล์ที่ต้องการ
- แทรกสูตร Excel เช่น =SUM() หรือ =VLOOKUP() เข้าสู่เซลล์
- ป้องกันแผ่นงาน ตรึงบานหน้าต่าง และตั้งค่าความกว้างของคอลัมน์โดยทางโปรแกรม
- สร้างการส่งมอบตามสมุดงานสำหรับผู้ใช้ที่ไม่ใช่ Python
ตัวอย่าง:การเพิ่มแผนภูมิเนทีฟลงในสมุดงานของคุณ
หลังจากสร้างข้อมูลที่สะอาดด้วย Pandas แล้ว ให้ใช้ openpyxl เพื่อเพิ่มแผนภูมิแท่งแบบมืออาชีพโดยไม่ต้องเปิด Excel ด้วยตนเอง
from openpyxl import load_workbook
from openpyxl.chart import BarChart, Reference
import pandas as pd
file_path = 'SalesData.xlsx'
df = pd.read_excel(file_path, sheet_name='CleanData')
chart_data = df.groupby('Region', as_index=False)['NetRevenue'] \
.sum().sort_values('NetRevenue', ascending=False)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a',
if_sheet_exists='replace') as writer:
chart_data.to_excel(writer, sheet_name='RegionChart', index=False)
wb = load_workbook(file_path)
ws = wb['RegionChart']
chart = BarChart()
chart.title = 'Net Revenue by Region'
chart.y_axis.title = 'Net Revenue ($)'
chart.x_axis.title = 'Region'
values = Reference(ws, min_col=2, min_row=1, max_row=ws.max_row)
labels = Reference(ws, min_col=1, min_row=2, max_row=ws.max_row)
chart.add_data(values, titles_from_data=True)
chart.set_categories(labels)
ws.add_chart(chart, 'D2')
wb.save(file_path)
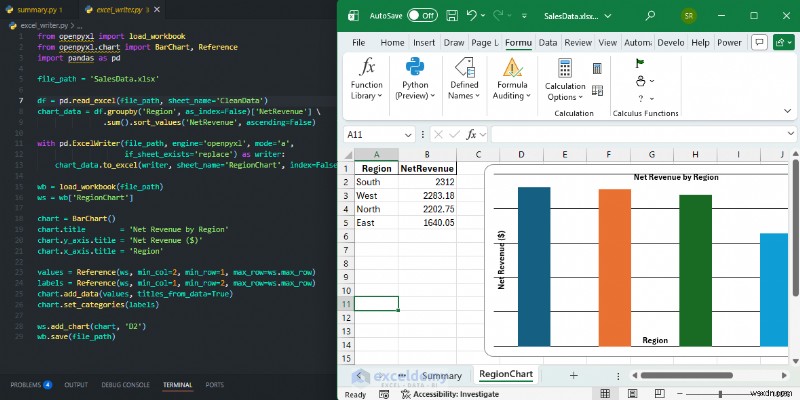
เมื่อใดควรใช้: Pandas ช่วยคุณวิเคราะห์ข้อมูล openpyxl ช่วยคุณส่งมอบมัน ใช้ OpenPyXL เมื่อคุณต้องการเอาต์พุต Excel ที่สมบูรณ์แบบทุกพิกเซล เช่น รายงานและแดชบอร์ดที่ดูสร้างขึ้นด้วยมือ และเมื่อผลลัพธ์ต้องอยู่ใน .xlsx ด้วยแผนภูมิ Excel ดั้งเดิมและการจัดรูปแบบที่เพื่อนร่วมงานสามารถแก้ไขได้ต่อไป
3. Matplotlib – การแสดงภาพอันทรงพลังที่เหนือกว่าแผนภูมิ Excel
แผนภูมิ Excel นั้นสะดวก แต่ Matplotlib ช่วยให้นักวิเคราะห์ควบคุมได้มากขึ้น Matplotlib เป็นไลบรารี่สำหรับสร้างโครงเรื่องคุณภาพสิ่งพิมพ์คงที่ สามารถปรับแต่งได้สูงและทำงานร่วมกับ Pandas ได้ดีเพื่อการวิเคราะห์เชิงสำรวจอย่างรวดเร็ว
จุดแข็งหลักสำหรับ Excel Pro:
- สร้างแผนภูมิขั้นสูง เช่น แผนที่ความร้อน แผนภูมิกระจายพร้อมเส้นแนวโน้ม แผนภูมิกล่อง ฮิสโตแกรม และแผนภูมิ 3 มิติ
- ควบคุมแบบอักษร สี เส้นตาราง เครื่องหมายถูก และคำอธิบายได้มากขึ้น
- สร้างเค้าโครงแผนย่อยแบบหลายแผงที่แสดงแผนภูมิหลายรายการพร้อมกัน
- ส่งออกเป็นรูปภาพ, PDF หรือ SVG หรือฝังภาพกลับเข้าไปใน Excel ด้วย OpenPyXL
- ใส่คำอธิบายประกอบจุดข้อมูลด้วยป้ายกำกับและลูกศรที่กำหนดเอง
ตัวอย่าง:การสร้างแดชบอร์ดการขายแบบหลายแผง
มาสร้างแผนภูมิสองแผง:แนวโน้มรายได้รายเดือนทางด้านซ้ายและรายละเอียดหมวดหมู่ทางด้านขวา จากนั้นเราจะบันทึกเป็นภาพที่มีความละเอียดสูง พร้อมสำหรับรายงานใดๆ
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
df['Month'] = pd.to_datetime(df['OrderDate']).dt.to_period('M')
monthly = df.groupby('Month')['NetRevenue'].sum()
cat_rev = df.groupby('Category')['NetRevenue'].sum().sort_values(ascending=True)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('Sales Performance Dashboard', fontsize=16, fontweight='bold')
# Left panel — monthly revenue line chart
ax1.plot(list(monthly.index.astype(str)), monthly.values,
marker='o', color='#1E5FAD', linewidth=2)
ax1.set_title('Monthly Net Revenue')
ax1.set_xlabel('Month')
ax1.set_ylabel('Revenue ($)')
ax1.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
ax1.tick_params(axis='x', rotation=45)
ax1.grid(axis='y', linestyle='--', alpha=0.5)
# Right panel — revenue by category horizontal bar chart
ax2.barh(cat_rev.index, cat_rev.values, color='#217346')
ax2.set_title('Revenue by Category')
ax2.set_xlabel('Revenue ($)')
ax2.xaxis.set_major_formatter(mticker.FuncFormatter(lambda x, _: f'${x:,.0f}'))
plt.tight_layout()
plt.savefig('sales_dashboard.png', dpi=150, bbox_inches='tight')
print('Dashboard saved as sales_dashboard.png')
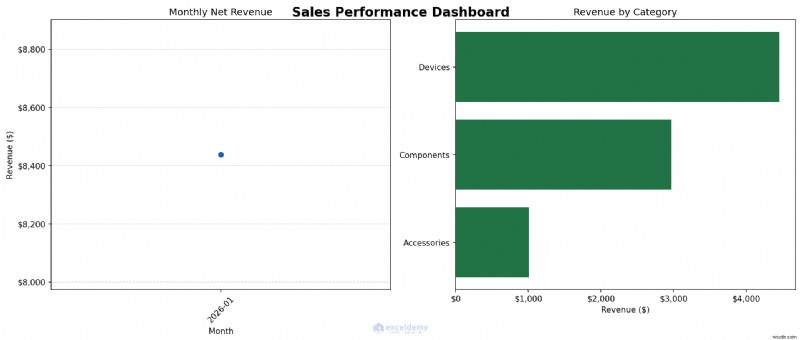
เมื่อใดควรใช้: ใช้ Python เพื่อสร้างแผนภูมิการวิเคราะห์ก่อน จากนั้นตัดสินใจว่าควรให้แผนภูมิยังคงเป็นเอาต์พุต Python หรือควรส่งคืนข้อมูลสรุปไปยัง Excel เพื่อจัดรูปแบบแดชบอร์ดขั้นสุดท้าย ใช้ Matplotlib เมื่อคุณต้องการแผนภูมิสำหรับรายงานหรือการนำเสนอ หรือเมื่อคุณต้องการสร้างแผนภูมิเดียวกันซ้ำๆ จากข้อมูลที่อัปเดตด้วยสไตล์ที่สอดคล้องกัน
4. Seaborn – การแสดงข้อมูลเชิงสถิติ
สัตว์ทะเล สร้างบน Matplotlib และมุ่งเน้นไปที่การแสดงภาพทางสถิติ มันช่วยลดความยุ่งยากในการสร้างแผนภูมิที่ดึงดูดสายตาซึ่งเน้นรูปแบบและความสัมพันธ์ ในกรณีที่ Matplotlib อาจต้องใช้หลายสิบบรรทัดสำหรับแผนภูมิที่สวยงาม Seaborn มักจะสามารถบรรลุผลลัพธ์ที่คล้ายกันในหนึ่งหรือสองบรรทัดด้วยสไตล์เริ่มต้นที่น่าดึงดูด มีความยอดเยี่ยมในการเปิดเผยการแจกแจง ความสัมพันธ์ และรูปแบบที่ซ่อนอยู่ในข้อมูลของคุณ
จุดแข็งหลักสำหรับ Excel Pro:
- สร้างแผนภูมิทางสถิติอย่างรวดเร็ว
- ทำงานได้ดีสำหรับการวิเคราะห์ข้อมูลเชิงสำรวจ
- สร้างแผนที่ความร้อนของความสัมพันธ์เพื่อดูว่าคอลัมน์เกี่ยวข้องกันอย่างไร
- สร้างแปลงกระจายสินค้าที่มีเส้นโค้งความหนาแน่นในตัว
- ใช้แปลงกล่องและแปลงไวโอลินเพื่อเปรียบเทียบกลุ่มด้วยสายตา
- สร้างพล็อตคู่สำหรับเมทริกซ์ Scatterplot อัตโนมัติในคอลัมน์ตัวเลข
- สร้างแผนการถดถอยด้วยช่วงความเชื่อมั่นในบรรทัดเดียว
ตัวอย่าง:การสร้างแผนที่ความร้อนสหสัมพันธ์
ค้นหารูปแบบที่ซ่อนอยู่ในข้อมูล Excel ของคุณ:ตัวแปรใดที่ย้ายไปรวมกัน แผนที่ความร้อนสามารถตอบคำถามนี้ได้อย่างรวดเร็วและทำได้ดีกว่าเครื่องมือในตัวของ Excel โดยทั่วไป
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
correlation = df.select_dtypes(include='number').corr()
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation,
annot=True, # show correlation values in each cell
fmt='.2f',
cmap='coolwarm', # red = positive, blue = negative
center=0,
square=True,
linewidths=0.5
)
plt.title('Correlation Matrix — Sales Variables', fontsize=14, fontweight='bold')
plt.tight_layout()
plt.savefig('correlation_heatmap.png', dpi=150)
print('Heatmap saved!')
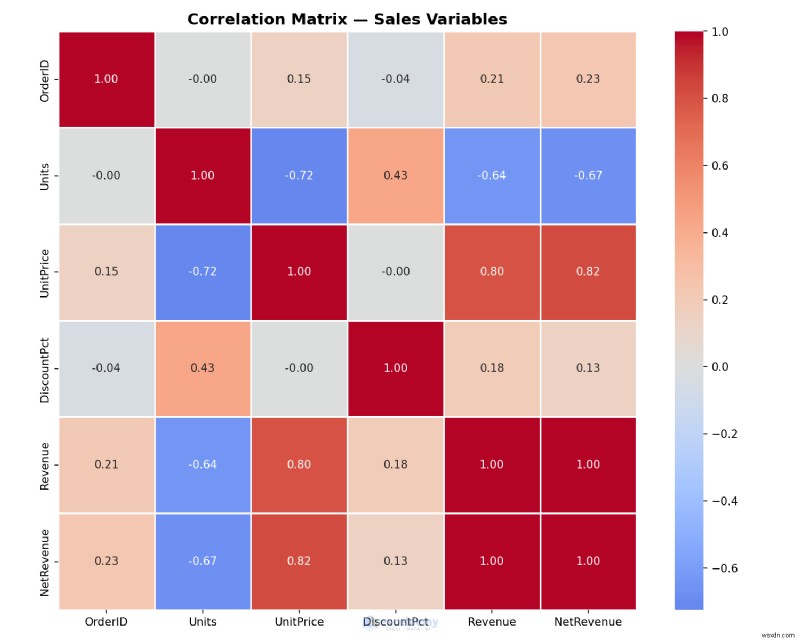
ตัวอย่าง:การสร้าง Box Plot ในหนึ่งบรรทัด
เปรียบเทียบการกระจายรายได้ข้ามภูมิภาคเพื่อระบุค่าผิดปกติได้ทันที
plt.figure(figsize=(10, 6))
sns.boxplot(data=df, x='Region', y='NetRevenue', hue='Region', palette='Set2', legend=False)
plt.title('Revenue Distribution by Region')
plt.ylabel('Net Revenue ($)')
plt.tight_layout()
plt.savefig('region_boxplot.png', dpi=150)
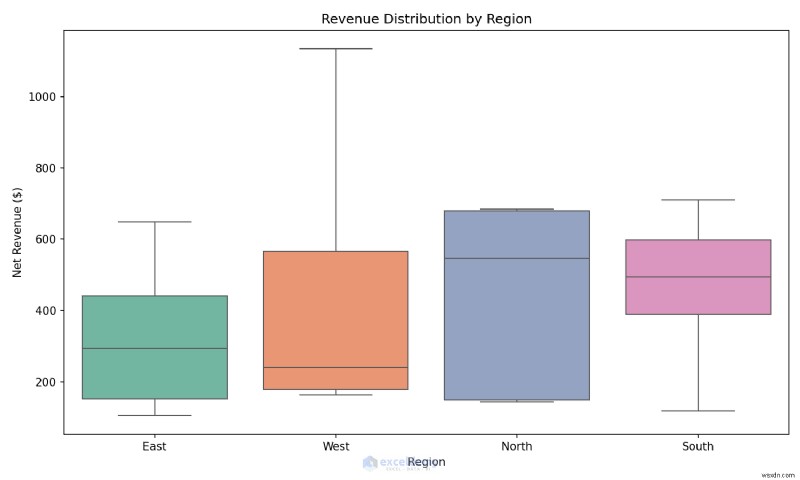
เมื่อใดควรใช้: ใช้ Seaborn ในระหว่างการวิเคราะห์เชิงสำรวจ เมื่อคุณต้องการทำความเข้าใจการแจกแจง ค่าผิดปกติ และความสัมพันธ์อย่างรวดเร็ว ก่อนที่จะสร้างรายงานอย่างเป็นทางการ
5. Scikit-learn – การเรียนรู้ของเครื่องบนข้อมูล Excel โดยตรง
นี่คือห้องสมุดที่ย้ายคุณจากการรายงานไปสู่การสนับสนุนการตัดสินใจ Scikit-เรียนรู้ นำการเรียนรู้ของเครื่องแบบมืออาชีพมาสู่เวิร์กโฟลว์ Excel ของคุณ ช่วยให้สามารถวิเคราะห์เชิงคาดการณ์สำหรับผู้ใช้ Excel รวมถึงการถดถอย การจัดหมวดหมู่ การจัดกลุ่ม และการคาดการณ์ที่ Excel ดั้งเดิมไม่สามารถจัดการได้อย่างง่ายดาย แทนที่จะอธิบายเฉพาะสิ่งที่เกิดขึ้นในข้อมูลของคุณ ข้อมูลนี้ช่วยให้คุณคาดการณ์สิ่งที่อาจเกิดขึ้นต่อไป ตั้งแต่การคาดการณ์ยอดขาย การจัดประเภทลูกค้า ไปจนถึงการตรวจจับความผิดปกติ
จุดแข็งหลักสำหรับ Excel Pro:
- การถดถอยเชิงเส้นและลอจิสติกเพื่อคาดการณ์ผลลัพธ์ที่เป็นตัวเลขหรือหมวดหมู่ เช่น ความเสี่ยงในการเลิกใช้งาน หรือการคาดการณ์ยอดขาย
- แผนผังการตัดสินใจและฟอเรสต์แบบสุ่มสำหรับการทำนายที่ตีความได้
- K-หมายถึงการจัดกลุ่มเพื่อจัดกลุ่มบันทึกที่คล้ายกันโดยอัตโนมัติ
- ฝึกการแยกการทดสอบและการตรวจสอบข้ามเพื่อวัดความแม่นยำของโมเดล
- การปรับขนาดคุณลักษณะ การเข้ารหัส และไปป์ไลน์การประมวลผลล่วงหน้า
- ส่งคืนการคาดการณ์ไปยัง Excel เพื่อการกรองและการเรียงลำดับ
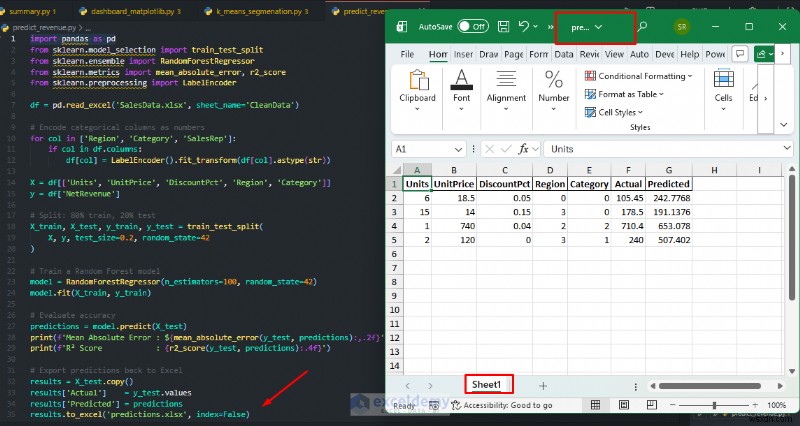
ตัวอย่าง:การคาดการณ์รายได้สุทธิ
ฝึกแบบจำลองเกี่ยวกับข้อมูลการขายในอดีตของคุณ จากนั้นใช้แบบจำลองนั้นเพื่อคาดการณ์รายได้สำหรับคำสั่งซื้อใหม่ ซึ่งเป็นการวิเคราะห์ที่ Excel ไม่สามารถทำได้ตามปกติ
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import LabelEncoder
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
# Encode categorical columns as numbers
for col in ['Region', 'Category', 'SalesRep']:
if col in df.columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df[['Units', 'UnitPrice', 'DiscountPct', 'Region', 'Category']]
y = df['NetRevenue']
# Split: 80% train, 20% test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train a Random Forest model
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Evaluate accuracy
predictions = model.predict(X_test)
print(f'Mean Absolute Error: ${mean_absolute_error(y_test, predictions):,.2f}')
print(f'R² Score: {r2_score(y_test, predictions):.4f}')
# Export predictions back to Excel
results = X_test.copy()
results['Actual'] = y_test.values
results['Predicted'] = predictions
results.to_excel('predictions.xlsx', index=False)
print('Predictions exported to predictions.xlsx')
การแบ่งส่วนลูกค้า K-Means:
แบ่งกลุ่มลูกค้าออกเป็นกลุ่มโดยอัตโนมัติตามพฤติกรรมการซื้อ โดยไม่ต้องใช้เกณฑ์ด้วยตนเอง
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
df = pd.read_excel('SalesData.xlsx', sheet_name='CleanData')
customer = df.groupby('Customer').agg(
TotalOrders = ('OrderID', 'count'),
TotalRevenue = ('NetRevenue', 'sum'),
AvgDiscount = ('DiscountPct', 'mean')
).reset_index()
X_scaled = StandardScaler().fit_transform(
customer[['TotalOrders', 'TotalRevenue', 'AvgDiscount']]
)
customer['Segment'] = KMeans(n_clusters=3, random_state=42, n_init=10) \
.fit_predict(X_scaled)
customer.to_excel('customer_segments.xlsx', index=False)
print('Segmentation complete! See customer_segments.xlsx')
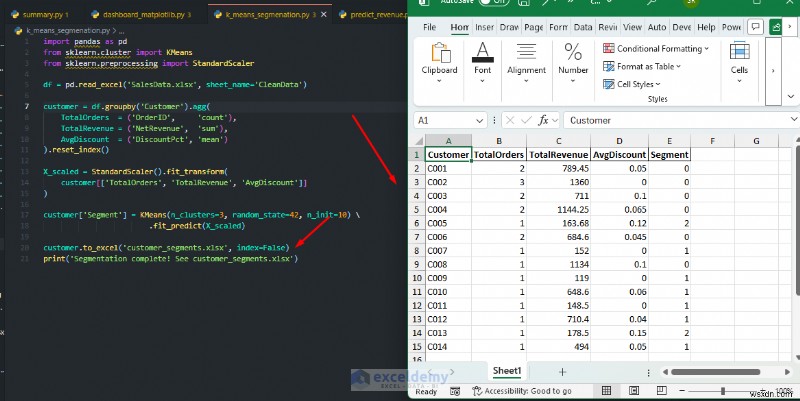
เมื่อใดควรใช้: คุณสามารถเขียนการคาดคะเนกลับเข้าไปในเวิร์กชีต จากนั้นให้ผู้ใช้ Excel กรอง จัดเรียง สร้างแผนภูมิ หรือรวมผลลัพธ์เข้ากับสูตรและการจัดรูปแบบตามเงื่อนไข ช่วยให้มืออาชีพสามารถเพิ่มข้อมูลเชิงลึกของแมชชีนเลิร์นนิงกลับเข้าไปในสเปรดชีตได้โดยตรง ใช้ Scikit-learn เมื่อคุณต้องการคาดการณ์ค่าในอนาคต จัดประเภทบันทึก หรือค้นหาการจัดกลุ่มตามธรรมชาติที่ PivotTable ไม่สามารถเปิดเผยได้
โบนัส:Xlwings – การทำงานอัตโนมัติแบบสองทิศทางและการรวม Live Excel
xlwings ไลบรารีรันอินสแตนซ์ Excel แบบเรียลไทม์ มันเชื่อมโยง Python และ Excel เข้าด้วยกัน ทำให้เกิดการทำงานอัตโนมัติอย่างแท้จริง ในขณะที่ openpyxl อ่านและเขียนไฟล์คงที่ xlwings สามารถเปิด Excel จัดการมันแบบเรียลไทม์ อ่านค่ากลับเข้าไปใน Python เรียกใช้ฟังก์ชัน Python จากปุ่ม Excel และสร้าง UDF แบบเต็ม (ฟังก์ชันที่ผู้ใช้กำหนด) ที่ปรากฏในเซลล์ มันเป็นทางเลือกที่ทันสมัยแทนเวิร์กโฟลว์ที่ใช้ VBA จำนวนมาก
จุดแข็งหลักสำหรับ Excel Pro:
- ควบคุมเซสชัน Excel แบบสด:เปิด อ่าน เขียน และปิดสมุดงานโดยทางโปรแกรม
- เขียนฟังก์ชัน Python ที่สามารถเรียกได้โดยตรงจากเซลล์ Excel เป็น UDF
- ทำงานที่ซ้ำกันโดยอัตโนมัติ เช่น การรีเฟรชข้อมูลและการสร้างรายงาน
- พุชแผนภูมิ Pandas DataFrames และ Matplotlib ไปยังช่วงที่ตั้งชื่อโดยตรง
- เรียกใช้สคริปต์ Python ที่ถูกกระตุ้นโดยปุ่ม Excel
- ทำงานได้ทั้งบน Windows และ macOS
- เป็นทางเลือกที่ดีหรือเป็นส่วนเสริมของ Python ใน Excel สำหรับเวิร์กโฟลว์เดสก์ท็อป
คุณสามารถใช้ xlwings เมื่อคุณต้องการโต้ตอบแบบสดสองทางกับ Excel เมื่อแทนที่มาโคร VBA เมื่อสร้างแดชบอร์ดแบบโต้ตอบ หรือเมื่ออนุญาตให้เพื่อนร่วมงานที่ไม่ใช่ด้านเทคนิคเรียกใช้การวิเคราะห์ Python ด้วยการคลิกปุ่ม
การเลือกไลบรารีสแต็กที่ดีที่สุดสำหรับผู้เชี่ยวชาญด้าน Excel ที่แตกต่างกัน
ไม่ใช่นักวิเคราะห์ทุกคนที่ต้องการไลบรารีทั้งห้าพร้อมกัน วิธีปฏิบัติในทางปฏิบัติในการรับเลี้ยงบุตรบุญธรรมคือตามบทบาท
- สำหรับนักวิเคราะห์การรายงาน: การรวมกันนี้ช่วยให้คุณล้างข้อมูล สร้างบทสรุป สร้างแผนภูมิ และส่งออกผลลัพธ์สมุดงานที่สวยงามได้
- แพนด้า
- Matplotlib
- Openpyxl
- สำหรับนักวิเคราะห์การเงินและการดำเนินงาน: สแต็กนี้ทำงานได้ดีสำหรับการสร้างแบบจำลอง การคำนวณ KPI การจัดสรร และการรายงานรายเดือนที่ทำซ้ำได้
- แพนด้า
- ซีบอร์น
- Openpyxl
- สำหรับทีมวิเคราะห์ขั้นสูง: การรวมกันนี้ช่วยให้คุณได้รับขั้นตอนทั้งหมดตั้งแต่การเตรียมข้อมูล การให้คะแนนเชิงคาดการณ์ ไปจนถึงการจัดส่งสมุดงาน
- แพนด้า
- Matplotlib
- Scikit-เรียนรู้
- Openpyxl
- ซีบอร์น
ความคิดสุดท้าย
นี่คือไลบรารี Python ห้าไลบรารีสำหรับการวิเคราะห์ข้อมูล Excel ขั้นสูงที่มืออาชีพทุกคนควรใช้ ฝึกฝนเครื่องมือเหล่านี้ให้เชี่ยวชาญ และคุณสามารถแปลง Excel จากแอปพลิเคชันสเปรดชีตธรรมดาให้เป็นแพลตฟอร์มการวิเคราะห์ที่มีความสามารถมากขึ้น เส้นทางการเรียนรู้ที่สมเหตุสมผลคือการเริ่มต้นด้วย Pandas จากนั้นเพิ่ม openpyxl จากนั้นเรียนรู้ Matplotlib และ Seaborn ร่วมกัน และจัดการกับ Scikit-learn หลังจากนั้น แต่ละไลบรารีใช้งานได้กับ .xlsx เดียวกัน ไฟล์ที่คุณใช้อยู่แล้ว เริ่มสำรวจพวกเขาเพื่อเป็นนักวิเคราะห์ข้อมูลที่มีความสามารถมากขึ้น
รับแบบฝึกหัด Excel ขั้นสูงพร้อมโซลูชันฟรี!