
ในโพสต์นี้ เราจะเรียนรู้พื้นฐานของโครงข่ายประสาทเทียมและวิธีที่เราสามารถปรับใช้มันโดยใช้ Ruby! หากคุณรู้สึกทึ่งกับปัญญาประดิษฐ์และการเรียนรู้เชิงลึก แต่ไม่แน่ใจว่าจะเริ่มต้นอย่างไร โพสต์นี้เหมาะสำหรับคุณ! เราจะพูดถึงตัวอย่างง่ายๆ เพื่อเน้นแนวคิดหลัก ไม่น่าเป็นไปได้มากที่คุณจะใช้ Ruby ในการเขียนโครงข่ายประสาทเทียมแบบหลายชั้น แต่เพื่อความเรียบง่ายและอ่านง่าย มันเป็นวิธีที่ดีในการทำความเข้าใจว่าเกิดอะไรขึ้น ขั้นแรก ลองย้อนกลับไปดูว่าเรามาที่นี่ได้อย่างไร
 ภาพนิ่งจากภาพยนตร์เรื่อง Ex Machnia เครดิตภาพ
ภาพนิ่งจากภาพยนตร์เรื่อง Ex Machnia เครดิตภาพ
Ex Machina เป็นภาพยนตร์ที่ออกฉายในปี 2014 หากคุณค้นหาชื่อใน Google จะจำแนกประเภทของภาพยนตร์เป็น "Drama/Fantasy" และเมื่อผมดูหนังเรื่องนี้ครั้งแรก มันดูเหมือนนิยายวิทยาศาสตร์
แต่ นานมากไหม
หากคุณถาม Ray Kurzweil นักอนาคตนิยมที่มีชื่อเสียงซึ่งทำงานที่ Google ปี 2029 อาจเป็นปีปัญญาประดิษฐ์ที่จะผ่านการทดสอบทัวริงที่ถูกต้อง (ซึ่งเป็นการทดลองเพื่อดูว่ามนุษย์สามารถแยกแยะระหว่างเครื่อง/คอมพิวเตอร์กับมนุษย์คนอื่นได้หรือไม่ ) นอกจากนี้ เขายังคาดการณ์ว่าภาวะภาวะเอกฐาน (เมื่อคอมพิวเตอร์มีสติปัญญาเหนือกว่ามนุษย์) จะเกิดขึ้นภายในปี 2045
อะไรทำให้เคิร์ซไวล์มั่นใจ?
การเกิดขึ้นของการเรียนรู้เชิงลึก
พูดง่ายๆ ก็คือ การเรียนรู้เชิงลึกเป็นส่วนย่อยของแมชชีนเลิร์นนิงที่ใช้โครงข่ายประสาทเทียมเพื่อดึงข้อมูลเชิงลึกจากข้อมูลจำนวนมาก แอปพลิเคชันการเรียนรู้เชิงลึกในโลกแห่งความเป็นจริงมีดังนี้:- รถยนต์ที่ขับด้วยตนเอง - การตรวจหามะเร็ง - ผู้ช่วยเสมือน เช่น Siri และ Alexa - การทำนายเหตุการณ์สภาพอากาศสุดขั้ว เช่น แผ่นดินไหว
แต่ "โครงข่ายประสาทเทียม" คืออะไร
โครงข่ายประสาทได้ชื่อมาจากเซลล์ประสาท ซึ่งเป็นเซลล์สมองที่ประมวลผลและส่งข้อมูลผ่านสัญญาณไฟฟ้าและเคมี เกร็ดน่ารู้:สมองของมนุษย์ประกอบด้วยเซลล์ประสาทมากกว่า 80 พันล้านเซลล์!
ในการคำนวณ โครงข่ายประสาทเทียมมีลักษณะดังนี้:
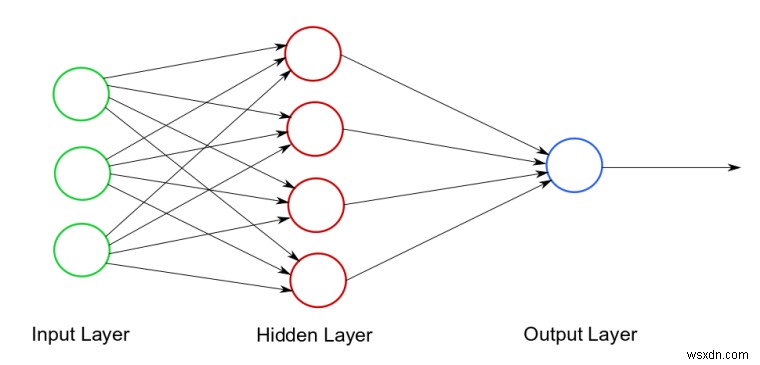 ตัวอย่างแผนภาพโครงข่ายประสาทเทียม เครดิตภาพ
ตัวอย่างแผนภาพโครงข่ายประสาทเทียม เครดิตภาพ
อย่างที่คุณเห็น มีสามส่วน:1) เลเยอร์อินพุต - ข้อมูลเริ่มต้น 2) เลเยอร์ที่ซ่อนอยู่ - โครงข่ายประสาทเทียมสามารถมี 1 (หรือมากกว่า) เลเยอร์ที่ซ่อนอยู่ นี่คือที่ที่การคำนวณทั้งหมดเสร็จสิ้น! 3) เลเยอร์เอาต์พุต -- ผลลัพธ์สุดท้าย/การทำนาย
บทเรียนประวัติศาสตร์ฉบับย่อ
โครงข่ายประสาทเทียมไม่ใช่เรื่องใหม่ อันที่จริง โครงข่ายประสาทเทียมที่สามารถฝึกได้เครื่องแรก (Perceptron) ได้รับการพัฒนาที่ Cornell University ในปี 1950 อย่างไรก็ตาม มีการมองโลกในแง่ร้ายมากมายเกี่ยวกับการบังคับใช้โครงข่ายประสาทเทียม ส่วนใหญ่เป็นเพราะแบบจำลองดั้งเดิมประกอบด้วยเลเยอร์ที่ซ่อนอยู่เพียงชั้นเดียว หนังสือที่ตีพิมพ์ในปี 2512 แสดงให้เห็นว่าการใช้ Perceptron สำหรับการคำนวณที่ค่อนข้างง่ายจะไม่สามารถทำได้
การฟื้นตัวของโครงข่ายประสาทเทียมเกิดจากเกมคอมพิวเตอร์ ซึ่งขณะนี้ต้องใช้หน่วยประมวลผลกราฟิก (GPU) ที่ใช้พลังงานสูงมาก ซึ่งมีสถาปัตยกรรมที่คล้ายคลึงกับโครงข่ายประสาท ความแตกต่างคือจำนวนเลเยอร์ที่ซ่อนอยู่ แทนที่จะเป็นหนึ่งโครงข่ายประสาทเทียมที่ได้รับการฝึกฝนในวันนี้ใช้ 10, 15 หรือ 50+ ชั้น!
เวลาตัวอย่าง!
เพื่อให้เข้าใจวิธีการทำงาน มาดูตัวอย่างกัน คุณจะต้องติดตั้ง ruby-fann อัญมณี. เปิดเทอร์มินัลของคุณและย้ายไปยังไดเร็กทอรีการทำงานของคุณ จากนั้นเรียกใช้สิ่งต่อไปนี้:
gem install ruby-fann
สร้างไฟล์ Ruby ใหม่ (ฉันตั้งชื่อของฉันว่า neural-net.rb ).
ต่อไป เราจะใช้ชุดข้อมูล "การบริโภคแอลกอฮอล์ของนักเรียน" จาก Kaggle คุณสามารถดาวน์โหลดได้ที่นี่ เปิดไฟล์ "student-mat.csv" ใน Google ชีต (หรือเครื่องมือแก้ไขที่คุณเลือก) ลบคอลัมน์ทั้งหมด ยกเว้นคอลัมน์เหล่านี้:- Dalc (การบริโภคแอลกอฮอล์ในวันทำงาน โดยที่ 1 ต่ำมากและ 5 สูงมาก) - Walc (การบริโภคเครื่องดื่มแอลกอฮอล์ในช่วงสุดสัปดาห์ที่ 1 ต่ำมากและ 5 สูงมาก) - G3 (ระดับสุดท้ายระหว่าง 0 ถึง 20)
เราจำเป็นต้องเปลี่ยนคอลัมน์เกรดสุดท้ายเป็นเลขฐานสอง -- ไม่ว่าจะเป็น 0 หรือ 1 -- เพื่อให้อัญมณีทับทิมทำงาน สำหรับตัวอย่างนี้ เราจะถือว่าอะไรที่น้อยกว่าหรือเท่ากับ 10 เป็น "0" และมากกว่า 10 เป็น "1" ขึ้นอยู่กับโปรแกรมที่คุณใช้ คุณควรสามารถเขียนสูตรในเซลล์เพื่อเปลี่ยนค่าเป็น 1 หรือ 0 โดยอัตโนมัติตามค่าของเซลล์ ใน Google ชีต จะมีลักษณะดังนี้:
=IF(C3 >= 10, 1, 0)
บันทึกข้อมูลนี้เป็นไฟล์ .CSV (ฉันตั้งชื่อของฉันว่า students.csv ) ในไดเร็กทอรีเดียวกันกับไฟล์ Ruby ของคุณ
โครงข่ายประสาทเทียมของเราจะมีเลเยอร์ดังต่อไปนี้:- เลเยอร์อินพุต:2 โหนด (การบริโภคแอลกอฮอล์ในวันทำงานและการบริโภคแอลกอฮอล์ในช่วงสุดสัปดาห์)- เลเยอร์ที่ซ่อนอยู่:6 โหนดที่ซ่อนไว้ (ซึ่งค่อนข้างจะเริ่มต้นโดยพลการ คุณสามารถแก้ไขได้ในภายหลังขณะทดสอบ)- เอาต์พุต เลเยอร์:1 โหนด (ทั้ง 0 หรือ 1)
ขั้นแรก เราจะต้องกำหนดให้ ruby-fann gem เช่นเดียวกับในตัว csv ห้องสมุด. เพิ่มสิ่งนี้ในบรรทัดแรกในโปรแกรม Ruby ของคุณ:
require 'ruby-fann'
require 'csv'
ต่อไป เราต้องโหลดข้อมูลจากไฟล์ CSV ของเราลงในอาร์เรย์
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
ต่อไป เราต้องแบ่งข้อมูลออกเป็นข้อมูลการฝึกอบรมและการทดสอบ การแบ่ง 80/20 เป็นเรื่องปกติ โดยที่ข้อมูลของคุณ 20% ใช้สำหรับการทดสอบและ 80% สำหรับการฝึกอบรม "การฝึกอบรม" ในที่นี้หมายความว่าโมเดลจะเรียนรู้จากข้อมูลนี้ จากนั้นเราจะใช้ข้อมูล "การทดสอบ" เพื่อดูว่าโมเดลคาดการณ์ผลลัพธ์ได้ดีเพียงใด
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
เย็น! เรามีข้อมูลของเราพร้อมที่จะไป ถัดมาคือความมหัศจรรย์!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
เราใช้วัตถุ RubyFann::TrainData และส่งผ่าน x_train_data, ของเรา ซึ่งเป็นการบริโภคเครื่องดื่มแอลกอฮอล์ในวันทำงานและวันหยุดสุดสัปดาห์ และ y_train_data, . ของเรา ซึ่งเป็น 0 หรือ 1 ตามเกรดของหลักสูตรสุดท้าย
ตอนนี้ มาตั้งค่าโมเดลโครงข่ายประสาทเทียมจริงของเราด้วยจำนวนเซลล์ประสาทที่ซ่อนอยู่ที่เราพูดถึงก่อนหน้านี้
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
โอเค ได้เวลาซ้อมแล้ว!
model.train_on_data(train, 1000, 10, 0.01)
ที่นี่เราผ่านใน train ตัวแปรที่เราสร้างไว้ก่อนหน้านี้ 1,000 หมายถึงจำนวนของ max_epochs 10 หมายถึงจำนวนข้อผิดพลาดระหว่างรายงาน และ 0.1 คือข้อผิดพลาดของค่าเฉลี่ยกำลังสองที่ต้องการ ยุคหนึ่งคือเมื่อชุดข้อมูลทั้งหมดถูกส่งผ่านโครงข่ายประสาทเทียม ข้อผิดพลาดเฉลี่ยกำลังสองคือสิ่งที่เรากำลังพยายามย่อให้เล็กสุด คุณสามารถอ่านเพิ่มเติมเกี่ยวกับความหมายได้ที่นี่
ต่อไป เราต้องการทราบว่าแบบจำลองของเราทำได้ดีเพียงใดโดยเปรียบเทียบสิ่งที่แบบจำลองคาดการณ์ไว้สำหรับข้อมูลการทดสอบของเรากับผลลัพธ์จริง เราสามารถทำได้โดยใช้รหัสนี้:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
เรียกใช้โปรแกรมของเราและดูว่าเกิดอะไรขึ้น!
ruby neural-net.rb
คุณควรเห็นผลลัพธ์มากมายสำหรับยุค แต่ที่ด้านล่าง คุณควรเห็นสิ่งนี้:
Accuracy: 56.82% - test set of size 20.0%
อ๊อฟ มันไม่ดีนะ! แต่มากับจุดข้อมูลของเราเองและเรียกใช้แบบจำลอง
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
ในที่นี้ เรามีตัวอย่างสองตัวอย่าง อย่างแรก เรากำลังผ่าน 1 วินาทีสำหรับการบริโภคเครื่องดื่มแอลกอฮอล์ในวันธรรมดาและวันหยุดสุดสัปดาห์ ถ้าฉันเป็นนักพนัน ฉันเดาว่านักเรียนคนนี้จะมีเกรดสุดท้ายมากกว่า 10 (เช่น 1) ตัวอย่างที่สองส่งผ่านค่าสูง (5 และ 4) สำหรับการบริโภคเครื่องดื่มแอลกอฮอล์ ดังนั้นฉันเดาว่านักเรียนคนนี้จะมีเกรดสุดท้ายเท่ากับหรือต่ำกว่า 10 (เช่น 0) มาเริ่มโปรแกรมของเราอีกครั้งและดูว่าเกิดอะไรขึ้น!
ผลลัพธ์ของคุณควรมีลักษณะดังนี้:
Algorithm predicted class: [1]
Algorithm predicted class: [0]
แบบจำลองของเราดูเหมือนจะทำในสิ่งที่เราคาดหวังสำหรับตัวเลขที่ปลายล่างหรือสูงกว่าของสเปกตรัม แต่มันยากลำบากเมื่อตัวเลขตรงข้ามกัน (ลองผสมหลายๆ อย่างกัน -- 1 และ 5 หรือ 2 และ 3 เป็นตัวอย่าง) หรือตรงกลาง เรายังสามารถดูได้จากข้อมูลในยุคของเราว่า แม้ว่าข้อผิดพลาดจะลดลง แต่ก็ยังสูงมาก (กลาง-20%) ซึ่งหมายความว่าอาจไม่มีความสัมพันธ์ระหว่างการบริโภคเครื่องดื่มแอลกอฮอล์และเกรดของหลักสูตร ฉันแนะนำให้คุณลองเล่นกับชุดข้อมูลดั้งเดิมจาก Kaggle - มีตัวแปรอิสระอื่น ๆ ที่เราสามารถใช้ทำนายผลลัพธ์ของหลักสูตรได้หรือไม่
สรุป
มีความสลับซับซ้อนมากมาย (ส่วนใหญ่เกี่ยวกับคณิตศาสตร์) ที่เกิดขึ้นภายใต้ประทุนเพื่อทำงานทั้งหมดนี้ หากคุณสงสัยและต้องการเรียนรู้เพิ่มเติม ฉันขอแนะนำให้ดูเอกสารใน FANN หรือดูซอร์สโค้ดของ ruby-fann อัญมณี. ฉันยังแนะนำให้ดูสารคดี "AlphaGo" บน Netflix ด้วย เพราะไม่ต้องใช้ความรู้ทางเทคนิคมากนักจึงจะสนุกกับมันได้ และให้ตัวอย่างที่ดีในชีวิตจริงว่าการเรียนรู้อย่างลึกซึ้งนั้นผลักดันขีดจำกัดของสิ่งที่คอมพิวเตอร์สามารถทำได้สำเร็จได้อย่างไร
Kurzweil จะลงเอยด้วยการทำนายที่ถูกต้องหรือไม่? เวลาเท่านั้นที่จะบอก!
