
เผยแพร่ครั้งแรกโดย Tricore:11 กรกฎาคม 2017
ในตอนที่ 1 ของซีรีส์สองส่วนนี้บน Apache™ Hadoop® เราได้แนะนำ Hadoopecosystem และเฟรมเวิร์ก Hadoop ในส่วนที่ 2 เราครอบคลุมส่วนประกอบหลักเพิ่มเติมของเฟรมเวิร์ก Hadoop รวมถึงการสืบค้น การรวมภายนอก การแลกเปลี่ยนข้อมูล การประสานงาน และการจัดการ นอกจากนี้เรายังแนะนำโมดูลที่ตรวจสอบคลัสเตอร์ Hadoop
กำลังค้นหา
ส่วนที่ 1 ของซีรีส์นี้แนะนำ Apache Pig™ เป็นเครื่องมือเขียนสคริปต์ ซึ่งเขียนด้วยภาษา Pig Latin โดย Pig ได้รับการแปลเป็นงาน MapReduce ที่ปฏิบัติการได้ มีข้อดีหลายประการที่คุณสามารถเรียนรู้เพิ่มเติมได้ในส่วนที่ 1
อย่างไรก็ตาม นักพัฒนาบางคนยังคงชอบ SQL หากคุณต้องการใช้สิ่งที่คุณรู้ คุณสามารถใช้ SQL กับ Hadoop แทนได้
รัง
Apache Hive™ เป็นคลังข้อมูลแบบกระจายที่จัดการและจัดระเบียบข้อมูลจำนวนมาก คลังสินค้านี้สร้างขึ้นบน HadoopDistributed File System (HDFS™) ภาษาคิวรี Hive HiveQL อิงตามความหมายของ SQL เอ็นจิ้นรันไทม์แปลง HiveQL เป็นงาน MapReduce ที่สืบค้นข้อมูล
Hive มีความสามารถดังต่อไปนี้:
-
ที่เก็บข้อมูลแผนผังสำหรับเก็บข้อมูลดิบจำนวนมาก
-
สภาพแวดล้อมเหมือน SQL สำหรับดำเนินการวิเคราะห์และสืบค้นข้อมูลดิบใน HDFS
-
บูรณาการกับแอปพลิเคชันระบบจัดการฐานข้อมูลเชิงสัมพันธ์ภายนอก (RDBMS)
ภาพต่อไปนี้แสดงภาพสถาปัตยกรรมของระบบนิเวศ Hadoop:
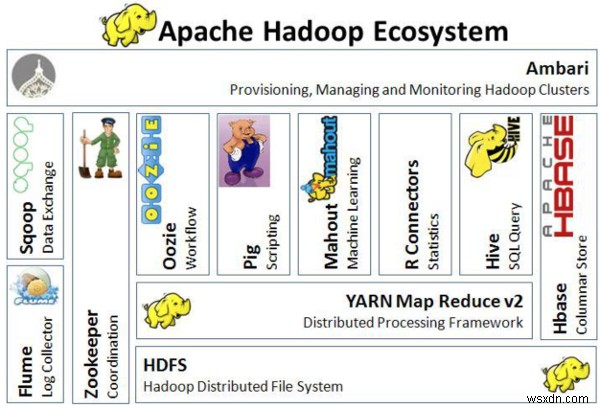 สถาปัตยกรรมของระบบนิเวศ Hadoop
สถาปัตยกรรมของระบบนิเวศ Hadoop การรวมภายนอก
Apache Flume™ เป็นบริการที่กระจาย เชื่อถือได้ และพร้อมใช้งานเพื่อการรวบรวม รวบรวม และย้ายข้อมูลบันทึกจำนวนมากไปยัง HDFS อย่างมีประสิทธิภาพ Flume ส่งข้อมูลเหตุการณ์ปริมาณมากโดยใช้สถาปัตยกรรมกระแสข้อมูลการสตรีมที่ทนทานต่อข้อผิดพลาดและพร้อมกู้คืนเมื่อเกิดข้อผิดพลาด
Flume ยังมีความสามารถดังต่อไปนี้:
-
ส่งข้อมูลเหตุการณ์จำนวนมาก เช่น การรับส่งข้อมูลในเครือข่าย บันทึก และข้อความอีเมล
-
สตรีมข้อมูลจากหลายแหล่งไปยัง HDFS
-
รับประกันการสตรีมข้อมูลแบบเรียลไทม์ที่เชื่อถือได้ไปยังแอปพลิเคชัน Hadoop
การแลกเปลี่ยนข้อมูล
Apache Sqoop™ ได้รับการออกแบบมาเพื่อถ่ายโอนข้อมูลจำนวนมากระหว่าง Hadoop และที่จัดเก็บข้อมูลภายนอก เช่น ฐานข้อมูลเชิงสัมพันธ์และคลังข้อมูลองค์กร Sqoop ทำงานร่วมกับฐานข้อมูลเชิงสัมพันธ์ เช่น TeradataDatabase, IBM® Netezza, Oracle® Database, MySQL™ และPostgreSQL® Sqoop ใช้กันอย่างแพร่หลายในบริษัทส่วนใหญ่ที่รวบรวม oranalyze big data
Sqoop มีฟังก์ชันดังต่อไปนี้:
-
มันสามารถทำให้กระบวนการส่วนใหญ่อธิบายสคีมาสำหรับข้อมูลที่นำเข้าเป็นไปโดยอัตโนมัติทั้งนี้ขึ้นอยู่กับฐานข้อมูล
-
ใช้กรอบงาน MapReduce เพื่อนำเข้าและส่งออกข้อมูล ซึ่งช่วยให้Sqoopมีกลไกคู่ขนานและความทนทานต่อข้อผิดพลาด
-
มีตัวเชื่อมต่อสำหรับฐานข้อมูล RDBMS หลักทั้งหมด
-
รองรับการโหลดแบบเต็มและที่เพิ่มขึ้น การส่งออกและนำเข้าข้อมูลแบบคู่ขนาน และการบีบอัดข้อมูล
-
รองรับการรวมระบบรักษาความปลอดภัย Kerberos
ประสานงาน
Apache Zookeeper™ เป็นบริการประสานงานสำหรับแอปพลิเคชันแบบกระจายที่เปิดใช้งานการซิงโครไนซ์ข้ามคลัสเตอร์ ให้พื้นที่เก็บข้อมูลแบบรวมศูนย์ซึ่งแอปพลิเคชันแบบกระจายสามารถจัดเก็บและเรียกข้อมูลได้
Zookeeper คือเครื่องมือ Hadoop ด้านการบริหารที่ใช้จัดการงานในกลุ่ม นักพัฒนาบางคนอ้างถึงเครื่องมือนี้ว่าเป็น “ยาม” เนื่องจากการเปลี่ยนแปลงใดๆ ของข้อมูลในโหนดหนึ่งจะถูกส่งไปยังโหนดอื่น
การจัดเตรียม การจัดการ และตรวจสอบคลัสเตอร์ Hadoop
Apache Ambari™ เป็นเครื่องมือบนเว็บสำหรับการจัดเตรียม จัดการ และตรวจสอบคลัสเตอร์ Apache Hadoop มีอินเทอร์เฟซผู้ใช้ที่เรียบง่ายแต่มีการโต้ตอบสูงสำหรับการติดตั้งเครื่องมือและดำเนินการจัดการ การกำหนดค่า และการตรวจสอบ Ambari มีแดชบอร์ดสำหรับการดูข้อมูลเกี่ยวกับความสมบูรณ์ของคลัสเตอร์ เช่น แผนที่ความร้อน นอกจากนี้ยังช่วยให้คุณสามารถดูแอปพลิเคชัน MapReduce, Pig และ Hive ควบคู่ไปกับคุณลักษณะต่างๆ เพื่อให้คุณสามารถวิเคราะห์คุณลักษณะด้านประสิทธิภาพได้อย่างง่ายดาย
แอมบารียังมีความสามารถดังต่อไปนี้:
-
การทำแผนที่บริการหลักด้วยโหนด
-
ความสามารถในการเลือกบริการที่คุณต้องการติดตั้ง
-
การเลือกสแต็กแบบกำหนดเองอย่างง่าย
-
อินเทอร์เฟซที่สะอาดขึ้น
-
การติดตั้ง การตรวจสอบ และการจัดการที่คล่องตัว
บทสรุป
Hadoop เป็นโซลูชันที่มีประสิทธิภาพมากสำหรับบริษัทที่ต้องการจัดเก็บและวิเคราะห์ข้อมูลจำนวนมหาศาล เป็นเครื่องมือที่เป็นที่ต้องการอย่างมากสำหรับการจัดการข้อมูลในระบบแบบกระจาย เนื่องจากเป็นโอเพ่นซอร์ส จึงเปิดให้บริษัทต่างๆ ใช้ประโยชน์ได้อย่างอิสระ หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับ Hadoop โปรดดูเอกสารอย่างเป็นทางการที่เว็บไซต์ Apache Software Foundation
คุณเคยใช้ Hadoop หรือไม่? ใช้แท็บคำติชมเพื่อแสดงความคิดเห็นหรือถามคำถาม
