
เผยแพร่ครั้งแรกโดย Tricore:2 ส.ค. 2017
แม้ว่าจะเริ่มต้นใช้งาน MongoDB ได้ง่าย แต่ปัญหาที่ซับซ้อนมากขึ้นก็ปรากฏขึ้นเมื่อคุณสร้างแอปพลิเคชัน คุณอาจพบว่าตัวเองกำลังสงสัยในสิ่งต่างๆ เช่น:
- ฉันจะซิงค์สมาชิกแบบจำลองอีกครั้งในชุดแบบจำลองได้อย่างไร
- ฉันจะกู้คืน MongoDB หลังจากเกิดความผิดพลาดได้อย่างไร
- ฉันควรใช้ข้อกำหนด GridFS ของ MongoDB เพื่อจัดเก็บและเรียกค้นไฟล์เมื่อใด
- ฉันจะแก้ไขข้อมูลที่เสียหายได้อย่างไร
โพสต์ในบล็อกนี้แบ่งปันเคล็ดลับบางประการในการจัดการกับสถานการณ์เหล่านี้เมื่อคุณใช้ MongoDB
เคล็ดลับที่ 1:อย่าพึ่งพาคำสั่งซ่อมแซมเพื่อกู้คืนข้อมูลของคุณ
หากฐานข้อมูลของคุณขัดข้องและคุณไม่ได้ใช้งาน –journal ตั้งค่าสถานะอย่าใช้ข้อมูลของเซิร์ฟเวอร์นั้น
repairของ MongoDB คำสั่งจะผ่านทุกเอกสารที่สามารถค้นหาและทำสำเนาทั้งหมดได้ อย่างไรก็ตาม โปรดทราบว่ากระบวนการนี้ใช้เวลานาน ใช้พื้นที่ดิสก์มาก (เท่ากับพื้นที่ที่ใช้อยู่ในปัจจุบัน) และข้ามระเบียนที่เสียหาย เนื่องจากกระบวนการจำลองแบบของ MongoDB ไม่สามารถแก้ไขข้อมูลที่เสียหาย คุณจะต้องล้างข้อมูลที่อาจเสียหายก่อนที่จะทำการซิงค์ใหม่
เคล็ดลับ 2:ซิงค์สมาชิกของชุดแบบจำลองอีกครั้ง
ในการซิงค์สมาชิกของชุดเรพพลิกา ตรวจสอบให้แน่ใจว่าอย่างน้อยหนึ่งสมาชิกรองและสมาชิกหลักหนึ่งคนเปิดใช้งานอยู่ จากนั้น ตรวจสอบให้แน่ใจว่าคุณเข้าสู่ระบบใหม่ในฐานะผู้ใช้ชื่อ Oracle และหยุดบริการ MongoDB
เข้าสู่ระบบในฐานะผู้ใช้ชื่อ MongoDB และย้ายไฟล์ข้อมูลทั้งหมดในโฟลเดอร์สำรอง เพื่อให้คุณสามารถกู้คืนได้หากคุณประสบปัญหา หากมีไฟล์เก่าอยู่ในโฟลเดอร์สำรอง คุณสามารถลบออกได้ หากคุณไม่แน่ใจว่าจะหาไฟล์ข้อมูลได้จากที่ใด ลองดูใน /etc/mongod.conf .ในฐานะผู้ใช้ชื่อ Oracle ให้เริ่มบริการ MongoDB
เข้าสู่ระบบฐานข้อมูลเพื่อตรวจสอบ คุณไม่จำเป็นต้องตรวจสอบสิทธิ์เพื่อเข้าถึงฐานข้อมูลจนกว่าสมาชิกจะซิงค์ในชุดแบบจำลอง
หลังจากกระบวนการจำลองแบบเสร็จสมบูรณ์ สถานะจะเปลี่ยนจากSTARTUP2 ถึง SECONDARY .
เคล็ดลับ 3:อย่าใช้ GridFS สำหรับข้อมูลไบนารีขนาดเล็ก
MongoDB ใช้ข้อกำหนด GridFS เพื่อจัดเก็บและเรียกค้นไฟล์ขนาดใหญ่ ความไม่เป็นจริง GridFS จะแยกวัตถุไบนารีขนาดใหญ่ก่อนที่จะจัดเก็บไว้ในฐานข้อมูล GridFS ต้องการสองข้อความค้นหา:หนึ่งรายการเพื่อดึงข้อมูลเมตาของไฟล์และหนึ่งรายการเพื่อดึงเนื้อหา ดังนั้น หากคุณใช้ GridFS เพื่อจัดเก็บไฟล์ขนาดเล็ก คุณจะเพิ่มจำนวนการสืบค้นที่แอปพลิเคชันของคุณต้องดำเนินการเป็นสองเท่า
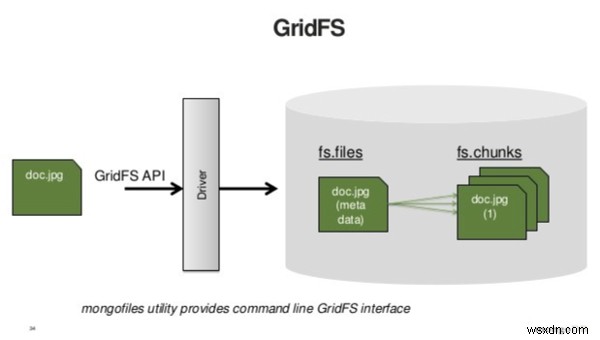
ที่มา:https://www.slideshare.net
GridFS ได้รับการออกแบบมาเพื่อจัดเก็บข้อมูลขนาดใหญ่ ซึ่งหมายถึงข้อมูลที่ใหญ่เกินกว่าจะใส่ลงในเอกสารเดียวได้ ตามหลักการทั่วไป สิ่งที่ใหญ่เกินกว่าจะโหลดในไคลเอนต์อาจไม่ใช่สิ่งที่คุณต้องการโหลดทั้งหมดในครั้งเดียวบนเซิร์ฟเวอร์ ทางเลือกคือการสตรีม ทุกสิ่งที่คุณวางแผนจะสตรีมไปยังลูกค้าคือตัวเลือกที่ดีสำหรับ GridFS
เคล็ดลับที่ 4:ลดการเข้าถึงดิสก์
นักพัฒนาทราบว่าการเข้าถึงข้อมูลจาก RAM นั้นรวดเร็วและการเข้าถึงข้อมูลจากดิสก์นั้นช้า
แม้ว่าคุณอาจทราบดีว่าการลดจำนวนการเข้าถึงดิสก์เป็นเทคนิคการเพิ่มประสิทธิภาพที่ยอดเยี่ยม แต่คุณอาจไม่ทราบวิธีทำงานนี้ให้สำเร็จ
วิธีหนึ่งคือการใช้โซลิดสเตตไดรฟ์ (SSD) SSD ทำงานหลายอย่างได้เร็วกว่าฮาร์ดดิสก์ไดรฟ์ (HDD) แบบเดิมมาก พวกเขายังทำงานได้ดีกับ MongoDB ในทางกลับกัน มักจะมีขนาดเล็กกว่าและมีราคาแพงกว่า
รูปภาพต่อไปนี้เปรียบเทียบ SSD และ HDD

ที่มา:https://www.serverintellect.com
อีกวิธีหนึ่งในการลดจำนวนการเข้าถึงดิสก์คือการเพิ่ม RAM อย่างไรก็ตาม วิธีนี้จะพาคุณไปได้ไกลเท่านั้น เพราะในที่สุด RAM ของคุณจะไม่สามารถรองรับขนาดข้อมูลของคุณได้
คำถามคือ เราจะจัดเก็บข้อมูลเทราไบต์หรือเพตะไบต์บนดิสก์ได้อย่างไร ตั้งโปรแกรมแอปพลิเคชันที่จะเข้าถึงหน่วยความจำข้อมูลที่ร้องขอบ่อยเป็นส่วนใหญ่ และย้ายข้อมูลจากดิสก์ไปยังหน่วยความจำให้บ่อยที่สุดเท่าที่จะทำได้
หากคุณเข้าถึงข้อมูลทั้งหมดของคุณแบบสุ่มในแบบเรียลไทม์ คำตอบคือคุณจะต้องใช้ RAM จำนวนมาก อย่างไรก็ตาม แอปพลิเคชันส่วนใหญ่ไม่ทำงานในลักษณะนี้ ข้อมูลล่าสุดมีการเข้าถึงบ่อยกว่าข้อมูลที่เก่ากว่า ผู้ใช้บางคนมีความกระตือรือร้นมากกว่าคนอื่นๆ และบางภูมิภาคมีลูกค้ามากกว่าคนอื่นๆ แอปพลิเคชันที่เหมาะสมกับคำอธิบายนี้สามารถออกแบบมาเพื่อเก็บเอกสารบางอย่างไว้ในหน่วยความจำ และเข้าถึงดิสก์ได้ไม่บ่อยนัก
เคล็ดลับ 5:เริ่มต้น MongoDB ตามปกติหลังจากฐานข้อมูลขัดข้อง
หากคุณเรียกใช้งานเจอร์นัลและระบบของคุณขัดข้องในวิธีที่สามารถกู้คืนได้ คุณสามารถรีสตาร์ทฐานข้อมูลได้ตามปกติ ตรวจสอบให้แน่ใจว่าคุณใช้ตัวเลือกปกติทั้งหมด โดยเฉพาะ -- dbpath (เพื่อให้สามารถหาไฟล์เจอร์นัลได้) และ--journal .
MongoDB จะแก้ไขข้อมูลของคุณโดยอัตโนมัติก่อนที่จะเริ่มยอมรับการเชื่อมต่อ กระบวนการนี้อาจใช้เวลาสองสามนาทีสำหรับชุดข้อมูลขนาดใหญ่ แต่ใช้เวลาน้อยกว่าปกติในการซ่อมแซมชุดข้อมูลขนาดใหญ่
ไฟล์เจอร์นัลถูกเก็บไว้ใน journal ไดเรกทอรี อย่าลบไฟล์เหล่านี้
เคล็ดลับ 6:กระชับฐานข้อมูลโดยใช้คำสั่งซ่อมแซม
คำสั่งซ่อมแซมจะดำเนินการ mongodump แล้วก็mongorestore การทำสำเนาข้อมูลของคุณอย่างหมดจด ในกระบวนการนี้จะลบ "รู" ที่ว่างเปล่าในไฟล์ข้อมูลของคุณออกด้วย
คำสั่งซ่อมแซมจะบล็อกการดำเนินการและต้องการพื้นที่ดิสก์สองเท่าที่ฐานข้อมูลของคุณกำลังทำงานอยู่ อย่างไรก็ตาม หากคุณมีเครื่องอื่น คุณสามารถทำขั้นตอนเดียวกันได้ด้วยตนเองโดยใช้ mongodump และmongorestore .
หากต้องการดำเนินการให้เสร็จสิ้นด้วยตนเอง ให้ใช้ขั้นตอนต่อไปนี้:
-
ลงจากเครื่อง Hyd1 และ
fsyncและlock:rs.stepDown() db.runCommand({fsync : 1, lock : 1}) -
ดัมพ์ไฟล์ไปที่ Hyd2:
Hyd2$ mongodump --host Hyd1 -
ทำสำเนาของไฟล์ข้อมูลใน Hyd1 เพื่อให้คุณยังคงมีข้อมูลสำรอง จากนั้นให้ลบไฟล์ข้อมูลเดิมและรีสตาร์ท Hyd1 ด้วยข้อมูลว่างเปล่า
-
กู้คืนจาก Hyd2 หากต้องการกู้คืนไฟล์ข้อมูล ให้ป้อนคำสั่งต่อไปนี้:
Hyd2$ mongorestore --host Hyd1 --port 10000 # specify port if it's not 27017
บทสรุป
การเปลี่ยนแปลงเหล่านี้ช่วยเพิ่มประสิทธิภาพ MongoDB ของเราอย่างมาก หากคุณกำลังวางแผนที่จะใช้ MongoDB คุณอาจต้องการบุ๊กมาร์กบทความนี้ จากนั้นกลับมาดูและตรวจดูเคล็ดลับแต่ละข้อในครั้งต่อไปที่คุณเริ่มโครงการใหม่
ในตอนที่ 2 ของชุดข้อมูลสองส่วนนี้ เราจะแชร์เคล็ดลับที่ช่วยให้องค์กรขนาดใหญ่ออกแบบ เพิ่มประสิทธิภาพ และใช้ฟีเจอร์ MongoDB ที่เป็นประโยชน์ได้อย่างเหมาะสม
ใช้แท็บคำติชมเพื่อแสดงความคิดเห็นหรือถามคำถาม
