
ในขณะที่ไอทีเติบโตขึ้นเรื่อยๆ ระบบสารสนเทศก็กลายเป็นอุตสาหกรรมที่มีความสำคัญอย่างยิ่งยวด การหยุดชะงักของบริการในระบบข้อมูลอาจทำให้เกิดความสูญเสียทางเศรษฐกิจ การสูญเสียข้อมูลที่สำคัญ และส่งผลกระทบต่อภาพลักษณ์ของแบรนด์ในตลาด โดยเฉพาะอย่างยิ่งสำหรับอุตสาหกรรมต่างๆ เช่น การสื่อสาร การเงิน การรักษาพยาบาล อีคอมเมิร์ซ โลจิสติกส์ และรัฐบาล ดังนั้นความต่อเนื่องของการบริการจึงมีความสำคัญต่อการสร้างระบบสารสนเทศ ในปัจจุบัน ความต่อเนื่องของบริการได้รับการปรับปรุงให้ดีขึ้นโดยการสร้างศูนย์การกู้คืนความเสียหาย (DR) ซึ่งบันทึกสำเนาของข้อมูลการผลิตไว้
แนะนำตัว
ในโซลูชัน DR แบบดั้งเดิม ศูนย์ DR หนึ่งแห่งจะถูกปรับใช้สำหรับแต่ละศูนย์ข้อมูลการผลิต (DC) ศูนย์ DR จะไม่ให้การเข้าถึงบริการ เว้นแต่ว่า ProductionDC จะพบกับภัยพิบัติที่นำไปสู่การหยุดให้บริการ ซึ่งไม่สามารถซ่อมแซมได้ในช่วงเวลาสั้นๆ ดังนั้น ศูนย์ DR ต้องเผชิญกับความท้าทายดังต่อไปนี้:
-
เมื่อศูนย์การผลิตประสบกับความล้มเหลวของแหล่งจ่ายไฟ ไฟไหม้ น้ำท่วม แผ่นดินไหว จำเป็นต้องมีการดำเนินการด้วยตนเองเพื่อสลับบริการไปยังศูนย์ DR นอกจากนี้จำเป็นต้องมีมาตรการการกู้คืนแบบมืออาชีพและการดีบัก ภัยพิบัติเหล่านี้อาจทำให้บริการหยุดชะงักในระยะยาวและให้บริการไม่ต่อเนื่อง
-
ศูนย์ DR ไม่ได้ให้บริการและไม่ได้ใช้งานเกือบตลอดเวลา ซึ่งช่วยลดการใช้ทรัพยากร
เพื่อตอบสนองความต้องการของลูกค้าในการใช้ทรัพยากรอย่างมีประสิทธิภาพ การทำโหลดบาลานซ์ และการสลับอัตโนมัติระหว่าง DC สองชุด Oracle® ได้เปิดตัวโซลูชัน Active-Active DC แบบ end-to-end โซลูชันนี้ช่วยให้ DC ทั้งสองทำงานพร้อมกันและแชร์โหลดบริการเพื่อปรับปรุงความสามารถในการบริการโดยรวมและการใช้ทรัพยากร โซลูชันนี้ยังช่วยรับประกันการเฟลโอเวอร์โดยอัตโนมัติด้วยการรับรู้ถึงบริการเป็นศูนย์ ในกรณีที่อุปกรณ์ล้มเหลวหรือความล้มเหลวของ DC เดียว นอกจากนี้ ยังมี Recovery Point Objective (RPO) ที่เป็นศูนย์และ Recovery Time Objective (RTO) ที่เป็นศูนย์ หมายเหตุ:RTO ขึ้นอยู่กับระบบแอปพลิเคชันและโหมดการปรับใช้
มีโหมดความพร้อมใช้งานสองโหมดในอุตสาหกรรมการจัดเก็บข้อมูลปัจจุบัน:
- แอ็คทีฟ-พาสซีฟ (AP) หรือแอ็คทีฟ-สแตนบาย
- active-active (AA) หรือ metro virtual data center (MVDC)
ส่วนประกอบที่สำคัญของชั้นฐานข้อมูล
ฐานข้อมูล (DB) ควรได้รับการตั้งค่าในโหมดแอ็คทีฟสแตนด์บายโดยมีตัวเลือกการสูญเสียข้อมูลเป็นศูนย์ รายการต่อไปนี้เป็นส่วนประกอบที่สำคัญ:
- Oracle Data Guard Broker:ทำให้การกำหนดค่า Data Guard เป็นอัตโนมัติและรวมศูนย์ และช่วยเรียกใช้การสลับหรือเฟลโอเวอร์ด้วยคำสั่งเดียวสำหรับการเปลี่ยนแปลงบทบาทที่ซับซ้อน
- ฐานข้อมูลย้อนหลัง:จัดเตรียมการกรอกลับหรือย้อนกลับสำหรับฐานข้อมูล และจัดเก็บข้อมูลบันทึกย้อนหลังในพื้นที่การกู้คืนแฟลช
- Fast-Start Failover (FSFO):เปิดใช้งานการเฟลโอเวอร์โดยไม่สูญเสียข้อมูลเป็นศูนย์ FSFO จะไม่ทริกเกอร์เว้นแต่ฐานข้อมูลสำรองจะซิงค์กับฐานข้อมูลหลัก
- ผู้สังเกตการณ์:จัดเตรียมกระบวนการแยกต่างหากที่รวมอยู่ในอินเทอร์เฟซบรรทัดคำสั่งของ Data Guard
dgmgrlซึ่งตรวจสอบสถานะของฐานข้อมูลหลักและสแตนด์บายสำหรับเงื่อนไขความล้มเหลวที่อาจเกิดขึ้น
การกำหนดค่า Data Guard
รูปภาพต่อไปนี้แสดงการกำหนดค่า Data Guard:
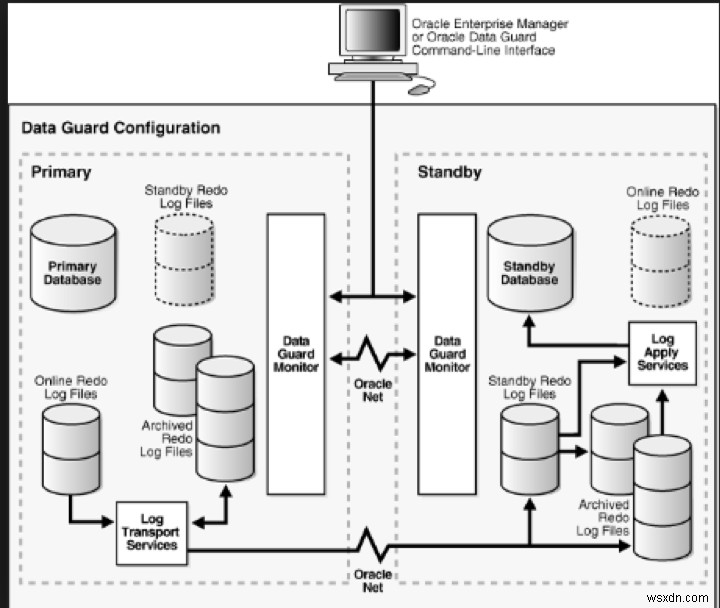
ที่มาของรูปภาพ: https://neeraj-dba.blogspot.com/2011/10/dataguard-broker-and-its-benefits_05.html
ในฐานข้อมูลหลัก กระบวนการ Log Writer (LGWR) จะส่งข้อมูลการทำซ้ำไปยังกระบวนการ Log Network Server (LNSn) อย่างน้อยหนึ่งกระบวนการ ซึ่งจะเริ่มต้น NetworkI/O ไปยังปลายทางระยะไกลหลายแห่งพร้อมกัน ธุรกรรมจะไม่ถูกผูกมัดในฐานข้อมูลหลักจนกว่าข้อมูลการทำซ้ำจะมีความจำเป็นในการกู้คืนธุรกรรมที่ได้รับจากปลายทาง LGWR SYNC ทั้งหมด
บนฐานข้อมูลสแตนด์บาย Remote File Server (RFS) จะได้รับข้อมูลการทำซ้ำผ่านเครือข่ายจากกระบวนการ LGWR และเขียนข้อมูลการทำซ้ำไปยังไฟล์บันทึกการทำซ้ำขณะสแตนด์บาย
สถาปัตยกรรมความพร้อมใช้งานสูงสุด
เมื่อคุณออกแบบสถาปัตยกรรมเพื่อความพร้อมใช้งานสูงสุด คุณควรพิจารณาถึงสาเหตุที่เป็นไปได้ของการหยุดทำงานและวิธีจัดประเภทเวลาหยุดทำงานที่ไม่ได้วางแผนไว้และเวลาหยุดทำงานตามแผน
การหยุดทำงานโดยไม่ได้วางแผนรวมถึงการหยุดชะงักโดยไม่คาดคิดกับรายการต่อไปนี้:
-
ความพร้อมใช้งานของเซิร์ฟเวอร์:คุณต้องตรวจสอบให้แน่ใจว่าเข้าถึง DBservices ได้อย่างต่อเนื่อง แม้ว่าจะมีความล้มเหลวที่ไม่คาดคิดของเครื่องหนึ่งเครื่องขึ้นไปที่โฮสต์เซิร์ฟเวอร์ theDB ซึ่งอาจเกิดขึ้นได้เนื่องจากความผิดพลาดของฮาร์ดแวร์หรือซอฟต์แวร์ OracleReal Application Clusters (RAC) ให้การป้องกันที่มีประสิทธิภาพสูงสุดต่อความล้มเหลวดังกล่าว
-
ความพร้อมใช้งานของข้อมูล:เพื่อลดความล้มเหลวของข้อมูล เช่น การสูญหาย ความเสียหาย หรือความเสียหายของข้อมูลที่มีความสำคัญต่อธุรกิจ แผนของคุณต้องแน่ใจว่าคุณสามารถเข้าถึงข้อมูลของคุณได้เสมอ
การหยุดทำงานตามแผนรวมถึงการหยุดชะงักตามกำหนดเวลาในการเข้าถึงรวมถึงรายการต่อไปนี้:
- การเปลี่ยนแปลงระบบ
- การเปลี่ยนแปลงข้อมูล
- การเปลี่ยนแปลงแอป
สถานการณ์การทดสอบสวิตช์สำหรับ MVDC
การเปลี่ยนผ่านคือการดำเนินการพลิกกลับบทบาทที่ได้รับการควบคุมและวางแผนไว้ โดยที่ฐานข้อมูลหลักและสแตนด์บายในการกำหนดค่า Data Guard จะสลับบทบาทของตน หลังจากเปลี่ยนแล้ว แต่ละฐานข้อมูลจะยังคงมีส่วนร่วมในการกำหนดค่า Data Guard ในบทบาทใหม่
กระบวนการสลับ
การเปลี่ยนจะเกิดขึ้นตามลำดับต่อไปนี้:
- DB หลักดั้งเดิมจะสลับบทบาทเป็นสแตนด์บาย
- ฐานข้อมูลสแตนด์บายเดิมจะเปลี่ยนเป็นบทบาทหลัก
Data Guard Broker จะดูแลกิจกรรมต่อไปนี้โดยอัตโนมัติเมื่อคุณทำการเปลี่ยน:
- ตรวจสอบว่า DB สแตนด์บายหลักและเป้าหมายออนไลน์อยู่และไม่มีข้อผิดพลาด
- ปิดระบบทั้งหมดยกเว้นอินสแตนซ์เดียวในการกำหนดค่า RAC สำหรับฐานข้อมูลหลักและสแตนด์บาย
- สลับบทบาทของฐานข้อมูลหลักและสแตนด์บาย ก่อนอื่น Data Guard Broker จะแปลงฐานข้อมูลหลักดั้งเดิมให้ทำงานในบทบาทสแตนด์บายก่อน จากนั้นนายหน้าเปลี่ยนฐานข้อมูลเป้าหมายสแตนด์บายเป็นบทบาทหลัก นอกจากนี้ยังอัปเดตไฟล์การกำหนดค่านายหน้าเพื่อบันทึกการเปลี่ยนแปลงในบทบาทเพื่อให้แน่ใจว่าแต่ละDB ทำงานในบทบาทที่ถูกต้องหลังจากรีสตาร์ท
- รีสตาร์ท DB สแตนด์บายใหม่ (เดิมคือฐานข้อมูลหลัก) และเริ่มกระบวนการ Redo Apply โดยใช้ข้อมูลทำซ้ำจาก DB หลักใหม่ หากนี่คือ RAC DB นายหน้าจะรีสตาร์ทอินสแตนซ์ที่ปิดตัวลงก่อนการเปลี่ยนแปลง
- รีสตาร์ท DB หลักใหม่ เปิดและเริ่มทำซ้ำบริการขนส่ง ส่งข้อมูลทำซ้ำไปยัง DB สแตนด์บาย หากนี่คือ RAC DB นายหน้าจะรีสตาร์ทอินสแตนซ์ที่ปิดตัวลงก่อนการเปลี่ยนแปลง
ก่อนเปลี่ยน:
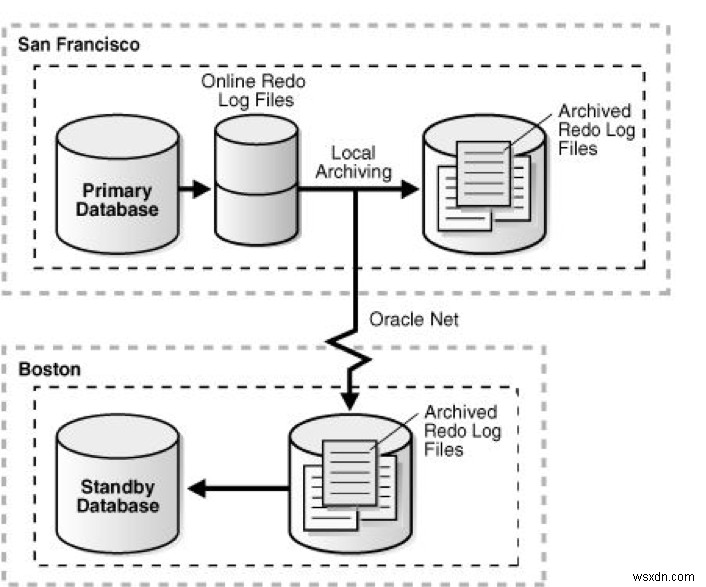
ที่มาของรูปภาพ: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
หลังจากเปลี่ยน:
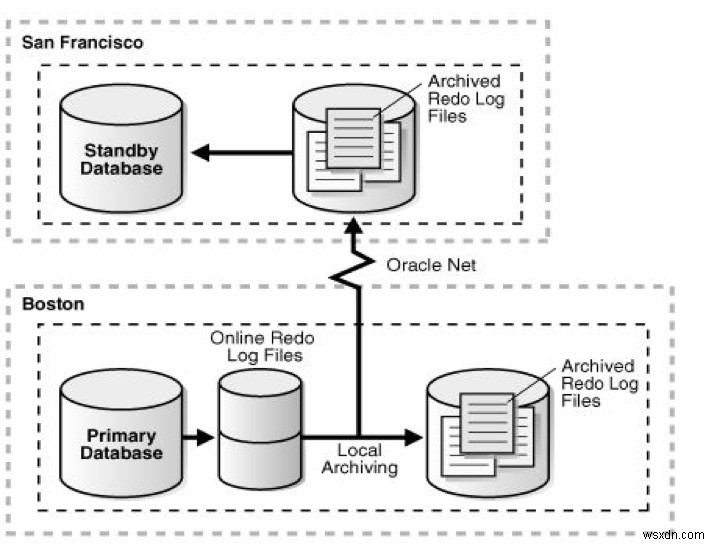
ที่มาของรูปภาพ: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
ขั้นตอนในการดำเนินการเปลี่ยน
หากต้องการเปลี่ยน ให้ทำตามขั้นตอนต่อไปนี้:
-
ตรวจสอบให้แน่ใจว่าปิดแอปพลิเคชันอย่างสมบูรณ์ และไม่มีผู้ใช้เชื่อมต่อกับฐานข้อมูล
-
ปิดใช้งานสคริปต์ UTL ของไฟล์เก็บถาวรที่ทำงานอยู่ใน DC ทั้งสองอย่างน้อย 30 นาทีก่อนเริ่มการสลับ หลังจากการทดสอบเสร็จสิ้นและ DB กำลังทำงานอยู่ในตำแหน่งที่ต้องการ ให้ยกเลิกการใส่ความคิดเห็นในสคริปต์ยูทิลิตี้ที่เก็บถาวร
-
เรียกใช้คำสั่ง SQL ต่อไปนี้ในฐานข้อมูลหลักปัจจุบัน:
SELECT * FROM DBA_JOBS_RUNNING; (There should not be any sys owned jobs running) SELECT OWNER, JOB_NAME, START_DATE, END_DATE, ENABLED FROM DBA_SCHEDULER_JOBS WHERE ENABLED='TRUE' AND OWNER <> 'SYS'; (Data Guard Broker does not kill the jobs owned by sys.) -
ตั้งค่า
job_queue_processesและaq_tm_processesเป็น 0. จดค่าเดิมไว้เพราะคุณต้องรีเซ็ตเป็นค่าเดิมหลังจากการทดสอบการเปลี่ยนผ่านเสร็จสิ้น -
หยุด
emagentที่ทำงานอยู่บนฐานข้อมูลหลัก -
เรียกใช้คำสั่ง SQL ต่อไปนี้ในฐานข้อมูลหลักปัจจุบัน:
SELECT sid, username, status, program, inst_id FROM gv$session WHERE username is not null and status='ACTIVE' order by inst_id; (Validate and check the number of connections is active; a large number of active connections can lead to the switchover taking more time.) -
ออกจากระบบ
sqlplus. ทั้งหมด เซสชันที่คุณเชื่อมต่อเป็นsys. -
เรียกใช้คำสั่ง SQL ต่อไปนี้ในฐานข้อมูลหลักปัจจุบัน:
set linesize to 132 col value format a35 SELECT inst_id,name,value from gv$parameter WHERE name in ('job_queue_processes','aq_tm_processes'); (Check and validate the value of job_queue_processes and aq_tm_processes should be zero.) -
เรียกใช้คำสั่งต่อไปนี้เพื่อตรวจสอบการกำหนดค่า Data Guard:
DGMGRL> show configuration verbose ** STATUS Should show success, do not proceed if the status is not "success". -
ตรวจสอบสถานะ Cluster Ready Services (CRS) เพื่อให้แน่ใจว่าทรัพยากรทั้งหมดได้รับการลงทะเบียนออนไลน์ เนื่องจากนายหน้ามอบการส่งมอบให้กับ CRS เพื่อต่อเชื่อมและปิดฐานข้อมูลในระหว่างกระบวนการนี้
-
สลับบันทึกสองสามรายการในฐานข้อมูลหลักและตรวจสอบว่าได้นำไปใช้กับฐานข้อมูลสำรอง
-
ก่อนดำเนินการต่อ ให้ดำเนินการสลับและตรวจสอบบันทึก DRC และบันทึกการแจ้งเตือนสำหรับความล้มเหลวใดๆ คำสั่งต่อไปนี้จะแปลงการสแตนด์บายหลักเก่าแล้วแปลงการสแตนด์บายเก่าเป็นคำสั่งหลัก:
DGMGRL> switchover to ‘DDMPROD_STANDBY’; -
หลังจากเปลี่ยนเสร็จแล้ว ตรวจสอบให้แน่ใจว่าการขนส่งบันทึกและใช้บริการบันทึกนั้นทำงานได้อย่างถูกต้อง
สถานการณ์การทดสอบเฟลโอเวอร์สำหรับ MVDC
เฟลโอเวอร์คือเมื่อ DB หลัก (อินสแตนซ์ทั้งหมดของ DB หลัก RAC) ล้มเหลว และ DB สแตนด์บายจะเปลี่ยนไปรับบทบาทหลัก เกิดข้อผิดพลาดในกรณีต่อไปนี้:
- ความล้มเหลวอย่างร้ายแรงของ DB หลักที่ไม่สามารถกู้คืน DB หลักได้ทันท่วงที
- เมื่อทั้งผู้สังเกตการณ์และฐานข้อมูลสำรองขาดการเชื่อมต่อเครือข่ายกับฐานข้อมูลหลัก และเมื่อฐานข้อมูลสำรองยืนยันว่าอยู่ใน ซิงโครไนซ์ รัฐ.
สถานการณ์ความล้มเหลว
เงื่อนไข DB ต่อไปนี้ทำให้เกิดการเฟลโอเวอร์อย่างรวดเร็ว:
- ความล้มเหลวของไซต์หลัก
- เงื่อนไขฐานข้อมูลหลัก รวมถึงสิ่งต่อไปนี้:
- อินสแตนซ์ล้มเหลว
- ตัวอย่างสุดท้ายที่รอดตาย ถ้า RAC
- การปิดระบบจะยกเลิกอินสแตนซ์ที่มีอยู่ล่าสุด
- ไฟล์ข้อมูลออฟไลน์เนื่องจากข้อผิดพลาดของ I/O (เกณฑ์ถูกละเว้นเมื่อดำเนินการเฟลโอเวอร์เนื่องจากไฟล์ข้อมูลออฟไลน์)
เงื่อนไขที่เกี่ยวข้องกับเครือข่ายอาจทำให้เกิดการเฟลโอเวอร์ได้ก็ต่อเมื่อลิงก์ระหว่างตัวหลักและผู้สังเกตการณ์ รวมถึงฐานข้อมูลสำรองหลักและเป้าหมายหยุดทำงาน จำเป็นต้องมีการเชื่อมต่อระหว่างผู้สังเกตการณ์และสแตนด์บายเพื่อให้ผู้สังเกตการณ์ยืนยันว่าการกำหนดค่าอยู่ในสถานะซิงโครไนซ์ .
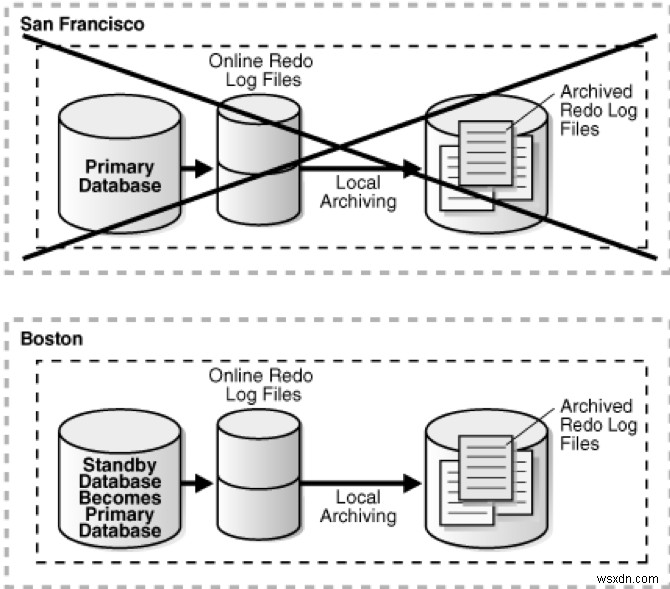
ที่มาของรูปภาพ: https://docs.oracle.com/cd/E11882_01/server.112/e41134/role_management.htm#SBYDB00615
บทสรุป
MVDC ช่วยให้การใช้ทรัพยากรอย่างมีประสิทธิภาพ การทำโหลดบาลานซ์ ความพร้อมใช้งานสูง และการสลับอัตโนมัติระหว่าง DC สองชุด DC ทั้งสองทำงานพร้อมกัน (ใช้งานอยู่) เพื่อแชร์โหลดบริการและปรับปรุงความสามารถในการบริการโดยรวม MVDC ช่วยลดการแทรกแซงของมนุษย์ที่จำเป็นในการสลับระหว่างฐานข้อมูลสำหรับการกู้คืนระบบเมื่อเกิดข้อผิดพลาด หรือการสลับการอัปเกรด/การบำรุงรักษา
ใช้แท็บคำติชมเพื่อแสดงความคิดเห็นหรือถามคำถาม
เพิ่มประสิทธิภาพสภาพแวดล้อมของคุณด้วยการดูแลระบบ การจัดการ และการกำหนดค่าจากผู้เชี่ยวชาญ
บริการแอปพลิเคชันของ Rackspace(RAS) ผู้เชี่ยวชาญจะให้บริการแบบมืออาชีพและที่มีการจัดการในแอปพลิเคชันที่หลากหลาย:
- แพลตฟอร์มอีคอมเมิร์ซและประสบการณ์ดิจิทัล
- การวางแผนทรัพยากรองค์กร (ERP)
- ระบบธุรกิจอัจฉริยะ
- การจัดการลูกค้าสัมพันธ์ของ Salesforce (CRM)
- ฐานข้อมูล
- อีเมลโฮสติ้งและประสิทธิภาพการทำงาน
เราจัดส่ง:
- ความเชี่ยวชาญที่เป็นกลาง :เราลดความซับซ้อนและเป็นแนวทางในการสร้างสรรค์สิ่งใหม่ของคุณ โดยมุ่งเน้นที่ความสามารถที่มอบคุณค่าในทันที
- ประสบการณ์สุดคลั่ง ™:เรารวมกระบวนการก่อน เทคโนโลยีที่สอง®แนวทางพร้อมการสนับสนุนทางเทคนิคเฉพาะเพื่อมอบโซลูชันที่ครอบคลุม
- ผลงานที่ยอดเยี่ยม :เราใช้ประสบการณ์ระบบคลาวด์ที่ครอบคลุมเพื่อช่วยคุณเลือกและปรับใช้เทคโนโลยีที่เหมาะสมบนระบบคลาวด์ที่เหมาะสม
- ส่งไว :เราพบคุณในที่ที่คุณอยู่ในการเดินทางของคุณและปรับความสำเร็จของเราไปพร้อมกับคุณ
แชทเลยเพื่อเริ่มต้น
