
ข้อมูลเบื้องต้นเกี่ยวกับตัวแทนการวิจัย AI
การวิจัยเชิงวิชาการดำเนินไปอย่างรวดเร็ว มีรายงานใหม่ๆ ปรากฏทุกวันบน arXiv และเซิร์ฟเวอร์ก่อนการพิมพ์อื่นๆ การติดตามด้วยตนเองอาจล้นหลาม ในคู่มือนี้ เราจะสร้างผู้ช่วยวิจัย AI นั่น:
- เข้าใจคำถามที่เป็นภาษาธรรมชาติของนักวิจัย
- ค้นหาเอกสารที่เกี่ยวข้องมากที่สุดในฐานข้อมูลเวกเตอร์ของบทคัดย่อ arXiv
- สรุปข้อมูลเชิงลึกที่สำคัญและอธิบายว่าตอบคำถามอย่างไร
- ให้ลิงก์ PDF โดยตรงเพื่อการอ่านเชิงลึก
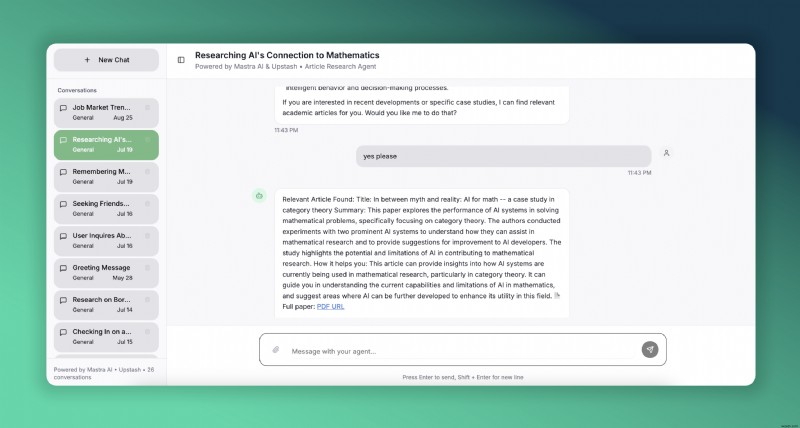
เราจะทำสิ่งนี้ให้สำเร็จด้วย Mastra เฟรมเวิร์ก TypeScript แบบโอเพ่นซอร์สสำหรับการสร้างเอเจนต์ AI และ Upstash สำหรับพื้นที่จัดเก็บ Redis และ Vector แบบไร้เซิร์ฟเวอร์ นี่คือการสาธิตสดของตัวแทนบทความของเราที่เน้นด้านการวิจัย AI มีการปรับใช้บน Vercel เพื่อให้คุณทดลองใช้
มาสตราคืออะไร?
Mastra เป็นเฟรมเวิร์กที่รวมแบตเตอรี่ซึ่งทำให้การสร้างเอเจนต์ AI ระดับการผลิตเป็นเรื่องง่าย
- ตัวแทนและขั้นตอนการทำงาน — เขียนตัวแทน เครื่องมือ และเวิร์กโฟลว์หลายขั้นตอน
- การสร้างแบบดึงข้อมูล-เสริม (RAG) - หน่วยความจำภายในและร้านค้าเวกเตอร์
- หลาย LLM - ทำงานร่วมกับ OpenAI, Claude และอื่นๆ อีกมากมาย
เราจะสร้างตัวแทนที่ใช้ Upstash Redis สำหรับหน่วยความจำ นอกจากนี้ยังจะมีเครื่องมือในการค้นหาบทความวิจัยที่เกี่ยวข้อง ซึ่งเราจะฝังไว้ในฐานข้อมูล Upstash Vector ก่อนหน้านี้
หากต้องการเจาะลึกยิ่งขึ้น โปรดดูเอกสารประกอบของ Mastra
กองเทคโนโลยีสำหรับโครงการ
- กรอบงาน Mastra เพื่อสร้างตัวแทนและเครื่องมือ AI
- สุดยอด Redis เพื่อให้หน่วยความจำการสนทนาแก่ตัวแทน
- เวกเตอร์ขั้นสูง เพื่อจัดเก็บการฝังบทคัดย่อของบทความวิจัย
- Next.js และ Vercel เพื่อสร้างและปรับใช้เว็บแอปพลิเคชัน
นอกจากนี้เรายังจะใช้ Upstash Ratelimit เพื่อจำกัดคำขอสำหรับแอปพลิเคชันสาธิตของเรา
Implementation Walkthrough
การสร้างแอปพลิเคชันนี้เกี่ยวข้องกับการสร้างองค์ประกอบหลักสองส่วน:เซิร์ฟเวอร์ Mastra และแอปพลิเคชันเว็บ แม้ว่าพวกเขาจะอยู่ในโปรเจ็กต์เดียวกันได้ แต่การแยกพวกมันออกจากกันจะสะอาดกว่า เริ่มจากเซิร์ฟเวอร์ Mastra กันก่อน
การสร้างโครงการ Mastra
หากต้องการสร้างโปรเจ็กต์ Mastra ใหม่ ให้รันคำสั่งต่อไปนี้ในเทอร์มินัลของคุณ
npm create mastra@latestมันจะถามคำถามสองสามข้อ สำหรับโปรเจ็กต์นี้ การตั้งค่าเริ่มต้นก็ใช้ได้
การสร้างตัวแทนและเครื่องมือ
ขั้นตอนแรกในการกำหนดค่าตัวแทนคือการกำหนดชื่อ วัตถุประสงค์ และเครื่องมือ สิ่งสำคัญคือต้องเลือกโมเดลภาษาที่จะทำงานได้ดีสำหรับงานที่กำหนด ในโปรเจ็กต์นี้ เราจะมีหนึ่งตัวแทนและหนึ่งเครื่องมือ
export const articleAgent = new Agent({
name: "articleAgent",
instructions: instruction,
model: openai('gpt-4o'),
tools: { articleQueryTool },
memory: memory
});
การกำหนดค่าตัวแทนทำได้ง่ายดังที่แสดงไว้ด้านบน เรากำหนด articleAgent ของเรา ด้วย 04 (ซึ่งทำหน้าที่เป็นพรอมต์ของระบบ) เฉพาะ 13 , 28 และองค์ประกอบที่สำคัญอีกประการหนึ่ง:32 .
ความทรงจำของเจ้าหน้าที่
Mastra มอบทั้งประวัติการแชทและความสามารถในการเรียกคืนความหมายให้กับตัวแทน ด้วยการรักษาหน่วยความจำในพื้นที่จัดเก็บข้อมูล เจ้าหน้าที่จึงสามารถให้คำตอบที่เป็นส่วนตัวและแม่นยำยิ่งขึ้น มาดูการกำหนดค่าหน่วยความจำของตัวแทนของเรากัน
export const memory = new Memory({
storage: myUpstashStore,
options: {
lastMessages: 10,
semanticRecall: false,
threads: {
generateTitle: true
}
}
});
เพื่อเปิดใช้งานประวัติการแชท เราใช้ Upstash Redis เป็นตัวเลือกการจัดเก็บข้อมูลของเรา เรากำหนดค่าเริ่มต้นเป็น 47 วัตถุซึ่งขยาย 58 เพื่อให้แน่ใจว่ามันจะทำงานได้อย่างราบรื่นกับตัวแทน Mastra ของเรา
export const myUpstashStore = new UpstashStore({
url: process.env.UPSTASH_REDIS_REST_URL!,
token: process.env.UPSTASH_REDIS_REST_TOKEN!,
});ก่อนหน้านี้เราได้กล่าวถึงการเพิ่มฟีเจอร์การเรียกคืนความหมายให้กับตัวแทนของเรา ซึ่งช่วยให้ตัวแทนสามารถพิจารณาข้อความก่อนหน้าที่เกี่ยวข้องกับบริบทปัจจุบันได้ เพื่อทำเช่นนั้น เอเจนต์จำเป็นต้องมีฐานข้อมูลเวกเตอร์และเครื่องฝังเพื่อประมวลผลข้อความ เนื่องจากการสาธิตสาธารณะของเราไม่ใช่เพื่อการใช้งานส่วนตัวและไม่จำเป็นต้องจำข้อความในกระทู้ต่างๆ เราจึงไม่ใช้คุณสมบัตินี้ แต่สามารถนำไปใช้ได้ดังต่อไปนี้
export const myUpstashVector = new UpstashVector({
url: process.env.UPSTASH_VECTOR_REST_URL!,
token: process.env.UPSTASH_VECTOR_REST_TOKEN!,
});
export const memory = new Memory({
storage: myUpstashStore,
vector: myUpstashVector,
embedder: openai.embedding("text-embedding-3-small"),
options: {
lastMessages: 10,
semanticRecall: {
topK: 3,
messageRange: 2,
scope: 'resource'
},
threads: {
generateTitle: true
}
}
});ในการกำหนดค่าการเรียกคืนความหมาย topK ระบุจำนวนข้อความที่คล้ายกันที่จะดึงข้อมูล ช่วงข้อความ กำหนดจำนวนบริบทโดยรอบที่จะรวมไว้ในการจับคู่แต่ละรายการ และการตั้งค่า ขอบเขต เป็น 'ทรัพยากร' ทำให้ตัวแทนค้นหาในเธรดทั้งหมดที่เกี่ยวข้องกับผู้ใช้ชื่อ 'ทรัพยากร' หน่วยความจำแบบครอสเธรดนี้เป็นหน่วยความจำอันทรงพลังที่มาพร้อมกับ Upstash
เครื่องมือ
การสร้างเครื่องมือนั้นเกือบจะง่ายพอๆ กับการสร้างตัวแทน เราจัดเตรียมชื่อ คำอธิบาย สคีมาอินพุตและเอาท์พุต และฟังก์ชันที่จะดำเนินการเมื่อตัวแทนต้องการความสามารถของเครื่องมือ
export const articleQueryTool = createTool({
id: 'get-relevant-article',
description: 'Get relevant article information',
inputSchema: z.object({
question: z.string().describe('the question about the field'),
}),
outputSchema: z.object({
bestOption: z.object({
abstract: z.string().describe('the abstract of the article'),
title: z.string().describe('the title of the article'),
pdfUrl: z.string().describe('the PDF URL of the article')
})
}),
execute: async ({ context }) => {
return await querySimilar(context.question);
},
});เราใช้ Zod เพื่อตรวจสอบสคีมาอินพุตและเอาต์พุต ซึ่งจะช่วยรักษาการตอบสนองที่สม่ำเสมอและลดข้อผิดพลาดที่อาจเกิดขึ้นจาก LLM เรายังกำหนดฟังก์ชันสำหรับเครื่องมือที่จะใช้ด้วย เครื่องมือของเราจะสืบค้นบทความวิจัยจำนวนมาก ซึ่งมีการอัปเดตเป็นระยะผ่าน arXiv API และฝังอยู่ในฐานข้อมูล Upstash Vector ของเรา
const querySimilar = async (query: string) => {
const { embedding } = await embed({
value: query,
model: openai.embedding("text-embedding-3-small"),
});
const results = await myMastraUpstashVector.query({
indexName: "arxiv",
queryVector: embedding,
topK: 3,
});
if (results && results.length > 0) {
const bestMatch = results[0];
const metadata = bestMatch.metadata as ArxivPaper;
return {
bestOption: {
abstract: metadata.abstract,
title: metadata.title,
pdfUrl: metadata.pdfUrl
}
};
}
throw new Error("No relevant information found");
}
เราสามารถดำเนินการง่ายๆ บนฐานข้อมูลเวกเตอร์ของเราได้โดยใช้ 67 อินสแตนซ์ซึ่งขยาย 79 . Above, we query for similar article abstracts that we embedded beforehand and return the best result to the tool. โปรดทราบว่าเราใช้โมเดลการฝังเดียวกันสำหรับการสืบค้นเช่นเดียวกับที่เราทำกับบทความ เราจะอธิบายการฝังบทความโดยละเอียดเพิ่มเติมในภายหลัง
อินสแตนซ์ Mastra
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
deployer: new VercelDeployer()
});
เราเพียงแค่ระบุตัวแทนที่จะใช้และ 80 ของเรา วัตถุพร้อมแล้ว นอกจากนี้เรายังจัดเตรียมพื้นที่จัดเก็บข้อมูลเพื่อคงข้อมูลไว้นอกเหนือจากพื้นที่จัดเก็บข้อมูลในหน่วยความจำ คุณยังสามารถเลือกจากการกำหนดค่าการใช้งานที่มีอยู่ เราจะปรับใช้โดยใช้ Vercel
ด้วยตัวเลือกเริ่มต้นจาก 93 เรามีโครงสร้างไฟล์ที่ต้องการอยู่แล้ว:
.
└── mastra
├── agents
│ └── index.ts
├── tools
│ └── index.ts
└── index.ts
เหลือเพียงขั้นตอนเดียวก่อนที่จะปรับใช้:ตัวแปรสภาพแวดล้อมของเรา
OPENAI_API_KEY=
UPSTASH_VECTOR_REST_URL=
UPSTASH_VECTOR_REST_TOKEN=
UPSTASH_REDIS_REST_URL=
UPSTASH_REDIS_REST_TOKEN=
ใส่สิ่งเหล่านี้ใน 107 ของคุณ ไฟล์สำหรับการพัฒนาในเครื่องและเพิ่มลงในสภาพแวดล้อมการปรับใช้ของคุณ
ตอนนี้เราพร้อมที่จะสร้างและปรับใช้เซิร์ฟเวอร์ Mastra ของเราแล้ว
npm run build && vercel --prodคุณสามารถตรวจสอบเอกสาร Vercel เพื่อดูวิธีการปรับใช้
ในระหว่างการพัฒนา เราสามารถใช้ Mastra Playground เพื่อดูผลลัพธ์ของเซิร์ฟเวอร์ของเราได้ รันคำสั่งต่อไปนี้:
npm run devซึ่งจะมีลิงก์ไปยังอินเทอร์เฟซเว็บที่คุณสามารถสนทนากับตัวแทนของเรา เรียกใช้เครื่องมือได้อย่างชัดเจน และสำรวจความสามารถของเซิร์ฟเวอร์ของเรา
ตอนนี้ได้เวลาพูดถึงส่วนอื่นๆ ของแอปพลิเคชันแล้ว
เซิร์ฟเวอร์ Next.js
เมื่อตั้งค่าเซิร์ฟเวอร์ Mastra แล้ว เราจะต้องจัดการสามสิ่ง ได้แก่ UI การสื่อสารกับเซิร์ฟเวอร์ Mastra และบริการบทความที่พูดคุยกับ arXiv API และฝังบทคัดย่อลงใน Upstash Vector Mastra มี SDK ไคลเอ็นต์เพื่อแสดงฟังก์ชันการทำงานของเซิร์ฟเวอร์ คุณสามารถเข้าถึงตัวแทน เครื่องมือ หน่วยความจำ และอื่นๆ อีกมากมายผ่านสิ่งนี้ การใช้งานตรงไปตรงมา แต่เราจะแบ่งปันตัวอย่างบางส่วน สำหรับรายละเอียดเพิ่มเติม คุณสามารถตรวจสอบเอกสารประกอบได้ที่นี่ ในโปรเจ็กต์ Next.js คุณสามารถติดตั้งและใช้ SDK ไคลเอ็นต์ได้
npm install @mastra/client-js@latest
ในโค้ดของคุณ ให้สร้างอินสแตนซ์ของ 117 เพื่อใช้ในโครงการของคุณ
import { MastraClient } from "@mastra/client-js";
export const mastra_sdk = new MastraClient({
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API!,
retries: 3,
});
คุณต้องตั้งค่า 129 ไปยังที่อยู่ของเซิร์ฟเวอร์ Mastra ของคุณ หากคุณกำลังพัฒนาในพื้นที่ นี่จะเป็น 131 ที่อยู่ เนื่องจากอาจมีข้อขัดแย้งเกี่ยวกับพอร์ตใน 140 คุณสามารถเปลี่ยนการกำหนดค่าของเซิร์ฟเวอร์ Mastra เมื่อใช้งานในเครื่องได้ดังนี้:
export const mastra = new Mastra({
storage: myMastraUpstashStore,
agents: { articleAgent },
server: {
port: 4111,
timeout: 10000,
}
});
ตอนนี้ เมื่อเรารันเซิร์ฟเวอร์ Mastra ภายในเครื่องด้วย 156 โดยจะให้บริการที่พอร์ต 169 . เราสามารถตั้งค่า 172 ได้ ถึง 186 เมื่อเรารันโครงการ Next.js ภายในเครื่อง
มาดูกันว่าเราจะใช้ SDK ไคลเอนต์ของ Mastra ได้อย่างไร
export const MASTRA_CONFIG = {
resourceId: process.env.NEXT_PUBLIC_RESOURCE_ID || "articleAgent",
agentId: "articleAgent",
baseUrl: process.env.NEXT_PUBLIC_MASTRA_API || "http://localhost:4111",
retries: 3,
}; // this is exported in another file so that we can use it anywhere in the codebase.
// Get your agent and simply stream your response through your agent object.
const agent = mastra_sdk.getAgent(MASTRA_CONFIG.agentId);
const response = await agent.stream({
messages: [message],
resourceId: MASTRA_CONFIG.resourceId,
threadId: threadId
});คุณสามารถรับเครื่องมือและตัวแทนของคุณได้ และเมื่อคุณมีแล้ว คุณสามารถทำเกือบทุกอย่างที่คุณสามารถทำได้กับออบเจ็กต์จริงผ่าน SDK ไคลเอ็นต์
เนื่องจากเราจะเผยแพร่โปรเจ็กต์สาธิตนี้ต่อสาธารณะ จึงเป็นสิ่งสำคัญที่จะหลีกเลี่ยงภาระหนักในเอเจนต์ This is where Upstash Ratelimit comes in. Before every stream request, we will check if the user is rate-limited. ในการกำหนดค่าตัวจำกัดอัตราของเรา เราจะต้องมี Upstash Redis เราสามารถใช้ฐานข้อมูล Redis เดียวกันกับที่เรามีสำหรับตัวแทน Mastra ของเราได้
import { Ratelimit } from '@upstash/ratelimit';
import { Redis } from '@upstash/redis';
// Using the same Redis DB across the project
export const rateLimit = new Ratelimit({
redis: new Redis({
url: process.env.UPSTASH_REDIS_MEMORY_URL!,
token: process.env.UPSTASH_REDIS_MEMORY_TOKEN!
}),
limiter: Ratelimit.slidingWindow(10, '10s'),
prefix: 'upstash-ratelimit',
});
// Fetch the below function before every stream.
export async function isRateLimited(id: string): Promise<boolean> {
const { success } = await rateLimit.limit(id);
return !success;
}ด้วยวิธีนี้ เราจึงมั่นใจได้ว่าปลายทางของเราจะไม่อยู่ภายใต้ภาระหนัก
เมื่อสร้างตัวแทนแชทด้วย Mastra การทราบคุณสมบัติบางอย่างของการสร้างเธรดของ Mastra จะมีประโยชน์ โปรดจำไว้ว่าเมื่อเรากำหนดค่าหน่วยความจำสำหรับตัวแทน เราได้ตั้งค่า 190 เป็น 209 ใน 217 วัตถุ สิ่งนี้ทำให้ Mastra สร้างชื่อโดยอัตโนมัติสำหรับเธรดที่สร้างขึ้นใหม่ แต่ประเด็นสำคัญคือ คุณสามารถสร้างเธรดได้อย่างชัดเจน แต่การสร้างหัวเรื่องอัตโนมัติไม่ได้ถูกกระตุ้นในลักษณะนั้น โดยปกติแล้ว วิธีการสร้างเธรดใหม่จะเป็นดังนี้:
const thread = await mastraClient.createMemoryThread({
title: "New Conversation",
metadata: { category: "support" },
resourceId: "resource-1",
agentId: "agent-1",
});
อย่างไรก็ตาม การทำเช่นนี้จะทำให้ความสามารถของตัวแทนในการสร้างชื่อเรื่องโดยอัตโนมัติหายไป เนื่องจากคุณตั้งค่าด้วยตนเอง ออกจาก 223 ช่องว่างก็ใช้งานไม่ได้เช่นกัน ในกรณีนี้ เราจะเห็นได้ว่า Playground ทำอะไรได้บ้าง จำ Playground ที่ Mastra จัดทำขึ้นเพื่อสัมผัสความสามารถของเซิร์ฟเวอร์ของคุณในระหว่างการพัฒนาหรือไม่? หากเราตรวจสอบแท็บเครือข่ายในเครื่องมือสำหรับนักพัฒนาเบราว์เซอร์ เราจะเห็นว่าเมื่อมีการสร้างเธรดใหม่ เธรดใหม่จะไม่ส่งคำขอ API เพื่อสร้างเธรดดังกล่าว แต่จะรอให้คุณส่งข้อความแรกแทน หลังจากนั้นจะส่งคำขอสตรีมพร้อม ID เธรดที่สร้างขึ้นใหม่ สิ่งนี้จะบอก Mastra ว่าไม่มีเธรดที่มี ID นี้ ดังนั้นควรสร้างเธรดขึ้นมา และหาก 234 เป็นจริง ให้ตั้งชื่อตามข้อความแรก
มาต่อด้วยองค์ประกอบสุดท้ายของโครงการของเรา:บทความ arXiv
บทความ arXiv
arXiv เป็นคลังบทความวิจัยเกือบ 2.4 ล้านบทความในสาขาต่างๆ ที่เปิดให้เข้าถึงได้ 245 สืบค้นฐานข้อมูล Upstash Vector ซึ่งป้อนโดยบทความที่ดึงข้อมูลผ่าน arXiv API API นั้นใช้งานง่าย คุณสามารถหารายละเอียดเพิ่มเติมได้ที่นี่
ในโครงการของเรา เราดึงข้อมูลและจัดเก็บบทความทุกวัน ครั้งแรกที่เซิร์ฟเวอร์ทำงาน จะดึงบทความประมาณ 30,000 บทความจากหมวดหมู่ที่ระบุ หลังจากนั้นจะดึงบทความใหม่ที่เผยแพร่เมื่อวันก่อน ในการระบุหมวดหมู่ของบทความและไม่ว่าจะดึงข้อมูลชุดใหญ่เริ่มต้นหรือไม่ เราได้ตั้งค่าตัวแปรสภาพแวดล้อมที่เกี่ยวข้อง เราควรจัดเตรียมหมวดหมู่บทความที่ต้องการโดยใช้อนุกรมวิธานของ arXiv โดยคั่นด้วยเครื่องหมายจุลภาค คุณสามารถค้นหาหมวดหมู่ได้ที่นี่
CATEGORIES=cs.AI
RUN_BEGINNING_STACK=falseหากคุณต้องการฐานข้อมูลที่ครอบคลุมมากขึ้น คุณสามารถใช้การเข้าถึงข้อมูลจำนวนมากของ arXiv ได้ หากไม่มีสิ่งนี้ เราก็จะถูกจำกัดไว้ที่ 30,000 บทความต่อการสืบค้น API ซึ่งเพียงพอสำหรับวัตถุประสงค์ของเรา
ข้อความค้นหาง่ายๆ สำหรับ arXiv มีลักษณะดังนี้:
const categories = process.env.CATEGORIES?.split(',') || []; // Get the desired categories and split them for the query.
const searchQuery = categories.length === 1 ? `cat:${categories[0]}` : `(${categories.map(c => `cat:${c}`).join(" OR ")})`;
const query = `search_query=${searchQuery}&sortBy=submittedDate&sortOrder=descending`;
const url = `http://export.arxiv.org/api/query?${query}`;
const response = await axios.get(url); // Make the API call with the constructed URL.เราโทรที่คล้ายกันเพื่อรับบทความล่าสุดทุกวันและดึงข้อมูลสแต็กเริ่มต้น
หลังจากดึงข้อมูลบทความแล้ว เราจะทำให้บทความเหล่านั้นเป็นมาตรฐานและฝังไว้เพื่อจัดเก็บใน Upstash Vector นี่จะต้องเป็นฐานข้อมูลเวกเตอร์เดียวกันกับที่เครื่องมือ Mastra ของเราใช้ โดย "ทำให้เป็นมาตรฐาน" เราหมายถึงการแยกวิเคราะห์บทความที่ดึงมาออกเป็น 254 มาตรฐาน ประเภทซึ่งเราจะใช้ทั่วทั้งโค้ดเบสของเรา
export interface ArxivPaper {
id: string;
title: string;
abstract: string;
authors: string[];
published: string;
pdfUrl: string;
category: string;
}// The type for our articles, across our codebase.
async function storeAbstracts(papers: ArxivPaper[]) {
const embeddingModel = openai.embedding("text-embedding-3-small"); // The same model used to query on the Mastra side.
const embeddings = await embedArticles(papers, embeddingModel)
// Put the embeddings into the required form with their metadata.
const vectorsToUpsert = getVectorsToUpsert(embeddings, papers)
for (let j = 0; j < vectorsToUpsert.length; j++) {
await vectorStore.upsert(vectorsToUpsert[j], { namespace: "arxiv" }); // Upsert the embeddings with their metadata to Upstash Vector.
}
}To ensure our database remains current with the latest research, we implement Upstash QStash for scheduled task execution. ด้วยการปรับใช้บน Vercel เราจำเป็นต้องป้องกันการหมดเวลาของฟังก์ชันที่อาจเกิดขึ้นกับช่วงการประมวลผลที่ขยายออกไป เราแก้ไขปัญหานี้ด้วยการเปิดเผยตำแหน่งข้อมูล API สาธารณะบนเซิร์ฟเวอร์ของเรา ทำให้อินสแตนซ์ QStash ของเราเรียกใช้ฟังก์ชันการอัปเดตฐานข้อมูลรายวันได้อย่างน่าเชื่อถือ
// src/app/api/arxiv_reneval/route.ts
import { verifySignatureAppRouter } from "@upstash/qstash/nextjs"
import { fetchAndUpsertYesterday} from "@/services/arxiv"
async function handler(request: Request) {
console.log("Fetching and upserting yesterday's papers...")
await fetchAndUpsertYesterday()
console.log("Fetching and upserting yesterday's papers completed")
return Response.json({ success: true })
}
export const POST = verifySignatureAppRouter(handler)สามารถกำหนดค่าตัวกำหนดเวลาได้ผ่าน Upstash Console เพื่อทริกเกอร์คำขอไปยังตำแหน่งข้อมูลนี้โดยอัตโนมัติทุกวันเวลา 6:00 น. UTC
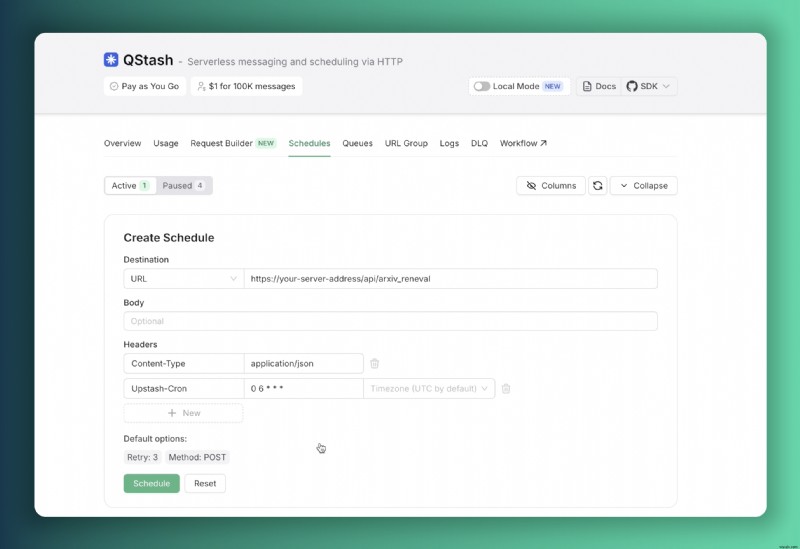
ด้วยการกำหนดค่าตัวกำหนดเวลานี้ เซิร์ฟเวอร์ของเราจะดำเนินการอัปเดตฐานข้อมูลอัตโนมัติทุกเช้า เพื่อให้มั่นใจว่าข้อมูลมีความสดใหม่อย่างต่อเนื่อง
เราควรจัดเตรียมข้อมูลประจำตัวสำหรับอินสแตนซ์ QStash ของเราด้วย ตัวแปร env ที่จำเป็นทั้งหมดจะได้รับในไฟล์ env ตัวอย่าง
นั่นก็ค่อนข้างมาก หากต้องการคุณสามารถลองเล่นกับโค้ดได้ เพียงแยกที่เก็บและเริ่มพัฒนา คุณสามารถไปที่พื้นที่เก็บข้อมูลของส่วนของ Mastra ที่นี่ และ repo อื่น ๆ ที่นี่ หลังจากฟอร์กพวกมันแล้ว:
- โคลนพวกมันไปยังเครื่องของคุณ
- กรอกตัวแปรสภาพแวดล้อมของคุณ (ตัวอย่าง
265มีไฟล์ให้มาด้วย) - ไปที่ไดเร็กทอรีรากสำหรับทั้งสองโครงการในเทอร์มินัลที่แยกจากกัน
- เรียกใช้คำสั่งต่อไปนี้:
npm install
npm run devตอนนี้คุณสามารถดูใบสมัครของคุณได้ที่ http://localhost:3000
ด้วย Mastra คุณสามารถสร้างสิ่งที่ซับซ้อนมากขึ้นได้โดยใช้เทมเพลตอื่นๆ เช่น RAG เวิร์กโฟลว์ และเครือข่าย ดูเหมือนว่าหน่วยความจำและอุปกรณ์จัดเก็บข้อมูลมีบทบาทสำคัญในวัตถุประสงค์เหล่านี้ทั้งหมด นี่คือจุดที่ Upstash เปล่งประกาย
