
คุณเคยสังเกตไหมว่าช่องค้นหาแนะนำคำในขณะที่คุณพิมพ์อย่างไร ปรากฎว่าคำแนะนำเหล่านี้ส่วนใหญ่แสดงตามลำดับตัวอักษรและไม่มีประโยชน์มากนัก
แต่จะเป็นอย่างไรหากช่องค้นหามีประสิทธิภาพมากขึ้นเมื่อเวลาผ่านไป
เรียนรู้จากสิ่งที่ผู้คนคลิกจริงๆ และแสดงผลลัพธ์ที่ได้รับความนิยมสูงสุดก่อน
นี่คือสิ่งที่เราจะสร้าง:
เราจะดูว่าชุดที่เรียงลำดับ Redis สามารถขับเคลื่อนระบบเติมข้อความอัตโนมัติอัจฉริยะที่เรียนรู้จากพฤติกรรมของผู้ใช้และแม่นยำยิ่งขึ้น (แสดงผลลัพธ์ยอดนิยมก่อน) เมื่อเวลาผ่านไปได้อย่างไร
แนวคิดของระบบเติมข้อความอัตโนมัติอัจฉริยะ
ช่องค้นหาพื้นฐานจะใช้วิธีการที่เรียกว่าการจับคู่คำนำหน้าเพื่อตัดสินใจว่าจะแสดงผลลัพธ์ใดก่อน
ขณะที่คุณพิมพ์ ระบบจะแสดงรายการที่ตรงกันตามลำดับ A-Z จริงๆ แล้วไม่สนใจว่าผู้คนจะคลิกผลลัพธ์ใดมากที่สุด
เราจะทำให้มันฉลาดขึ้น ช่องค้นหาของเราจะเรียนรู้จากสิ่งที่ผู้คนเลือก . เมื่อมีคนคลิกที่ผลการค้นหา เราจะแสดงผลลัพธ์นั้นก่อนในครั้งต่อไป
ซึ่งหมายความว่าการค้นหาของเราจะดีขึ้นและเป็นประโยชน์มากขึ้นเมื่อเวลาผ่านไปโดยการแสดงผลลัพธ์ที่ได้รับความนิยมสูงสุดที่ด้านบนโดยอัตโนมัติ
เหตุใดจึงมีความสำคัญสำหรับแอปพลิเคชันการค้นหา
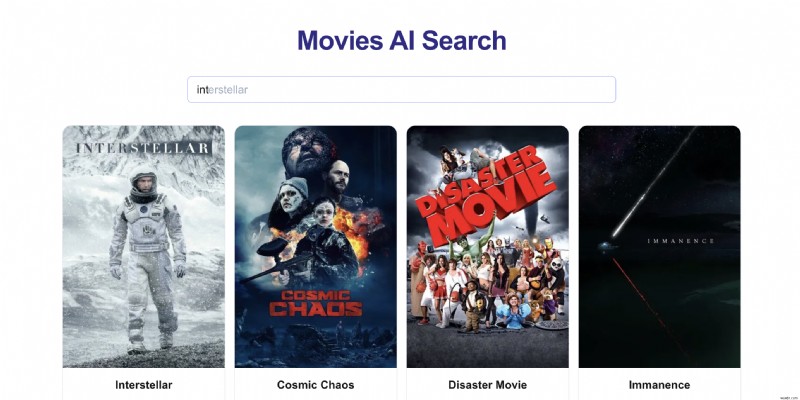
พิจารณาแอปพลิเคชันค้นหาภาพยนตร์:เมื่อผู้ใช้พิมพ์ "int" พวกเขาอาจเห็น:
- "ตัวสกัดกั้น"
- "รัฐ 60"
- "ดวงดาว"
ในระบบ "ดั้งเดิม" สิ่งเหล่านี้จะปรากฏตามตัวอักษร อย่างไรก็ตาม หากผู้ใช้คลิกที่ "Interstellar" อย่างสม่ำเสมอ เราก็อยากจะเลื่อนระดับให้อยู่ด้านบนสุดของคำแนะนำที่เติมข้อความอัตโนมัติ
ระบบการจัดอันดับอัจฉริยะนี้ทำงานได้ดีมากสำหรับ:
- บริการสตรีมมิ่ง เช่น Netflix หรือ YouTube เพื่อแสดงสิ่งที่ผู้คนรับชมมากที่สุด
- ร้านค้าออนไลน์ เพื่อแสดงผลิตภัณฑ์ยอดนิยมก่อนเมื่อค้นหา
- ศูนย์ช่วยเหลือ เพื่อแสดงคำถามที่พบบ่อยที่สุดที่ผู้คนถาม
- เว็บไซต์ใดๆ ที่มีการค้นหา เพื่อแสดงสิ่งที่คนส่วนใหญ่คลิกเป็นอันดับแรก
ทำความเข้าใจกับชุดที่เรียงลำดับ Redis
มาทำความเข้าใจว่าทำไม Redis Sorted Set ถึงยอดเยี่ยมสำหรับการสร้างระบบเติมข้อความอัตโนมัติ
ชุดเรียงลำดับ Redis เปรียบเสมือนรายการอัจฉริยะโดยที่:
- แต่ละรายการมีเอกลักษณ์เฉพาะตัว (เหมือนชุด)
- แต่ละรายการมีคะแนน (สำหรับการสั่งซื้อ)
- รายการสามารถจัดเรียงได้อย่างรวดเร็วตามคะแนน
สำหรับระบบเติมข้อความอัตโนมัติ เราจะใช้ชุดการเรียงลำดับสองชุด:
- หนึ่งรายการสำหรับคำนำหน้าข้อความที่ตรงกัน (เช่น "int" ตรงกับ "interstellar")
- อีกหนึ่งรายการสำหรับติดตามความนิยมของคำแนะนำแต่ละรายการ
สองชุดนี้ทำงานร่วมกันเพื่อแนะนำผลลัพธ์ที่เกี่ยวข้องมากที่สุดตามที่ผู้ใช้พิมพ์
รากฐาน:การเรียงลำดับตามตัวอักษร
ชุดเรียงลำดับ Redis จะรักษาลำดับตามตัวอักษรเมื่อสมาชิกทุกคนมีคะแนนเท่ากัน วิธีนี้เหมาะอย่างยิ่งสำหรับการสร้างคำแนะนำในการค้นหา เนื่องจากช่วยให้เรา:
- จัดเก็บคำนำหน้าทั้งหมด ของคำที่สามารถค้นหาได้ในโครงสร้างข้อมูลเดียว
- ใช้
ZRANKเพื่อค้นหาตำแหน่งเริ่มต้นของคำนำหน้าใดๆ ในเวลา O(log N) - ใช้
ZSCANเพื่อดึงข้อมูลการแข่งขันทั้งหมดที่เริ่มต้นจากตำแหน่งนั้นอย่างมีประสิทธิภาพ - ใช้
ZMSCOREเพื่อรับคะแนนความนิยมของแต่ละนัด - ใช้
ZINCRBYเพื่อเพิ่มคะแนนความนิยมของแต่ละนัด
ลองดูตัวอย่างง่ายๆ เมื่อเราเพิ่มภาพยนตร์เรื่อง "INTERSTELLAR" ลงในระบบการค้นหาของเรา เราจะแยกย่อยดังนี้:
- คะแนน:0 สมาชิก:"ฉัน"
- คะแนน:0 สมาชิก:"IN"
- คะแนน:0 สมาชิก:"INT"
- คะแนน:0 สมาชิก:"INTE"
- คะแนน:0 สมาชิก:"INTER"
- คะแนน:0 สมาชิก:"INTERSTELLAR$Interstellar" (รายการที่สมบูรณ์พร้อมรูปแบบการแสดงผล)
ดูว่าเราใช้ $ อย่างไร หากต้องการแยกเวอร์ชันการค้นหาออกจากเวอร์ชันที่แสดง ด้วยวิธีนี้ ผู้ใช้สามารถค้นหาได้โดยไม่ต้องกังวลกับอักษรตัวพิมพ์ใหญ่หรือตัวพิมพ์เล็ก แต่เรายังคงแสดงชื่อภาพยนตร์ว่าควรจะมีลักษณะอย่างไร
เราจัดเก็บข้อมูลอย่างไร
เราใช้ชุดการจัดเรียง Redis สองชุดเพื่อทำให้การเติมข้อความอัตโนมัติของเราทำงาน:
1. รายการชื่อภาพยนตร์
มาติดตามชุดที่จัดเรียงที่เรียกว่า movies . ลองคิดดูว่านี่เป็นพจนานุกรมที่ช่วยให้เราค้นหาภาพยนตร์ได้อย่างรวดเร็ว เมื่อมีคนพิมพ์ "int" เราจะสามารถค้นหาภาพยนตร์ทั้งหมดที่ขึ้นต้นด้วยตัวอักษรเหล่านั้นได้ทันที
การเกิดขึ้นครั้งแรกของ "int" จะพบได้ภายใน ZRANK จากนั้นเริ่มจากตำแหน่งนั้นชื่อภาพยนตร์เต็มที่มีไวด์การ์ด INT*$* จะถูกดึงออกมา
2. รายการภาพยนตร์ยอดนิยม
เรามาติดตามชุดการจัดเรียงที่เรียกว่า movie-popularity กัน . นี่คือรายการ "ภาพยนตร์ที่กำลังมาแรง" ของเรา
ทุกครั้งที่มีคนคลิกภาพยนตร์ในผลการค้นหา ภาพยนตร์นั้นจะได้รับความนิยมมากขึ้นโดยการเพิ่มคะแนนโดยใช้ ZINCRBY . ภาพยนตร์ที่มีคนคลิกมากที่สุดจะปรากฏเป็นอันดับแรกในการค้นหาในอนาคต
มันเหมือนกับวิธีที่ Netflix แสดงภาพยนตร์ที่กำลังมาแรงให้คุณดู - ยิ่งมีคนดูอะไรมากเท่าไรก็ยิ่งปรากฏในคำแนะนำมากขึ้นเท่านั้น
ในกรณีของเรา หลังจากที่ค้นหาค่าที่ตรงกันทั้งหมดสำหรับ INT*$* แล้ว เราไปเช็คคะแนนกันที่ movie-popularity เพื่อให้ได้สิ่งที่ได้รับความนิยมสูงสุด
กระแสอัลกอริทึม
graph TD
A[User types 'int'] --> B[ZRANK: Find lexicographic position of 'INT']
B --> C[ZSCAN: Retrieve matches starting from position (movies set)]
C --> D[Filter: Extract complete terms containing '$']
D --> E[ZMSCORE: Get popularity scores for all matches (movie-popularity set)]
E --> F[Rank: Return highest-scored suggestion]
G[User selects suggestion] --> H[ZINCRBY: Increment popularity score]
H --> I[Future searches: Higher scored items rank first]
I --> Aเมื่อผู้ใช้ค้นหาและคลิกคำแนะนำ ระบบจะเรียนรู้และปรับปรุง ยิ่งมีคนใช้งานมากเท่าใด การแสดงคำแนะนำที่เกี่ยวข้องมากที่สุดก่อนก็จะยิ่งดียิ่งขึ้น
มาสร้างระบบเติมข้อความอัตโนมัติกันเถอะ
มาดูกันว่าเราสร้างระบบเติมข้อความอัตโนมัตินี้ทีละขั้นตอนอย่างไร เราจะทำให้มันง่ายมาก!
ขั้นตอนที่ 1:การเพิ่มชื่อภาพยนตร์ลงใน Redis
ขั้นแรก เราต้องเพิ่มชื่อภาพยนตร์ของเราลงใน Redis เพื่อให้เราสามารถค้นหาได้ในภายหลัง คุณสามารถเริ่มต้นด้วยรายการภาพยนตร์ง่ายๆ ได้จากทุกที่ - อาจเป็นฐานข้อมูลของคุณหรือเพียงไฟล์ข้อความ นี่คือวิธีที่เราเพิ่ม:
import { Redis } from "@upstash/redis";
const redis = new Redis({
url: process.env.UPSTASH_REDIS_URL!,
token: process.env.UPSTASH_REDIS_TOKEN!,
});
// Example: your list of titles
const titles = [
"Interceptor",
"Interstate 60",
"Interstellar",
// ... more titles
];
async function populateAutocomplete() {
// Insert prefixes and full titles into the 'movies' sorted set
for (const title of titles) {
let term = title.toUpperCase();
let terms = [];
for (let i = 1; i < term.length; i++) {
terms.push({ score: 0, member: term.substring(0, i) });
}
terms.push({ score: 0, member: term });
terms.push({ score: 0, member: term + "$" + title });
await redis.zadd("movies", ...terms);
}
// Insert all titles into the 'movie-popularity' sorted set for popularity tracking
await redis.zadd(
"movie-popularity",
...titles.map((title) => ({
score: 0,
member: title.toUpperCase(),
})),
);
}
populateAutocomplete();มาดูรายละเอียดว่าโค้ดด้านบนนี้ใช้ทำอะไร:
-
สำหรับชื่อภาพยนตร์แต่ละเรื่อง เราจัดเก็บ:
- การจับคู่บางส่วนที่เป็นไปได้ทั้งหมด (เช่น "INT", "INTE", "INTER" สำหรับ "Interstellar")
- ชื่อเต็ม
- เวอร์ชันที่จัดรูปแบบสำหรับการแสดงผล
-
นอกจากนี้ เรายังสร้างรายการแยกต่างหากเพื่อติดตามความนิยมของภาพยนตร์แต่ละเรื่อง โดยเริ่มต้นที่จำนวนการดูเป็นศูนย์
สิ่งนี้ทำให้เรามีทุกสิ่งที่จำเป็นในการแสดงคำแนะนำอันชาญฉลาดในขณะที่ผู้ใช้พิมพ์และเรียนรู้จากสิ่งที่พวกเขาคลิก
ขั้นตอนที่ 2:ค้นหาคู่ที่ดีที่สุด
ต่อไป เราจะดูว่าเราค้นหาชื่อภาพยนตร์เหล่านี้อย่างไรเพื่อค้นหารายการที่ตรงกัน matchQuery ของเรา ฟังก์ชั่นทำหน้าที่ยกของหนักทั้งหมด:
export const matchQuery = async (query: string): Promise<string | null> => {
const upperQuery = query.toUpperCase();
// Step 1: Find starting position using lexicographic ordering
let rank = await redis.zrank("movies", upperQuery);
if (rank === null) return null;
// Step 2: Efficiently scan for matches from that position
const scanResult = await redis.zscan("movies", rank, {
match: `${upperQuery}*$*`,
count: 1000,
});
// Step 3: Extract complete entries and get their popularity scores
const completeTitles = scanResult[1].filter(
(el, idx) => idx % 2 === 0 && el.includes("$"),
);
const baseNames = completeTitles.map((title) => title.split("$")[0]);
const scores = await redis.zmscore("movie-popularity", baseNames);
// Step 4: Return the highest-scored (most popular) match
const maxScore = Math.max(...scores);
const bestMatchIndex = scores.indexOf(maxScore);
return completeTitles[bestMatchIndex].split("$")[1];
};การเรียนรู้จากตัวเลือกของผู้ใช้
เมื่อมีคนเลือกชื่อภาพยนตร์ เราจะเพิ่มคะแนน 1 คะแนน ภาพยนตร์ที่มีคะแนนมากกว่าจะแสดงอยู่ในรายการแนะนำที่สูงกว่า มันง่ายมาก!
ระบบจะฉลาดขึ้นเมื่อเวลาผ่านไปโดยการติดตามสิ่งที่ผู้คนเลือกจริงๆ
const onSubmit = async (title: string) => {
// Handle submit logic here
await redis.zincrby("movie-popularity", 1, title.toUpperCase());
};มันเร็วแค่ไหน?
มาดูกันว่าวิธีแก้ปัญหานี้เร็วแค่ไหนโดยแจกแจงเวลาแต่ละการดำเนินการที่ใช้:
- ZRANK :O(log N) - เวลาค้นหาลอการิทึม
- ZSCAN :O(log N + M) - โดยที่ M คือจำนวนองค์ประกอบที่ส่งคืน
- ZMSCORE :O(N) - โดยที่ N คือจำนวนผลลัพธ์ที่ตรงกัน ไม่ใช่ขนาดชุดข้อมูลทั้งหมด
- ซินซีบี :O(log N) - การเพิ่มขึ้นอะตอมด้วยความซับซ้อนของลอการิทึม
เมื่อเราเพิ่มชื่อภาพยนตร์ ประสิทธิภาพก็ยังคงสม่ำเสมอ
บทสรุป:สิ่งที่เราสร้างขึ้นร่วมกัน
คุณเพิ่งเรียนรู้วิธีสร้างช่องค้นหาอัจฉริยะที่จะดีขึ้นเมื่อเวลาผ่านไปโดยไม่ต้องใช้ AI!
การเติมข้อความอัตโนมัติของเราจะเรียนรู้จากสิ่งที่ผู้คนเลือกและใช้ข้อมูลนั้นเพื่อแสดงคำแนะนำที่ดีขึ้น
รวดเร็ว ง่ายดาย และมีประโยชน์มากขึ้นเมื่อมีผู้คนใช้งานมากขึ้น
ต้องการพูดคุยเกี่ยวกับกลยุทธ์การเพิ่มประสิทธิภาพ Redis หรือแชร์การใช้งานของคุณเองไหม เข้าร่วมกับเราบน Discord!
