
สิ่งที่เรากำลังสร้าง
ในบทความนี้ เรากำลังสร้างสตรีม LLM ที่มีความทนทานอย่างยิ่งซึ่งสามารถอยู่รอดได้อย่างง่ายดาย:
- เครือข่ายขัดข้อง
- เพจรีเฟรช
- การปิดเว็บไซต์
- การปิดฝาแล็ปท็อป
โบนัส:คุณสามารถดูสตรีมเดียวกันได้บนอุปกรณ์หลายเครื่อง (เช่น โทรศัพท์และแล็ปท็อป) ในเวลาเดียวกัน .
ไม่ว่าคุณจะพยายามหยุดสตรีมมากเพียงใด สตรีมจะยังคงอยู่ในพื้นหลังในขณะที่คุณไม่ได้เชื่อมต่อ และดำเนินการต่ออย่างราบรื่นเมื่อคุณกลับมา นี่เป็นสิ่งที่ เหลือเชื่อ ประสบการณ์ผู้ใช้
การสาธิตสตรีม LLM ที่ทนทาน 👇
แรงบันดาลใจ
เมื่อสร้างด้วย AI แนวทางปฏิบัติที่ดีที่สุดในการสตรีมการตอบสนองของ AI แบบเรียลไทม์
แทนที่จะรอการตอบกลับทั้งหมด ผู้ใช้ของคุณจะเห็นเนื้อหาแบบเรียลไทม์ในขณะที่มันถูกสร้างขึ้น ซึ่งน่าทึ่งมากสำหรับ UX เครื่องมืออย่าง AI SDK โดย Vercel ทำให้สิ่งนี้ง่ายมาก:
import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});หากต้องการให้สตรีม LLM แบบเรียลไทม์ทำงานในระดับเทคนิค คุณต้องเชื่อมต่อไคลเอ็นต์กับ API และสตรีมข้อมูลกลับโดยใช้โปรโตคอล เช่น Server Sent Events (SSE):
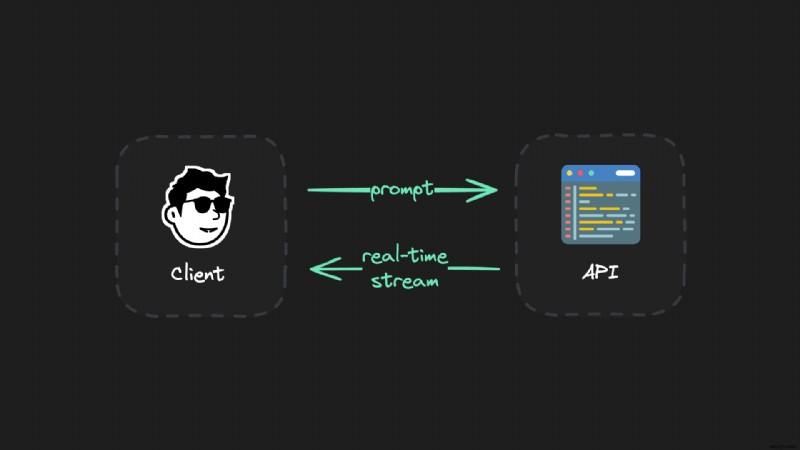
แต่:การตั้งค่านี้มีปัญหา
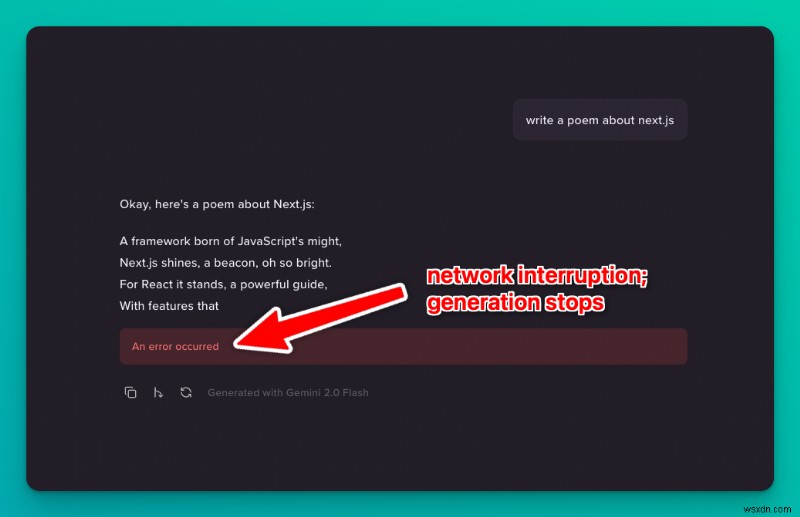
หากมีสิ่งใดเกิดขึ้นระหว่างการสตรีม เช่น การตัดการเชื่อมต่ออินเทอร์เน็ต การปิดฝาแล็ปท็อป หรือการขัดข้องของเครือข่าย รุ่นทั้งหมดจะสูญหายไป คุณต้องเริ่มต้นใหม่และรอคนรุ่นทั้งหมดอีกครั้ง สิ่งนี้สร้างความรำคาญให้กับคนรุ่นต่อๆ ไป (เช่น โมเดลที่ใช้งานราคาแพงอย่าง O1)
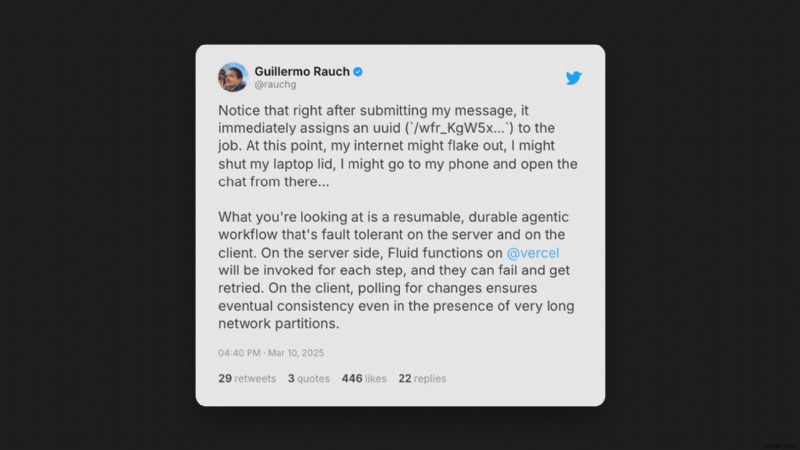
แน่นอนว่าปัญหานี้อยู่ในเรดาร์ของผู้คน มีความต้องการอย่างแท้จริงสำหรับการสตรีม LLM แบบเรียลไทม์ที่เชื่อถือได้ และนักพัฒนาจำนวนมากกำลังทดลองวิธีทำให้มันใช้งานได้:
การสร้างสตรีม LLM ที่มีความทนทานสูง
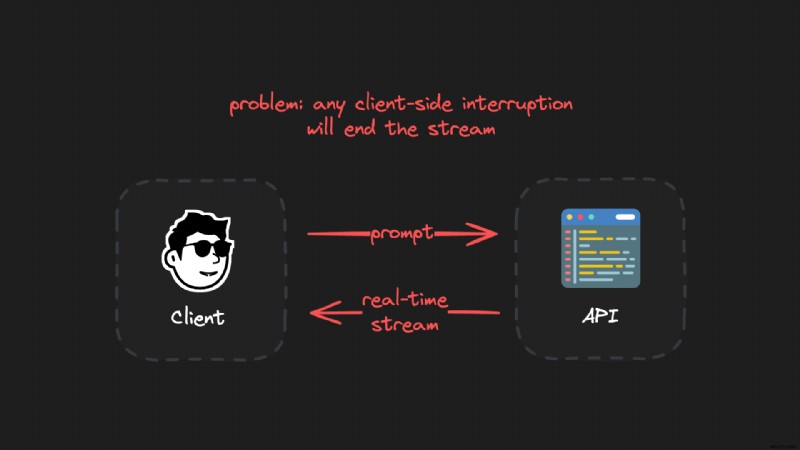
สูตรลับสำหรับการสร้างสตรีม LLM ที่ทนทานและใช้งานต่อได้อย่างแท้จริงกำลังแยกไคลเอนต์ออกจากสภาพแวดล้อมการสร้าง การเชื่อมต่อไคลเอนต์ไม่เสถียรและสามารถยกเลิกการเชื่อมต่อได้ด้วยเหตุผลหลายประการ เช่น การปิดแล็ปท็อป ปัญหาเครือข่าย หรือการรีเฟรชเพจ
โดยการแยกไคลเอ็นต์และกระบวนการสร้างออกจากกัน การสร้างจะดำเนินต่อไปอย่างต่อเนื่องโดยไม่หยุดชะงัก ลูกค้าสามารถเชื่อมต่อใหม่ได้ตลอดเวลาโดยไม่รบกวนรุ่นที่กำลังดำเนินอยู่
ความคิดที่ไม่ดี:การเชื่อมต่อโดยตรงอย่างต่อเนื่อง:
ความคิดที่ดี:การเชื่อมต่อสตรีมแบบเปลี่ยนได้และขัดจังหวะได้:
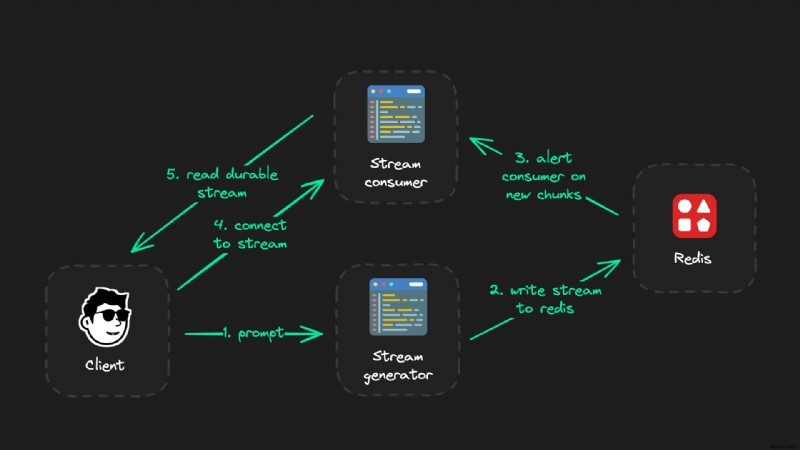
ใช่แล้ว สถาปัตยกรรมนี้อาจดูค่อนข้างซับซ้อนสำหรับการสตรีม AI แบบธรรมดา ดังที่คุณเห็นในโค้ดตอนนี้ นี่เป็นโค้ดเพียงไม่กี่บรรทัดและใช้เวลาเพียงไม่กี่นาทีในการติดตั้ง
การตั้งค่าการสตรีมที่ทนทาน
การตั้งค่าสตรีม LLM ที่เชื่อถือได้อย่างยิ่งมีสามส่วน:
- ลูกค้า (ส่วนหน้า)
- ตัวสร้างสตรีม (เส้นทาง API)
- ผู้บริโภคสตรีม (รวมถึงเส้นทาง API)
การเชื่อมต่อโดยตรงกับไคลเอนต์ทั้งหมดสามารถถูกขัดจังหวะหรือหยุดชั่วคราวได้ตลอดเวลา ชิ้นส่วนของตรรกะที่รับผิดชอบในการสร้างสตรีมเอาท์พุต LLM (ตัวสร้างสตรีม) จึงควรเป็น API อิสระที่ไม่เคยมีการเชื่อมต่อกับไคลเอนต์
แต่เราจะเชื่อมต่อกับไคลเอนต์ผ่านทางผู้บริโภคแทน - ซึ่งเพิ่งอ่านข้อมูลจาก Redis และค่อนข้างจะ "โง่" แทน จุดประสงค์เดียวคือเพื่ออ่านเอาต์พุตของตัวสร้างและจัดเตรียมชิ้นส่วน LLM ทั้งหมดที่ไคลเอนต์ยังไม่เคยเห็นเมื่อใดก็ตามที่ไคลเอนต์เชื่อมต่อกับมัน แค่นั้นแหละ.
สรุปโดยย่อ - แต่ละส่วนทำอะไร:
- ลูกค้า: ทริกเกอร์ตัวสร้างสตรีม (แต่ไม่เคยรักษาการเชื่อมต่อแบบเปิด) และเรนเดอร์สตรีมแบบเรียลไทม์
- ตัวสร้างสตรีม: สร้างเอาต์พุต LLM แบบเรียลไทม์และเผยแพร่ไปยัง Redis
- สตรีมผู้บริโภค: อ่านสตรีมของตัวสร้างและพุชชิ้นส่วนไปยังไคลเอนต์
ตัวสร้างมีหน้าที่อ่านสตรีม LLM และเผยแพร่ไปยัง Redis แบบเรียลไทม์เท่านั้น เราได้รับการเชื่อมต่อที่เปลี่ยนได้จากไคลเอนต์ไปยังผู้บริโภคสตรีมที่สามารถสิ้นสุด เชื่อมต่อใหม่ ฯลฯ - ไม่มีผลกระทบใด ๆ กับตัวสร้างสตรีม
ตัวอย่างโค้ด
ในส่วนนี้เราจะมาดูโค้ดกัน เพื่อให้หลักการชัดเจน เราจะดูที่การใช้งานจริงและสมบูรณ์ของโค้ดจริงในตอนท้าย
สำหรับตอนนี้ การเข้าใจโค้ดจะง่ายกว่ามากหากเราพิจารณาที่ส่วนย่อยหลักและวัตถุประสงค์ แทนที่จะดูที่ไฟล์โค้ดทั้งหมด
1. ลูกค้า
ลูกค้ามีหน้าที่รับผิดชอบ 3 ประการเท่านั้น:
- การสร้างรหัสเซสชัน
- การทริกเกอร์ตัวสร้าง
- การเรนเดอร์สตรีมการสร้าง
มาดูกันทีละอัน:
ไคลเอนต์:กำลังสร้างรหัสเซสชัน
เมื่อไคลเอนต์เชื่อมต่อหรือเชื่อมต่อกับสตรีมอีกครั้ง เราต้องการส่งข้อความทั้งหมดที่ไคลเอนต์ยังไม่เคยเห็น นั่นหมายความว่าในระหว่างสตรีมที่ใช้งานอยู่ แต่ละข้อความจะมีเฉพาะเดลต้าที่แน่นอนที่ไคลเอ็นต์จำเป็นต้องดู ไม่ใช่สตรีมทั้งหมด
เมื่อเชื่อมต่อใหม่ สตรีมทั้งหมดจนถึงจุดรุ่นปัจจุบันจะถูกส่งและการสมัครสมาชิกกิจกรรมในอนาคตทั้งหมดจะราบรื่นโดยไม่มีส่วนขาดหายไป
อย่างไร?
Redis Streams ซึ่งเป็นวิธีจัดเก็บและดึงข้อมูลแบบเรียลไทม์อย่างมีประสิทธิภาพ มีฟังก์ชันที่ยังไม่เคยเห็นมาก่อนซึ่งสร้างอยู่ภายในผ่านสิ่งที่เรียกว่ากลุ่มผู้บริโภค สิ่งเดียวที่เราต้องทำ:ตรวจสอบให้แน่ใจว่าลูกค้าแต่ละรายมีเซสชันที่ไม่ซ้ำกัน ซึ่งหมายความว่าเรากำหนด ID ที่ไม่ซ้ำกันให้กับแต่ละรุ่น
เราจะเรียนรู้เพิ่มเติมเกี่ยวกับกลุ่มผู้บริโภคเมื่อดูที่ผู้บริโภคแบบสตรีม มีลักษณะดังนี้:
await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});ตรรกะทั้งหมดที่ไคลเอ็นต์เห็นว่าสตรีมใดจนถึงจุดใดและชิ้นส่วนใดที่ขาดหายไป ได้รับการจัดการโดยสตรีม Redis ทั้งหมด พร้อมรับประกันความแม่นยำ เราไม่เคยได้รับชิ้นส่วน LLM ที่ขาดหายไปและส่งข้อมูลตามที่ลูกค้าต้องการเสมอ
สิ่งเดียวที่ลูกค้าต้องทำในตอนนี้:กำหนด ID สำหรับแต่ละรุ่น เราเพียงแค่ใช้ nanoid :
import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);ไคลเอนต์:ทริกเกอร์กระแสการสร้าง
การโต้ตอบเดียวที่ไคลเอนต์มีต่อเอ็นจิ้นการสร้างคือการทริกเกอร์มัน ในทางเทคนิค คุณสามารถทริกเกอร์การสร้างได้จากทุกที่ (เช่น งาน CRON ไปป์ไลน์อัตโนมัติ)
ในรูปแบบที่ง่ายที่สุด นี่เป็นเพียงการเรียกไปยังเส้นทางการสร้าง API:
// 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});ลูกค้า:กำลังอ่าน Generation Stream
หลังจากทริกเกอร์การสร้าง เครื่องกำเนิดไฟฟ้าจะเริ่มสตรีมเอาต์พุต LLM ไปยังร้านค้า Redis แบบรวมศูนย์ ซึ่งแยกออกจากไคลเอ็นต์โดยสมบูรณ์ มาเชื่อมต่อกับสตรีมคอนซูเมอร์เพื่ออ่านสตรีมรุ่น:
// 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});แค่นั้นแหละ!
นั่นคือความรับผิดชอบสามประการของลูกค้า แน่นอนว่าเราสามารถเพิ่มความน่าสนใจได้มากด้วย hooks แบบกำหนดเองสำหรับการสร้าง ID การตอบกลับแบบสอบถามเพื่อความน่าเชื่อถือเพิ่มเติม และอื่นๆ อีกมากมาย เราจะพูดถึงเรื่องนี้ในตัวอย่างโค้ดที่สมบูรณ์ในภายหลัง
2. เครื่องกำเนิดสตรีม
ตัวสร้างสตรีมจะเปิดสตรีม LLM และเขียนแต่ละส่วนลงในสตรีม Redis โดยจะเผยแพร่ข้อความสำหรับทุกส่วนที่เขียนเพื่อแจ้งเตือนผู้บริโภคสตรีมเกี่ยวกับข้อมูลใหม่สำหรับการอัปเดตแบบเรียลไทม์
หมายเหตุ:ขอย้ำอีกครั้งว่านี่ไม่ใช่ตัวอย่างโค้ดแบบเต็มโดยเจตนา เราจะไปที่โค้ดแบบเต็มในตอนท้าย เพื่อทำความเข้าใจแนวคิด
import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)3. ผู้บริโภคสตรีม
ผู้บริโภคสตรีมเชื่อมต่อกับ Redis และฟังการแจ้งเตือนกลุ่มใหม่ผ่าน Redis pub/sub ลูกค้าแต่ละรายจะมีกลุ่มผู้บริโภคของตนเองเพื่อติดตามข้อความที่เห็นและไม่เห็น
หมายเหตุ:การเผยแพร่ไม่ได้ถ่ายโอนส่วนข้อมูลจริง เพียงแจ้งเตือนว่ามีส่วนข้อมูลใหม่พร้อมใช้งานในสตรีม
เมื่อมีก้อนข้อมูลใหม่ API ผู้บริโภคสตรีมจะอ่านจากสตรีมและส่งต่อไปยังไคลเอนต์ที่เชื่อมต่อทั้งหมด กลุ่มผู้บริโภค Redis ติดตามสิ่งที่ลูกค้าแต่ละรายได้เห็นเพื่อรับประกันว่าไม่มีการถ่ายโอนข้อมูลซ้ำหรือชิ้นส่วนที่ขาดหายไป
ผู้บริโภคกระแสหลักมีลักษณะดังนี้:
const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});หมายเหตุ:เรากำลังสร้างกลุ่มผู้บริโภคในทุกการเชื่อมต่อ วิธีนี้ใช้ได้ผลดีเพราะ Redis จัดการการดำเนินการนี้อย่างมีประสิทธิภาพ เช่น จะไม่มีอะไรเกิดขึ้นหากมีกลุ่มอยู่แล้ว
รหัสเต็ม
การสร้าง SessionID
จนถึงขณะนี้ เราได้ดูโค้ดแต่ละส่วนเพื่อทำความเข้าใจงานของลูกค้า ตัวสร้างสตรีม และผู้ใช้สตรีมเป็นรายบุคคล ตอนนี้ เรามาดูกันว่าชิ้นส่วนเหล่านี้เข้ากันได้อย่างไรโดยดูการใช้งานแบบเต็ม
ในการเริ่มต้น การสร้าง sessionId ควรมีความยืดหยุ่นมากกว่าการใช้ nanoid() . ท้ายที่สุดแล้วหากเว็บไซต์ถูกรีเฟรชหรือปิดล่ะ? เมื่อเชื่อมต่อใหม่ เราจะสูญเสีย sessionId ที่สร้างขึ้นหากเราไม่เก็บไว้ที่ไหนสักแห่ง - มันจะต้องคงอยู่ตราบเท่าที่รุ่นนั้นทำงาน
โชคดีที่ localStorage เหมาะสำหรับสิ่งนี้:
import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};ลูกค้า
เราได้เห็นสองส่วนที่สำคัญที่สุดของลูกค้าแล้ว:การเริ่มต้นสตรีมและการเชื่อมต่อกับสตรีม เมื่อเราได้รับการยืนยันจาก API ว่าตัวสร้างกำลังทำงานอยู่ เราจะเชื่อมต่อกับสตรีมโดยใช้ react-queries refetch ยูทิลิตี้เพื่อเรียกใช้แบบสอบถามการเชื่อมต่อของเรา
ต่อไปนี้คือลักษณะที่ชิ้นส่วนทั้งหมดประกอบเข้ากัน:
app/page.tsx"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}ตัวสร้างสตรีม
นี่คือโค้ดทั้งหมดสำหรับตัวสร้างสตรีม หากการสร้าง LLM ล้มเหลว ณ จุดใดก็ตาม ระบบจะลองอีกครั้งโดยอัตโนมัติโดยใช้ Upstash Workflow เพื่อความน่าเชื่อถือสูงสุด:
api/llm-stream/route.tsimport {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});เพื่อความปลอดภัยประเภทที่สมบูรณ์ ฉันยังเขียนสกีมาข้อความทั้งหมดใน zod:
ข้อความ-schema.tsimport { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};สตรีมผู้บริโภค
สุดท้ายนี้ เรามาดูการใช้งานของผู้บริโภคอย่างเต็มรูปแบบกัน นี่คือการเชื่อมต่อแบบถอดเปลี่ยนได้ซึ่งจะส่งไปตามส่วนที่มองไม่เห็นทั้งหมดโดยอัตโนมัติเมื่อไคลเอนต์เชื่อมต่อ:
api/check-stream/route.tsimport { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}สรุปด่วนและคำสุดท้าย
เราเพิ่งสร้างสตรีม LLM ที่แข็งแกร่งอย่างยิ่ง ซึ่งสามารถจัดการกับการหยุดชะงักของเครือข่าย การรีเฟรชหน้า และแม้แต่การตัดการเชื่อมต่อโดยสมบูรณ์ นี่คือสิ่งที่เราทำ:
-
การสร้างแยกจากการนำส่ง: ด้วยการแยกการสร้าง LLM ออกจากการเชื่อมต่อไคลเอ็นต์ การสร้างเนื้อหาจะดำเนินต่อไปโดยไม่คำนึงถึงปัญหาของไคลเอ็นต์
-
พื้นที่จัดเก็บข้อมูลถาวรโดยใช้สตรีม Redis: เรากำลังใช้สตรีม Redis เป็นนายหน้าข้อความถาวรเพื่อจัดเก็บแต่ละส่วนของการตอบกลับ LLM ในขณะที่ถูกสร้างขึ้น
-
อัปเดตแบบเรียลไทม์ด้วย Redis Pub/Sub: เราได้สร้างระบบการแจ้งเตือนโดยใช้ Redis Pub/Sub เพื่อแจ้งให้ผู้บริโภคสตรีมทราบเมื่อมีการชิ้นใหม่
-
การเชื่อมต่อใหม่อัตโนมัติ: ลูกค้าสามารถเชื่อมต่อใหม่ได้ตลอดเวลาและรับเนื้อหาทั้งหมดโดยอัตโนมัติ รับประกันว่าไม่มีข้อมูลซ้ำหรือขาดหายไป ซึ่งรวมถึงเนื้อหาที่สร้างขึ้นระหว่างการตัดการเชื่อมต่อ
-
การจัดการเซสชัน: เราสร้างระบบเซสชันที่อนุญาตให้ผู้ใช้ดูสตรีมบนอุปกรณ์หลายเครื่องพร้อมกันได้
สรุปคือ ขณะนี้เรากำลังมอบประสบการณ์ผู้ใช้ (UX) ที่ยอดเยี่ยมให้กับผู้ใช้ของเรา ฉันแนะนำแนวทางนี้จริงๆ โดยเฉพาะอย่างยิ่งหากคุณกำลังสร้างบริการแชท LLM
ไชโยสำหรับการอ่าน! หากคุณมีข้อเสนอแนะหรือต้องการเป็นผู้เขียนรับเชิญใน Upstash โปรดติดต่อที่ josh@upstash.com 🙌
