
แอปพลิเคชันซอฟต์แวร์จะมีคุณค่าก็ต่อเมื่อสามารถตอบสนองความต้องการของลูกค้าได้เท่านั้น เมื่อเราพิจารณาความต้องการของลูกค้า ความต้องการแรกที่เราพบคือความเร็วของแอปพลิเคชันและความน่าเชื่อถือของข้อมูล อย่างไรก็ตาม เมื่อแอปพลิเคชันเติบโตและขยายไปทั่วโลก ฐานข้อมูล SQL มักจะกลายเป็นคอขวดด้านประสิทธิภาพเนื่องจากปริมาณการสืบค้นที่เพิ่มขึ้น เวลาแฝงที่สูงขึ้น และฐานผู้ใช้ที่กระจายตามพื้นที่ทางภูมิศาสตร์
เพื่อแก้ไขปัญหาเหล่านี้เมื่อแอปพลิเคชันเติบโตขึ้น การแคชเป็นหนึ่งในวิธีแก้ปัญหาแรกในการลดภาระในฐานข้อมูลหลักสำหรับการสืบค้นซ้ำ ๆ และลดเวลาแฝงเมื่อผู้ใช้ส่งการสืบค้น เมื่อเราพูดถึงแคช เครื่องมือเดียวกันนี้ก็เข้ามาในใจเราแต่ละคนใช่ไหม ใช่แล้ว นั่นคือเรดิส Redis เป็นเครื่องมือที่สมบูรณ์แบบสำหรับการแคชข้อมูลเพื่อลดภาระและทำให้แอปพลิเคชันเร็วขึ้น Upstash ยังมีการจำลอง Redis ที่กระจายทั่วโลก ซึ่งจะทำให้แอปพลิเคชันเร็วกว่าแคชปกติมาก
ในบล็อกนี้ เราจะสำรวจข้อดีทางเทคนิคของการผสานรวม Global Redis เข้ากับฐานข้อมูล SQL อภิปรายเกี่ยวกับผลกระทบที่มีต่อเวลาแฝงและความสามารถในการปรับขนาด และให้ตัวอย่างการใช้งานจริงสำหรับการใช้ Global Redis กับ PostgreSQL และ MySQL
ประโยชน์ของการแคช
เรามาตรวจสอบกันก่อนว่าทำไมเราจึงควรใช้แคช
การแคชมีประโยชน์หลักสองประการที่ฉันอยากจะพูดถึงในบล็อกนี้:การลดภาระฐานข้อมูลและลดเวลาแฝงให้กับผู้ใช้
การลดภาระฐานข้อมูล
ฐานข้อมูล SQL เก่งในการจัดการข้อมูลที่มีโครงสร้างและการสืบค้นที่ซับซ้อน แต่ภายใต้ภาระงานหนัก ฐานข้อมูลเหล่านี้อาจกลายเป็นคอขวดได้ การสืบค้นข้อมูลเดียวกันซ้ำๆ ในปริมาณมาก เช่น รายละเอียดผลิตภัณฑ์ โปรไฟล์ผู้ใช้ หรือการตั้งค่าที่เข้าถึงบ่อย จะใช้ทรัพยากร CPU และ I/O จำนวนมาก ด้วยการแคชผลลัพธ์เหล่านี้ จำนวนการสืบค้นที่เข้าสู่ฐานข้อมูลจะลดลงอย่างมาก ช่วยให้ฐานข้อมูลมุ่งเน้นไปที่งานที่สำคัญมากขึ้น เช่น การประมวลผลธุรกรรมและการอัปเดต
ตัวอย่างเช่น:
- ไม่มีแคช:คุณลักษณะยอดนิยมบนเว็บไซต์สร้างการสืบค้นฐานข้อมูลที่เหมือนกันหลายล้านรายการทุกวัน ส่งผลให้ประสิทธิภาพการทำงานอื่นช้าลง
- ด้วยการแคช:ผลลัพธ์การสืบค้นที่เข้าถึงบ่อยจะถูกจัดเก็บไว้ในแคชความเร็วสูง เช่น Redis ซึ่งช่วยลดอัตราการสืบค้นฐานข้อมูลได้มากกว่า 90%
การลดความหน่วง
การลดภาระของฐานข้อมูลนั้นเพื่อสุขภาพของระบบเพื่อให้มั่นใจในความน่าเชื่อถือของข้อมูล การแคชยังช่วยปรับปรุงเวลาที่ผู้ใช้ร้องขอและสืบค้น
เมื่อแอปพลิเคชันค้นหาฐานข้อมูลเดียวกันซ้ำๆ การดึงข้อมูลจะใช้เวลานานเสมอ โดยเฉพาะอย่างยิ่งถ้าแบบสอบถามเหล่านี้สร้างภาระงานขนาดใหญ่บนฐานข้อมูล ความล่าช้าเหล่านี้ทั้งหมดอาจเพิ่มขึ้นอีก นี่เป็นปัญหาอย่างยิ่งสำหรับแอปพลิเคชันที่ต้องการการเข้าถึงข้อมูลแบบเรียลไทม์หรือการจัดการปริมาณการสืบค้นที่สูง ซึ่งแม้แต่ความล่าช้าเล็กน้อยก็อาจส่งผลกระทบต่อประสิทธิภาพได้อย่างมาก
การแคชช่วยแก้ปัญหานี้ด้วยการจัดเก็บข้อมูลที่เข้าถึงบ่อยไว้ในหน่วยความจำ ซึ่งสามารถดึงข้อมูลได้เร็วกว่าการสืบค้นฐานข้อมูลมาก ด้วยการลดการพึ่งพาการสืบค้นฐานข้อมูลสำหรับการร้องขอซ้ำ ๆ การแคชจะลดการเดินทางของเครือข่ายให้เหลือน้อยที่สุด และหลีกเลี่ยงค่าใช้จ่ายในการคำนวณในการดำเนินการสืบค้นที่ซับซ้อน ผลที่ได้คือ เวลาตอบสนองได้รับการปรับปรุงอย่างมาก ทำให้แอปพลิเคชันสามารถส่งมอบประสิทธิภาพที่รวดเร็วและสม่ำเสมอยิ่งขึ้น แม้ภายใต้ภาระงานหนักหรือในสภาพแวดล้อมแบบกระจาย
กลยุทธ์การแคชทั่วไป
สิ่งสำคัญคือต้องเข้าใจกลยุทธ์การแคชหลักสองกลยุทธ์ที่ใช้ในการเพิ่มประสิทธิภาพแอปพลิเคชัน:ยกเว้นแคช และ การเขียนผ่าน . แต่ละแนวทางมีกรณีการใช้งานและข้อดีข้อเสีย ขึ้นอยู่กับข้อกำหนดของแอปพลิเคชัน
ยกเว้นแคช เป็นเทคนิคการแคชที่พบบ่อยที่สุด ในเทคนิคนี้ แอปพลิเคชันจะตรวจสอบแคชเพื่อดูข้อมูลก่อน หากข้อมูลไม่อยู่ในแคช (แคชพลาด) จะดึงข้อมูลจากฐานข้อมูลและเขียนลงในแคชเพื่อใช้ในอนาคต
นี่คือแผนภาพง่ายๆ ที่แสดงวิธีการทำงานของการยกเว้นแคช ซึ่งคุณทุกคนอาจเคยเห็นมาแล้วจากที่ใดที่หนึ่งก่อนที่จะมาที่บล็อกนี้

ข้อดีของการแคชนี้คือขนาดแคชได้รับการปรับให้เหมาะสม และข้อมูลแคชจะถูกโหลดใหม่เมื่อผู้ใช้ต้องการ ในทางกลับกัน ข้อเสียคือข้อมูลจะไม่สามารถใช้ได้หลังจากที่แคชถูกล้างเมื่อ TTL หมดลง ในเวลานั้น แคชจะถูกโหลดซ้ำเมื่อผู้ใช้ร้องขอข้อมูลนั้น ในกรณีนี้ ผู้ใช้รายนั้นจะต้องรอให้แบบสอบถามเสร็จสิ้น แต่แน่นอนว่าคำขอถัดไปจะสามารถรับข้อมูลจากแคชได้อีกครั้ง
ใน การเขียนผ่าน กลยุทธ์การดำเนินการเขียนทุกครั้งไปยังฐานข้อมูลจะถูกเขียนลงในแคชทันทีเช่นกัน เพื่อให้แน่ใจว่าแคชจะอัปเดตข้อมูลล่าสุดจากฐานข้อมูลอยู่เสมอ
นี่คือไดอะแกรมอย่างง่ายของการแคชการเขียนผ่าน:

กลยุทธ์นี้รับประกันความสอดคล้องของข้อมูลระหว่างแคชและฐานข้อมูล และไม่มีคำขอใดพบกับเวลาแฝงที่สูงกว่า เนื่องจากข้อมูลจะพร้อมใช้งานแล้วโดยไม่ต้องรอคำขอจากผู้ใช้ อย่างไรก็ตาม ข้อเสียคือแคชมีข้อมูลทั้งหมด แม้ว่าจะไม่จำเป็นก็ตาม นอกจากนั้น การดำเนินการเขียนทุกครั้งจะได้รับเวลาแฝงเนื่องจากข้อมูลจะถูกเขียนไปยังแคชเช่นกัน
โกลบอล เรดดิสคืออะไร? ประโยชน์ของ Global Redis
ตอนนี้เรามาดูวิธีปรับปรุงประสิทธิภาพของฐานข้อมูล SQL กันดีกว่า
แหล่งที่มาของเวลาแฝงอีกประการหนึ่งคือตำแหน่งของฐานข้อมูล ในกรณีส่วนใหญ่ ฐานข้อมูลหลักจะอยู่ในภูมิภาคเฉพาะ อย่างไรก็ตาม ข้อมูลควรสามารถเข้าถึงได้ในตำแหน่งที่ใกล้ที่สุดเพื่อให้เราสามารถลดความล่าช้าที่เกิดจากระยะทางไปยังที่เก็บข้อมูลได้
ปัญหานี้ป้องกันได้โดยใช้ Redis ที่กระจายทั่วโลกซึ่งจัดทำโดย Upstash
Global Redis เป็นโซลูชันแคชแบบกระจายที่จำลองข้อมูลในตำแหน่งทางภูมิศาสตร์หลายแห่ง เพื่อให้มั่นใจว่ามีการเข้าถึงที่มีความหน่วงต่ำสำหรับแอปพลิเคชันที่กระจายทั่วโลก
มาดูวิธีสร้าง Redis ทั่วโลกกันอย่างรวดเร็ว ขั้นแรก เข้าสู่ระบบคอนโซล Upstash
หลังจากเข้าสู่ระบบแล้ว เราสามารถสร้างฐานข้อมูล Redis ได้ที่นี่ Upstash มีหลายตำแหน่งเพื่อค้นหาแบบจำลองการอ่าน
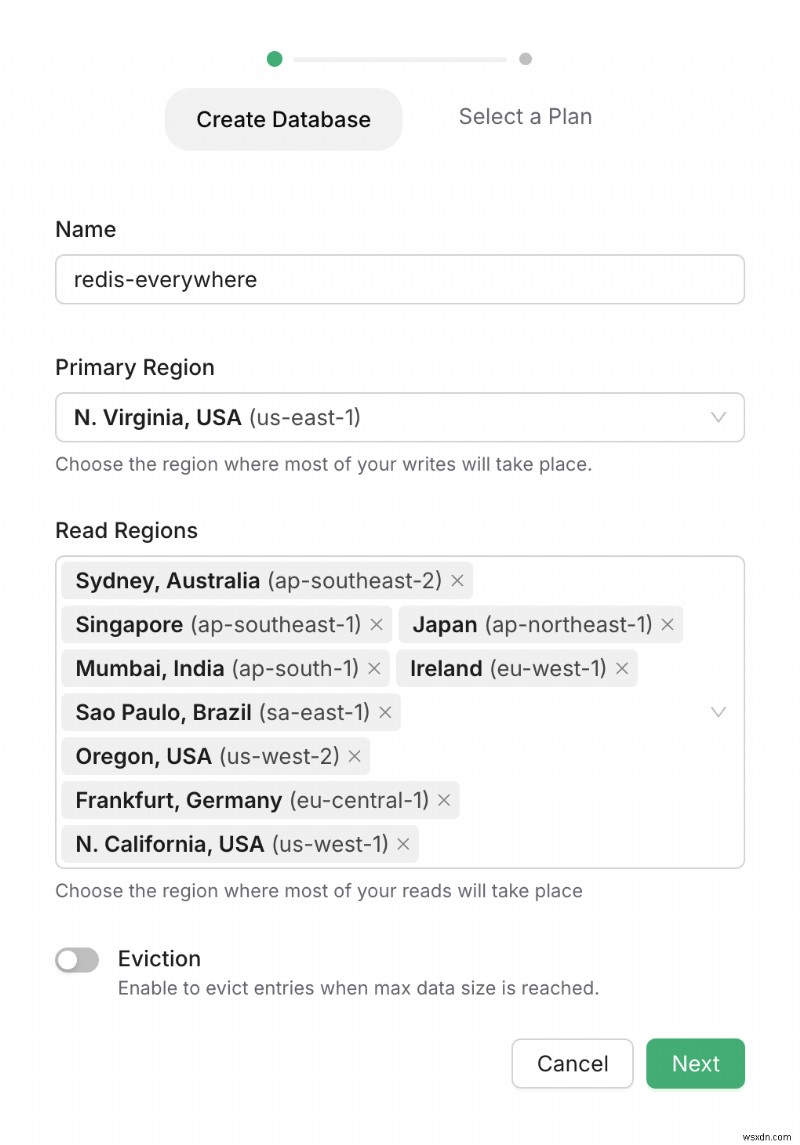
เมื่อเลือกตำแหน่งที่อ่านแล้ว คุณสามารถเลือกแผนและสร้างฐานข้อมูล Redis ของคุณได้ในที่สุด เพียงเท่านี้!
ในคอนโซล คุณสามารถเพิ่ม/ลบขอบเขตหลังจากสร้างฐานข้อมูลได้เช่นกัน

ฐานข้อมูล Global Redis ส่วนใหญ่จะใช้โดยแอปพลิเคชันที่กระจายทั่วโลกและแอปพลิเคชันที่ทำงานที่ Edge
เวลาแฝงต่ำสำหรับแอปพลิเคชันที่กระจายทั่วโลก
ในระบบที่กระจายทั่วโลก เวลาแฝงมักจะกลายเป็นคอขวดเนื่องจากระยะห่างทางกายภาพระหว่างผู้ใช้กับฐานข้อมูลกลางหรือแคช Global Redis แก้ไขปัญหานี้ด้วยการจำลองข้อมูลข้ามโหนดที่กระจายตามภูมิศาสตร์หลายแห่ง
เมื่อผู้ใช้ร้องขอข้อมูล โหนดแคชที่ใกล้ที่สุดจะทำหน้าที่ตามคำขอ ซึ่งช่วยลดเวลาการเดินทางของเครือข่ายได้อย่างมาก การเข้าถึงแบบท้องถิ่นนี้รับประกันเวลาตอบสนองที่เร็วขึ้นและประสบการณ์ผู้ใช้ที่สอดคล้องกัน โดยไม่คำนึงถึงตำแหน่งของผู้ใช้
สมมติว่าหากผู้ใช้อยู่ในโตเกียว แต่ฐานข้อมูลอยู่ในดับลิน ระยะทางจะทำให้การตอบสนองต่อผู้ใช้ล่าช้า หากมีแบบจำลองการอ่านของ Upstash Redis ในยุโรป คำขอสามารถกำหนดเส้นทางไปยังแบบจำลองการอ่านที่ใกล้ที่สุด ซึ่งเป็นแบบจำลองในยุโรปในกรณีนี้
ข้อมูลเวลาแฝงต่ำสำหรับ Edge Runtimes (เช่น Cloudflare Workers)
Edge Runtimes คือสภาพแวดล้อมที่ออกแบบมาเพื่อรันโค้ดที่ Edge ของเครือข่ายใกล้กับผู้ใช้ปลายทาง รันไทม์ของ Edge กระจายตรรกะของแอปพลิเคชันไปยังสถานที่ตั้ง Edge หลายแห่งทั่วโลก สถาปัตยกรรมนี้ลดระยะห่างทางกายภาพระหว่างผู้ใช้และการดำเนินการตามคำขอของพวกเขา ซึ่งช่วยลดเวลาแฝงและปรับปรุงประสิทธิภาพได้อย่างมาก
แม้ว่ารันไทม์ Edge จะทำให้ผู้ใช้เข้าใกล้การประมวลผลมากขึ้น แต่พวกเขายังคงต้องการเข้าถึงข้อมูลสำหรับการดำเนินการส่วนใหญ่ เช่น การดึงข้อมูลเฉพาะผู้ใช้ โทเค็นเซสชัน หรือการกำหนดค่า หากไม่มีเลเยอร์การแคช แต่ละคำขอยังคงต้องมีการส่งข้อมูลแบบไปกลับไปยังฐานข้อมูลกลาง ซึ่งจะลบผลประโยชน์ด้านเวลาแฝงไปมาก นี่คือจุดที่ Global Redis มีบทบาทสำคัญ เนื่องจากจะจำลองข้อมูลที่ใช้บ่อยไปยัง Edge เพื่อให้แน่ใจว่ามีการเข้าถึงที่มีเวลาแฝงต่ำ
โค้ดตัวอย่าง 1:PostgreSQL พร้อม Node.js
การแคชด้วย Global Redis นั้นสมบูรณ์แบบ ตอนนี้ เราจะเห็นตัวอย่างโค้ดที่ใช้กลยุทธ์การเก็บแคชกับ Upstash Redis และฐานข้อมูล Postgresql
ก่อนอื่นเราควรติดตั้ง SDK ที่เราจะใช้เชื่อมต่อกับที่เก็บข้อมูล
npm install pg upstash/redis
เมื่อเราติดตั้งการขึ้นต่อกันแล้ว เราก็สามารถเชื่อมต่อกับที่เก็บข้อมูล Upstash Redis และ Postgres ได้
const { Redis } = require('@upstash/redis'); // Upstash Redis SDK
const { Client } = require('pg');
const redis = new Redis({
url: <UPSTASH_REDIS_REST_URL>,
token: <UPSTASH_REDIS_REST_TOKEN>,
})
const client = new Client({
user: 'username',
password: 'password',
host: 'host',
port: 'port_number',
database: 'database_name',
});
client.connect();ตอนนี้เรามาเขียนฟังก์ชันในชั้นการเข้าถึงข้อมูลของเรากันดีกว่า ฟังก์ชั่นนี้สามารถแก้ไขได้ตามความต้องการของคุณ
สมมติว่าเราต้องการแสดงข้อมูลผู้ใช้บนเว็บไซต์ของเราตามรหัสผู้ใช้ ในกรณีนี้ เราควรมีฟังก์ชันที่รับ userId เป็นพารามิเตอร์
async function getUserData(userId) {
// Check cache first
const cachedData = await redis.get(userId);
if (cachedData) {
console.log('Cache hit');
return JSON.parse(cachedData);
}
// Fallback to database
console.log('Cache miss');
const query = 'SELECT * FROM users WHERE id = $1';
const { rows } = await client.query(query, [userId]);
await redis.set(userId, JSON.stringify(rows), { EX: 300 }); // Cache for 5 minutes
return rows;
}นี่ไง! ตอนนี้ฟังก์ชันนี้จะตรวจสอบก่อนว่าข้อมูลผู้ใช้มีอยู่ในฐานข้อมูล Redis ที่ใกล้กับภูมิภาคของผู้ร้องขอมากที่สุดหรือไม่ หากไม่มีให้บริการ ระบบจะสอบถามข้อมูลที่ร้องขอจากฐานข้อมูล Postgresql และเขียนข้อมูลที่ส่งคืนไปยังภูมิภาคหลักของ Upstash Redis ข้อมูลที่เขียนไปยังภูมิภาคหลักจะถูกคัดลอกไปยังแบบจำลองการอ่านทั้งหมดโดยอัตโนมัติ
โค้ดตัวอย่าง 2:MYSQL พร้อม Python
ทีนี้มาดูอีกตัวอย่างหนึ่ง ครั้งนี้ เราจะดำเนินการแคชแบบเดียวกัน แต่คราวนี้ฐานข้อมูลหลักจะเป็น MYSQL นอกจากนี้ เราจะเขียนฟังก์ชันนี้ใน Python เพื่อดูว่ามันทำงานอย่างไรในแอปพลิเคชันที่ใช้ Python
ตามปกติ เราจะดาวน์โหลดการขึ้นต่อกันที่เราจะใช้สำหรับการเชื่อมต่อฐานข้อมูลก่อน
pip install upstash-redis upstash-redis
ตอนนี้ เราสามารถเริ่มต้นไคลเอนต์และเชื่อมต่อพวกเขาได้
import upstash_redis
import mysql.connector
import json
# Initialize Upstash Redis client
redis_client = upstash_redis.Redis(
url='<your-upstash-redis-url>',
token='<your-upstash-token>'
)
# Initialize MySQL client
db = mysql.connector.connect(
host="<your-mysql-host>",
user="<your-mysql-user>",
password="<your-mysql-password>",
database="<your-database-name>"
)
cursor = db.cursor(dictionary=True)การเชื่อมต่อพร้อมแล้ว ตอนนี้เราจะใช้ฟังก์ชันที่คล้ายกันที่เราใช้งานในส่วนที่แล้ว
def get_user_data(userId):
# Check the cache for the data
cache_data = redis_client.get(key)
if cache_data:
print("Cache hit")
return json.loads(cache_data)
# If cache miss, query the MySQL database
print("Cache miss")
cursor.execute("SELECT * FROM users WHERE key = %s", (userId))
result = cursor.fetchone()
if result:
# Store the data in the cache with a TTL of 1 hour
redis_client.set(key, json.dumps(result), ex=3600)
return resultบทสรุป
ด้วยการรวม Global Redis เข้ากับสถาปัตยกรรมของคุณ คุณจะได้รับประสิทธิภาพที่เพิ่มขึ้นอย่างมากสำหรับแอปพลิเคชันที่ใช้ SQL โดยเฉพาะในสภาพแวดล้อมแบบกระจายทั่วโลก ด้วยการเข้าถึงที่มีเวลาแฝงต่ำ โหลดฐานข้อมูลที่ลดลง และความเข้ากันได้กับรันไทม์ Edge ทำให้ Global Redis สามารถจัดการกับความท้าทายด้านประสิทธิภาพของแอปพลิเคชันด้วยฐานข้อมูล SQL ได้
ในบล็อกโพสต์นี้ เราได้กล่าวถึงคุณประโยชน์ของการแคชด้วย Redis ทั่วโลก และตรวจสอบตัวอย่างบางส่วน นี่เป็นเพียงตัวอย่างพื้นฐานที่สามารถขยายเพิ่มเติมได้ตามความต้องการของคุณ
ฉันหวังว่าบล็อกนี้จะเป็นจุดเริ่มต้นที่ดีสำหรับคุณในการเริ่มใช้ประโยชน์จากพลังของ Redis ระดับโลก
