
มีอัลกอริธึมการทำคลัสเตอร์หลายประเภทในแมชชีนเลิร์นนิง อัลกอริทึมเหล่านี้สามารถนำมาใช้ใน Python ในบทความนี้ ให้เรามาอภิปรายและใช้อัลกอริธึม 'Mean−Shift' โดยใช้ Python เป็นอัลกอริทึมการจัดกลุ่มที่ใช้เป็นวิธีการเรียนรู้แบบไม่มีผู้ดูแล
ในอัลกอริธึมนี้ ไม่มีการตั้งสมมติฐานใดๆ นี่หมายความว่ามันเป็นอัลกอริธึมที่ไม่มีพารามิเตอร์ อัลกอริทึมนี้จะกำหนดจุดข้อมูลให้กับบางคลัสเตอร์ซ้ำๆ ซึ่งทำได้โดยการย้ายจุดข้อมูลเหล่านี้ไปยังจุดข้อมูลที่มีความหนาแน่นสูงสุด
จุดข้อมูลที่มีความหนาแน่นสูงนี้เรียกว่าเซนทรอยด์ของคลัสเตอร์ ความแตกต่างระหว่างอัลกอริธึมการเปลี่ยนค่าเฉลี่ยและ K หมายถึงการจัดกลุ่มคือ ในอดีต (K–หมายถึง) จำเป็นต้องระบุจำนวนคลัสเตอร์ล่วงหน้า
เนื่องจากจำนวนคลัสเตอร์ถูกพบโดยใช้ K หมายถึงอัลกอริทึมตามข้อมูลที่มีอยู่
ให้เราเข้าใจขั้นตอนในอัลกอริทึม Mean-shift -
-
จุดข้อมูลถูกกำหนดให้กับคลัสเตอร์ของตัวเอง
-
จากนั้นจึงกำหนดเซนทรอยด์ของคลัสเตอร์เหล่านี้
-
ตำแหน่งของเซนทรอยด์เหล่านี้มีการปรับปรุงซ้ำๆ
-
ถัดไป กระบวนการจะย้ายไปยังบริเวณที่มีความหนาแน่นสูงขึ้น
-
เมื่อเซนทรอยด์ไปถึงตำแหน่งที่ไม่สามารถเคลื่อนที่ต่อไปได้ กระบวนการจะหยุด
ให้เราเข้าใจว่ามันสามารถนำมาใช้ใน Python ได้อย่างไรโดยใช้ scikit−learn −
ตัวอย่าง
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
from sklearn.datasets.samples_generator import make_blobs
centers = [[3,3,1],[4,5,5],[11,10,10]]
X, _ = make_blobs(n_samples = 950, centers = centers, cluster_std = 0.89)
plt.title("Implementation of Mean-Shift algorithm")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
plt.scatter(X[:,0],X[:,1])
plt.show()
ms = MeanShift()
ms.fit(X)
labels = ms.labels_
clusterCent = ms.cluster_centers_
print(clusterCent)
numCluster = len(np.unique(labels))
print("Estimated clusters:", numCluster)
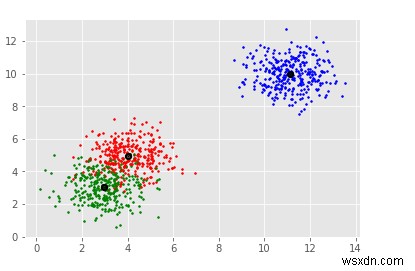
colors = 10*['r.','g.','b.','c.','k.','y.','m.']
for i in range(len(X)):
plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 3)
plt.scatter(clusterCent[:,0],clusterCent[:,1],
marker=".",color='k', s=20, linewidths = 5, zorder=10)
plt.show() ผลลัพธ์
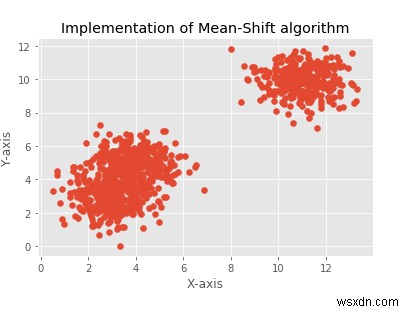
[[ 3.05250924 3.03734994 1.06159541] [ 3.92913017 4.99956874 4.86668482] [10.99127523 10.02361122 10.00084718]] Estimated clusters: 3
คำอธิบาย
-
แพ็คเกจที่จำเป็นจะถูกนำเข้าและกำหนดนามแฝงเพื่อให้ใช้งานง่าย
-
'ggplot' ถูกกำหนดให้กับฟังก์ชัน 'use' ที่มีอยู่ในคลาส 'style'
-
ฟังก์ชัน "make_blobs" ใช้เพื่อสร้างคลัสเตอร์ของข้อมูล
-
ฟังก์ชัน set_xlabel, set_ylabel และ set_title ใช้เพื่อจัดเตรียมป้ายกำกับสำหรับแกน "X", แกน "Y" และชื่อ
-
มีการเรียกฟังก์ชัน "MeanShift" และกำหนดให้กับตัวแปร
-
ข้อมูลเหมาะสมกับโมเดล
-
มีการกำหนดป้ายกำกับและจำนวนคลัสเตอร์
-
ข้อมูลนี้ถูกพล็อต และพล็อตแบบกระจายสำหรับข้อมูลที่พอดีกับโมเดลก็จะแสดงขึ้นด้วย
-
จะแสดงบนคอนโซลโดยใช้ฟังก์ชัน "แสดง"
