สถิติเป็นพื้นฐานในการเรียนรู้ ml และ AI เนื่องจาก Python เป็นภาษาที่เลือกใช้สำหรับเทคโนโลยีเหล่านี้ เราจะมาดูวิธีการเขียนโปรแกรม Python ที่รวมการวิเคราะห์ทางสถิติเข้าด้วยกัน ในบทความนี้ เราจะมาดูวิธีการสร้างกราฟและแผนภูมิโดยใช้โมดูล Python ต่างๆ แผนภูมิที่หลากหลายนี้ช่วยให้เราวิเคราะห์ข้อมูลได้อย่างรวดเร็วและได้ข้อมูลภายในเป็นการสรุปแบบกราฟิก
การเตรียมข้อมูล
เรานำชุดข้อมูลที่มีข้อมูลเกี่ยวกับเมล็ดพันธุ์ต่างๆ ชุดข้อมูลนี้มีให้ที่ kaggle ในลิงค์ที่แสดงในโปรแกรมด้านล่าง มีแปดคอลัมน์ที่จะใช้ในการจัดแผนภูมิประเภทต่างๆ เพื่อเปรียบเทียบคุณสมบัติของเมล็ดพันธุ์ต่างๆ โปรแกรมด้านล่างโหลดชุดข้อมูลจากสภาพแวดล้อมภายในเครื่องและแสดงตัวอย่างแถว
ตัวอย่าง
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
datainput = pd.read_csv('E:\\seeds.csv')
#https://www.kaggle.com/jmcaro/wheat-seedsuci
print(datainput) ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -
Area Perimeter Compactness ... Asymmetry.Coeff Kernel.Groove Type 0 15.26 14.84 0.8710 ... 2.221 5.220 1 1 14.88 14.57 0.8811 ... 1.018 4.956 1 2 14.29 14.09 0.9050 ... 2.699 4.825 1 3 13.84 13.94 0.8955 ... 2.259 4.805 1 4 16.14 14.99 0.9034 ... 1.355 5.175 1 .. ... ... ... ... ... ... ... 194 12.19 13.20 0.8783 ... 3.631 4.870 3 195 11.23 12.88 0.8511 ... 4.325 5.003 3 196 13.20 13.66 0.8883 ... 8.315 5.056 3 197 11.84 13.21 0.8521 ... 3.598 5.044 3 198 12.30 13.34 0.8684 ... 5.637 5.063 3 [199 rows x 8 columns]
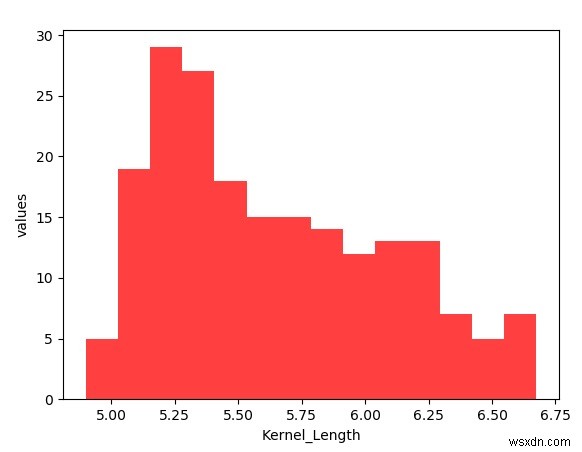
การสร้างฮิสโตแกรม
ในการสร้างฮิสโตแกรม เราลบแถวส่วนหัวออกจากไฟล์ csv และอ่านไฟล์เป็นอาร์เรย์แบบ numpy จากนั้นเราใช้โมดูล genfromtxt เพื่ออ่านไฟล์ ความยาวของเคอร์เนลที่ยื่นจะอยู่ที่ดัชนีคอลัมน์ 3 ในอาร์เรย์ สุดท้าย เราใช้ matplotlib เพื่อพล็อตฮิสโตแกรมโดยใช้ชุดข้อมูลที่สร้างโดย numpy และใช้ป้ายกำกับที่จำเป็นด้วย
ตัวอย่าง
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_Length = seed_data[:, [3]]
x = len(Kernel_Length)
y = np.sqrt(x)
y = int(y)
z = plot.hist(Kernel_Length, bins=y, color='#FF4040')
z = plot.xlabel('Kernel_Length')
z = plot.ylabel('values')
plot.show() ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -
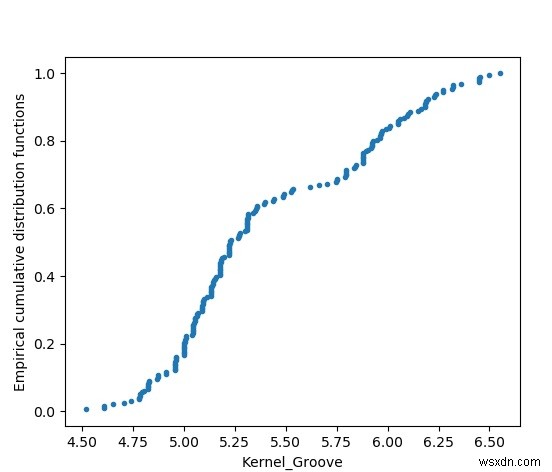
ฟังก์ชันการแจกแจงสะสมเชิงประจักษ์
แผนภูมินี้แสดงพล็อตของขนาดร่องเคอร์เนลที่กระจายไปทั่วชุดข้อมูล เรียงจากค่าน้อยไปมาก และแสดงเป็นการแจกแจง
ตัวอย่าง
import matplotlib.pyplot as plot
import numpy as np
from numpy import genfromtxt
seed_data = genfromtxt('E:\\seeds.csv', delimiter=',')
Kernel_groove = seed_data[:, 6]
def ECDF(seed_data):#Empirical cumulative distribution functions
i = len(seed_data)
m = np.sort(seed_data)
n = np.arange(1, i + 1) / i
return m, n
m, n = ECDF(Kernel_groove)
plot.plot(m, n, marker='.', linestyle='none')
plot.xlabel('Kernel_Groove')
plot.ylabel('Empirical cumulative distribution functions')
plot.show() ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -
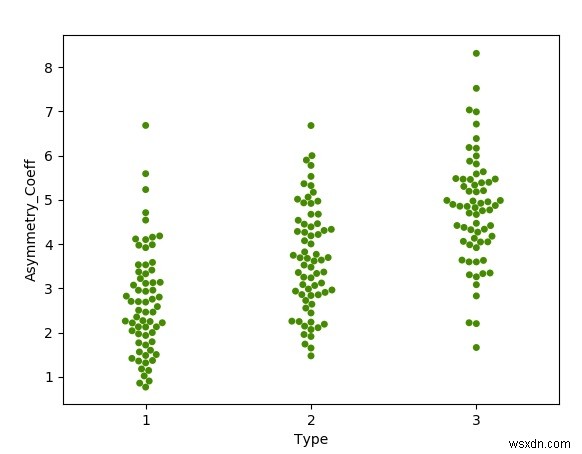
แปลงปลูกผึ้ง
พล็อต beeswarm แสดงขนาดของกลุ่มจุดข้อมูลโดยการจัดกลุ่มจุดข้อมูลแต่ละจุดด้วยสายตา เราใช้ห้องสมุด seaborn เพื่อสร้างกราฟนี้ เราใช้คอลัมน์ Type จากชุดข้อมูลเพื่อจัดกลุ่มเมล็ดพันธุ์ที่คล้ายกันเข้าด้วยกัน
ตัวอย่าง
import pandas as pd
import matplotlib.pyplot as plot
import seaborn as sns
datainput = pd.read_csv('E:\\seeds.csv')
sns.swarmplot(x='Type', y='Asymmetry.Coeff',data=datainput, color='#458B00')#bee swarm plot
plot.xlabel('Type')
plot.ylabel('Asymmetry_Coeff')
plot.show() ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -