สำมะโนเป็นเรื่องเกี่ยวกับการบันทึกข้อมูลเกี่ยวกับประชากรที่กำหนดอย่างเป็นระบบ ข้อมูลที่รวบรวมได้รวมถึงหมวดหมู่ต่างๆ ของข้อมูล เช่น รายละเอียดด้านประชากร เศรษฐกิจ ที่อยู่อาศัย ฯลฯ ซึ่งท้ายที่สุดแล้วจะช่วยให้รัฐบาลเข้าใจสถานการณ์ปัจจุบันและการวางแผนสำหรับอนาคต ในบทความนี้ เราจะมาดูวิธีใช้ประโยชน์จาก Python เพื่อวิเคราะห์ข้อมูลสำมะโนประชากรของอินเดีย เราจะพิจารณาด้านประชากรและเศรษฐกิจต่างๆ จากนั้นวางแผนค่าใช้จ่ายซึ่งจะฉายการวิเคราะห์ในลักษณะกราฟิก ที่มาที่รวบรวมมาจากเก๊กฮวย มันอยู่ที่นี่
การจัดระเบียบข้อมูล
ในโปรแกรมด้านล่าง อันดับแรก เราได้รับข้อมูลโดยใช้โปรแกรม python แบบสั้น มันแค่โหลดข้อมูลไปยังดาต้าเฟรมของแพนด้าเพื่อการวิเคราะห์เพิ่มเติม ผลลัพธ์จะแสดงบางฟิลด์เพื่อให้แสดงได้ง่ายขึ้น
ตัวอย่าง
import pandas as pd
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
#https://www.kaggle.com/danofer/india-census#india-districts-census-2011.csv
print(datainput) ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -
District code ... Total_Power_Parity 0 1 ... 1119 1 2 ... 1066 2 3 ... 242 3 4 ... 214 4 5 ... 629 .. ... ... ... 635 636 ... 10027 636 637 ... 4890 637 638 ... 3151 638 639 ... 3151 639 640 ... 5782 [640 rows x 118 columns]
การวิเคราะห์ความคล้ายคลึงกันระหว่างสองรัฐ
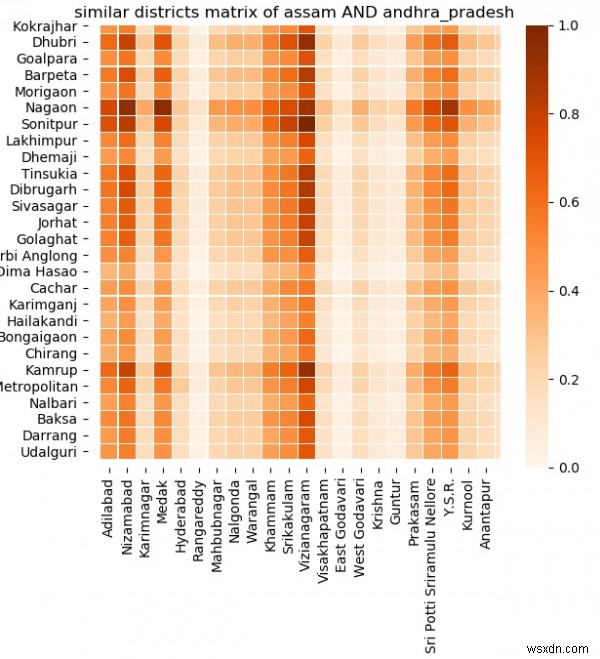
ตอนนี้เราได้รวบรวมข้อมูลแล้ว เราสามารถดำเนินการวิเคราะห์ความคล้ายคลึงกันในด้านต่างๆ ระหว่างสองรัฐได้ ความคล้ายคลึงกันอาจอยู่บนพื้นฐานของกลุ่มอายุ ความเป็นเจ้าของคอมพิวเตอร์ ความพร้อมของที่อยู่อาศัย ระดับการศึกษา ฯลฯ ในตัวอย่างด้านล่าง เราจะพิจารณาสองรัฐที่ชื่ออัสสัมและรัฐอานธรประเทศ จากนั้นเราเปรียบเทียบทั้งสองสถานะโดยใช้ similarity_matrix ฟิลด์ข้อมูลทั้งหมดจะถูกเปรียบเทียบสำหรับแต่ละเขตที่เป็นไปได้จากทั้งสองรัฐ แผนที่ความหนาแน่นที่ได้จะระบุว่าทั้งสองมีความเกี่ยวข้องกันมากเพียงใด ยิ่งเฉดสีเข้มยิ่งสัมพันธ์กัน
ตัวอย่าง
import pandas as pd
import matplotlib.pyplot as plot
from matplotlib.colors import Normalize
import seaborn as sns
import math
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
df_ASSAM = datainput.loc[datainput['State name'] == 'ASSAM']
df_ANDHRA_PRADESH = datainput.loc[datainput['State name'] == 'ANDHRA PRADESH']
def segment(x1, x2):
# Set indices for both the data frames
x1.set_index('District code')
x2.set_index('District code')
# The similarity matrix of size len(x1) X len(x2)
similarity_matrix = []
# Iterate through rows of df1
for r1 in x1.iterrows():
# Create list to hold similarity score of row1 with other rows of x2
y = []
# Iterate through rows of x2
for r2 in x2.iterrows():
# Calculate sum of squared differences
n = 0
for c in list(datainput)[3:]:
maximum_c = max(datainput[c])
minimum_c = min(datainput[c])
n += pow((r1[1][c] - r2[1][c]) / (maximum_c - minimum_c), 2)
# Take sqrt and inverse the result
y.append(1 / math.sqrt(n))
# Append similarity scores
similarity_matrix.append(y)
p = 0
q = 0
r = 0
for m in range(len(similarity_matrix)):
for n in range(len(similarity_matrix[m])):
if (similarity_matrix[m][n] > p):
p = similarity_matrix[m][n]
q = m
r = n
print("%s from ASSAM and %s from ANDHRA PRADESH are most similar" % (x1['District name'].iloc[q],x2['District name'].iloc[r]))
return similarity_matrix
m = segment(df_ASSAM, df_ANDHRA_PRADESH)
normalization=Normalize()
s = plot.axes()
sns.heatmap(normalization(m), xticklabels=df_ANDHRA_PRADESH['District name'],yticklabels=df_ASSAM['District name'],linewidths=0.05,cmap='Oranges').set_title("similar districts matrix of assam AND andhra_pradesh")
plot.rcParams['figure.figsize'] = (20,20)
plot.show() ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -
การเปรียบเทียบพารามิเตอร์เฉพาะ
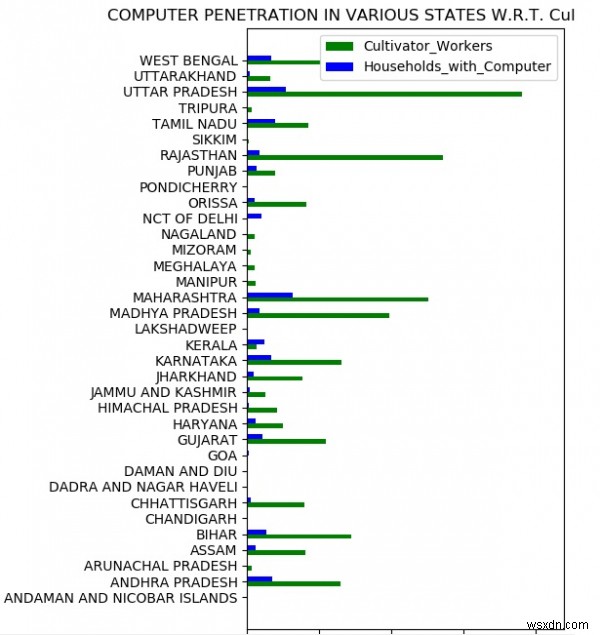
ตอนนี้ เราสามารถเปรียบเทียบสถานที่ต่างๆ กับพารามิเตอร์เฉพาะได้ ในตัวอย่างด้านล่าง เราเปรียบเทียบความพร้อมใช้งานของคอมพิวเตอร์ในครัวเรือนที่มีให้สำหรับพนักงานเพาะปลูก เราสร้างกราฟที่แสดงการเปรียบเทียบระหว่างพารามิเตอร์ทั้งสองนี้สำหรับแต่ละสถานะ
ตัวอย่าง
import pandas as pd
import matplotlib.pyplot as plot
from numpy import *
datainput = pd.read_csv('E:\\india-districts-census-2011.csv')
z = datainput.groupby(by="State name")
m = []
w = []
for k, g in z:
t = 0
t1 = 0
for r in g.iterrows():
t += r[1][36]
t1 += r[1][21]
m.append((k, t))
w.append((k, t1))
mp= pd.DataFrame({
'state': [x[0] for x in m],
'Households_with_Computer': [x[1] for x in m],
'Cultivator_Workers': [x[1] for x in w]})
d = arange(35)
wi = 0.3
fig, f = plot.subplots()
plot.xlim(0, 22000000)
r1 = f.barh(d, mp['Cultivator_Workers'], wi, color='g', align='center')
r2 = f.barh(d + wi, mp['Households_with_Computer'], wi, color='b', align='center')
f.set_xlabel('Population')
f.set_title('COMPUTER PENETRATION IN VARIOUS STATES W.R.T. Cultivator_Workers')
f.set_yticks(d + wi / 2)
f.set_yticklabels((x for x in mp['state']))
f.legend((r1[0], r2[0]), ('Cultivator_Workers', 'Households_with_Computer'))
plot.rcParams.update({'font.size': 15})
plot.rcParams['figure.figsize'] = (15, 15)
plot.show() ผลลัพธ์
การเรียกใช้โค้ดข้างต้นทำให้เราได้ผลลัพธ์ดังต่อไปนี้ -