
ในบทความนี้ เราจะเรียนรู้เกี่ยวกับเทคนิคการขูดเว็บโดยใช้โมดูล lxml ที่มีอยู่ใน Python
การขูดเว็บคืออะไร
การขูดเว็บจะใช้เพื่อรับ/รับข้อมูลจากเว็บไซต์โดยใช้โปรแกรมรวบรวมข้อมูล/สแกนเนอร์ การทำลายเว็บมีประโยชน์ในการดึงข้อมูลจากหน้าเว็บที่ไม่มีฟังก์ชันการทำงานของ API ใน python การขูดเว็บสามารถทำได้โดยใช้โมดูลต่างๆ เช่น Beautiful Soup, Scrappy &lxml
ที่นี่เราจะพูดถึงการขูดเว็บโดยใช้โมดูล lxml
เพื่อที่ เราต้อง ติดตั้ง lxml ก่อน
พิมพ์เทอร์มินัลหรือพรอมต์คำสั่ง -
>>> pip install lxml
ที่นี่ใช้ xpath เพื่อเข้าถึงข้อมูล
ในบทความนี้ เราจะดึงข้อมูลจากเว็บไซต์ที่เรียกว่า Steam ซึ่งมีข้อมูลเกี่ยวกับเกมต่างๆ
https://store.steampowered.com/genre/Free%20to%20Play/
ในหน้านี้ เราจะพยายามดึงข้อมูลจากส่วนการออกใหม่ยอดนิยม ที่นี่เราจะแยกชื่อ ราคา แท็กที่เกี่ยวข้อง &แพลตฟอร์มเป้าหมาย
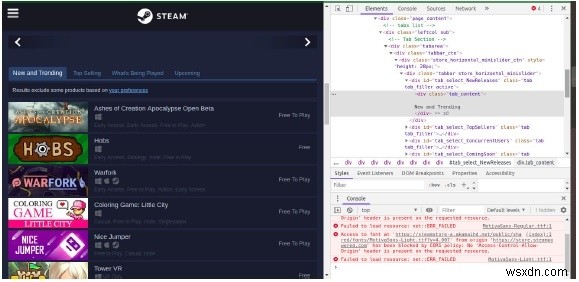
บนหน้าเว็บ ให้ดูโค้ด Html ของแท็บรุ่นใหม่โดยใช้คุณลักษณะตรวจสอบองค์ประกอบใน Chrome ที่นี่เราจะได้รู้ว่าแท็กใดที่จัดเก็บข้อมูลที่จำเป็น
ที่นี่ในเว็บไซต์นี้ ทุกองค์ประกอบรายการถูกห่อหุ้มในแท็ก div id=tab_content ซึ่งถูกห่อหุ้มเพิ่มเติมใน
a div tag id=tab_select_newreleases
มาดูการใช้งานกัน
