
การขูดเว็บไม่เพียงแต่สร้างความตื่นเต้นให้กับผู้ที่ชื่นชอบวิทยาศาสตร์ข้อมูลเท่านั้น แต่ยังรวมถึงนักเรียนหรือผู้เรียนที่ต้องการเจาะลึกลงไปในเว็บไซต์ด้วย Python มีไลบรารี่เว็บสแครปมากมายรวมถึง
-
ขี้เหนียว
-
Urllib
-
สวยซุป
-
ซีลีเนียม
-
คำขอหลาม
-
LXML
เราจะพูดถึงไลบรารี lxml ของ python เพื่อขูดข้อมูลจากหน้าเว็บ ซึ่งสร้างขึ้นจากไลบรารีการแยกวิเคราะห์ XML ของ libxml2 ที่เขียนด้วยภาษา C ซึ่งช่วยให้ทำงานได้เร็วกว่า Beautiful Soup แต่ยังติดตั้งบนคอมพิวเตอร์บางเครื่องได้ยากขึ้น โดยเฉพาะ Windows .
การติดตั้งและการนำเข้า lxml
lxml สามารถติดตั้งได้จากบรรทัดคำสั่งโดยใช้ pip
pip install lxml
หรือ
conda install -c anaconda lxml
เมื่อการติดตั้ง lxml เสร็จสมบูรณ์ ให้นำเข้าโมดูล html ซึ่งแยกวิเคราะห์ HTML จาก lxml
>>> from lxml import html
ดึงซอร์สโค้ดของหน้าที่คุณต้องการขูด - เรามีสองทางเลือกว่าเราสามารถใช้ไลบรารีคำขอ python หรือ urllib และใช้เพื่อสร้างวัตถุองค์ประกอบ lxml HTML ที่มี HTML ทั้งหมดของหน้า เราจะใช้ไลบรารีคำขอเพื่อดาวน์โหลดเนื้อหา HTML ของหน้า
ในการติดตั้งคำขอหลาม เพียงเรียกใช้คำสั่งง่ายๆ ในเทอร์มินัลที่คุณเลือก −
$ pipenv install requests
ขูดข้อมูลจาก Yahoo Finance
สมมติว่าเราต้องการขูดข้อมูลหุ้น/ทุนจาก google.finance หรือ yahoo.finance ด้านล่างนี้คือภาพหน้าจอของบริษัท Microsoft จาก Yahoo Finance
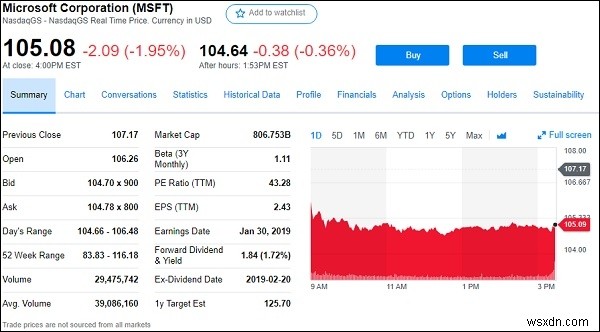
จากข้างบนนี้ (https://finance.yahoo.com/quote/msft ) เราจะแยกฟิลด์ทั้งหมดของหุ้นที่ปรากฏด้านบนเช่น
-
ก่อนหน้า ปิด, เปิด, เสนอราคา, ถาม, ช่วงของวัน, ช่วง 52 สัปดาห์, ปริมาณและอื่นๆ
ด้านล่างนี้คือรหัสที่จะทำสิ่งนี้ให้สำเร็จโดยใช้โมดูล python lxml -
lxml_scrape3.py
from lxml import html
import requests
from time import sleep
import json
import argparse
from collections import OrderedDict
from time import sleep
def parse(ticker):
url = "http://finance.yahoo.com/quote/%s?p=%s"%(ticker,ticker)
response = requests.get(url, verify = False)
print ("Parsing %s"%(url))
sleep(4)
parser = html.fromstring(response.text)
summary_table = parser.xpath('//div[contains(@data-test,"summary-table")]//tr')
summary_data = OrderedDict()
other_details_json_link = "https://query2.finance.yahoo.com/v10/finance/quoteSummary/{0}? formatted=true&lang=en-
US®ion=US&modules=summaryProfile%2CfinancialData%2CrecommendationTrend%2
CupgradeDowngradeHistory%2Cearnings%2CdefaultKeyStatistics%2CcalendarEvents&
corsDomain=finance.yahoo.com".format(ticker)summary_json_response=requests.get(other_details_json_link)
try:
json_loaded_summary = json.loads(summary_json_response.text)
y_Target_Est = json_loaded_summary["quoteSummary"]["result"][0]["financialData"] ["targetMeanPrice"]['raw']
earnings_list = json_loaded_summary["quoteSummary"]["result"][0]["calendarEvents"]['earnings']
eps = json_loaded_summary["quoteSummary"]["result"][0]["defaultKeyStatistics"]["trailingEps"]['raw']
datelist = []
for i in earnings_list['earningsDate']:
datelist.append(i['fmt'])
earnings_date = ' to '.join(datelist)
for table_data in summary_table:
raw_table_key = table_data.xpath('.//td[contains(@class,"C(black)")]//text()')
raw_table_value = table_data.xpath('.//td[contains(@class,"Ta(end)")]//text()')
table_key = ''.join(raw_table_key).strip()
table_value = ''.join(raw_table_value).strip()
summary_data.update({table_key:table_value})
summary_data.update({'1y Target Est':y_Target_Est,'EPS (TTM)':eps,'Earnings Date':earnings_date,'ticker':ticker,'url':url})
return summary_data
except:
print ("Failed to parse json response")
return {"error":"Failed to parse json response"}
if __name__=="__main__":
argparser = argparse.ArgumentParser()
argparser.add_argument('ticker',help = '')
args = argparser.parse_args()
ticker = args.ticker
print ("Fetching data for %s"%(ticker))
scraped_data = parse(ticker)
print ("Writing data to output file")
with open('%s-summary.json'%(ticker),'w') as fp:
json.dump(scraped_data,fp,indent = 4) หากต้องการเรียกใช้โค้ดด้านบน ให้พิมพ์ด้านล่างในเทอร์มินัลคำสั่ง -
c:\Python\Python361>python lxml_scrape3.py MSFT
ในการรัน lxml_scrap3.py คุณจะเห็น ไฟล์ .json ถูกสร้างขึ้นในไดเร็กทอรีการทำงานปัจจุบันของคุณ โดยตั้งชื่อบางอย่างเช่น "stockName-summary.json" ขณะที่ฉันกำลังพยายามแยกฟิลด์ msft(microsoft) จาก yahoo Finance ดังนั้นไฟล์คือ สร้างด้วยชื่อ − "msft-summary.json"
ด้านล่างนี้เป็นภาพหน้าจอของผลลัพธ์ที่สร้างขึ้น -
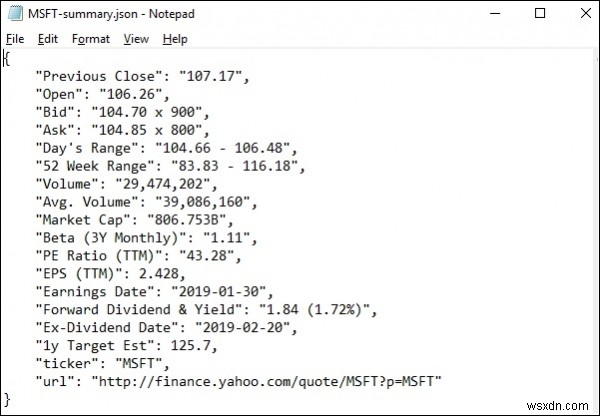
ดังนั้นเราจึงขูดข้อมูลที่จำเป็นทั้งหมดจาก yahoo.finance ของ microsoft ได้สำเร็จโดยใช้ lxml และร้องขอ จากนั้นจึงบันทึกข้อมูลในไฟล์ซึ่งภายหลังสามารถใช้เพื่อแบ่งปันหรือวิเคราะห์การเคลื่อนไหวของราคาหุ้นของ microsoft
