หนึ่งในกรอบงานที่ดีที่สุดสำหรับการพัฒนาโปรแกรมรวบรวมข้อมูลคือเรื่องที่สนใจ Scrapy เป็นเฟรมเวิร์กการขูดและรวบรวมข้อมูลเว็บยอดนิยมโดยใช้ฟังก์ชันระดับสูงเพื่อทำให้การขูดเว็บไซต์ง่ายขึ้น
การติดตั้ง
การติดตั้ง scrapy ใน windows นั้นง่ายมาก เราสามารถใช้ pip หรือ conda (ถ้าคุณมีอนาคอนด้า) Scrapy ทำงานบนทั้ง python 2 และ 3 เวอร์ชัน
pip ติดตั้ง Scrapy
หรือ
conda install –c conda-forge scrapy
หากติดตั้ง Scrapy อย่างถูกต้อง คำสั่ง scrapy จะพร้อมใช้งานในเทอร์มินัล -
C:\Users\rajesh>scrapyScrapy 1.6.0 - ไม่มีโปรเจ็กต์ที่ใช้งานอยู่Usage:scrapy[ตัวเลือก] [args]คำสั่งที่ใช้ได้:bench เรียกใช้การทดสอบเกณฑ์มาตรฐานอย่างรวดเร็ว ดึง URL โดยใช้ Scrapy downloadergenspider สร้างสไปเดอร์ใหม่โดยใช้ pre- templatesrunspider ที่กำหนดไว้ เรียกใช้แมงมุมที่มีในตัวเอง (โดยไม่ต้องสร้างโปรเจ็กต์) การตั้งค่า รับการตั้งค่า เชลล์ ขูดแบบโต้ตอบ consolestartproject สร้างโปรเจ็กต์ใหม่ รุ่น Print Scrapy ดูเวอร์ชันเปิด URL ในเบราว์เซอร์ ตามที่เห็นโดย Scrapy[ เพิ่มเติม ] มีคำสั่งเพิ่มเติมเมื่อเรียกใช้จากไดเรกทอรีโครงการ ใช้ "scrapy -h" เพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับคำสั่ง
การเริ่มต้นโครงการ
เมื่อติดตั้ง Scrapy แล้ว เราสามารถเรียกใช้ โครงการเริ่มต้น คำสั่งเพื่อสร้างโครงสร้างเริ่มต้นสำหรับโครงการ Scrapy แรกของเรา
ในการดำเนินการนี้ ให้เปิดเทอร์มินัลแล้วไปที่ไดเร็กทอรีที่คุณต้องการจัดเก็บโครงการ Scrapy ของคุณ จากนั้นเรียกใช้ scrapy startproject
C:\Users\rajesh>scrapy startproject scrapy_exampleNew Scrapy project 'scrapy_example' โดยใช้ไดเร็กทอรีเทมเพลต 'c:\python\python361\lib\site-packages\scrapy\templates\project' สร้างใน:C:\Users \rajesh\scrapy_exampleคุณสามารถเริ่มต้นสไปเดอร์ตัวแรกด้วย:cd scrapy_examplescrapy genspider example.comC:\Users\rajesh>cd scrapy_exampleC:\Users\rajesh\scrapy_example>tree /FFolder PATH listingVolume หมายเลขซีเรียลคือ 8CD6-8D39C:.│ เหม็น cfg│└───scrapy_example │ items.py │ Middlewares.py │ pipes.py │ settings.py │ __init__.py │ ├───แมงมุม │ │ __init__.py │ │ │ └───__pycache__ └─── __pycache__
อีกวิธีหนึ่งคือเราเรียกใช้ scrapy shell และทำ web scrapping ดังตัวอย่างด้านล่าง -
ใน [18]:fetch ("https://www.wsj.com/india")019-02-04 22:38:53 [scrapy.core.engine] DEBUG:Crawled (200) " rel="nofollow noopener noreferrer" target="_blank">https://www.wsj.com/india> (ผู้อ้างอิง:ไม่มี) โปรแกรมรวบรวมข้อมูลที่มีปัญหาจะส่งคืนวัตถุ "การตอบสนอง" ที่มีข้อมูลที่ดาวน์โหลด มาดูกันว่าโปรแกรมรวบรวมข้อมูลด้านบนของเรามีอะไรบ้าง -
In [19]:view(response)Out[19]:True
และในเบราว์เซอร์เริ่มต้นของคุณ ลิงก์ของเว็บจะเปิดขึ้นและคุณจะเห็นบางอย่างเช่น −

เยี่ยมมาก ที่ดูคล้ายกับหน้าเว็บของเรา ดังนั้นโปรแกรมรวบรวมข้อมูลจึงดาวน์โหลดหน้าเว็บทั้งหมดได้สำเร็จ
ทีนี้มาดูว่าโปรแกรมรวบรวมข้อมูลของเรามีอะไรบ้าง -
ใน [22]:print(response.text)The Wall Street Journal &ข่าวด่วน ธุรกิจ ข่าวการเงินและเศรษฐกิจ ข่าวโลกและวิดีโอ <ชื่อ meta ="viewport" content ="initial-scale =1.0001, maximum-scale =1.0001, maximum-scale =1.0001, user-scalable =no" data-reactid =".2316x0ul96e.0.3"/> <ชื่อ meta ="page.site" content ="wsj" data-reactid =".2316x0ul96e.0.7"/> <ชื่อ meta =" page.site.product" content ="WSJ" data-reactid =".2316x0ul96e.0.8"/> <ชื่อเมตา =" twitter:site" content ="@wsj" data-reactid =".2316x0ul96e.0.c:$6"/> …&อื่นๆ อีกมากมาย:มาลองดึงข้อมูลสำคัญสองสามอย่างจากหน้าเว็บนี้กัน -
กำลังขยายชื่อหน้าเว็บ −
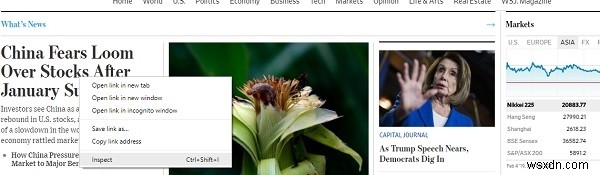
Scrapy มีวิธีดึงข้อมูลจาก HTML ตามตัวเลือก css เช่น class, id เป็นต้น หากต้องการค้นหาตัวเลือก css สำหรับชื่อหน้าเว็บใดๆ เพียงคลิกขวาแล้วคลิกตรวจสอบ เช่นด้านล่าง:
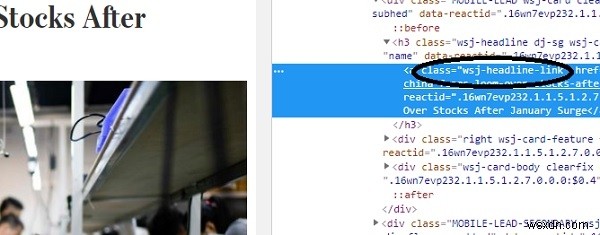
นี่จะเป็นการเปิดเครื่องมือสำหรับนักพัฒนาในหน้าต่างเบราว์เซอร์ของคุณ -
อย่างที่เห็น css class "wsj-headline-link" ถูกนำไปใช้กับแท็ก anchor() ทั้งหมดที่มีชื่อ ด้วยข้อมูลนี้ เราจะพยายามค้นหาชื่อทั้งหมดจากเนื้อหาที่เหลือในวัตถุตอบกลับ -
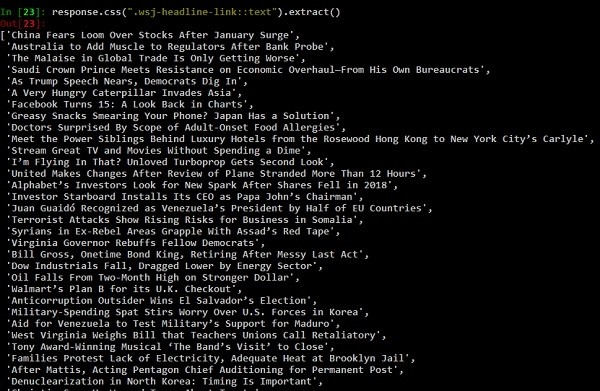
response.css() คือฟังก์ชันที่จะดึงเนื้อหาตามตัวเลือก css ที่ส่งผ่าน (เช่นแท็ก anchor ด้านบน) มาดูตัวอย่างเพิ่มเติมเกี่ยวกับฟังก์ชัน response.css ของเรากัน
ใน [24]:response.css(".wsj-headline-link::text")).extract_first()Out[24]:'China Fears Loom Over Stocks After January Surge'และ
ใน [25]:response.css(".wsj-headline-link").extract_first()Out[25]:'ความกลัวของจีน Loom Over Stocks หลังเดือนมกราคม Surge 'หากต้องการรับลิงก์ทั้งหมดจากหน้าเว็บ −
links =response.css('a::attr(href)').extract()ผลลัพธ์
['https://www.google.com/intl/en_us/chrome/browser/desktop/index.html','https://support.apple.com/downloads/','https:// www.mozilla.org/en-US/firefox/new/','https://windows.microsoft.com/en-us/internet-explorer/download-ie','https://www.barrons.com ','http://bigcharts.marketwatch.com','https://www.wsj.com/public/page/wsj-x-marketing.html','https://www.dowjones.com/' ,'https://global.factiva.com/factivalogin/login.asp?productname=global','https://www.fnlondon.com/','https://www.mansionglobal.com/',' https://www.marketwatch.com','https://newsplus.wsj.com','https://privatemarkets.dowjones.com','https://djlogin.dowjones.com/login.asp? productname=rnc','https://www.wsj.com/conferences','https://www.wsj.com/pro/centralbanking','https://www.wsj.com/video/', 'https://www.wsj.com','http://www.bigdecisions.com/','https://www.businessspectator.com.au/','https://www.checkout51.com /?utm_source=wsj&utm_medium=digitalhousead&utm_campaign=wsjspotlight','https://www.harpercollins.com/','https://housing. com/','https://www.makaan.com/','https://nypost.com/','https://www.newsamerica.com/','https://www.proptiger. com','https://www.rea-group.com/',…………หากต้องการรับความคิดเห็นจากหน้าเว็บ wsj(wall street journel) -
ใน [38]:response.css(".wsj-comment-count::text")).extract()Out[38]:['71', '59']ด้านบนนี้เป็นเพียงข้อมูลเบื้องต้นเกี่ยวกับการขูดเว็บผ่าน scrapy เราทำอะไรได้มากกว่านั้นด้วย scrapy