ในที่นี้ เราจะใช้ PyTorch เพื่อฝึก CNN ให้รู้จักตัวแยกประเภทหลักที่เขียนด้วยลายมือโดยใช้ชุดข้อมูล MNIST
MNIST เป็นชุดข้อมูลที่ใช้กันอย่างแพร่หลายสำหรับงานจำแนกประเภทที่เขียนด้วยลายมือซึ่งครอบคลุมรูปภาพระดับสีเทาขนาด 28*28 พิกเซลที่มีป้ายกำกับขนาด 28*28 พิกเซลมากกว่า 70k ของตัวเลขที่เขียนด้วยลายมือ ชุดข้อมูลประกอบด้วยรูปภาพการฝึกเกือบ 60k และรูปภาพทดสอบ 10k งานของเราคือการฝึกโมเดลโดยใช้อิมเมจการฝึก 60k และต่อมาก็ทดสอบความแม่นยำของการจัดหมวดหมู่กับอิมเมจทดสอบ 10k
การติดตั้ง
อันดับแรก เราต้องการ MXNet เวอร์ชันล่าสุด เพื่อเรียกใช้สิ่งต่อไปนี้บนเทอร์มินัลของคุณ:
$pip ติดตั้ง mxnet
และคุณจะชอบ
กำลังรวบรวม mxnet กำลังดาวน์โหลด https://files.pythonhosted.org/packages/60/6f/071f9ef51467f9f6cd35d1ad87156a29314033bbf78ad862a338b9eaf2e6/mxnet-1.2.0-py2.py3-none-win32.whl (12.8MB)██ (12.8MB) ███████████████████████████| 12.8MB 131kB/sRequirement เป็นไปตามข้อกำหนด:numpy ใน c:\python\python361\lib\site-packages (จาก mxnet) (1.16.0) กำลังรวบรวม graphviz (จาก mxnet) กำลังดาวน์โหลด https://files.pythonhosted.org/packages/ 1f/e2/ef2581b5b86625657afd32030f90cf2717456c1d2b711ba074bf007c0f1a/graphviz-0.10.1-py2.py3-none-any.whl….….การติดตั้งแพ็คเกจที่รวบรวม:graphviz, mxnet ติดตั้งสำเร็จแล้ว graphviz-0.1.0.1 อย่างที่สอง เราต้องการคลังคบเพลิงและคบเพลิง - หากไม่ใช่ที่ที่คุณสามารถติดตั้งโดยใช้ pipนำเข้าไลบรารี
นำเข้า Tormimport Torchvisionโหลดชุดข้อมูล MNIST
ก่อนที่เราจะเริ่มทำงานกับโปรแกรมของเรา เราจำเป็นต้องมีชุดข้อมูล MNIST ให้โหลดรูปภาพและป้ายกำกับลงในหน่วยความจำและกำหนดไฮเปอร์พารามิเตอร์ที่เราจะใช้สำหรับการทดสอบนี้
#n_epochs คือจำนวนครั้ง เราจะวนซ้ำชุดข้อมูลการฝึกที่สมบูรณ์n_epochs =3batch_size_train =64batch_size_test =1000#Learning_rate และโมเมนตัมสำหรับ opimizerlearning_rate =0.01momentum =0.5log_interval =10random_seed =1torch.backends.cud =Falsetorch.manual_seed(random_seed)ตอนนี้เราจะโหลดชุดข้อมูล MNIST โดยใช้ TorchVision เรากำลังใช้ batch_size ของ 64 สำหรับการฝึกอบรมและขนาด 1000 สำหรับการทดสอบในชุดข้อมูลนี้ สำหรับการทำให้เป็นมาตรฐาน เราจะใช้ค่าเฉลี่ย 0.1307 และค่าเบี่ยงเบนมาตรฐานที่ 0.3081 ของชุดข้อมูล MNIST
train_loader =torch.utils.data.DataLoader ( torchvision.datasets.MNIST('/files/', train=True, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor())” torchvision.transforms.Normalize((0.1307,), (0.3081,)) ]) ), batch_size=batch_size_train, shuffle=True)test_loader =torch.utils.data.DataLoader( torchvision.datasets.MNIST('/files/', train=False, download=True, transform=torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize( (0.1307,), (0.3081,)) ]) ),batch_size=batch_size_test, shuffle =จริง)ผลลัพธ์
กำลังดาวน์โหลด http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gzDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gzDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gzกำลังดาวน์โหลด http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gzProcessing...Done !ใช้ test_loader เพื่อโหลดข้อมูลการทดสอบ
ตัวอย่าง =ระบุ (test_loader)batch_idx, (example_data, example_targets) =ถัดไป (ตัวอย่าง)example_data.shapeผลลัพธ์
torch.Size([1000, 1, 28, 28])จากผลลัพธ์ เราจะเห็นได้ว่าชุดข้อมูลทดสอบหนึ่งชุดคือเทนเซอร์ของรูปร่าง [1000, 1, 28, 28] หมายถึง- 1,000 ตัวอย่างขนาด 28*28 พิกเซลในโทนสีเทา
ให้พล็อตชุดข้อมูลบางส่วนโดยใช้ matplotlib
นำเข้า matplotlib.pyplot เป็น pltfig =plt.figure()for i in range(5):plt.subplot(2,3,i+1)plt.tight_layout()plt.imshow(example_data[i][0] ], cmap='gray', interpolation='none')plt.title("ความจริงพื้น:{}".format(example_targets[i]))plt.xticks([])plt.yticks([])print( มะเดื่อ)ผลลัพธ์
การสร้างเครือข่าย
ตอนนี้ เรากำลังจะสร้างเครือข่ายของเราโดยใช้เลเยอร์ 2 มิติแบบ Convolutional ตามด้วยเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์สองชั้น เรากำลังจะสร้างคลาสใหม่สำหรับเครือข่ายที่เราต้องการสร้าง แต่ก่อนหน้านั้น เรามานำเข้าโมดูลกันก่อน
นำเข้า torch.nn เป็น nnimport torch.nn.functional เป็น Fimport torch.optim เป็น optimclass Net (nn.Module):def __init__(self):super(Net, self).__init__() self.conv1 =nn. Conv2d(1, 10, kernel_size=5) self.conv2 =nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop =nn.Dropout2d() self.fc1 =nn.Linear(320, 50) self.fc2 =nn.Linear(50, 10) def forward(ตัวเอง, x):x =F.relu(F.max_pool2d(self.conv1(x), 2)) x =F.relu(F.max_pool2d(self.conv2_drop) (self.conv2(x)), 2)) x =x.view(-1, 320) x =F.relu(self.fc1(x)) x =F.dropout(x, training=self.training) x =self.fc2(x)return F.log_softmax(x)เริ่มต้นเครือข่ายและเครื่องมือเพิ่มประสิทธิภาพ:
เครือข่าย =Net()optimizer =optim.SGD(network.parameters(), lr =learning_rate,momentum =โมเมนตัม)การฝึกโมเดล
มาสร้างแบบจำลองการฝึกอบรมของเรากัน ดังนั้นก่อนอื่น ให้ตรวจสอบว่าเครือข่ายของเราอยู่ในโหมดเครือข่าย จากนั้นจึงเชื่อมโยงข้อมูลการฝึกโดยรวมหนึ่งครั้งต่อยุค Dataloader จะโหลดแต่ละแบตช์ เราตั้งค่าการไล่ระดับสีเป็นศูนย์โดยใช้เครื่องมือเพิ่มประสิทธิภาพ.zero_grad()
train_losses =[]train_counter =[]test_losses =[]test_counter =[i*len(train_loader.dataset) สำหรับฉันในช่วง (n_epochs + 1)]เพื่อสร้างเส้นโค้งการฝึกที่ดี เราสร้างสองรายการสำหรับบันทึกการสูญเสียการฝึกอบรมและการทดสอบ บนแกน x เราต้องการแสดงจำนวนตัวอย่างการฝึก
การเรียกแบบย้อนกลับ () ตอนนี้เรารวบรวมชุดการไล่ระดับสีใหม่ซึ่งเราเผยแพร่กลับเข้าไปในพารามิเตอร์ของเครือข่ายแต่ละรายการโดยใช้เครื่องมือเพิ่มประสิทธิภาพขั้นตอน ()
def train(epoch):network.train() สำหรับ batch_idx, (data, target) ในการแจกแจง (train_loader):ตัวเพิ่มประสิทธิภาพ.zero_grad() เอาต์พุต =เครือข่าย (ข้อมูล) การสูญเสีย =F.nll_loss (เอาต์พุต, เป้าหมาย) การสูญเสีย .backward() optimizer.step() ถ้า batch_idx % log_interval ==0:print('Train Epoch:{} [{}/{} ({:.0f}%)]\tLoss:{:.6f}' รูปแบบ (ยุค, batch_idx * len (ข้อมูล), len (train_loader.dataset), 100 * batch_idx / len (train_loader), loss.item ())) train_losses.append (loss.item ()) train_counter.append ( ( batch_idx*64) + ((epoch-1)*len(train_loader.dataset))) torch.save(network.state_dict(), '/results/model.pth') torch.save(optimizer.state_dict(), ' /results/optimizer.pth')โมดูลเครือข่ายเป็นกลาง เช่นเดียวกับเครื่องมือเพิ่มประสิทธิภาพ มีความสามารถในการบันทึกและโหลดสถานะภายในโดยใช้ .state_dict()
สำหรับการทดสอบแบบวนรอบ เราได้สรุปผลการทดสอบที่สูญเสียและติดตามตัวเลขที่จัดประเภทอย่างถูกต้องเพื่อคำนวณความแม่นยำของเครือข่าย
def test():network.eval() test_loss =0 correct =0 with torch.no_grad():สำหรับข้อมูล เป้าหมายใน test_loader:output =network(data) test_loss +=F.nll_loss(output, target, size_average=False).item() pred =output.data.max(1, keepdim=True)[1] ถูกต้อง +=pred.eq(target.data.view_as(pred)).sum() test_loss /=len( test_loader.dataset) test_losses.append(test_loss) print('\nชุดทดสอบ:การสูญเสียเฉลี่ย:{:.4f} ความแม่นยำ:{}/{} ({:.0f}%)\n'.format( test_loss, ถูกต้อง len(test_loader.dataset), 100 * ถูกต้อง / len(test_loader.dataset)))ในการรันการฝึกอบรม เราเพิ่มการเรียก test() ก่อนที่เราจะวนรอบ n_epochs เพื่อประเมินโมเดลของเราด้วยพารามิเตอร์เริ่มต้นแบบสุ่ม
test()for epoch in range(1, n_epochs + 1):train(epoch) test()ผลลัพธ์
ชุดทดสอบ:เฉลี่ย การสูญเสีย:2.3048 ความแม่นยำ:1063/10000 (10%) ระยะรถไฟ:1 [0/60000 (0%)] ความสูญเสีย:2.294911 ระยะรถไฟ:1 [640/60000 (1%)]การสูญเสีย:2.314225 ระยะรถไฟ:1 [ 1280/60000 (2%)]การสูญเสีย:2.290719ช่วงรถไฟ:1 [1920/60000 (3%)]การสูญเสีย:2.294191ยุครถไฟ:1 [2560/60000 (4%)]การสูญเสีย:2.246799ยุครถไฟ:1 [3200/ 60000 (5%)]สูญเสีย:2.292224Train Epoch:1 [3840/60000 (6%)]Loss:2.216632Train Epoch:1 [4480/60000 (7%)]Loss:2.259646Train Epoch:1 [5120/60000 ( 9%)]การสูญเสีย:2.244781ช่วงรถไฟ:1 [5760/60000 (10%)]การสูญเสีย:2.245569ช่วงรถไฟ:1 [6400/60000 (11%)]การสูญเสีย:2.203358ยุครถไฟ:1 [7040/60000 (12%) )]การสูญเสีย:2.192290Train Epoch:1 [7680/60000 (13%)]การสูญเสีย:2.040502Train Epoch:1 [8320/60000 (14%)]การสูญเสีย:2.102528Train Epoch:1 [8960/60000 (15%)] ขาดทุน:1.944297Train Epoch:1 [9600/60000 (16%)]Loss:1.886444Train Epoch:1 [10240/60000 (17%)]Loss:1.801920Train Epoch:1 [10880/60000 (18%)]Loss:1.421267Train Epoch:1 [11520/60000 (19%)]การสูญเสีย:1.491448Train Epoch:1 [12160/60000 (20%)]การสูญเสีย:1.600088Train Epoch:1 [12800/60000 ( 21%)]การสูญเสีย:1.218677ช่วงรถไฟ:1 [13440/60000 (22%)]การสูญเสีย:1.060651ช่วงรถไฟ:1 [14080/60000 (23%)]การสูญเสีย:1.161512ยุครถไฟ:1 [14720/60000 (25%) )]การสูญเสีย:1.351181Train Epoch:1 [15360/60000 (26%)]การสูญเสีย:1.012257Train Epoch:1 [16000/60000 (27%)]การสูญเสีย:1.018847Train Epoch:1 [16640/60000 (28%)] การสูญเสีย:0.944324Train Epoch:1 [17280/60000 (29%)]Loss:0.929246Train Epoch:1 [17920/60000 (30%)]Loss:0.903336Train Epoch:1 [18560/60000 (31%)]การสูญเสีย:1.243159Train Epoch:1 [19200/60000 (32%)]Loss:0.696106Train Epoch:1 [19840/60000 (33%)]Loss:0.902251Train Epoch:1 [20480/60000 (34%)]การสูญเสีย:0.986816Train ช่วง:1 [21120/60000 (35%)]การสูญเสีย:1.203934ยุครถไฟ:1 [21760/60000 (36%)]การสูญเสีย:0.682855ช่วงรถไฟ:1 [22400/60000 (37%)]การสูญเสีย:0.653592ช่วงรถไฟ:1 [23040/60000 (38%)] ขาดทุน:0.932158 ระยะรถไฟ:1 [23680/60000 (39%)]การสูญเสีย:1.110188 ระยะรถไฟ:1 [24320/60000 (41%)]การสูญเสีย:0.817414 ระยะรถไฟ:1 [ 24960/60000 (42%)]การสูญเสีย:0.584215ยุครถไฟ:1 [25600/60000 (43%)]การสูญเสีย:0.724121ยุครถไฟ:1 [26240 /60000 (44%)]ขาดทุน:0.707071Train Epoch:1 [26880/60000 (45%)]Loss:0.574117Train Epoch:1 [27520/60000 (46%)]Loss:0.652862Train Epoch:1 [28160/60000 (47%)]ขาดทุน:0.654354Train Epoch:1 [28800/60000 (48%)]Loss:0.811647Train Epoch:1 [29440/60000 (49%)]Loss:0.536885Train Epoch:1 [30080/60000 (50) %)]การสูญเสีย:0.849961ระยะรถไฟ:1 [30720/60000 (51%)]การสูญเสีย:0.844555ระยะรถไฟ:1 [31360/60000 (52%)]การสูญเสีย:0.687859ยุครถไฟ:1 [32000/60000 (53%) ]ขาดทุน:0.766818Train Epoch:1 [32640/60000 (54%)]Loss:0.597061Train Epoch:1 [33280/60000 (55%)]Loss:0.691049Train Epoch:1 [33920/60000 (57%)]Loss :0.573049Train Epoch:1 [34560/60000 (58%)]Los:0.405698Train Epoch:1 [35200/60000 (59%)]Loss:0.480660Train Epoch:1 [35840/60000 (60%)]การสูญเสีย:0.582871 ยุครถไฟ:1 [36480/60000 (61%)]การสูญเสีย:0.496494…….ยุครถไฟ:3 [49920/60000 (83%)]การสูญเสีย:0.253500ยุครถไฟ:3 [50560/60000 (84%) )]ขาดทุน:0.364354Train Epoch:3 [51200/60000 (85%)]Loss:0.333843Train:3 [51840/60000 (86%)]Loss:0.096922Train ยุค:3 [52480/60000 (87%)]การสูญเสีย:0.282102ยุครถไฟ:3 [53120/60000 (88%)]การสูญเสีย:0.236428ยุครถไฟ:3 [53760/60000 (90%)]การสูญเสีย:0.610584ยุครถไฟ:3 [54400/60000 (91%)] ขาดทุน:0.198840 ระยะรถไฟ:3 [55040/60000 (92%)]การสูญเสีย:0.344225 ระยะรถไฟ:3 [55680/60000 (93%)]การสูญเสีย:0.158644 ระยะรถไฟ:3 [ 56320/60000 (94%)]ขาดทุน:0.216912ช่วงรถไฟ:3 [56960/60000 (95%)]ขาดทุน:0.309554ช่วงรถไฟ:3 [57600/60000 (96%)]ขาดทุน:0.243239ช่วงรถไฟ:3 [58240/ 60000 (97%)]การสูญเสีย:0.176541ยุครถไฟ:3 [58880/60000 (98%)]การสูญเสีย:0.456749ยุครถไฟ:3 [59520/60000 (99%)]การสูญเสีย:0.318569ชุดการทดสอบ:Avg. การสูญเสีย:0.0912 ความแม่นยำ:9716/10000 (97%)การประเมินประสิทธิภาพของโมเดล
ดังนั้นด้วยการฝึกอบรมเพียง 3 ช่วงเวลา เราจึงสามารถบรรลุความแม่นยำ 97% ในชุดทดสอบ ด้วยพารามิเตอร์เริ่มต้นแบบสุ่ม เราเริ่มต้นด้วยความแม่นยำ 10% ในชุดทดสอบก่อนเริ่มการฝึก
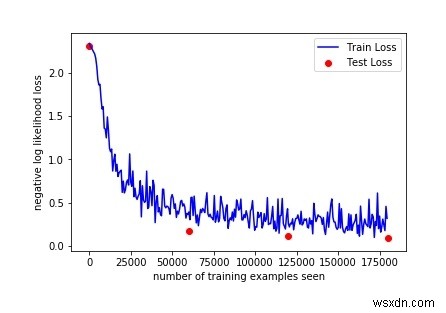
มาพลอตเส้นโค้งการฝึกกันเถอะ:
fig =plt.figure()plt.plot(train_counter, train_losses, color='blue')plt.scatter(test_counter, test_losses, color='red')plt.legend(['Train Loss', 'Test Loss'], loc='upper right')plt.xlabel('จำนวนตัวอย่างการฝึกอบรมที่เห็น')plt.ylabel('negative log likelihood loss')figผลลัพธ์
การตรวจสอบผลลัพธ์ด้านบนทำให้เราสามารถเพิ่มจำนวนยุคเพื่อดูผลลัพธ์เพิ่มเติม เนื่องจากความถูกต้องเพิ่มขึ้นโดยการตรวจสอบ 3 ยุค
แต่ก่อนหน้านั้น ให้เรียกใช้ตัวอย่างเพิ่มเติมและเปรียบเทียบผลลัพธ์ของโมเดล:
พร้อม torch.no_grad():output =network(example_data)fig =plt.figure()for i in range(6):plt.subplot(2,3,i+1) plt.tight_layout() plt. imshow(example_data[i][0], cmap='gray', interpolation='none') plt.title("Prediction:{}".format( output.data.max(1, keepdim=True)[1] [i].item())) plt.xticks([]) plt.yticks([])มะเดื่อ
ดังที่เราเห็นการคาดคะเนแบบจำลองของเรา ดูเหมือนว่าตัวอย่างเหล่านั้นจะตรงประเด็น