
Logistic Regression เป็นเทคนิคทางสถิติในการทำนายผลลัพธ์เลขฐานสอง ไม่ใช่เรื่องใหม่เนื่องจากกำลังถูกนำไปใช้ในด้านต่างๆ ตั้งแต่การเงิน การแพทย์ ไปจนถึงอาชญวิทยาและสังคมศาสตร์อื่นๆ
ในส่วนนี้ เราจะพัฒนาการถดถอยโลจิสติกโดยใช้ python แม้ว่าคุณจะสามารถใช้ภาษาอื่นเช่น R
ได้การติดตั้ง
เราจะใช้ไลบรารีด้านล่างในโปรแกรมตัวอย่างของเรา
-
อ้วน :เพื่อกำหนดอาร์เรย์ตัวเลขและเมทริกซ์
-
แพนด้า :เพื่อจัดการและดำเนินการกับข้อมูล
-
แบบจำลองสถิติ :เพื่อจัดการกับการประมาณค่าพารามิเตอร์และการทดสอบทางสถิติ
-
Pylab :เพื่อสร้างแปลง
คุณสามารถติดตั้งไลบรารีด้านบนโดยใช้ pip โดยเรียกใช้คำสั่งด้านล่างใน CLI
>pip ติดตั้ง numpy pandas statsmodels
ตัวอย่างกรณีการใช้งานสำหรับการถดถอยโลจิสติก
เพื่อทดสอบการถดถอยโลจิสติกของเราใน python เราจะใช้ข้อมูลการถดถอย logit ที่จัดทำโดย UCLA (สถาบันเพื่อการวิจัยและการศึกษาดิจิทัล) คุณสามารถเข้าถึงข้อมูลจากลิงค์ด้านล่างในรูปแบบ csv:https://stats.idre.ucla.edu/stat/data/binary.csv
ฉันได้บันทึกไฟล์ csv นี้ในเครื่องของฉันแล้ว &จะอ่านข้อมูลจากที่นั่น คุณสามารถทำได้เช่นกัน ด้วยไฟล์ csv นี้ เราจะระบุปัจจัยต่างๆ ที่อาจส่งผลต่อการรับเข้าเรียนในระดับบัณฑิตศึกษา
นำเข้าไลบรารีที่จำเป็นและโหลดชุดข้อมูล
เราจะอ่านข้อมูลโดยใช้ไลบรารี่แพนด้า (pandas.read_csv):
นำเข้าแพนด้าเป็น pdimport statsmodels.api เป็น smimport pylab เป็น plimport numpy เป็น npdf =pd.read_csv('binary.csv')#เราสามารถอ่านข้อมูลได้โดยตรงจากลิงก์ \# df =pd.read_csv('https://stats.idre.ucla.edu/stat/data/binary.csv')print(df.head()) ผลลัพธ์
ยอมรับ gre gpa rank0 0 380 3.61 31 1 660 3.67 32 1 800 4.00 13 1 640 3.19 44 0 520 2.93 4
ดังที่เราเห็นจากผลลัพธ์ด้านบน ชื่อคอลัมน์หนึ่งคือ 'อันดับ' ซึ่งอาจสร้างปัญหาได้เนื่องจาก 'อันดับ' เป็นชื่อของวิธีการในดาต้าเฟรมของแพนด้าด้วย เพื่อหลีกเลี่ยงความขัดแย้ง ฉันกำลังเปลี่ยนชื่อคอลัมน์ยศเป็น 'ศักดิ์ศรี' เรามาเปลี่ยนชื่อคอลัมน์ชุดข้อมูลกันเถอะ:
df.columns =["admit", "gre", "gpa", "prestige"]print(df.columns)
ผลลัพธ์
Index(['admit', 'gre', 'gpa', 'prestige'], dtype='object')ใน [ ]:
ตอนนี้ทุกอย่างดูเรียบร้อย ตอนนี้เราสามารถมองลึกลงไปอีกว่าชุดข้อมูลของเรามีอะไรบ้าง
#สรุปข้อมูล
เราจะใช้ฟังก์ชันแพนด้าเพื่อสรุปภาพรวมทุกอย่าง
print(df.describe())
ผลลัพธ์
ยอมรับ gre gpa prestigecount 400.000000 400.000000 400.000000 400.00000mean 0.317500 587.700000 3.389900 2.48500std 0.466087 115.516536 0.380567 0.94446min 0.000000 220.000000 2.260000 1.0000025% 0.000000 520.000000 3.130000 2.0000050% 0.000000 2.000000 2.580.07000000 1.0000000% สูงสุด 4.0000000 %เราสามารถรับค่าเบี่ยงเบนมาตรฐานของแต่ละคอลัมน์ของข้อมูลของเรา &ศักดิ์ศรีของการตัดตารางความถี่ได้ และไม่ว่าจะมีใครเข้ารับการรักษาหรือไม่
# ดูค่าเบี่ยงเบนมาตรฐานของแต่ละ columnprint(df.std())ผลลัพธ์
ยอมรับ 0.466087gre 115.516536gpa 0.380567 ศักดิ์ศรี 0.944460dtype:float64ตัวอย่าง
# ศักดิ์ศรีของการตัดตารางความถี่และไม่ว่าจะมีใครเข้ารับการรักษาหรือไม่print(pd.crosstab(df['admit'], df['prestige'], rownames =['admit']))ผลลัพธ์
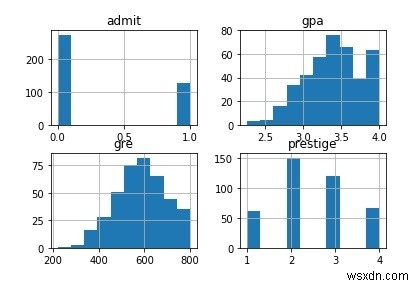
ศักดิ์ศรี 1 2 3 4admit0 28 97 93 551 33 54 28 12มาพลอตคอลัมน์ทั้งหมดของชุดข้อมูลกัน
# พล็อตทั้งหมดของ columnsdf.hist()pl.show()ผลลัพธ์
ตัวแปรจำลอง
ไลบรารี Python pandas มีความยืดหยุ่นอย่างมากในการแสดงตัวแปรตามหมวดหมู่
# dummify rankdummy_ranks =pd.get_dummies(df['prestige'], prefix='prestige')print(dummy_ranks.head())ผลลัพธ์
ศักดิ์ศรี_1 ศักดิ์ศรี_2 ศักดิ์ศรี_3 ศักดิ์ศรี_40 0 0 1 01 0 0 1 02 1 0 0 03 0 0 0 14 0 0 0 1ตัวอย่าง
# สร้าง data frame ที่สะอาดสำหรับ regressioncols_to_keep =['admit', 'gre', 'gpa']data =df[cols_to_keep].join(dummy_ranks.ix[:, 'prestige_2':])ผลลัพธ์
ยอมรับ gre gpa prestige_2 prestige_3 prestige_40 0 380 3.61 0 1 01 1 660 3.67 0 1 02 1 800 4.00 0 0 03 1 640 3.19 0 0 14 0 520 2.93 0 0 1In [ ]:การถดถอย
ตอนนี้เราจะทำการถดถอยโลจิสติก ซึ่งค่อนข้างง่าย เราเพียงแค่ระบุคอลัมน์ที่มีตัวแปรที่เรากำลังพยายามคาดการณ์ ตามด้วยคอลัมน์ที่โมเดลควรใช้ในการทำนาย
ตอนนี้เรากำลังคาดการณ์คอลัมน์การยอมรับตามตัวแปรจำลอง gre, gpa และ prestige prestige_2, prestige_3 &prestige_4
train_cols =data.columns[1:]# Index([gre, gpa, prestige_2, prestige_3, prestige_4], dtype=object)logit =sm.Logit(data['admit'], data[train_cols])# พอดีกับ modelresult =logit.fit()ผลลัพธ์
การเพิ่มประสิทธิภาพสิ้นสุดลงเรียบร้อยแล้ว ค่าฟังก์ชันปัจจุบัน:0.573147Iterations 6การตีความผลลัพธ์
มาสร้างผลลัพธ์สรุปโดยใช้ statsmodels
print(result.summary2())ผลลัพธ์
<ก่อนหน้า> ผลลัพธ์:Logit===============================================================รุ่น:Logit No. การทำซ้ำ:6.0000 ตัวแปรขึ้นอยู่กับ:ยอมรับ Pseudo R-squared:0.083Date:2019-03-03 14:16 AIC:470.5175 เลขที่ ข้อสังเกต:400 BIC:494.4663Df รุ่น:5 Log-Likelihood:-229.26Df ตกค้าง:394 LL-Null:-249.99Converged:1.0000 Scale:1.0000-------------------------------- ---------------------------------------------------- กอฟ. มาตรฐานสากล z P>|z| [0.025 0.975]--------------------------------------------- ------------------gre 0.0023 0.0011 2.0699 0.0385 0.0001 0.0044gpa 0.8040 0.3318 2.4231 0.0154 0.1537 1.4544prestige_2 -0.6754 0.3165 -2.1342 0.0328 -1.2958 -0.0551prestige_3 -1.3402 0.3453 -3.8812 0.0001 -2.0170 -0.6634prestige_4 -1.5515 0.4178 -3.7131 0.0002 -2.3704 -0.7325จุดตัดขวาง -3.9900 1.1400 -3.5001 0.0005 -6.2242 -1.7557==============================================================
ออบเจ็กต์ผลลัพธ์ด้านบนยังช่วยให้เราแยกและตรวจสอบส่วนต่างๆ ของเอาต์พุตของโมเดลได้
#ดูช่วงความเชื่อมั่นของแต่ละ coeffecientprint(result.conf_int())
ผลลัพธ์
0 1gre 0.000120 0.004409gpa 0.1153684 1.454391prestige_2 -1.295751 -0.055135prestige_3 -2.016992 -0.663416prestige_4 -2.370399 -0.732529intercept -6.224242 -1.755716
จากผลลัพธ์ข้างต้น เราจะเห็นได้ว่ามีความสัมพันธ์แบบผกผัน b/w ความน่าจะเป็นที่จะได้รับการยอมรับและศักดิ์ศรีของโรงเรียนระดับปริญญาตรีของผู้สมัคร
ดังนั้น ความน่าจะเป็นของผู้สมัครที่จะได้รับการยอมรับในโปรแกรมระดับบัณฑิตศึกษาจึงสูงขึ้นสำหรับนักเรียนที่เข้าเรียนในวิทยาลัยระดับปริญญาตรีอันดับต้นๆ (prestige_1=True) เมื่อเทียบกับโรงเรียนที่มีอันดับต่ำกว่า (prestige_3 หรือ prestige_4)
